 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTemporally Consistent Object 6D Pose Estimation for Robot Control
May 04, 2026Single-view RGB object pose estimators have reached a level of precision and efficiency that makes them good candidates for vision-based robot control. However, off-the-shelf methods lack temporal consistency and robustness that are mandatory for a stable feedback control. In this work, we develop a factor graph approach to enforce temporal consistency of the object pose estimates. In particular, the proposed approach: (i) incorporates object motion models, (ii) explicitly estimates the object pose measurement uncertainty, and (iii) integrates the above two components in an online optimization-based estimator. We demonstrate that with appropriate outlier rejection and smoothing using the proposed factor graph approach, we can significantly improve the results on standardized pose estimation benchmarks. We experimentally validate the stability of the proposed approach for a feedback-based robot control task in which the object is tracked by the camera attached to a torque controlled manipulator.
* Project page: https://data.ciirc.cvut.cz/public/projects/2024TemporalPose/
Multi-step manipulation task and motion planning guided by video demonstration
May 13, 2025



This work aims to leverage instructional video to solve complex multi-step task-and-motion planning tasks in robotics. Towards this goal, we propose an extension of the well-established Rapidly-Exploring Random Tree (RRT) planner, which simultaneously grows multiple trees around grasp and release states extracted from the guiding video. Our key novelty lies in combining contact states and 3D object poses extracted from the guiding video with a traditional planning algorithm that allows us to solve tasks with sequential dependencies, for example, if an object needs to be placed at a specific location to be grasped later. We also investigate the generalization capabilities of our approach to go beyond the scene depicted in the instructional video. To demonstrate the benefits of the proposed video-guided planning approach, we design a new benchmark with three challenging tasks: (I) 3D re-arrangement of multiple objects between a table and a shelf, (ii) multi-step transfer of an object through a tunnel, and (iii) transferring objects using a tray similar to a waiter transfers dishes. We demonstrate the effectiveness of our planning algorithm on several robots, including the Franka Emika Panda and the KUKA KMR iiwa. For a seamless transfer of the obtained plans to the real robot, we develop a trajectory refinement approach formulated as an optimal control problem (OCP).
Learning to Manipulate Tools by Aligning Simulation to Video Demonstration
Nov 04, 2021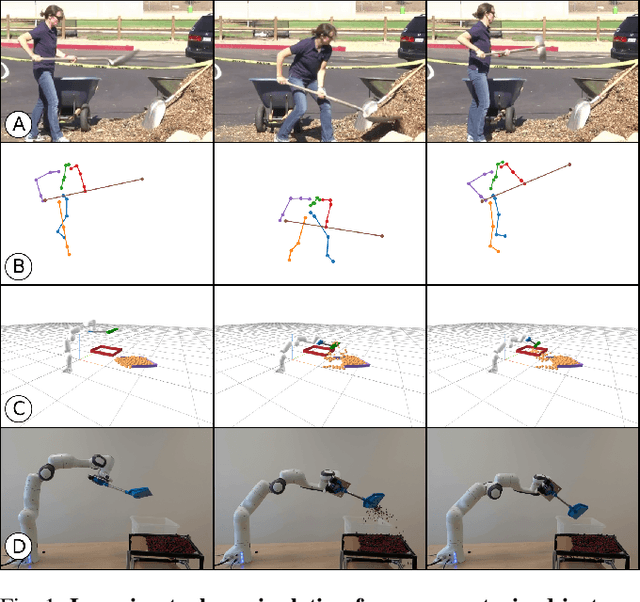


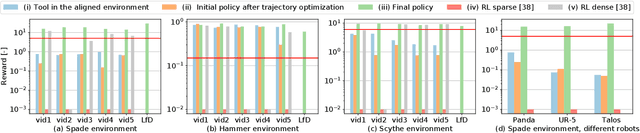
A seamless integration of robots into human environments requires robots to learn how to use existing human tools. Current approaches for learning tool manipulation skills mostly rely on expert demonstrations provided in the target robot environment, for example, by manually guiding the robot manipulator or by teleoperation. In this work, we introduce an automated approach that replaces an expert demonstration with a Youtube video for learning a tool manipulation strategy. The main contributions are twofold. First, we design an alignment procedure that aligns the simulated environment with the real-world scene observed in the video. This is formulated as an optimization problem that finds a spatial alignment of the tool trajectory to maximize the sparse goal reward given by the environment. Second, we describe an imitation learning approach that focuses on the trajectory of the tool rather than the motion of the human. For this we combine reinforcement learning with an optimization procedure to find a control policy and the placement of the robot based on the tool motion in the aligned environment. We demonstrate the proposed approach on spade, scythe and hammer tools in simulation, and show the effectiveness of the trained policy for the spade on a real Franka Emika Panda robot demonstration.