 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLight Lies: Optical Adversarial Attack
Jul 14, 2021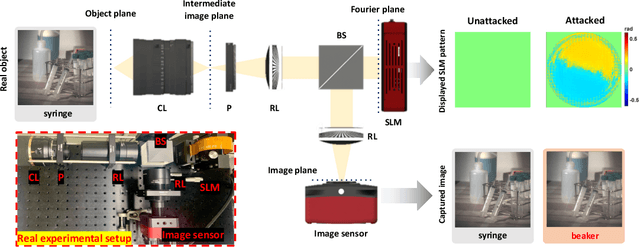

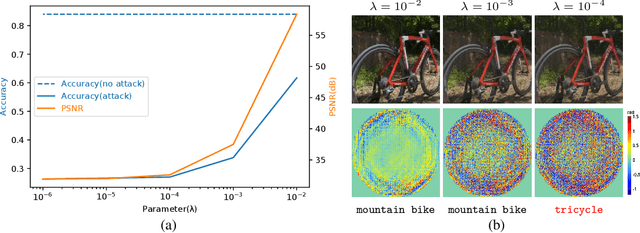
A significant amount of work has been done on adversarial attacks that inject imperceptible noise to images to deteriorate the image classification performance of deep models. However, most of the existing studies consider attacks in the digital (pixel) domain where an image acquired by an image sensor with sampling and quantization has been recorded. This paper, for the first time, introduces an optical adversarial attack, which physically alters the light field information arriving at the image sensor so that the classification model yields misclassification. More specifically, we modulate the phase of the light in the Fourier domain using a spatial light modulator placed in the photographic system. The operative parameters of the modulator are obtained by gradient-based optimization to maximize cross-entropy and minimize distortions. We present experiments based on both simulation and a real hardware optical system, from which the feasibility of the proposed optical attack is demonstrated. It is also verified that the proposed attack is completely different from common optical-domain distortions such as spherical aberration, defocus, and astigmatism in terms of both perturbation patterns and classification results.
Deep Image Destruction: A Comprehensive Study on Vulnerability of Deep Image-to-Image Models against Adversarial Attacks
Apr 30, 2021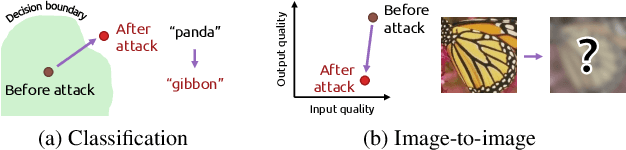
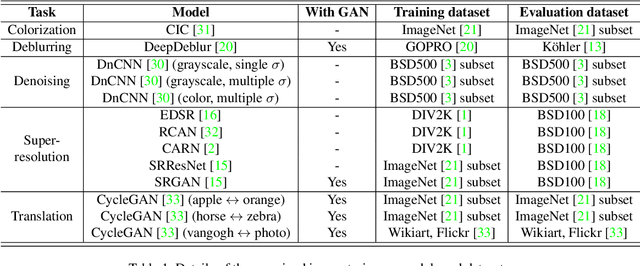
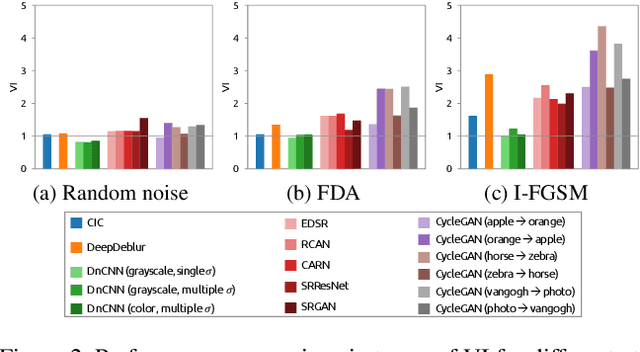

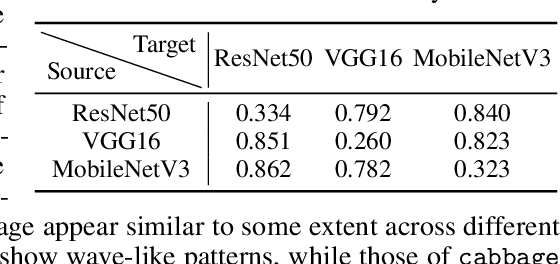
Recently, the vulnerability of deep image classification models to adversarial attacks has been investigated. However, such an issue has not been thoroughly studied for image-to-image models that can have different characteristics in quantitative evaluation, consequences of attacks, and defense strategy. To tackle this, we present comprehensive investigations into the vulnerability of deep image-to-image models to adversarial attacks. For five popular image-to-image tasks, 16 deep models are analyzed from various standpoints such as output quality degradation due to attacks, transferability of adversarial examples across different tasks, and characteristics of perturbations. We show that unlike in image classification tasks, the performance degradation on image-to-image tasks can largely differ depending on various factors, e.g., attack methods and task objectives. In addition, we analyze the effectiveness of conventional defense methods used for classification models in improving the robustness of the image-to-image models.
TREND: Truncated Generalized Normal Density Estimation of Inception Embeddings for Accurate GAN Evaluation
Apr 30, 2021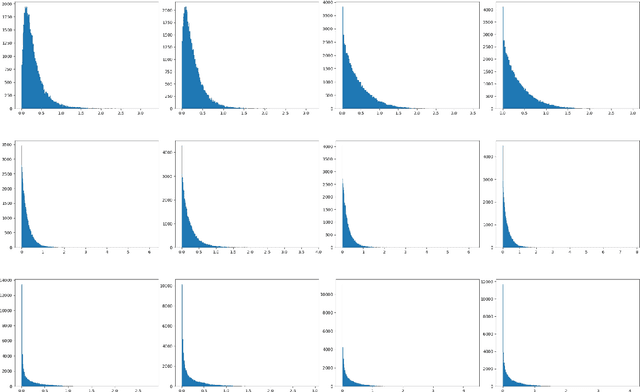
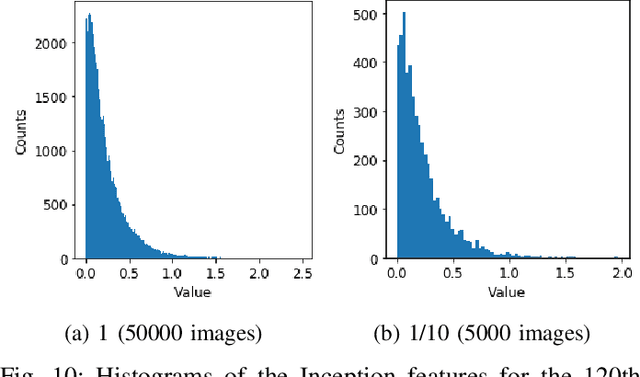

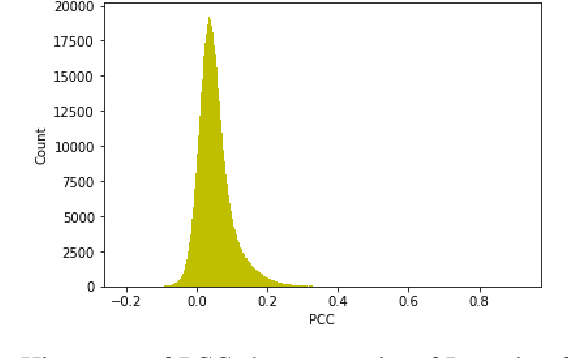
Evaluating image generation models such as generative adversarial networks (GANs) is a challenging problem. A common approach is to compare the distributions of the set of ground truth images and the set of generated test images. The Frech\'et Inception distance is one of the most widely used metrics for evaluation of GANs, which assumes that the features from a trained Inception model for a set of images follow a normal distribution. In this paper, we argue that this is an over-simplified assumption, which may lead to unreliable evaluation results, and more accurate density estimation can be achieved using a truncated generalized normal distribution. Based on this, we propose a novel metric for accurate evaluation of GANs, named TREND (TRuncated gEneralized Normal Density estimation of inception embeddings). We demonstrate that our approach significantly reduces errors of density estimation, which consequently eliminates the risk of faulty evaluation results. Furthermore, we show that the proposed metric significantly improves robustness of evaluation results against variation of the number of image samples.
Students are the Best Teacher: Exit-Ensemble Distillation with Multi-Exits
Apr 05, 2021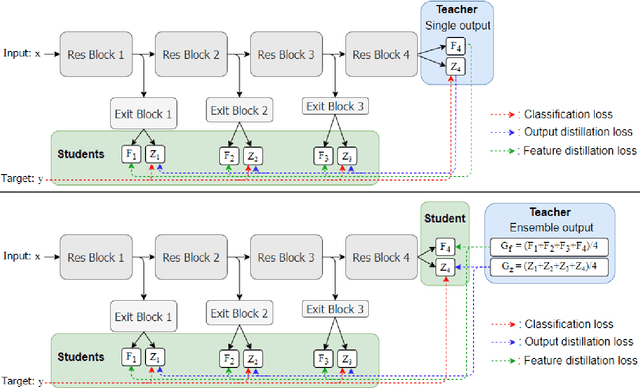
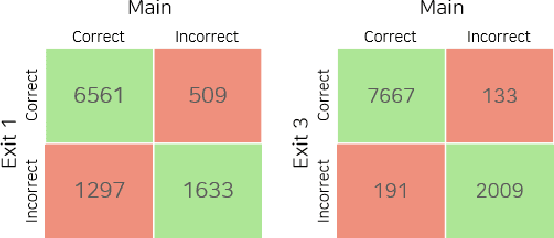
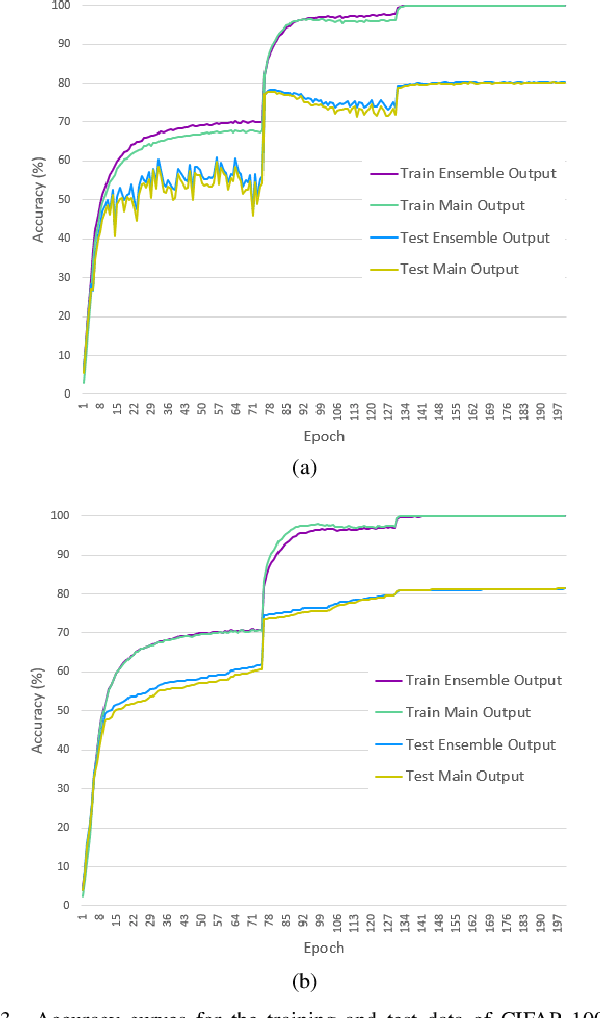
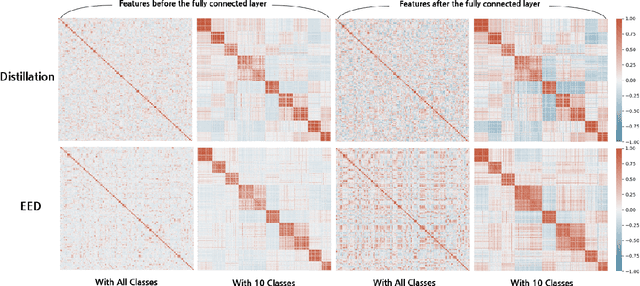
This paper proposes a novel knowledge distillation-based learning method to improve the classification performance of convolutional neural networks (CNNs) without a pre-trained teacher network, called exit-ensemble distillation. Our method exploits the multi-exit architecture that adds auxiliary classifiers (called exits) in the middle of a conventional CNN, through which early inference results can be obtained. The idea of our method is to train the network using the ensemble of the exits as the distillation target, which greatly improves the classification performance of the overall network. Our method suggests a new paradigm of knowledge distillation; unlike the conventional notion of distillation where teachers only teach students, we show that students can also help other students and even the teacher to learn better. Experimental results demonstrate that our method achieves significant improvement of classification performance on various popular CNN architectures (VGG, ResNet, ResNeXt, WideResNet, etc.). Furthermore, the proposed method can expedite the convergence of learning with improved stability. Our code will be available on Github.
Local Critic Training for Model-Parallel Learning of Deep Neural Networks
Feb 03, 2021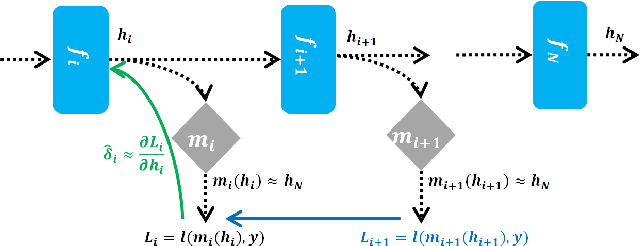
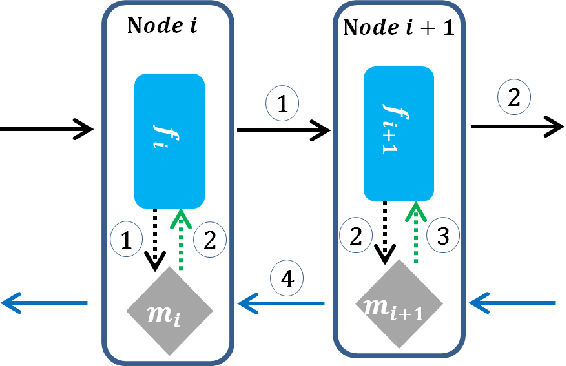
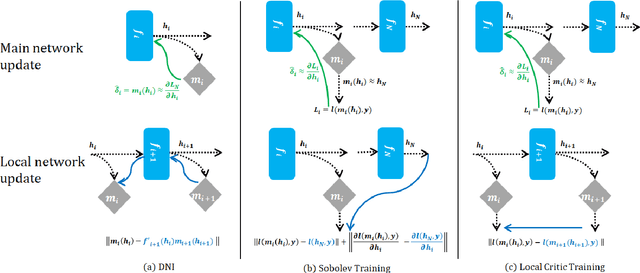
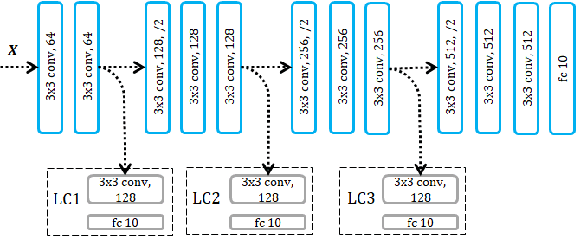
In this paper, we propose a novel model-parallel learning method, called local critic training, which trains neural networks using additional modules called local critic networks. The main network is divided into several layer groups and each layer group is updated through error gradients estimated by the corresponding local critic network. We show that the proposed approach successfully decouples the update process of the layer groups for both convolutional neural networks (CNNs) and recurrent neural networks (RNNs). In addition, we demonstrate that the proposed method is guaranteed to converge to a critical point. We also show that trained networks by the proposed method can be used for structural optimization. Experimental results show that our method achieves satisfactory performance, reduces training time greatly, and decreases memory consumption per machine. Code is available at https://github.com/hjdw2/Local-critic-training.
Wide Color Gamut Image Content Characterization: Method, Evaluation, and Applications
Jan 19, 2021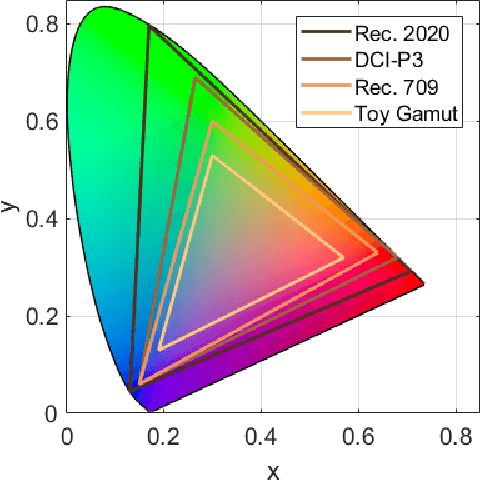
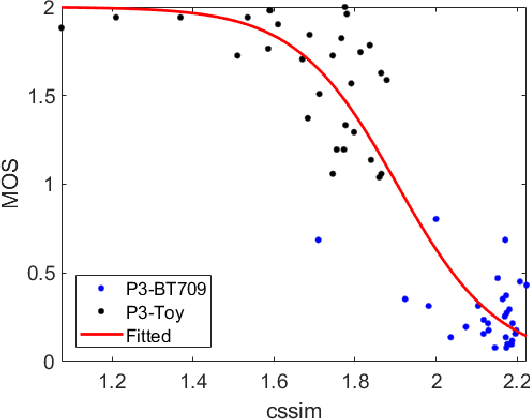
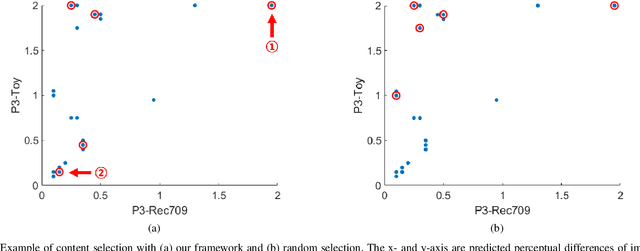

In this paper, we propose a novel framework to characterize a wide color gamut image content based on perceived quality due to the processes that change color gamut, and demonstrate two practical use cases where the framework can be applied. We first introduce the main framework and implementation details. Then, we provide analysis for understanding of existing wide color gamut datasets with quantitative characterization criteria on their characteristics, where four criteria, i.e., coverage, total coverage, uniformity, and total uniformity, are proposed. Finally, the framework is applied to content selection in a gamut mapping evaluation scenario in order to enhance reliability and robustness of the evaluation results. As a result, the framework fulfils content characterization for studies where quality of experience of wide color gamut stimuli is involved.
Ambiguity of Objective Image Quality Metrics: A New Methodology for Performance Evaluation
Jan 19, 2021
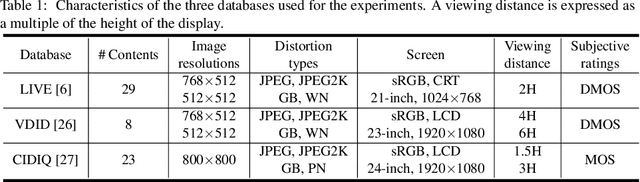
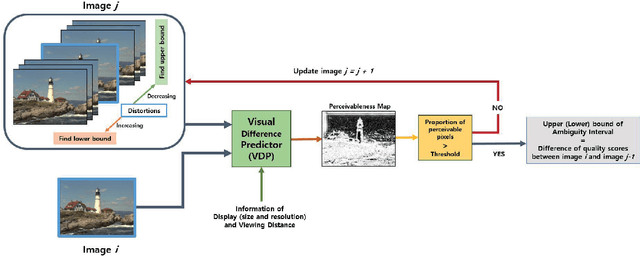
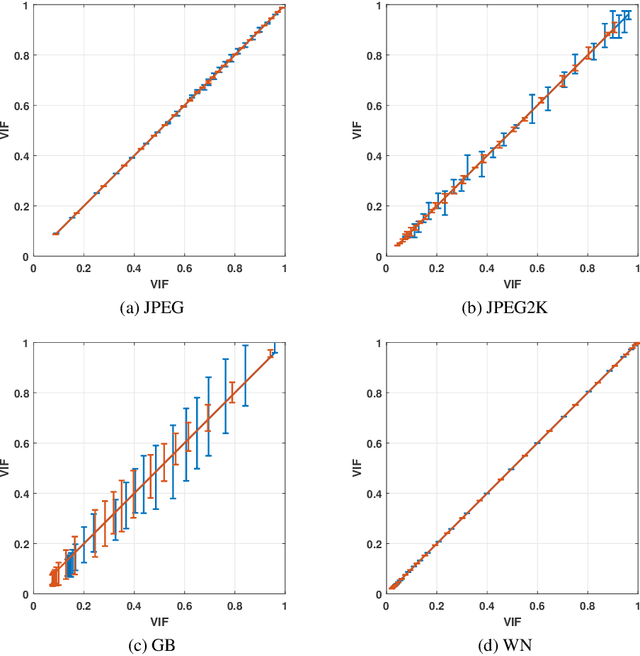
Objective image quality metrics try to estimate the perceptual quality of the given image by considering the characteristics of the human visual system. However, it is possible that the metrics produce different quality scores even for two images that are perceptually indistinguishable by human viewers, which have not been considered in the existing studies related to objective quality assessment. In this paper, we address the issue of ambiguity of objective image quality assessment. We propose an approach to obtain an ambiguity interval of an objective metric, within which the quality score difference is not perceptually significant. In particular, we use the visual difference predictor, which can consider viewing conditions that are important for visual quality perception. In order to demonstrate the usefulness of the proposed approach, we conduct experiments with 33 state-of-the-art image quality metrics in the viewpoint of their accuracy and ambiguity for three image quality databases. The results show that the ambiguity intervals can be applied as an additional figure of merit when conventional performance measurement does not determine superiority between the metrics. The effect of the viewing distance on the ambiguity interval is also shown.
Emotional EEG Classification using Connectivity Features and Convolutional Neural Networks
Jan 18, 2021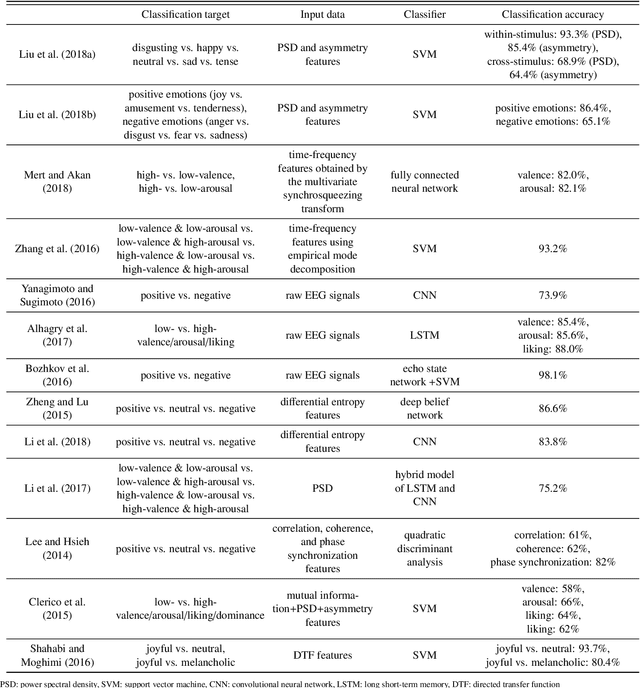
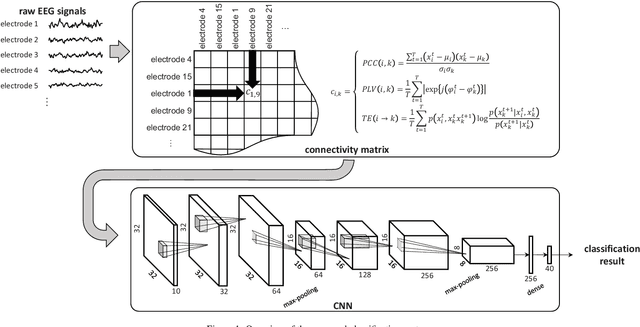
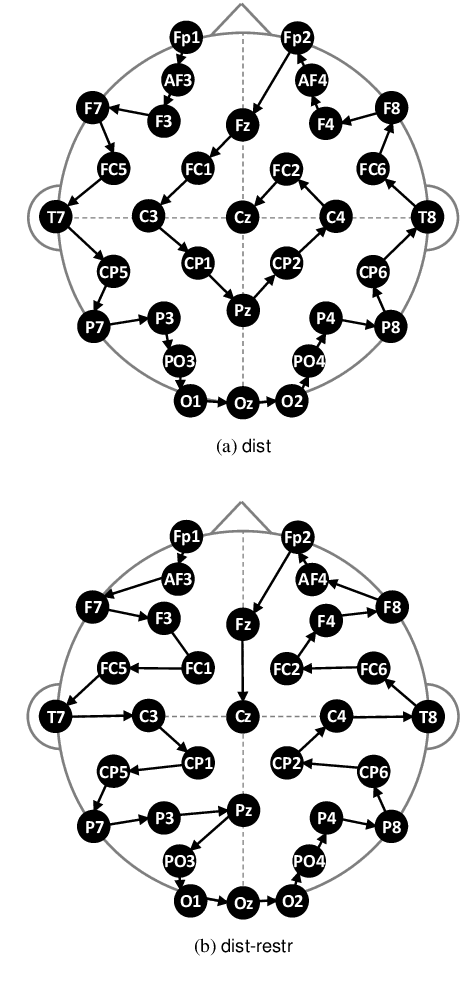
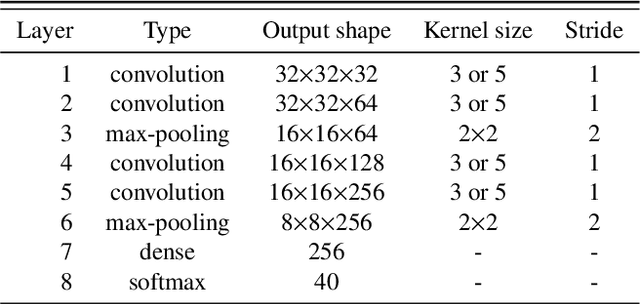
Convolutional neural networks (CNNs) are widely used to recognize the user's state through electroencephalography (EEG) signals. In the previous studies, the EEG signals are usually fed into the CNNs in the form of high-dimensional raw data. However, this approach makes it difficult to exploit the brain connectivity information that can be effective in describing the functional brain network and estimating the perceptual state of the user. We introduce a new classification system that utilizes brain connectivity with a CNN and validate its effectiveness via the emotional video classification by using three different types of connectivity measures. Furthermore, two data-driven methods to construct the connectivity matrix are proposed to maximize classification performance. Further analysis reveals that the level of concentration of the brain connectivity related to the emotional property of the target video is correlated with classification performance.
Just One Moment: Inconspicuous One Frame Attack on Deep Action Recognition
Nov 30, 2020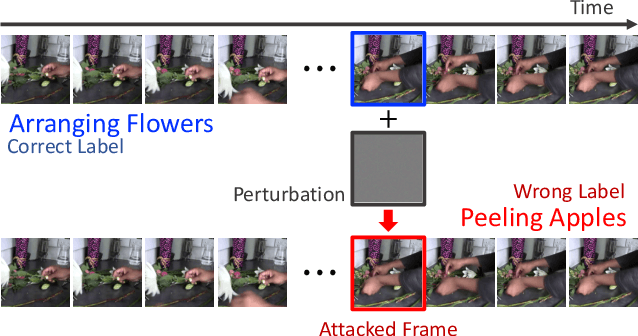
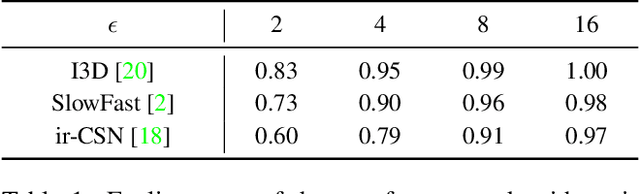
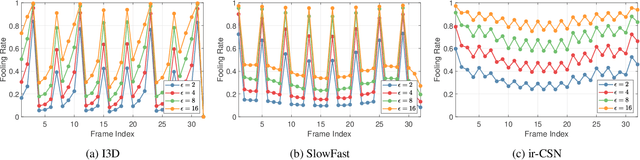
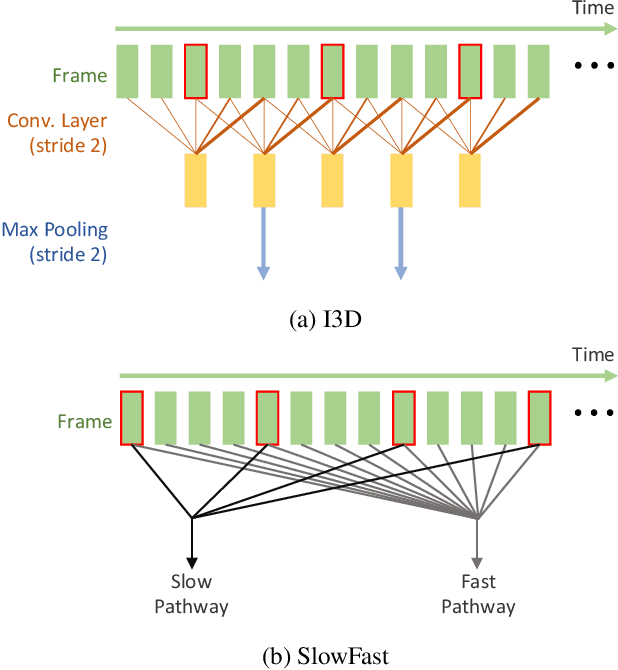
The video-based action recognition task has been extensively studied in recent years. In this paper, we study the vulnerability of deep learning-based action recognition methods against the adversarial attack using a new one frame attack that adds an inconspicuous perturbation to only a single frame of a given video clip. We investigate the effectiveness of our one frame attack on state-of-the-art action recognition models, along with thorough analysis of the vulnerability in terms of their model structure and perceivability of the perturbation. Our method shows high fooling rates and produces hardly perceivable perturbation to human observers, which is evaluated by a subjective test. In addition, we present a video-agnostic approach that finds a universal perturbation.
AIM 2020 Challenge on Real Image Super-Resolution: Methods and Results
Sep 25, 2020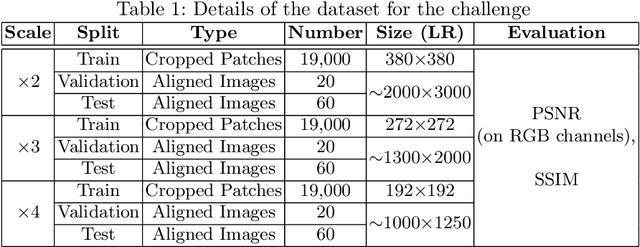
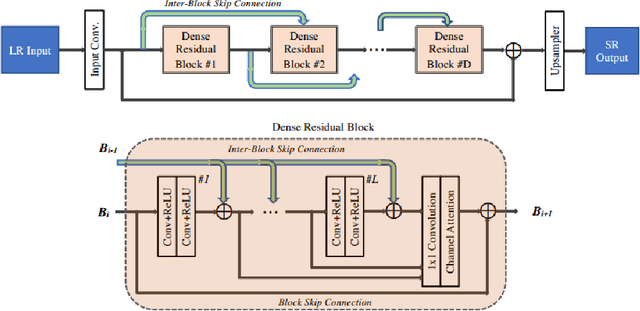
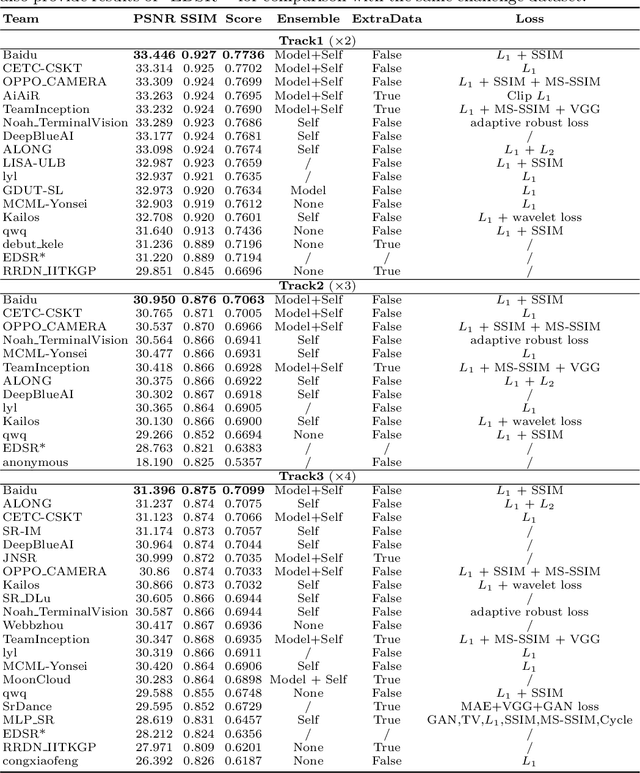
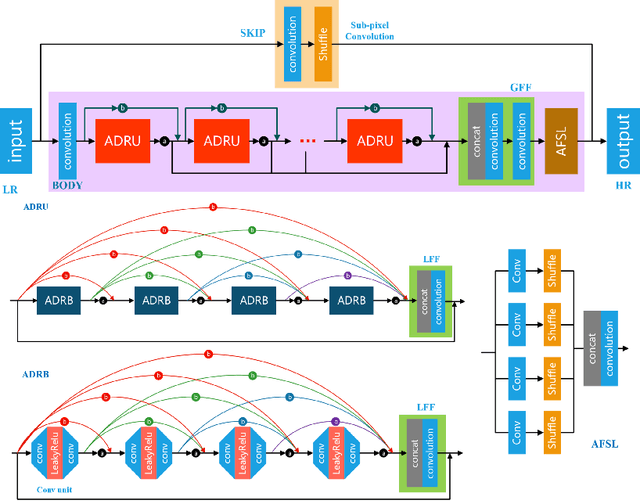
This paper introduces the real image Super-Resolution (SR) challenge that was part of the Advances in Image Manipulation (AIM) workshop, held in conjunction with ECCV 2020. This challenge involves three tracks to super-resolve an input image for $\times$2, $\times$3 and $\times$4 scaling factors, respectively. The goal is to attract more attention to realistic image degradation for the SR task, which is much more complicated and challenging, and contributes to real-world image super-resolution applications. 452 participants were registered for three tracks in total, and 24 teams submitted their results. They gauge the state-of-the-art approaches for real image SR in terms of PSNR and SSIM.