 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Implicit Volume Compression
May 18, 2020

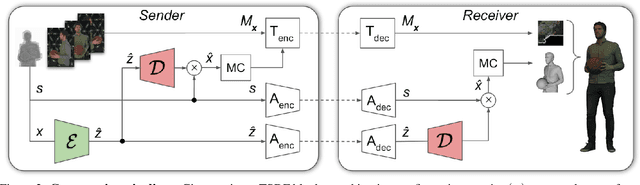
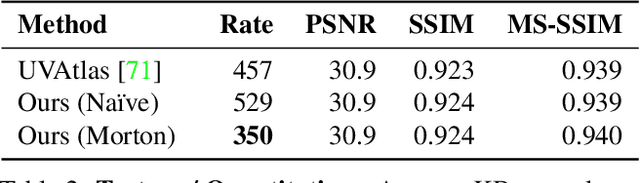
We describe a novel approach for compressing truncated signed distance fields (TSDF) stored in 3D voxel grids, and their corresponding textures. To compress the TSDF, our method relies on a block-based neural network architecture trained end-to-end, achieving state-of-the-art rate-distortion trade-off. To prevent topological errors, we losslessly compress the signs of the TSDF, which also upper bounds the reconstruction error by the voxel size. To compress the corresponding texture, we designed a fast block-based UV parameterization, generating coherent texture maps that can be effectively compressed using existing video compression algorithms. We demonstrate the performance of our algorithms on two 4D performance capture datasets, reducing bitrate by 66% for the same distortion, or alternatively reducing the distortion by 50% for the same bitrate, compared to the state-of-the-art.
Volumetric Capture of Humans with a Single RGBD Camera via Semi-Parametric Learning
May 29, 2019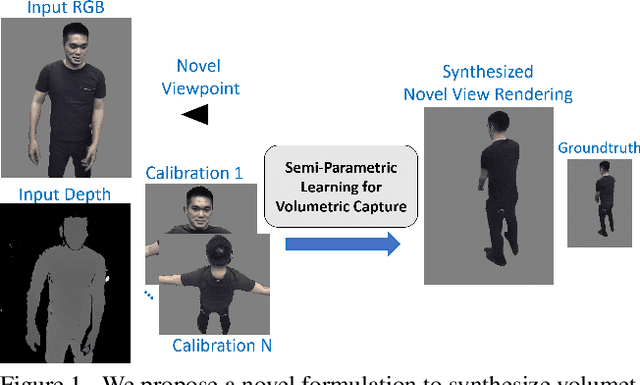

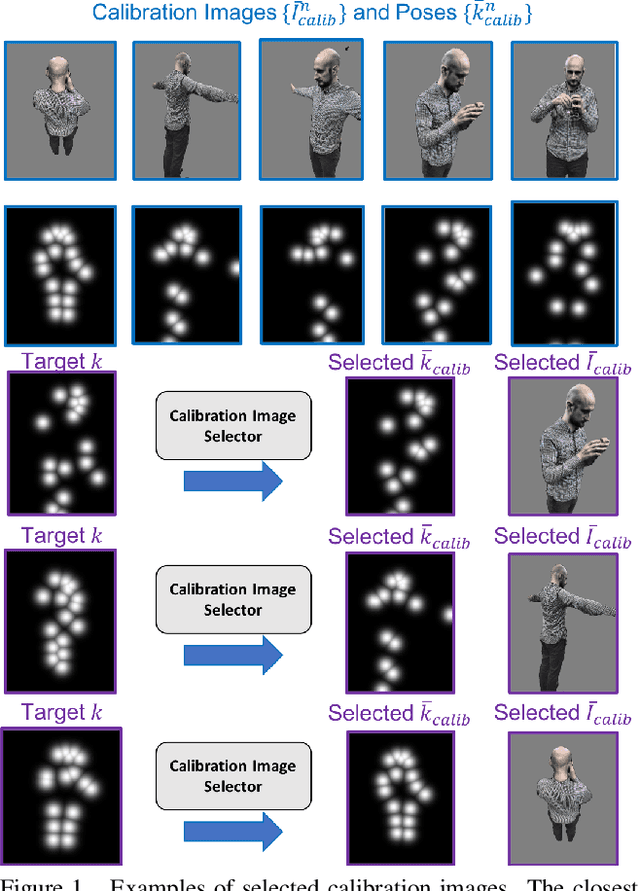
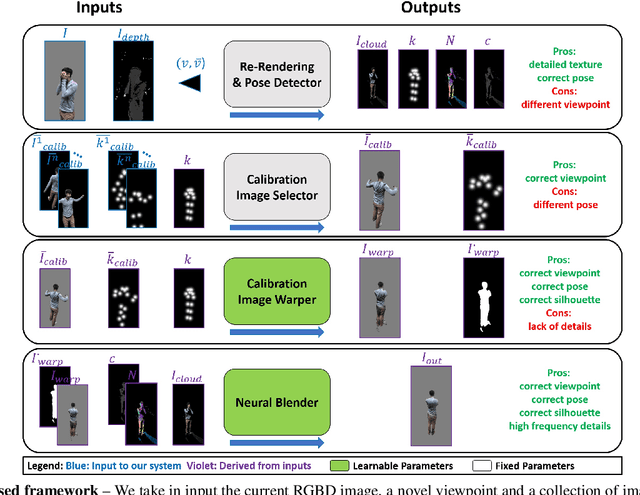
Volumetric (4D) performance capture is fundamental for AR/VR content generation. Whereas previous work in 4D performance capture has shown impressive results in studio settings, the technology is still far from being accessible to a typical consumer who, at best, might own a single RGBD sensor. Thus, in this work, we propose a method to synthesize free viewpoint renderings using a single RGBD camera. The key insight is to leverage previously seen "calibration" images of a given user to extrapolate what should be rendered in a novel viewpoint from the data available in the sensor. Given these past observations from multiple viewpoints, and the current RGBD image from a fixed view, we propose an end-to-end framework that fuses both these data sources to generate novel renderings of the performer. We demonstrate that the method can produce high fidelity images, and handle extreme changes in subject pose and camera viewpoints. We also show that the system generalizes to performers not seen in the training data. We run exhaustive experiments demonstrating the effectiveness of the proposed semi-parametric model (i.e. calibration images available to the neural network) compared to other state of the art machine learned solutions. Further, we compare the method with more traditional pipelines that employ multi-view capture. We show that our framework is able to achieve compelling results, with substantially less infrastructure than previously required.
LookinGood: Enhancing Performance Capture with Real-time Neural Re-Rendering
Nov 12, 2018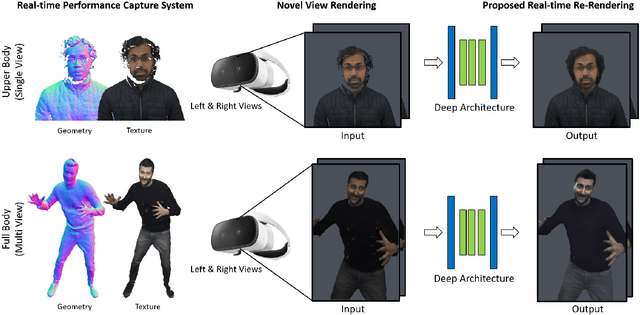



Motivated by augmented and virtual reality applications such as telepresence, there has been a recent focus in real-time performance capture of humans under motion. However, given the real-time constraint, these systems often suffer from artifacts in geometry and texture such as holes and noise in the final rendering, poor lighting, and low-resolution textures. We take the novel approach to augment such real-time performance capture systems with a deep architecture that takes a rendering from an arbitrary viewpoint, and jointly performs completion, super resolution, and denoising of the imagery in real-time. We call this approach neural (re-)rendering, and our live system "LookinGood". Our deep architecture is trained to produce high resolution and high quality images from a coarse rendering in real-time. First, we propose a self-supervised training method that does not require manual ground-truth annotation. We contribute a specialized reconstruction error that uses semantic information to focus on relevant parts of the subject, e.g. the face. We also introduce a salient reweighing scheme of the loss function that is able to discard outliers. We specifically design the system for virtual and augmented reality headsets where the consistency between the left and right eye plays a crucial role in the final user experience. Finally, we generate temporally stable results by explicitly minimizing the difference between two consecutive frames. We tested the proposed system in two different scenarios: one involving a single RGB-D sensor, and upper body reconstruction of an actor, the second consisting of full body 360 degree capture. Through extensive experimentation, we demonstrate how our system generalizes across unseen sequences and subjects. The supplementary video is available at http://youtu.be/Md3tdAKoLGU.
Why Adaptively Collected Data Have Negative Bias and How to Correct for It
Dec 30, 2017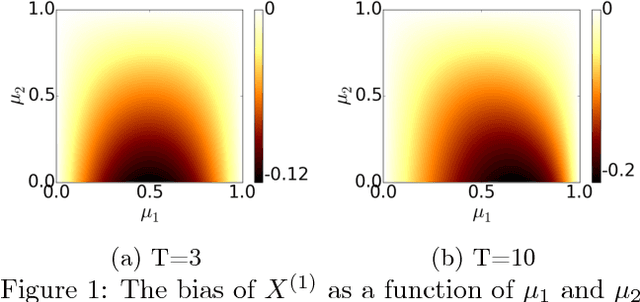
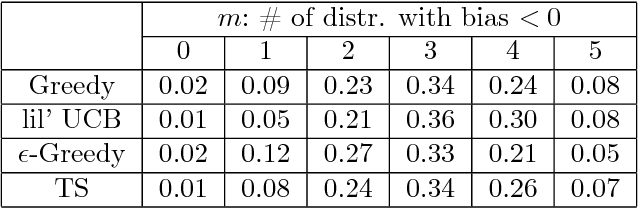
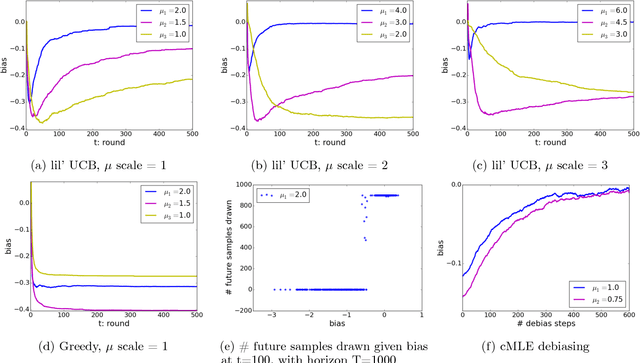
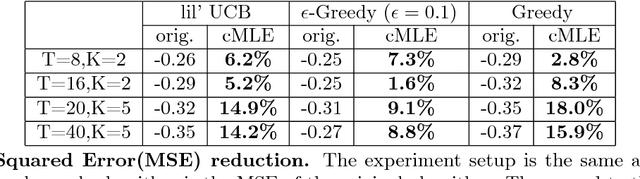
From scientific experiments to online A/B testing, the previously observed data often affects how future experiments are performed, which in turn affects which data will be collected. Such adaptivity introduces complex correlations between the data and the collection procedure. In this paper, we prove that when the data collection procedure satisfies natural conditions, then sample means of the data have systematic \emph{negative} biases. As an example, consider an adaptive clinical trial where additional data points are more likely to be tested for treatments that show initial promise. Our surprising result implies that the average observed treatment effects would underestimate the true effects of each treatment. We quantitatively analyze the magnitude and behavior of this negative bias in a variety of settings. We also propose a novel debiasing algorithm based on selective inference techniques. In experiments, our method can effectively reduce bias and estimation error.
Summary - TerpreT: A Probabilistic Programming Language for Program Induction
Dec 02, 2016
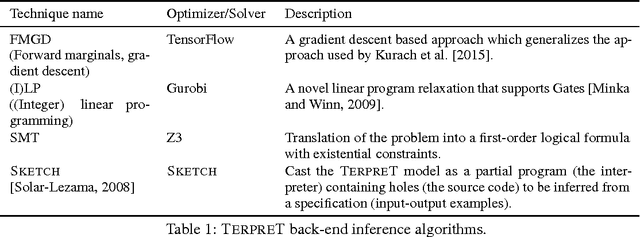
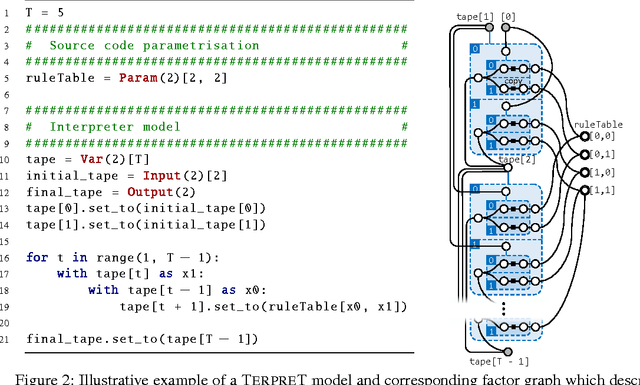
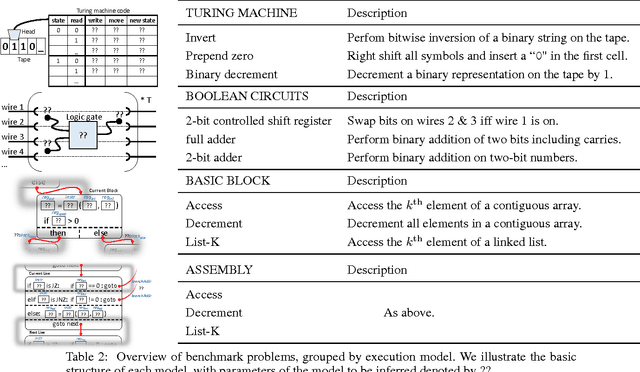
We study machine learning formulations of inductive program synthesis; that is, given input-output examples, synthesize source code that maps inputs to corresponding outputs. Our key contribution is TerpreT, a domain-specific language for expressing program synthesis problems. A TerpreT model is composed of a specification of a program representation and an interpreter that describes how programs map inputs to outputs. The inference task is to observe a set of input-output examples and infer the underlying program. From a TerpreT model we automatically perform inference using four different back-ends: gradient descent (thus each TerpreT model can be seen as defining a differentiable interpreter), linear program (LP) relaxations for graphical models, discrete satisfiability solving, and the Sketch program synthesis system. TerpreT has two main benefits. First, it enables rapid exploration of a range of domains, program representations, and interpreter models. Second, it separates the model specification from the inference algorithm, allowing proper comparisons between different approaches to inference. We illustrate the value of TerpreT by developing several interpreter models and performing an extensive empirical comparison between alternative inference algorithms on a variety of program models. To our knowledge, this is the first work to compare gradient-based search over program space to traditional search-based alternatives. Our key empirical finding is that constraint solvers dominate the gradient descent and LP-based formulations. This is a workshop summary of a longer report at arXiv:1608.04428
High-dimensional regression adjustments in randomized experiments
Oct 27, 2016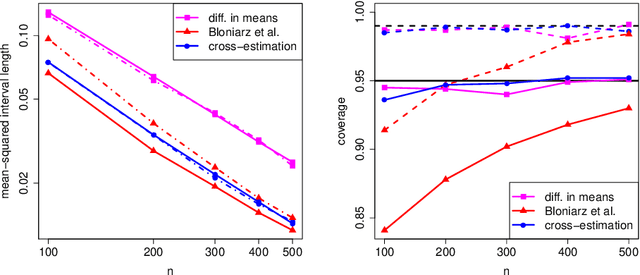
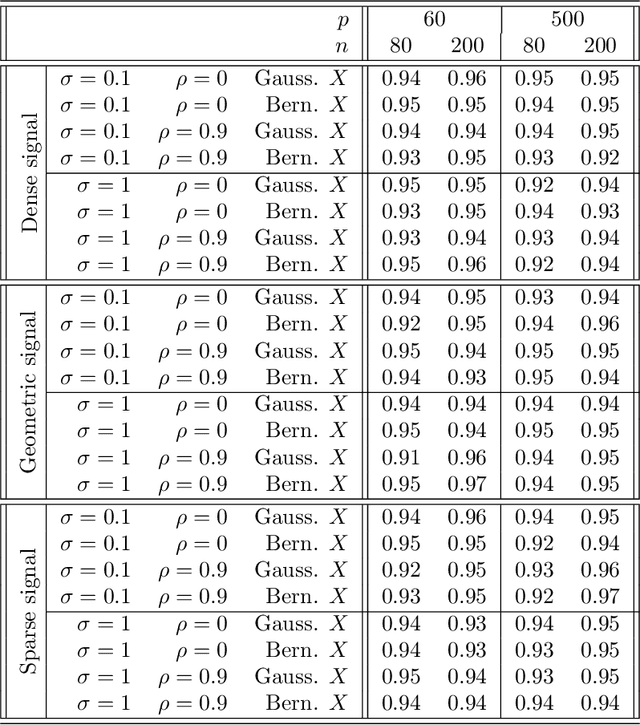
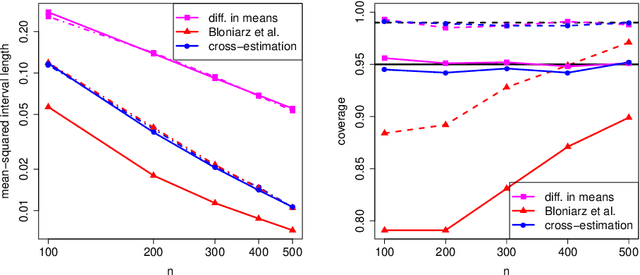
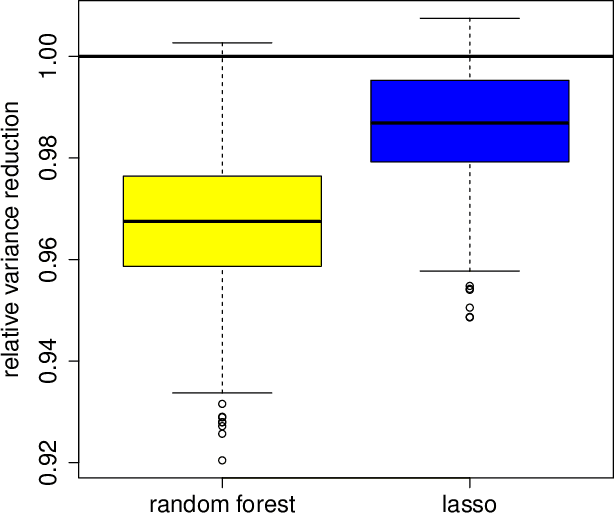
We study the problem of treatment effect estimation in randomized experiments with high-dimensional covariate information, and show that essentially any risk-consistent regression adjustment can be used to obtain efficient estimates of the average treatment effect. Our results considerably extend the range of settings where high-dimensional regression adjustments are guaranteed to provide valid inference about the population average treatment effect. We then propose cross-estimation, a simple method for obtaining finite-sample-unbiased treatment effect estimates that leverages high-dimensional regression adjustments. Our method can be used when the regression model is estimated using the lasso, the elastic net, subset selection, etc. Finally, we extend our analysis to allow for adaptive specification search via cross-validation, and flexible non-parametric regression adjustments with machine learning methods such as random forests or neural networks.
TerpreT: A Probabilistic Programming Language for Program Induction
Aug 15, 2016We study machine learning formulations of inductive program synthesis; given input-output examples, we try to synthesize source code that maps inputs to corresponding outputs. Our aims are to develop new machine learning approaches based on neural networks and graphical models, and to understand the capabilities of machine learning techniques relative to traditional alternatives, such as those based on constraint solving from the programming languages community. Our key contribution is the proposal of TerpreT, a domain-specific language for expressing program synthesis problems. TerpreT is similar to a probabilistic programming language: a model is composed of a specification of a program representation (declarations of random variables) and an interpreter describing how programs map inputs to outputs (a model connecting unknowns to observations). The inference task is to observe a set of input-output examples and infer the underlying program. TerpreT has two main benefits. First, it enables rapid exploration of a range of domains, program representations, and interpreter models. Second, it separates the model specification from the inference algorithm, allowing like-to-like comparisons between different approaches to inference. From a single TerpreT specification we automatically perform inference using four different back-ends. These are based on gradient descent, linear program (LP) relaxations for graphical models, discrete satisfiability solving, and the Sketch program synthesis system. We illustrate the value of TerpreT by developing several interpreter models and performing an empirical comparison between alternative inference algorithms. Our key empirical finding is that constraint solvers dominate the gradient descent and LP-based formulations. We conclude with suggestions for the machine learning community to make progress on program synthesis.
Selective Sequential Model Selection
Dec 08, 2015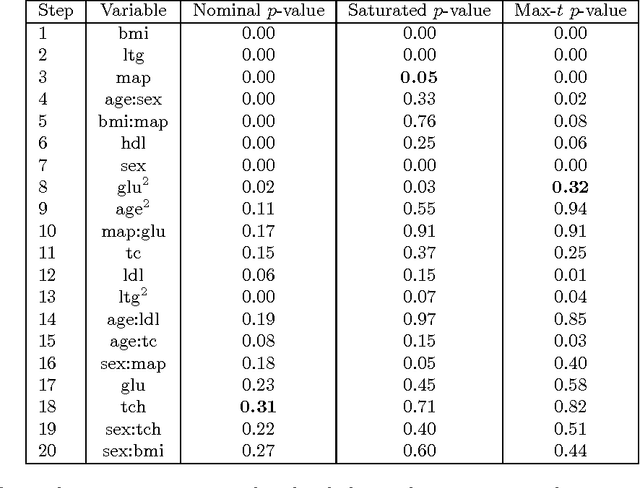
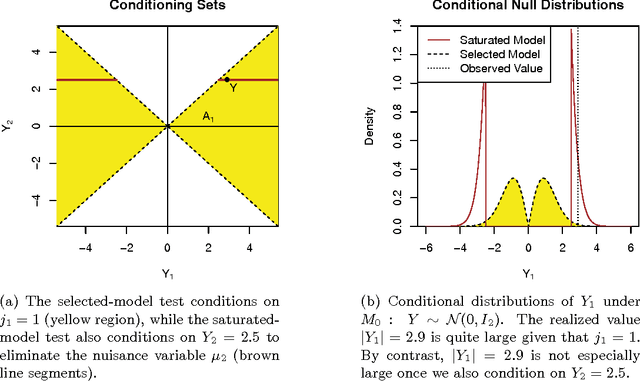
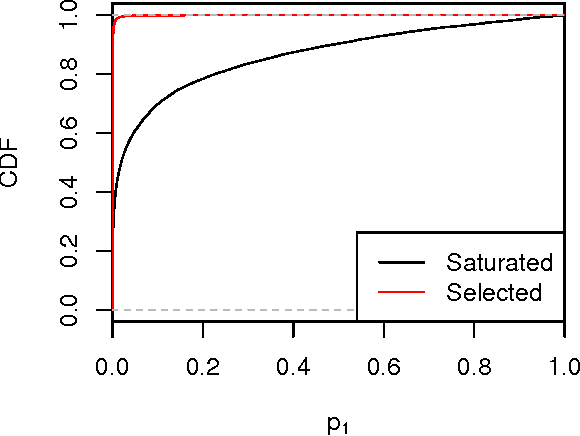
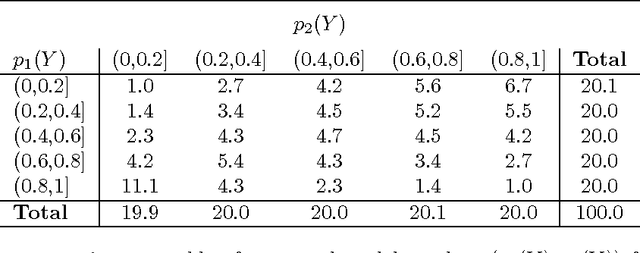
Many model selection algorithms produce a path of fits specifying a sequence of increasingly complex models. Given such a sequence and the data used to produce them, we consider the problem of choosing the least complex model that is not falsified by the data. Extending the selected-model tests of Fithian et al. (2014), we construct p-values for each step in the path which account for the adaptive selection of the model path using the data. In the case of linear regression, we propose two specific tests, the max-t test for forward stepwise regression (generalizing a proposal of Buja and Brown (2014)), and the next-entry test for the lasso. These tests improve on the power of the saturated-model test of Tibshirani et al. (2014), sometimes dramatically. In addition, our framework extends beyond linear regression to a much more general class of parametric and nonparametric model selection problems. To select a model, we can feed our single-step p-values as inputs into sequential stopping rules such as those proposed by G'Sell et al. (2013) and Li and Barber (2015), achieving control of the familywise error rate or false discovery rate (FDR) as desired. The FDR-controlling rules require the null p-values to be independent of each other and of the non-null p-values, a condition not satisfied by the saturated-model p-values of Tibshirani et al. (2014). We derive intuitive and general sufficient conditions for independence, and show that our proposed constructions yield independent p-values.
A lasso for hierarchical interactions
Jun 19, 2013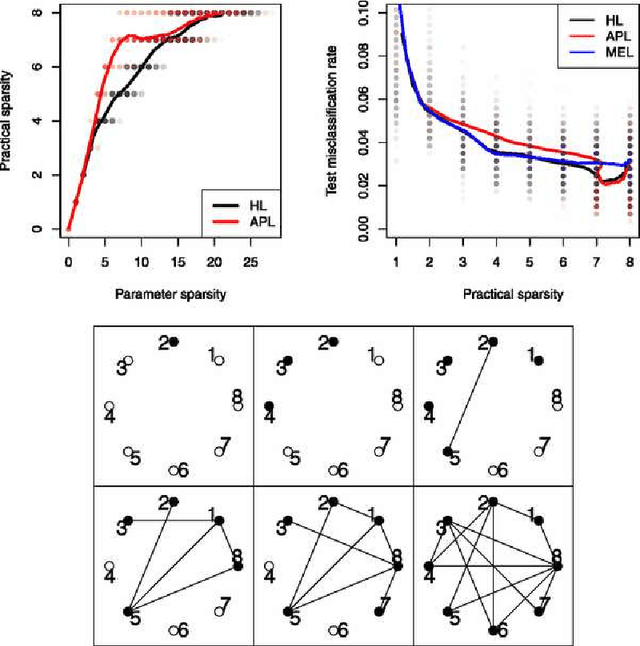
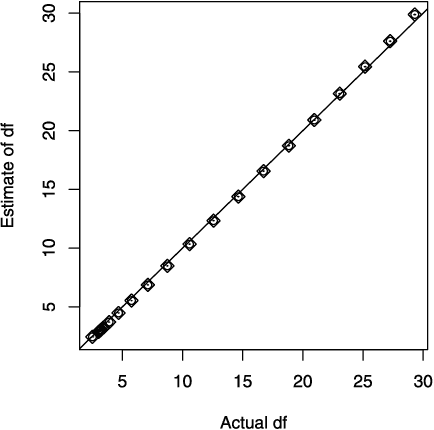
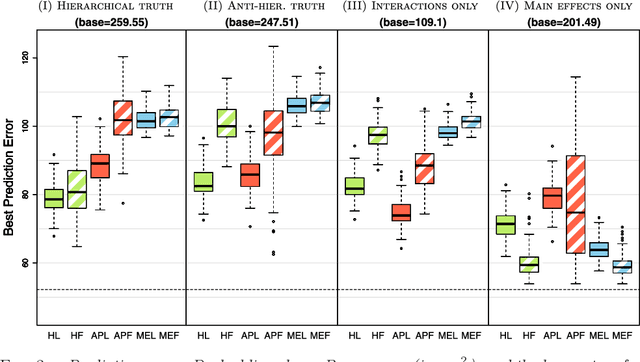
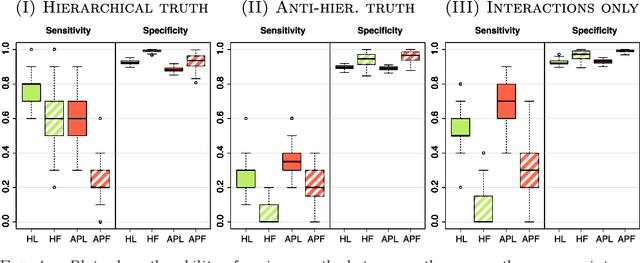
We add a set of convex constraints to the lasso to produce sparse interaction models that honor the hierarchy restriction that an interaction only be included in a model if one or both variables are marginally important. We give a precise characterization of the effect of this hierarchy constraint, prove that hierarchy holds with probability one and derive an unbiased estimate for the degrees of freedom of our estimator. A bound on this estimate reveals the amount of fitting "saved" by the hierarchy constraint. We distinguish between parameter sparsity - the number of nonzero coefficients - and practical sparsity - the number of raw variables one must measure to make a new prediction. Hierarchy focuses on the latter, which is more closely tied to important data collection concerns such as cost, time and effort. We develop an algorithm, available in the R package hierNet, and perform an empirical study of our method.
* Published in at http://dx.doi.org/10.1214/13-AOS1096 the Annals of Statistics (http://www.imstat.org/aos/) by the Institute of Mathematical Statistics (http://www.imstat.org)
A Generalized Least Squares Matrix Decomposition
Mar 13, 2012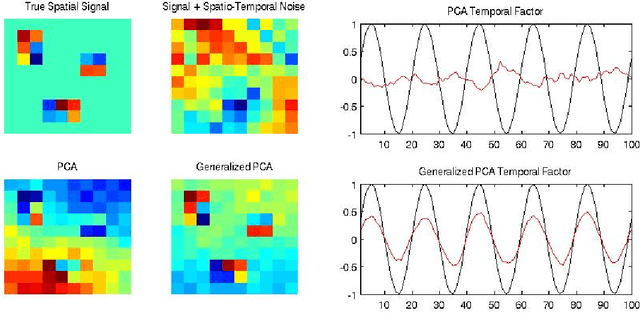
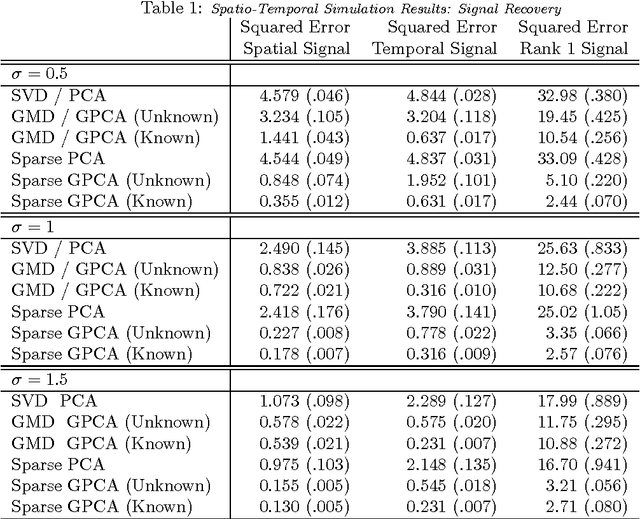
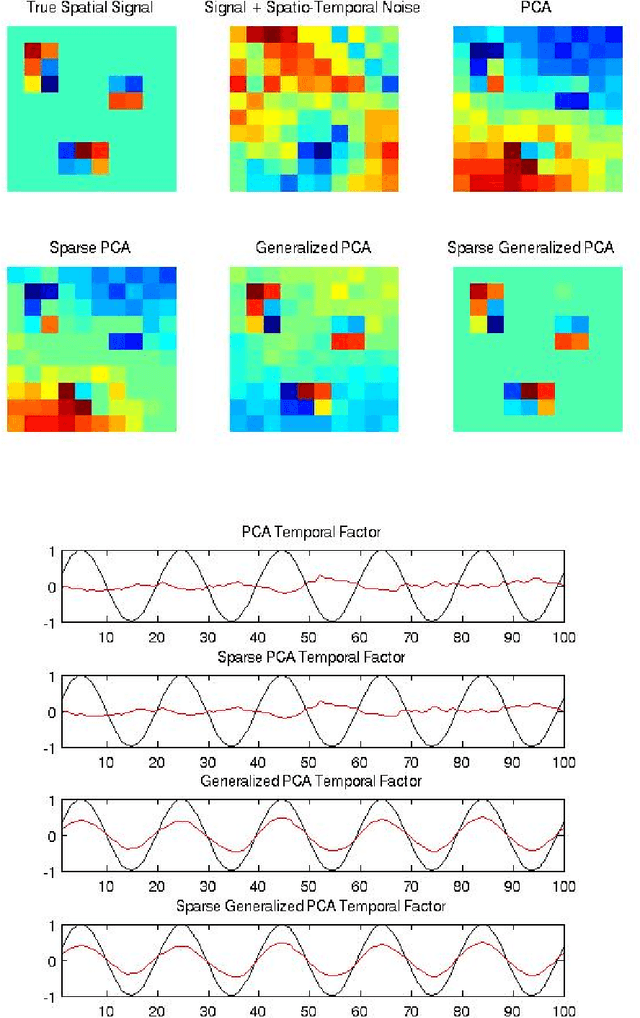
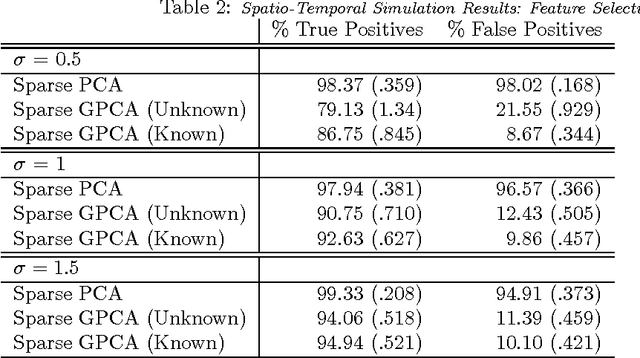
Variables in many massive high-dimensional data sets are structured, arising for example from measurements on a regular grid as in imaging and time series or from spatial-temporal measurements as in climate studies. Classical multivariate techniques ignore these structural relationships often resulting in poor performance. We propose a generalization of the singular value decomposition (SVD) and principal components analysis (PCA) that is appropriate for massive data sets with structured variables or known two-way dependencies. By finding the best low rank approximation of the data with respect to a transposable quadratic norm, our decomposition, entitled the Generalized least squares Matrix Decomposition (GMD), directly accounts for structural relationships. As many variables in high-dimensional settings are often irrelevant or noisy, we also regularize our matrix decomposition by adding two-way penalties to encourage sparsity or smoothness. We develop fast computational algorithms using our methods to perform generalized PCA (GPCA), sparse GPCA, and functional GPCA on massive data sets. Through simulations and a whole brain functional MRI example we demonstrate the utility of our methodology for dimension reduction, signal recovery, and feature selection with high-dimensional structured data.