 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGraffMatch: Global Matching of 3D Lines and Planes for Wide Baseline LiDAR Registration
Dec 24, 2022Using geometric landmarks like lines and planes can increase navigation accuracy and decrease map storage requirements compared to commonly-used LiDAR point cloud maps. However, landmark-based registration for applications like loop closure detection is challenging because a reliable initial guess is not available. Global landmark matching has been investigated in the literature, but these methods typically use ad hoc representations of 3D line and plane landmarks that are not invariant to large viewpoint changes, resulting in incorrect matches and high registration error. To address this issue, we adopt the affine Grassmannian manifold to represent 3D lines and planes and prove that the distance between two landmarks is invariant to rotation and translation if a shift operation is performed before applying the Grassmannian metric. This invariance property enables the use of our graph-based data association framework for identifying landmark matches that can subsequently be used for registration in the least-squares sense. Evaluated on a challenging landmark matching and registration task using publicly-available LiDAR datasets, our approach yields a 1.7x and 3.5x improvement in successful registrations compared to methods that use viewpoint-dependent centroid and "closest point" representations, respectively.
* accepted to RA-L; 8 pages. arXiv admin note: text overlap with arXiv:2205.08556
Mission-Aware Value of Information Censoring for Distributed Filtering
Nov 20, 2022In this paper, we study the problem of distributed estimation with an emphasis on communication-efficiency. The proposed algorithm is based on a windowed maximum a posteriori (MAP) estimation problem, wherein each agent in the network locally computes a Kalman-like filter estimate that approximates the centralized MAP solution. Information sharing among agents is restricted to their neighbors only, with guarantees on overall estimate consistency provided via logarithmic opinion pooling. The problem is efficiently distributed using the alternating direction method of multipliers (ADMM), whose overall communication usage is further reduced by a value of information (VoI) censoring mechanism, wherein agents only transmit their primal-dual iterates when deemed valuable to do so. The proposed censoring mechanism is mission-aware, enabling a globally efficient use of communication resources while guaranteeing possibly different local estimation requirements. To illustrate the validity of the approach we perform simulations in a target tracking scenario.
Game-Theoretical Perspectives on Active Equilibria: A Preferred Solution Concept over Nash Equilibria
Oct 28, 2022Multiagent learning settings are inherently more difficult than single-agent learning because each agent interacts with other simultaneously learning agents in a shared environment. An effective approach in multiagent reinforcement learning is to consider the learning process of agents and influence their future policies toward desirable behaviors from each agent's perspective. Importantly, if each agent maximizes its long-term rewards by accounting for the impact of its behavior on the set of convergence policies, the resulting multiagent system reaches an active equilibrium. While this new solution concept is general such that standard solution concepts, such as a Nash equilibrium, are special cases of active equilibria, it is unclear when an active equilibrium is a preferred equilibrium over other solution concepts. In this paper, we analyze active equilibria from a game-theoretic perspective by closely studying examples where Nash equilibria are known. By directly comparing active equilibria to Nash equilibria in these examples, we find that active equilibria find more effective solutions than Nash equilibria, concluding that an active equilibrium is the desired solution for multiagent learning settings.
Output Feedback Tube MPC-Guided Data Augmentation for Robust, Efficient Sensorimotor Policy Learning
Oct 18, 2022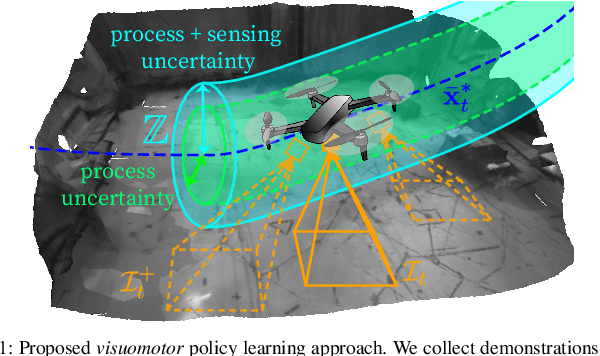

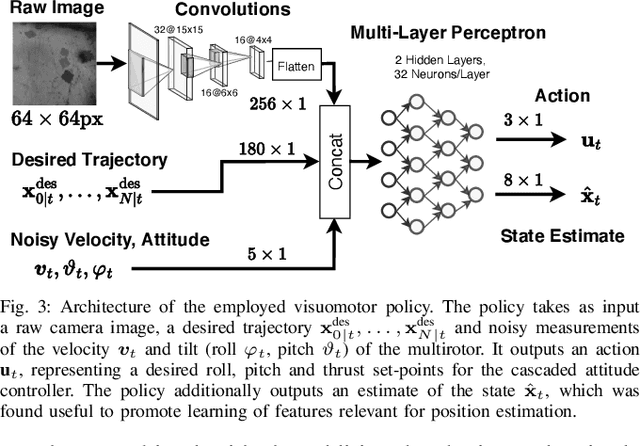
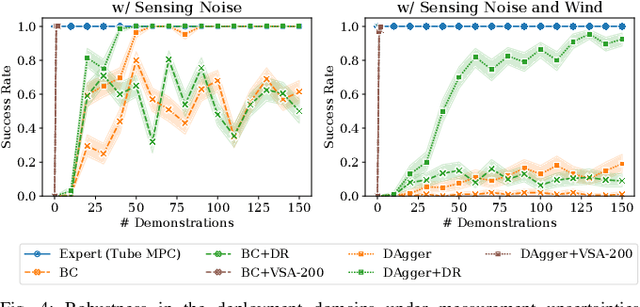
Imitation learning (IL) can generate computationally efficient sensorimotor policies from demonstrations provided by computationally expensive model-based sensing and control algorithms. However, commonly employed IL methods are often data-inefficient, requiring the collection of a large number of demonstrations and producing policies with limited robustness to uncertainties. In this work, we combine IL with an output feedback robust tube model predictive controller (RTMPC) to co-generate demonstrations and a data augmentation strategy to efficiently learn neural network-based sensorimotor policies. Thanks to the augmented data, we reduce the computation time and the number of demonstrations needed by IL, while providing robustness to sensing and process uncertainty. We tailor our approach to the task of learning a trajectory tracking visuomotor policy for an aerial robot, leveraging a 3D mesh of the environment as part of the data augmentation process. We numerically demonstrate that our method can learn a robust visuomotor policy from a single demonstration--a two-orders of magnitude improvement in demonstration efficiency compared to existing IL methods.
MIXER: Multiattribute, Multiway Fusion of Uncertain Pairwise Affinities
Oct 15, 2022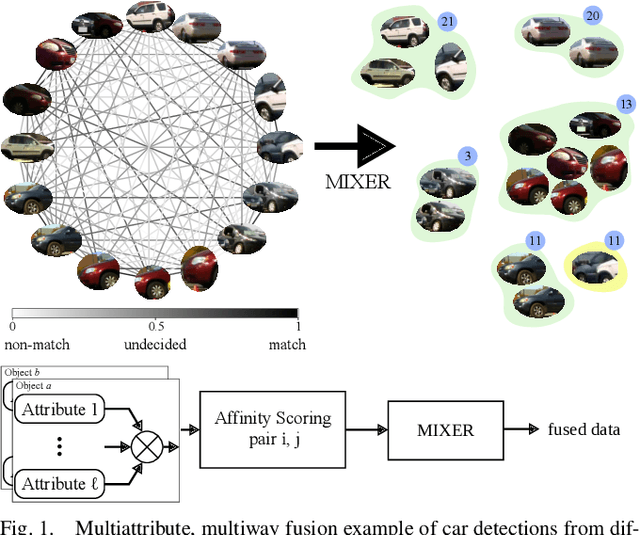
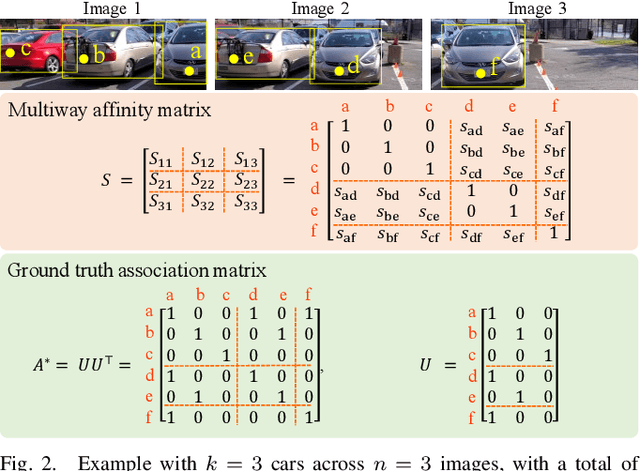
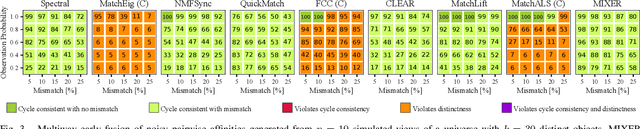
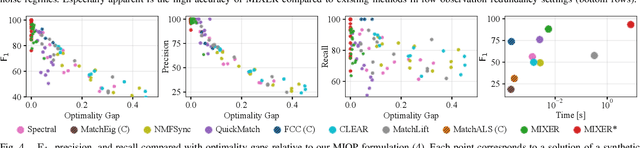
We present a multiway fusion algorithm capable of directly processing uncertain pairwise affinities. In contrast to existing works that require initial pairwise associations, our MIXER algorithm improves accuracy by leveraging the additional information provided by pairwise affinities. Our main contribution is a multiway fusion formulation that is particularly suited to processing non-binary affinities and a novel continuous relaxation whose solutions are guaranteed to be binary, thus avoiding the typical, but potentially problematic, solution binarization steps that may cause infeasibility. A crucial insight of our formulation is that it allows for three modes of association, ranging from non-match, undecided, and match. Exploiting this insight allows fusion to be delayed for some data pairs until more information is available, which is an effective feature for fusion of data with multiple attributes/information sources. We evaluate MIXER on typical synthetic data and benchmark datasets and show increased accuracy against the state of the art in multiway matching, especially in noisy regimes with low observation redundancy. Additionally, we collect RGB data of cars in a parking lot to demonstrate MIXER's ability to fuse data having multiple attributes (color, visual appearance, and bounding box). On this challenging dataset, MIXER achieves 74% F1 accuracy and is 49x faster than the next best algorithm, which has 42% accuracy.
A Hybrid Partitioning Strategy for Backward Reachability of Neural Feedback Loops
Oct 14, 2022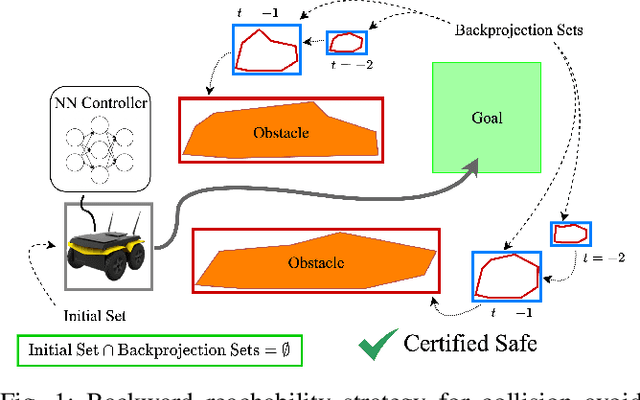
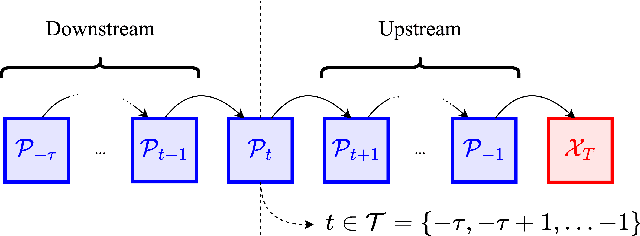
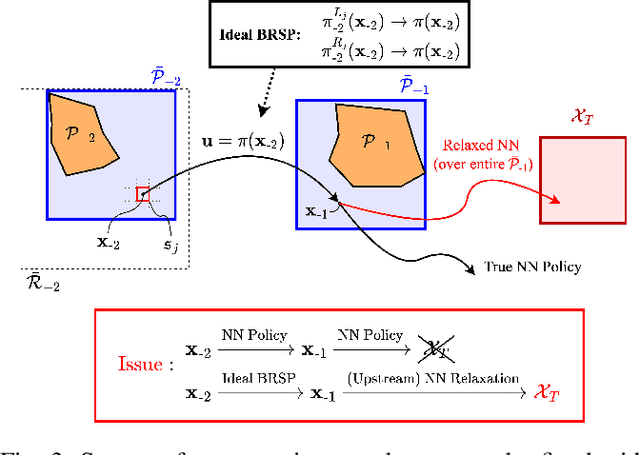
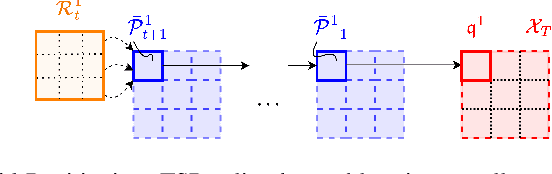
As neural networks become more integrated into the systems that we depend on for transportation, medicine, and security, it becomes increasingly important that we develop methods to analyze their behavior to ensure that they are safe to use within these contexts. The methods used in this paper seek to certify safety for closed-loop systems with neural network controllers, i.e., neural feedback loops, using backward reachability analysis. Namely, we calculate backprojection (BP) set over-approximations (BPOAs), i.e., sets of states that lead to a given target set that bounds dangerous regions of the state space. The system's safety can then be certified by checking its current state against the BPOAs. While over-approximating BPs is significantly faster than calculating exact BP sets, solving the relaxed problem leads to conservativeness. To combat conservativeness, partitioning strategies can be used to split the problem into a set of sub-problems, each less conservative than the unpartitioned problem. We introduce a hybrid partitioning method that uses both target set partitioning (TSP) and backreachable set partitioning (BRSP) to overcome a lower bound on estimation error that is present when using BRSP. Numerical results demonstrate a near order-of-magnitude reduction in estimation error compared to BRSP or TSP given the same computation time.
RAMP: A Risk-Aware Mapping and Planning Pipeline for Fast Off-Road Ground Robot Navigation
Oct 12, 2022
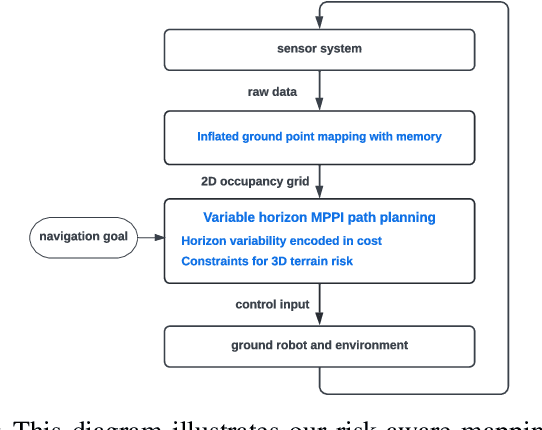

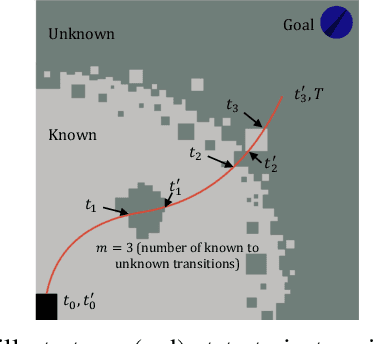
A key challenge in fast ground robot navigation in 3D terrain is balancing robot speed and safety. Recent work has shown that 2.5D maps (2D representations with additional 3D information) are ideal for real-time safe and fast planning. However, raytracing as a prevalent method of generating occupancy grid as the base 2D representation makes the generated map unsafe to plan in, due to inaccurate representation of unknown space. Additionally, existing planners such as MPPI do not reason about speeds in known free and unknown space separately, leading to slow plans. This work therefore first presents ground point inflation as a way to generate accurate occupancy grid maps from classified pointclouds. Then we present an MPPI-based planner with embedded variability in horizon, to maximize speed in known free space while retaining cautionary penetration into unknown space. Finally, we integrate this mapping and planning pipeline with risk constraints arising from 3D terrain, and verify that it enables fast and safe navigation using simulations and a hardware demonstration.
Spectral Sparsification for Communication-Efficient Collaborative Rotation and Translation Estimation
Oct 10, 2022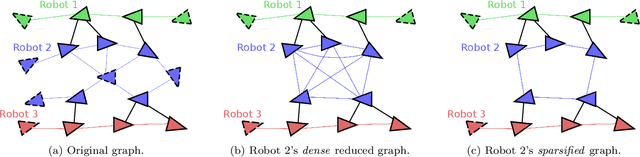
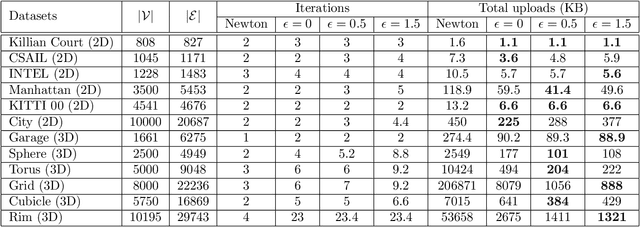
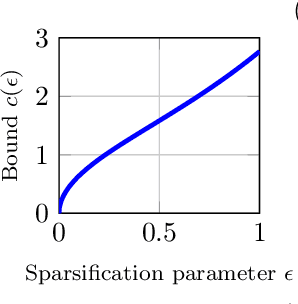
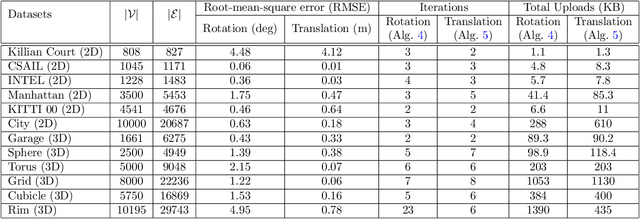
We propose fast and communication-efficient distributed algorithms for rotation averaging and translation recovery problems that arise from multi-robot simultaneous localization and mapping (SLAM) and distributed camera network localization applications. Our methods are based on theoretical relations between the Hessians of the underlying Riemannian optimization problems and the Laplacians of suitably weighted graphs. We leverage these results to design a distributed solver that performs approximate second-order optimization by solving a Laplacian system at each iteration. Crucially, our algorithms permit robots to employ spectral sparsification to sparsify intermediate dense matrices before communication, and hence provide a mechanism to trade off accuracy with communication efficiency with provable guarantees. We perform rigorous theoretical analysis of our methods and prove that they enjoy (local) linear rate of convergence on the problems of interest. Numerical experiments show that the proposed methods converge to high-precision solutions in a few iterations and that they are significantly more communication-efficient compared to baseline second-order solvers.
Robust MADER: Decentralized and Asynchronous Multiagent Trajectory Planner Robust to Communication Delay
Oct 06, 2022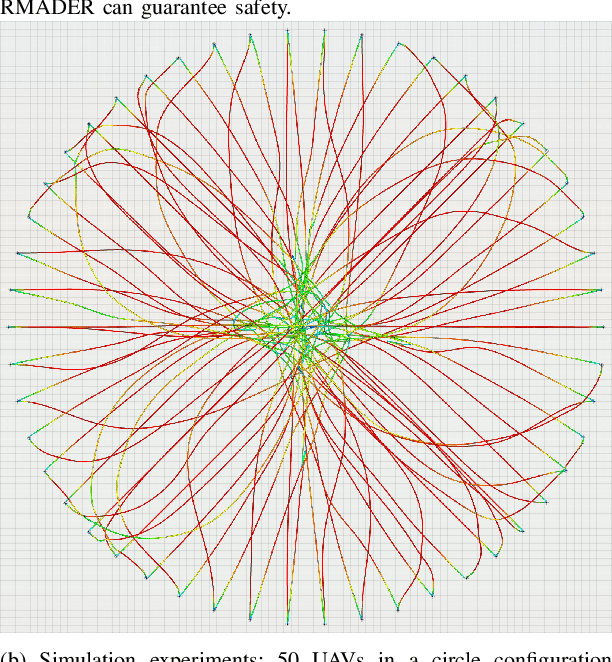
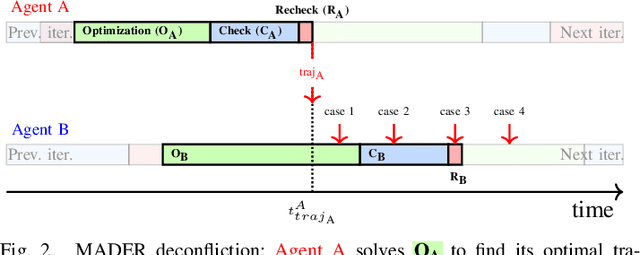
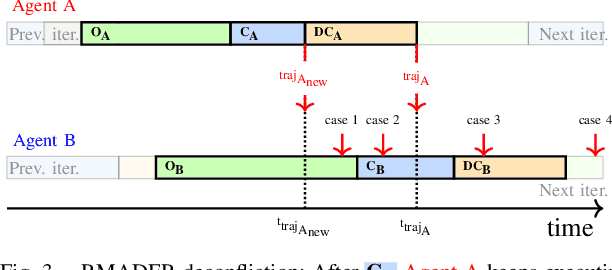
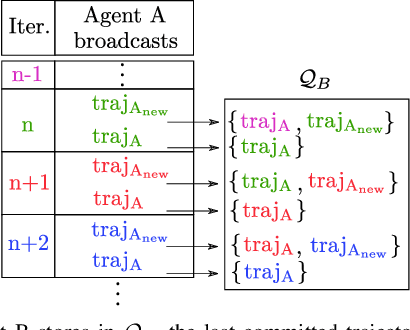
Although communication delays can disrupt multiagent systems, most of the existing multiagent trajectory planners lack a strategy to address this issue. State-of-the-art approaches typically assume perfect communication environments, which is hardly realistic in real-world experiments. This paper presents Robust MADER (RMADER), a decentralized and asynchronous multiagent trajectory planner that can handle communication delays among agents. By broadcasting both the newly optimized trajectory and the committed trajectory, and by performing a delay check step, RMADER is able to guarantee safety even under communication delay. RMADER was validated through extensive simulation and hardware flight experiments and achieved a 100% success rate of collision-free trajectory generation, outperforming state-of-the-art approaches.
Probabilistic Traversability Model for Risk-Aware Motion Planning in Off-Road Environments
Oct 01, 2022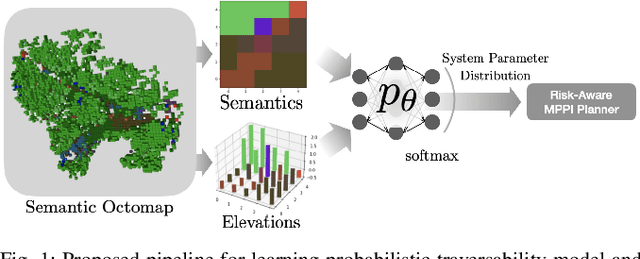
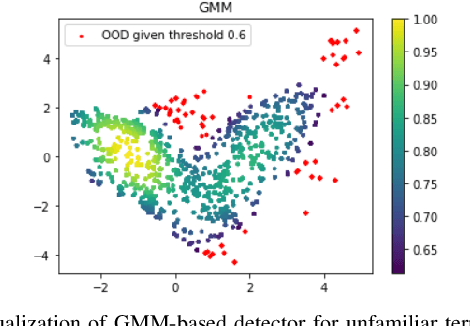
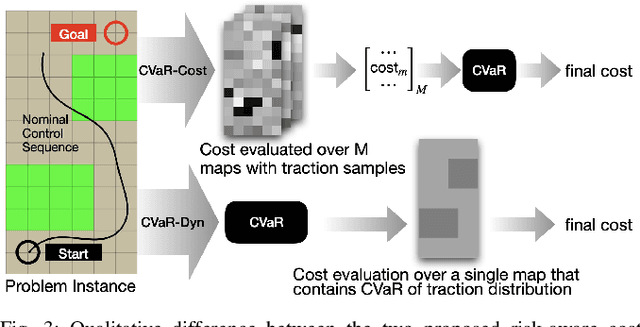
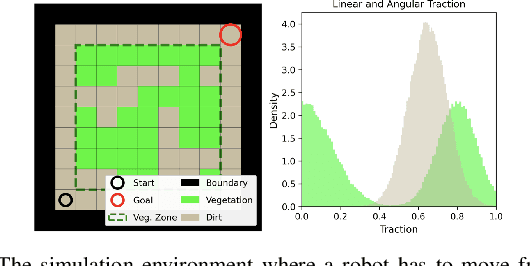
A key challenge in off-road navigation is that even visually similar or semantically identical terrain may have substantially different traction properties. Existing work typically assumes a nominal or expected robot dynamical model for planning, which can lead to degraded performance if the assumed models are not realizable given the terrain properties. In contrast, this work introduces a new probabilistic representation of traversability as a distribution of parameters in the robot's dynamical model that are conditioned on the terrain characteristics. This model is learned in a self-supervised manner by fitting a probability distribution over the parameters identified online, encoded as a neural network that takes terrain features as input. This work then presents two risk-aware planning algorithms that leverage the learned traversability model to plan risk-aware trajectories. Finally, a method for detecting unfamiliar terrain with respect to the training data is introduced based on a Gaussian Mixture Model fit to the latent space of the trained model. Experiments demonstrate that the proposed approach outperforms existing work that assumes nominal or expected robot dynamics in both success rate and completion time for representative navigation tasks. Furthermore, when the proposed approach is deployed in an unseen environment, excluding unfamiliar terrains during planning leads to improved success rate.