 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultiple Token Divergence: Measuring and Steering In-Context Computation Density
Dec 28, 2025Measuring the in-context computational effort of language models is a key challenge, as metrics like next-token loss fail to capture reasoning complexity. Prior methods based on latent state compressibility can be invasive and unstable. We propose Multiple Token Divergence (MTD), a simple measure of computational effort defined as the KL divergence between a model's full output distribution and that of a shallow, auxiliary prediction head. MTD can be computed directly from pre-trained models with multiple prediction heads, requiring no additional training. Building on this, we introduce Divergence Steering, a novel decoding method to control the computational character of generated text. We empirically show that MTD is more effective than prior methods at distinguishing complex tasks from simple ones. On mathematical reasoning benchmarks, MTD correlates positively with problem difficulty. Lower MTD is associated with more accurate reasoning. MTD provides a practical, lightweight tool for analyzing and steering the computational dynamics of language models.
RADLADS: Rapid Attention Distillation to Linear Attention Decoders at Scale
May 07, 2025We present Rapid Attention Distillation to Linear Attention Decoders at Scale (RADLADS), a protocol for rapidly converting softmax attention transformers into linear attention decoder models, along with two new RWKV-variant architectures, and models converted from popular Qwen2.5 open source models in 7B, 32B, and 72B sizes. Our conversion process requires only 350-700M tokens, less than 0.005% of the token count used to train the original teacher models. Converting to our 72B linear attention model costs less than \$2,000 USD at today's prices, yet quality at inference remains close to the original transformer. These models achieve state-of-the-art downstream performance across a set of standard benchmarks for linear attention models of their size. We release all our models on HuggingFace under the Apache 2.0 license, with the exception of our 72B models which are also governed by the Qwen License Agreement. Models at https://huggingface.co/collections/recursal/radlads-6818ee69e99e729ba8a87102 Training Code at https://github.com/recursal/RADLADS-paper
RWKV-7 "Goose" with Expressive Dynamic State Evolution
Mar 18, 2025We present RWKV-7 "Goose", a new sequence modeling architecture, along with pre-trained language models that establish a new state-of-the-art in downstream performance at the 3 billion parameter scale on multilingual tasks, and match current SoTA English language performance despite being trained on dramatically fewer tokens than other top 3B models. Nevertheless, RWKV-7 models require only constant memory usage and constant inference time per token. RWKV-7 introduces a newly generalized formulation of the delta rule with vector-valued gating and in-context learning rates, as well as a relaxed value replacement rule. We show that RWKV-7 can perform state tracking and recognize all regular languages, while retaining parallelizability of training. This exceeds the capabilities of Transformers under standard complexity conjectures, which are limited to $\mathsf{TC}^0$. To demonstrate RWKV-7's language modeling capability, we also present an extended open source 3.1 trillion token multilingual corpus, and train four RWKV-7 models ranging from 0.19 billion to 2.9 billion parameters on this dataset. To foster openness, reproduction, and adoption, we release our models and dataset component listing at https://huggingface.co/RWKV, and our training and inference code at https://github.com/RWKV/RWKV-LM all under the Apache 2.0 License.
GoldFinch: High Performance RWKV/Transformer Hybrid with Linear Pre-Fill and Extreme KV-Cache Compression
Jul 16, 2024



We introduce GoldFinch, a hybrid Linear Attention/Transformer sequence model that uses a new technique to efficiently generate a highly compressed and reusable KV-Cache in linear time and space with respect to sequence length. GoldFinch stacks our new GOLD transformer on top of an enhanced version of the Finch (RWKV-6) architecture. We train up to 1.5B parameter class models of the Finch, Llama, and GoldFinch architectures, and find dramatically improved modeling performance relative to both Finch and Llama. Our cache size savings increase linearly with model layer count, ranging from 756-2550 times smaller than the traditional transformer cache for common sizes, enabling inference of extremely large context lengths even on limited hardware. Although autoregressive generation has O(n) time complexity per token because of attention, pre-fill computation of the entire initial cache state for a submitted context costs only O(1) time per token due to the use of a recurrent neural network (RNN) to generate this cache. We release our trained weights and training code under the Apache 2.0 license for community use.
Uni-Mol Docking V2: Towards Realistic and Accurate Binding Pose Prediction
May 20, 2024



In recent years, machine learning (ML) methods have emerged as promising alternatives for molecular docking, offering the potential for high accuracy without incurring prohibitive computational costs. However, recent studies have indicated that these ML models may overfit to quantitative metrics while neglecting the physical constraints inherent in the problem. In this work, we present Uni-Mol Docking V2, which demonstrates a remarkable improvement in performance, accurately predicting the binding poses of 77+% of ligands in the PoseBusters benchmark with an RMSD value of less than 2.0 {\AA}, and 75+% passing all quality checks. This represents a significant increase from the 62% achieved by the previous Uni-Mol Docking model. Notably, our Uni-Mol Docking approach generates chemically accurate predictions, circumventing issues such as chirality inversions and steric clashes that have plagued previous ML models. Furthermore, we observe enhanced performance in terms of high-quality predictions (RMSD values of less than 1.0 {\AA} and 1.5 {\AA}) and physical soundness when Uni-Mol Docking is combined with more physics-based methods like Uni-Dock. Our results represent a significant advancement in the application of artificial intelligence for scientific research, adopting a holistic approach to ligand docking that is well-suited for industrial applications in virtual screening and drug design. The code, data and service for Uni-Mol Docking are publicly available for use and further development in https://github.com/dptech-corp/Uni-Mol.
Eagle and Finch: RWKV with Matrix-Valued States and Dynamic Recurrence
Apr 10, 2024



We present Eagle (RWKV-5) and Finch (RWKV-6), sequence models improving upon the RWKV (RWKV-4) architecture. Our architectural design advancements include multi-headed matrix-valued states and a dynamic recurrence mechanism that improve expressivity while maintaining the inference efficiency characteristics of RNNs. We introduce a new multilingual corpus with 1.12 trillion tokens and a fast tokenizer based on greedy matching for enhanced multilinguality. We trained four Eagle models, ranging from 0.46 to 7.5 billion parameters, and two Finch models with 1.6 and 3.1 billion parameters and find that they achieve competitive performance across a wide variety of benchmarks. We release all our models on HuggingFace under the Apache 2.0 license. Models at: https://huggingface.co/RWKV Training code at: https://github.com/RWKV/RWKV-LM Inference code at: https://github.com/RWKV/ChatRWKV Time-parallel training code at: https://github.com/RWKV/RWKV-infctx-trainer
RWKV: Reinventing RNNs for the Transformer Era
May 22, 2023



Transformers have revolutionized almost all natural language processing (NLP) tasks but suffer from memory and computational complexity that scales quadratically with sequence length. In contrast, recurrent neural networks (RNNs) exhibit linear scaling in memory and computational requirements but struggle to match the same performance as Transformers due to limitations in parallelization and scalability. We propose a novel model architecture, Receptance Weighted Key Value (RWKV), that combines the efficient parallelizable training of Transformers with the efficient inference of RNNs. Our approach leverages a linear attention mechanism and allows us to formulate the model as either a Transformer or an RNN, which parallelizes computations during training and maintains constant computational and memory complexity during inference, leading to the first non-transformer architecture to be scaled to tens of billions of parameters. Our experiments reveal that RWKV performs on par with similarly sized Transformers, suggesting that future work can leverage this architecture to create more efficient models. This work presents a significant step towards reconciling the trade-offs between computational efficiency and model performance in sequence processing tasks.
Improving Graph Property Prediction with Generalized Readout Functions
Sep 21, 2020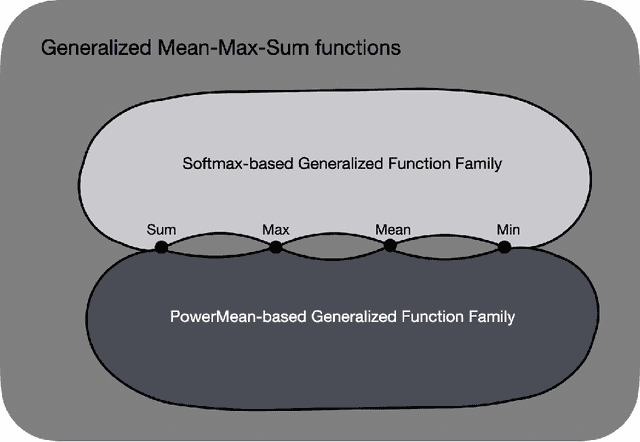
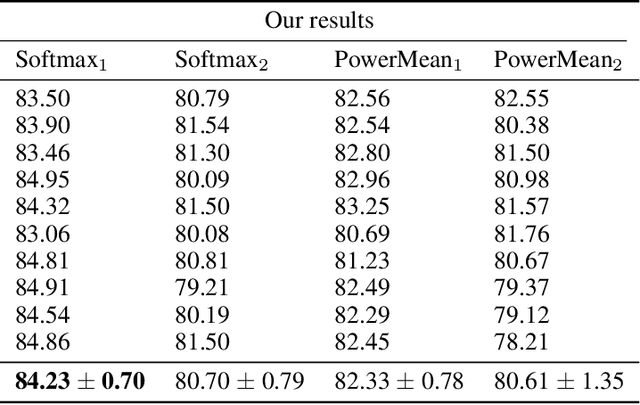

Graph property prediction is drawing increasing attention in the recent years due to the fact that graphs are one of the most general data structures since they can contain an arbitrary number of nodes and connections between them, and it is the backbone for many different tasks like classification and regression on such kind of data (networks, molecules, knowledge bases, ...). We introduce a novel generalized global pooling layer to mitigate the information loss that typically occurs at the Readout phase in Message-Passing Neural Networks. This novel layer is parametrized by two values ($\beta$ and $p$) which can optionally be learned, and the transformation it performs can revert to several already popular readout functions (mean, max and sum) under certain settings, which can be specified. To showcase the superior expressiveness and performance of this novel technique, we test it in a popular graph property prediction task by taking the current best-performing architecture and using our readout layer as a drop-in replacement and we report new state of the art results. The code to reproduce the experiments can be accessed here: https://github.com/EricAlcaide/generalized-readout-phase
E-swish: Adjusting Activations to Different Network Depths
Jan 22, 2018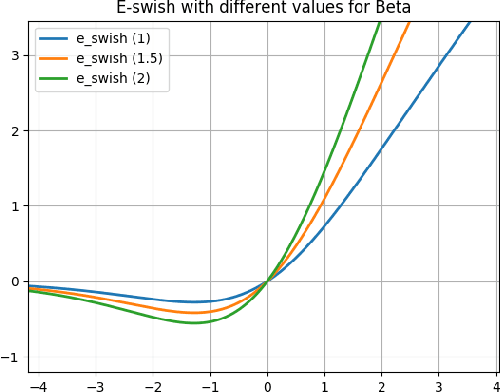

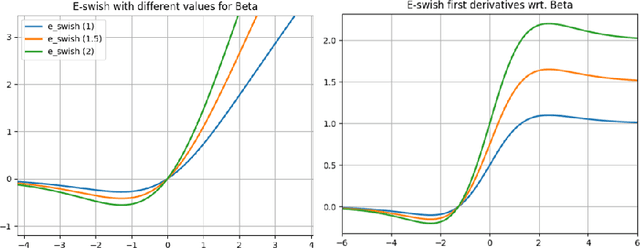

Activation functions have a notorious impact on neural networks on both training and testing the models against the desired problem. Currently, the most used activation function is the Rectified Linear Unit (ReLU). This paper introduces a new and novel activation function, closely related with the new activation $Swish = x * sigmoid(x)$ (Ramachandran et al., 2017) which generalizes it. We call the new activation $E-swish = \beta x * sigmoid(x)$. We show that E-swish outperforms many other well-known activations including both ReLU and Swish. For example, using E-swish provided 1.5% and 4.6% accuracy improvements on Cifar10 and Cifar100 respectively for the WRN 10-2 when compared to ReLU and 0.35% and 0.6% respectively when compared to Swish. The code to reproduce all our experiments can be found at https://github.com/EricAlcaide/E-swish