 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Long-Text Understanding with Short-Text Models
Aug 01, 2022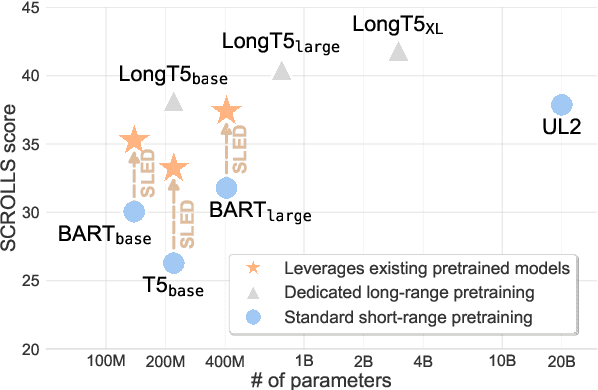
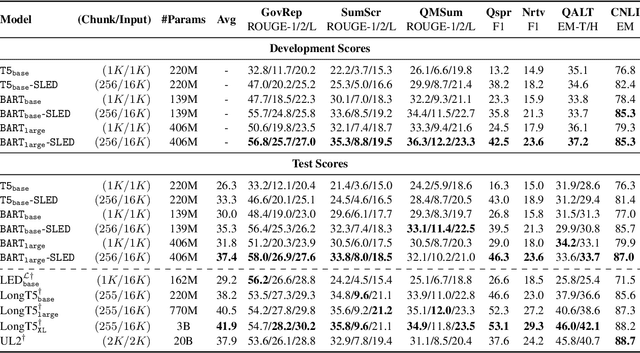
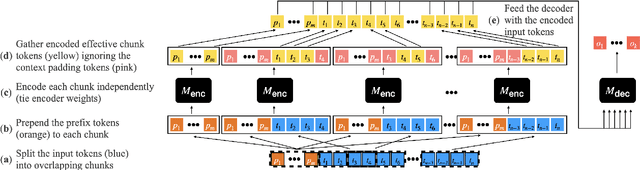
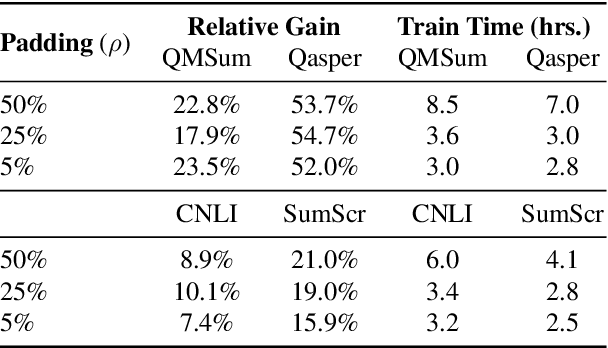
Transformer-based pretrained language models (LMs) are ubiquitous across natural language understanding, but cannot be applied to long sequences such as stories, scientific articles and long documents, due to their quadratic complexity. While a myriad of efficient transformer variants have been proposed, they are typically based on custom implementations that require expensive pretraining from scratch. In this work, we propose SLED: SLiding-Encoder and Decoder, a simple approach for processing long sequences that re-uses and leverages battle-tested short-text pretrained LMs. Specifically, we partition the input into overlapping chunks, encode each with a short-text LM encoder and use the pretrained decoder to fuse information across chunks (fusion-in-decoder). We illustrate through controlled experiments that SLED offers a viable strategy for long text understanding and evaluate our approach on SCROLLS, a benchmark with seven datasets across a wide range of language understanding tasks. We find that SLED is competitive with specialized models that are up to 50x larger and require a dedicated and expensive pretraining step.
Beyond the Imitation Game: Quantifying and extrapolating the capabilities of language models
Jun 10, 2022Language models demonstrate both quantitative improvement and new qualitative capabilities with increasing scale. Despite their potentially transformative impact, these new capabilities are as yet poorly characterized. In order to inform future research, prepare for disruptive new model capabilities, and ameliorate socially harmful effects, it is vital that we understand the present and near-future capabilities and limitations of language models. To address this challenge, we introduce the Beyond the Imitation Game benchmark (BIG-bench). BIG-bench currently consists of 204 tasks, contributed by 442 authors across 132 institutions. Task topics are diverse, drawing problems from linguistics, childhood development, math, common-sense reasoning, biology, physics, social bias, software development, and beyond. BIG-bench focuses on tasks that are believed to be beyond the capabilities of current language models. We evaluate the behavior of OpenAI's GPT models, Google-internal dense transformer architectures, and Switch-style sparse transformers on BIG-bench, across model sizes spanning millions to hundreds of billions of parameters. In addition, a team of human expert raters performed all tasks in order to provide a strong baseline. Findings include: model performance and calibration both improve with scale, but are poor in absolute terms (and when compared with rater performance); performance is remarkably similar across model classes, though with benefits from sparsity; tasks that improve gradually and predictably commonly involve a large knowledge or memorization component, whereas tasks that exhibit "breakthrough" behavior at a critical scale often involve multiple steps or components, or brittle metrics; social bias typically increases with scale in settings with ambiguous context, but this can be improved with prompting.
QAMPARI: : An Open-domain Question Answering Benchmark for Questions with Many Answers from Multiple Paragraphs
May 26, 2022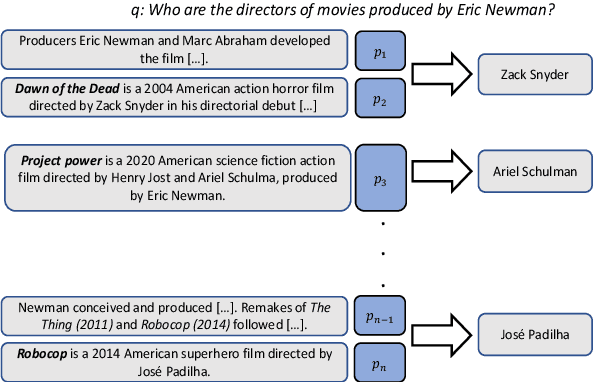

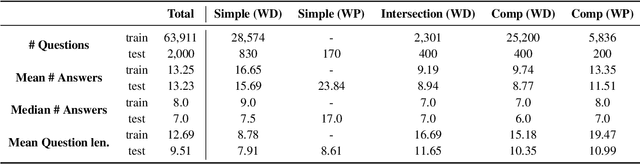
Existing benchmarks for open-domain question answering (ODQA) typically focus on questions whose answers can be extracted from a single paragraph. By contrast, many natural questions, such as "What players were drafted by the Brooklyn Nets?" have a list of answers. Answering such questions requires retrieving and reading from many passages, in a large corpus. We introduce QAMPARI, an ODQA benchmark, where question answers are lists of entities, spread across many paragraphs. We created QAMPARI by (a) generating questions with multiple answers from Wikipedia's knowledge graph and tables, (b) automatically pairing answers with supporting evidence in Wikipedia paragraphs, and (c) manually paraphrasing questions and validating each answer. We train ODQA models from the retrieve-and-read family and find that QAMPARI is challenging in terms of both passage retrieval and answer generation, reaching an F1 score of 26.6 at best. Our results highlight the need for developing ODQA models that handle a broad range of question types, including single and multi-answer questions.
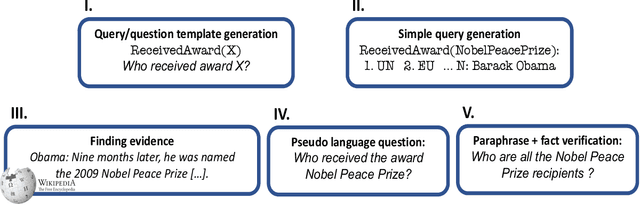
Inferring Implicit Relations with Language Models
Apr 28, 2022
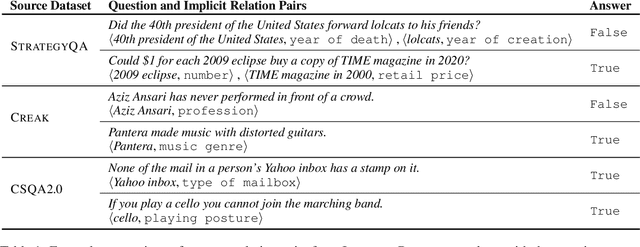
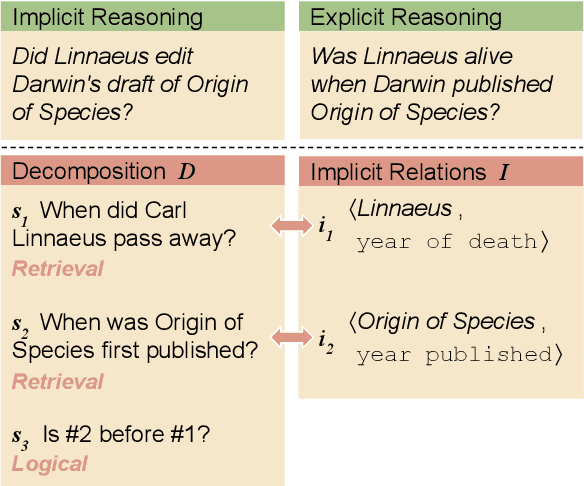
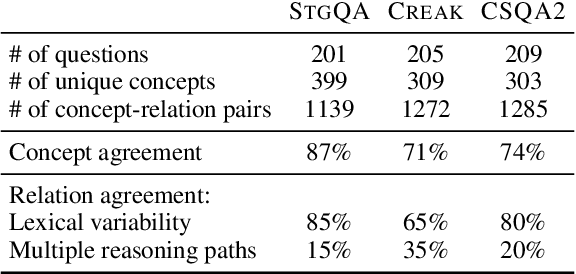
A prominent challenge for modern language understanding systems is the ability to answer implicit reasoning questions, where the required reasoning steps for answering the question are not mentioned in the text explicitly. In this work, we investigate why current models struggle with implicit reasoning question answering (QA) tasks, by decoupling inference of reasoning steps from their execution. We define a new task of implicit relation inference and construct a benchmark, IMPLICITRELATIONS, where given a question, a model should output a list of concept-relation pairs, where the relations describe the implicit reasoning steps required for answering the question. Using IMPLICITRELATIONS, we evaluate models from the GPT-3 family and find that, while these models struggle on the implicit reasoning QA task, they often succeed at inferring implicit relations. This suggests that the bottleneck for answering implicit reasoning questions is in the ability of language models to retrieve and reason over information rather than to plan an accurate reasoning strategy
Scaling Laws Under the Microscope: Predicting Transformer Performance from Small Scale Experiments
Feb 13, 2022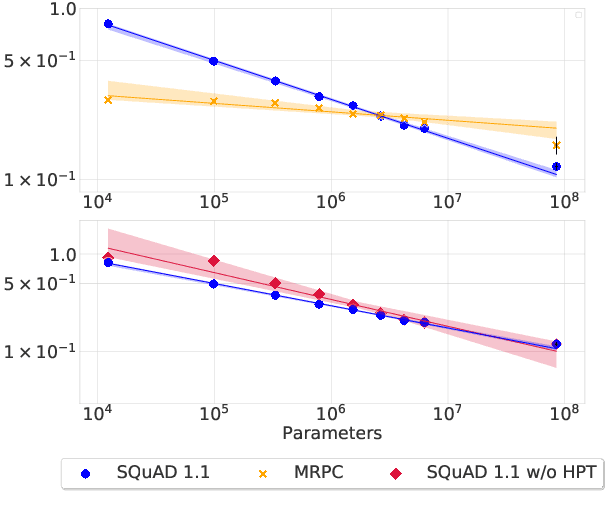
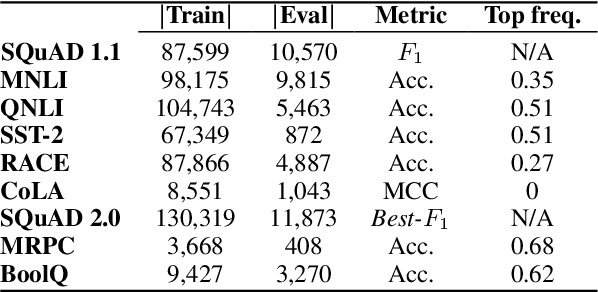
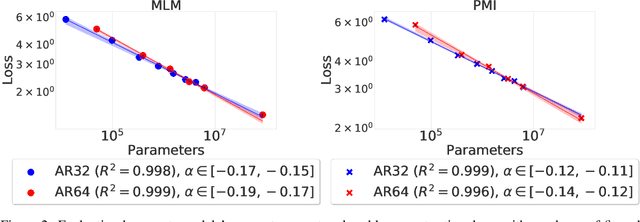
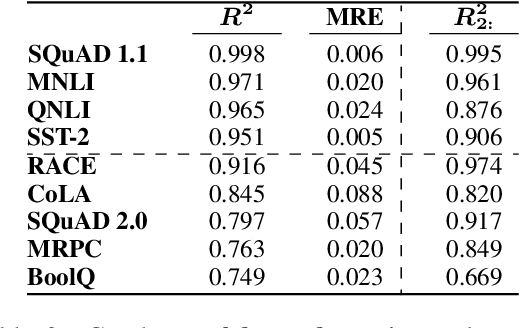
Neural scaling laws define a predictable relationship between a model's parameter count and its performance after training in the form of a power law. However, most research to date has not explicitly investigated whether scaling laws can be used to accelerate model development. In this work, we perform such an empirical investigation across a wide range of language understanding tasks, starting from models with as few as 10K parameters, and evaluate downstream performance across 9 language understanding tasks. We find that scaling laws emerge at finetuning time in some NLP tasks, and that they can also be exploited for debugging convergence when training large models. Moreover, for tasks where scaling laws exist, they can be used to predict the performance of larger models, which enables effective model selection. However, revealing scaling laws requires careful hyperparameter tuning and multiple runs for the purpose of uncertainty estimation, which incurs additional overhead, partially offsetting the computational benefits.
Unobserved Local Structures Make Compositional Generalization Hard
Jan 15, 2022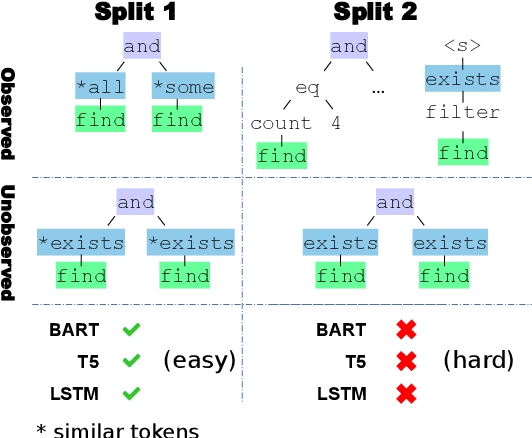

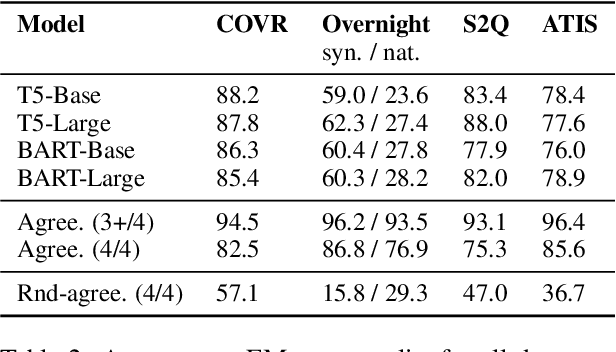
While recent work has convincingly showed that sequence-to-sequence models struggle to generalize to new compositions (termed compositional generalization), little is known on what makes compositional generalization hard on a particular test instance. In this work, we investigate what are the factors that make generalization to certain test instances challenging. We first substantiate that indeed some examples are more difficult than others by showing that different models consistently fail or succeed on the same test instances. Then, we propose a criterion for the difficulty of an example: a test instance is hard if it contains a local structure that was not observed at training time. We formulate a simple decision rule based on this criterion and empirically show it predicts instance-level generalization well across 5 different semantic parsing datasets, substantially better than alternative decision rules. Last, we show local structures can be leveraged for creating difficult adversarial compositional splits and also to improve compositional generalization under limited training budgets by strategically selecting examples for the training set.
CommonsenseQA 2.0: Exposing the Limits of AI through Gamification
Jan 14, 2022


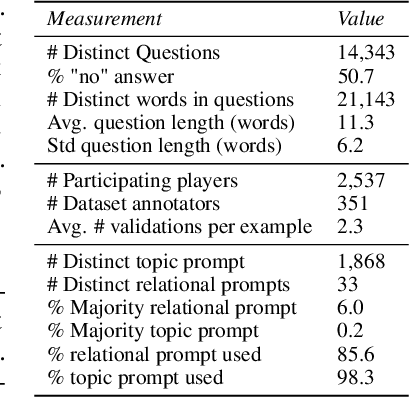
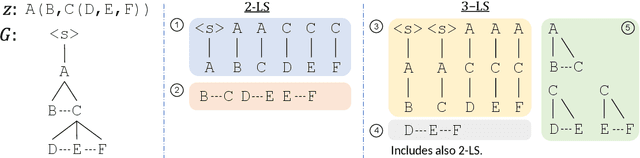
Constructing benchmarks that test the abilities of modern natural language understanding models is difficult - pre-trained language models exploit artifacts in benchmarks to achieve human parity, but still fail on adversarial examples and make errors that demonstrate a lack of common sense. In this work, we propose gamification as a framework for data construction. The goal of players in the game is to compose questions that mislead a rival AI while using specific phrases for extra points. The game environment leads to enhanced user engagement and simultaneously gives the game designer control over the collected data, allowing us to collect high-quality data at scale. Using our method we create CommonsenseQA 2.0, which includes 14,343 yes/no questions, and demonstrate its difficulty for models that are orders-of-magnitude larger than the AI used in the game itself. Our best baseline, the T5-based Unicorn with 11B parameters achieves an accuracy of 70.2%, substantially higher than GPT-3 (52.9%) in a few-shot inference setup. Both score well below human performance which is at 94.1%.
SCROLLS: Standardized CompaRison Over Long Language Sequences
Jan 10, 2022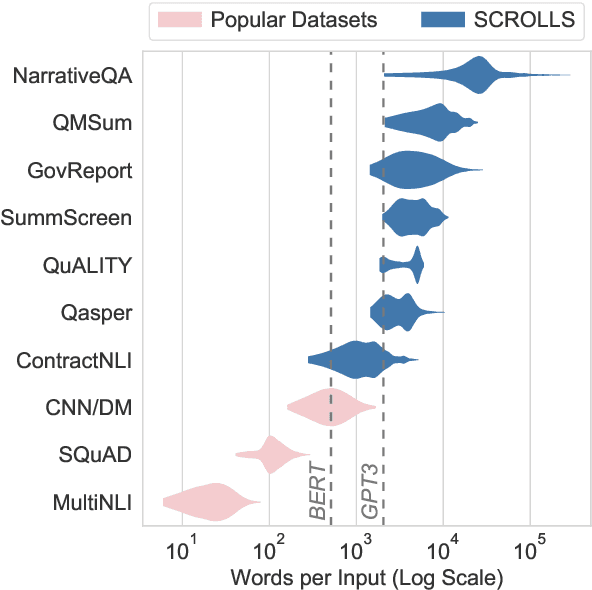
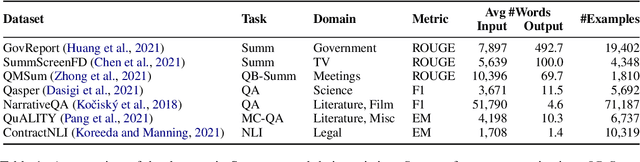

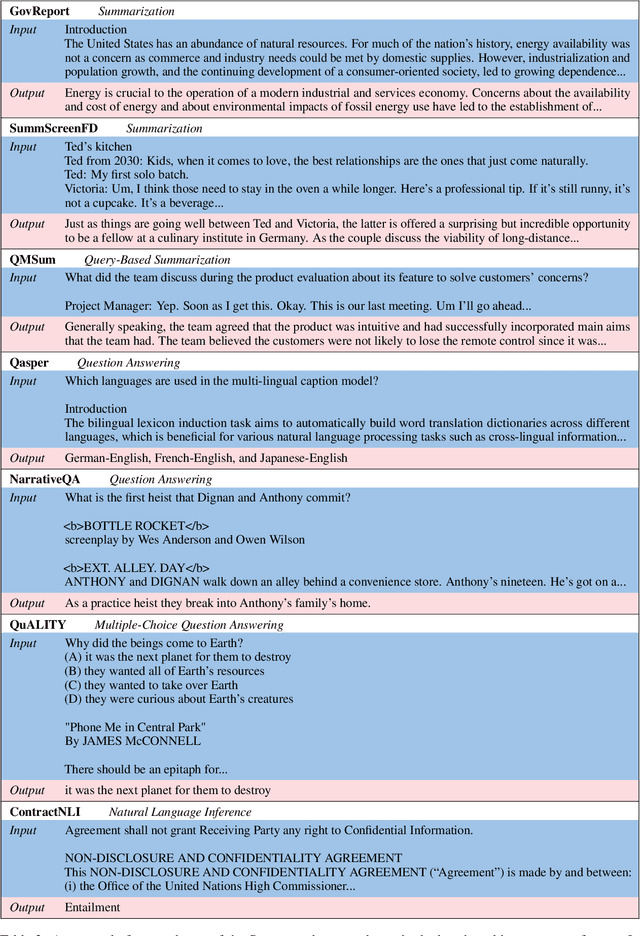
NLP benchmarks have largely focused on short texts, such as sentences and paragraphs, even though long texts comprise a considerable amount of natural language in the wild. We introduce SCROLLS, a suite of tasks that require reasoning over long texts. We examine existing long-text datasets, and handpick ones where the text is naturally long, while prioritizing tasks that involve synthesizing information across the input. SCROLLS contains summarization, question answering, and natural language inference tasks, covering multiple domains, including literature, science, business, and entertainment. Initial baselines, including Longformer Encoder-Decoder, indicate that there is ample room for improvement on SCROLLS. We make all datasets available in a unified text-to-text format and host a live leaderboard to facilitate research on model architecture and pretraining methods.
Learning To Retrieve Prompts for In-Context Learning
Dec 16, 2021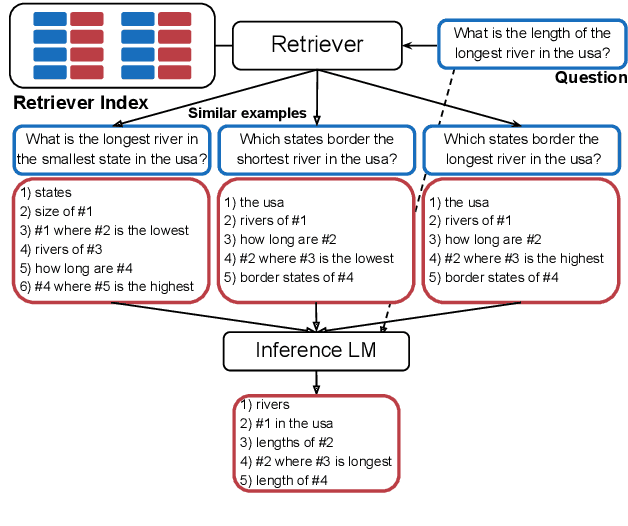

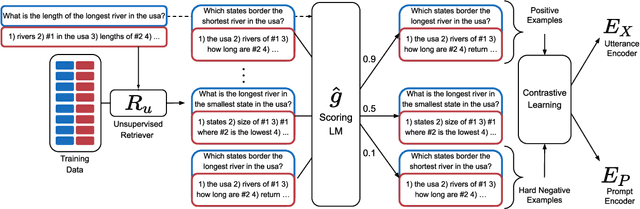
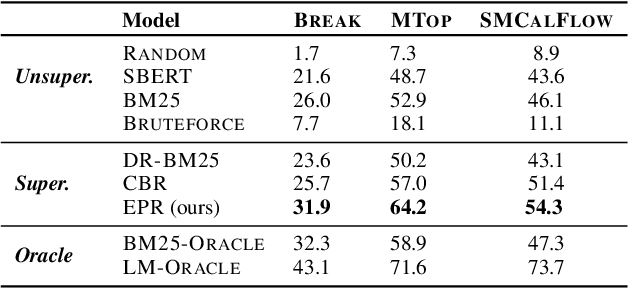
In-context learning is a recent paradigm in natural language understanding, where a large pre-trained language model (LM) observes a test instance and a few training examples as its input, and directly decodes the output without any update to its parameters. However, performance has been shown to strongly depend on the selected training examples (termed prompt). In this work, we propose an efficient method for retrieving prompts for in-context learning using annotated data and a LM. Given an input-output pair, we estimate the probability of the output given the input and a candidate training example as the prompt, and label training examples as positive or negative based on this probability. We then train an efficient dense retriever from this data, which is used to retrieve training examples as prompts at test time. We evaluate our approach on three sequence-to-sequence tasks where language utterances are mapped to meaning representations, and find that it substantially outperforms prior work and multiple baselines across the board.
Learning to Retrieve Passages without Supervision
Dec 14, 2021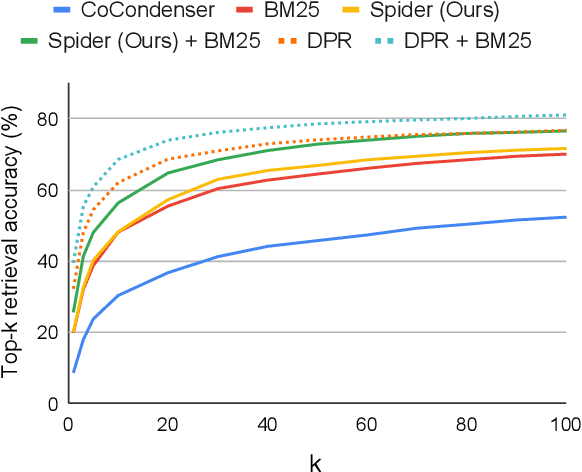
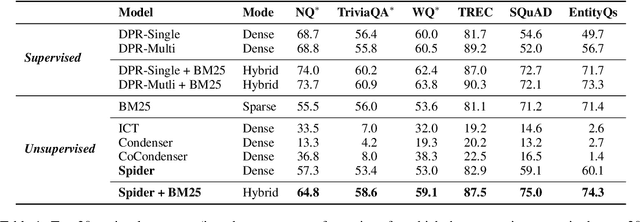
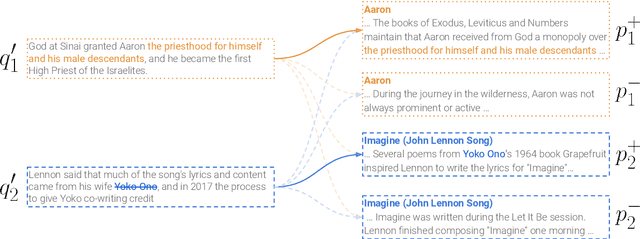
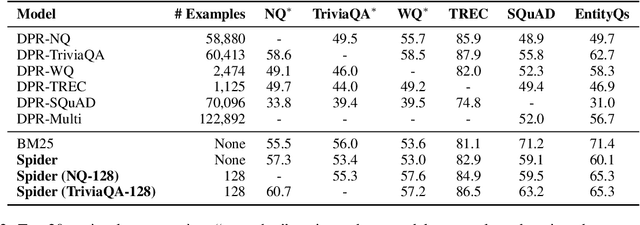
Dense retrievers for open-domain question answering (ODQA) have been shown to achieve impressive performance by training on large datasets of question-passage pairs. We investigate whether dense retrievers can be learned in a self-supervised fashion, and applied effectively without any annotations. We observe that existing pretrained models for retrieval struggle in this scenario, and propose a new pretraining scheme designed for retrieval: recurring span retrieval. We use recurring spans across passages in a document to create pseudo examples for contrastive learning. The resulting model -- Spider -- performs surprisingly well without any examples on a wide range of ODQA datasets, and is competitive with BM25, a strong sparse baseline. In addition, Spider often outperforms strong baselines like DPR trained on Natural Questions, when evaluated on questions from other datasets. Our hybrid retriever, which combines Spider with BM25, improves over its components across all datasets, and is often competitive with in-domain DPR models, which are trained on tens of thousands of examples.