 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRecomposer: Event-roll-guided generative audio editing
Sep 05, 2025Editing complex real-world sound scenes is difficult because individual sound sources overlap in time. Generative models can fill-in missing or corrupted details based on their strong prior understanding of the data domain. We present a system for editing individual sound events within complex scenes able to delete, insert, and enhance individual sound events based on textual edit descriptions (e.g., ``enhance Door'') and a graphical representation of the event timing derived from an ``event roll'' transcription. We present an encoder-decoder transformer working on SoundStream representations, trained on synthetic (input, desired output) audio example pairs formed by adding isolated sound events to dense, real-world backgrounds. Evaluation reveals the importance of each part of the edit descriptions -- action, class, timing. Our work demonstrates ``recomposition'' is an important and practical application.
Source Separation by Flow Matching
May 22, 2025


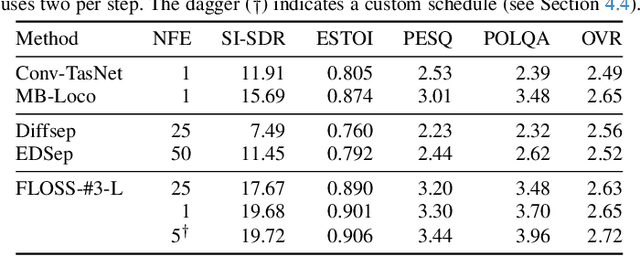
We consider the problem of single-channel audio source separation with the goal of reconstructing $K$ sources from their mixture. We address this ill-posed problem with FLOSS (FLOw matching for Source Separation), a constrained generation method based on flow matching, ensuring strict mixture consistency. Flow matching is a general methodology that, when given samples from two probability distributions defined on the same space, learns an ordinary differential equation to output a sample from one of the distributions when provided with a sample from the other. In our context, we have access to samples from the joint distribution of $K$ sources and so the corresponding samples from the lower-dimensional distribution of their mixture. To apply flow matching, we augment these mixture samples with artificial noise components to ensure the resulting "augmented" distribution matches the dimensionality of the $K$ source distribution. Additionally, as any permutation of the sources yields the same mixture, we adopt an equivariant formulation of flow matching which relies on a suitable custom-designed neural network architecture. We demonstrate the performance of the method for the separation of overlapping speech.
Understanding Learning with Sliced-Wasserstein Requires Rethinking Informative Slices
Nov 16, 2024The practical applications of Wasserstein distances (WDs) are constrained by their sample and computational complexities. Sliced-Wasserstein distances (SWDs) provide a workaround by projecting distributions onto one-dimensional subspaces, leveraging the more efficient, closed-form WDs for one-dimensional distributions. However, in high dimensions, most random projections become uninformative due to the concentration of measure phenomenon. Although several SWD variants have been proposed to focus on \textit{informative} slices, they often introduce additional complexity, numerical instability, and compromise desirable theoretical (metric) properties of SWD. Amidst the growing literature that focuses on directly modifying the slicing distribution, which often face challenges, we revisit the classical Sliced-Wasserstein and propose instead to rescale the 1D Wasserstein to make all slices equally informative. Importantly, we show that with an appropriate data assumption and notion of \textit{slice informativeness}, rescaling for all individual slices simplifies to \textbf{a single global scaling factor} on the SWD. This, in turn, translates to the standard learning rate search for gradient-based learning in common machine learning workflows. We perform extensive experiments across various machine learning tasks showing that the classical SWD, when properly configured, can often match or surpass the performance of more complex variants. We then answer the following question: "Is Sliced-Wasserstein all you need for common learning tasks?"
Towards sub-millisecond latency real-time speech enhancement models on hearables
Sep 26, 2024



Low latency models are critical for real-time speech enhancement applications, such as hearing aids and hearables. However, the sub-millisecond latency space for resource-constrained hearables remains underexplored. We demonstrate speech enhancement using a computationally efficient minimum-phase FIR filter, enabling sample-by-sample processing to achieve mean algorithmic latency of 0.32 ms to 1.25 ms. With a single microphone, we observe a mean SI-SDRi of 4.1 dB. The approach shows generalization with a DNSMOS increase of 0.2 on unseen audio recordings. We use a lightweight LSTM-based model of 644k parameters to generate FIR taps. We benchmark that our system can run on low-power DSP with 388 MIPS and mean end-to-end latency of 3.35 ms. We provide a comparison with baseline low-latency spectral masking techniques. We hope this work will enable a better understanding of latency and can be used to improve the comfort and usability of hearables.
Separating the "Chirp" from the "Chat": Self-supervised Visual Grounding of Sound and Language
Jun 09, 2024



We present DenseAV, a novel dual encoder grounding architecture that learns high-resolution, semantically meaningful, and audio-visually aligned features solely through watching videos. We show that DenseAV can discover the ``meaning'' of words and the ``location'' of sounds without explicit localization supervision. Furthermore, it automatically discovers and distinguishes between these two types of associations without supervision. We show that DenseAV's localization abilities arise from a new multi-head feature aggregation operator that directly compares dense image and audio representations for contrastive learning. In contrast, many other systems that learn ``global'' audio and video representations cannot localize words and sound. Finally, we contribute two new datasets to improve the evaluation of AV representations through speech and sound prompted semantic segmentation. On these and other datasets we show DenseAV dramatically outperforms the prior art on speech and sound prompted semantic segmentation. DenseAV outperforms the previous state-of-the-art, ImageBind, on cross-modal retrieval using fewer than half of the parameters. Project Page: \href{https://aka.ms/denseav}{https://aka.ms/denseav}
Objective and subjective evaluation of speech enhancement methods in the UDASE task of the 7th CHiME challenge
Feb 02, 2024



Supervised models for speech enhancement are trained using artificially generated mixtures of clean speech and noise signals. However, the synthetic training conditions may not accurately reflect real-world conditions encountered during testing. This discrepancy can result in poor performance when the test domain significantly differs from the synthetic training domain. To tackle this issue, the UDASE task of the 7th CHiME challenge aimed to leverage real-world noisy speech recordings from the test domain for unsupervised domain adaptation of speech enhancement models. Specifically, this test domain corresponds to the CHiME-5 dataset, characterized by real multi-speaker and conversational speech recordings made in noisy and reverberant domestic environments, for which ground-truth clean speech signals are not available. In this paper, we present the objective and subjective evaluations of the systems that were submitted to the CHiME-7 UDASE task, and we provide an analysis of the results. This analysis reveals a limited correlation between subjective ratings and several supervised nonintrusive performance metrics recently proposed for speech enhancement. Conversely, the results suggest that more traditional intrusive objective metrics can be used for in-domain performance evaluation using the reverberant LibriCHiME-5 dataset developed for the challenge. The subjective evaluation indicates that all systems successfully reduced the background noise, but always at the expense of increased distortion. Out of the four speech enhancement methods evaluated subjectively, only one demonstrated an improvement in overall quality compared to the unprocessed noisy speech, highlighting the difficulty of the task. The tools and audio material created for the CHiME-7 UDASE task are shared with the community.
TokenSplit: Using Discrete Speech Representations for Direct, Refined, and Transcript-Conditioned Speech Separation and Recognition
Aug 21, 2023


We present TokenSplit, a speech separation model that acts on discrete token sequences. The model is trained on multiple tasks simultaneously: separate and transcribe each speech source, and generate speech from text. The model operates on transcripts and audio token sequences and achieves multiple tasks through masking of inputs. The model is a sequence-to-sequence encoder-decoder model that uses the Transformer architecture. We also present a "refinement" version of the model that predicts enhanced audio tokens from the audio tokens of speech separated by a conventional separation model. Using both objective metrics and subjective MUSHRA listening tests, we show that our model achieves excellent performance in terms of separation, both with or without transcript conditioning. We also measure the automatic speech recognition (ASR) performance and provide audio samples of speech synthesis to demonstrate the additional utility of our model.
The CHiME-7 UDASE task: Unsupervised domain adaptation for conversational speech enhancement
Jul 07, 2023Supervised speech enhancement models are trained using artificially generated mixtures of clean speech and noise signals, which may not match real-world recording conditions at test time. This mismatch can lead to poor performance if the test domain significantly differs from the synthetic training domain. In this paper, we introduce the unsupervised domain adaptation for conversational speech enhancement (UDASE) task of the 7th CHiME challenge. This task aims to leverage real-world noisy speech recordings from the target test domain for unsupervised domain adaptation of speech enhancement models. The target test domain corresponds to the multi-speaker reverberant conversational speech recordings of the CHiME-5 dataset, for which the ground-truth clean speech reference is not available. Given a CHiME-5 recording, the task is to estimate the clean, potentially multi-speaker, reverberant speech, removing the additive background noise. We discuss the motivation for the CHiME-7 UDASE task and describe the data, the task, and the baseline system.
Unsupervised Multi-channel Separation and Adaptation
May 18, 2023


A key challenge in machine learning is to generalize from training data to an application domain of interest. This work generalizes the recently-proposed mixture invariant training (MixIT) algorithm to perform unsupervised learning in the multi-channel setting. We use MixIT to train a model on far-field microphone array recordings of overlapping reverberant and noisy speech from the AMI Corpus. The models are trained on both supervised and unsupervised training data, and are tested on real AMI recordings containing overlapping speech. To objectively evaluate our models, we also use a synthetic multi-channel AMI test set. Holding network architectures constant, we find that a fine-tuned semi-supervised model yields the largest improvement to SI-SNR and to human listening ratings across synthetic and real datasets, outperforming supervised models trained on well-matched synthetic data. Our results demonstrate that unsupervised learning through MixIT enables model adaptation on both single- and multi-channel real-world speech recordings.
AudioSlots: A slot-centric generative model for audio separation
May 09, 2023In a range of recent works, object-centric architectures have been shown to be suitable for unsupervised scene decomposition in the vision domain. Inspired by these methods we present AudioSlots, a slot-centric generative model for blind source separation in the audio domain. AudioSlots is built using permutation-equivariant encoder and decoder networks. The encoder network based on the Transformer architecture learns to map a mixed audio spectrogram to an unordered set of independent source embeddings. The spatial broadcast decoder network learns to generate the source spectrograms from the source embeddings. We train the model in an end-to-end manner using a permutation invariant loss function. Our results on Libri2Mix speech separation constitute a proof of concept that this approach shows promise. We discuss the results and limitations of our approach in detail, and further outline potential ways to overcome the limitations and directions for future work.