 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeObjective and subjective evaluation of speech enhancement methods in the UDASE task of the 7th CHiME challenge
Feb 02, 2024



Supervised models for speech enhancement are trained using artificially generated mixtures of clean speech and noise signals. However, the synthetic training conditions may not accurately reflect real-world conditions encountered during testing. This discrepancy can result in poor performance when the test domain significantly differs from the synthetic training domain. To tackle this issue, the UDASE task of the 7th CHiME challenge aimed to leverage real-world noisy speech recordings from the test domain for unsupervised domain adaptation of speech enhancement models. Specifically, this test domain corresponds to the CHiME-5 dataset, characterized by real multi-speaker and conversational speech recordings made in noisy and reverberant domestic environments, for which ground-truth clean speech signals are not available. In this paper, we present the objective and subjective evaluations of the systems that were submitted to the CHiME-7 UDASE task, and we provide an analysis of the results. This analysis reveals a limited correlation between subjective ratings and several supervised nonintrusive performance metrics recently proposed for speech enhancement. Conversely, the results suggest that more traditional intrusive objective metrics can be used for in-domain performance evaluation using the reverberant LibriCHiME-5 dataset developed for the challenge. The subjective evaluation indicates that all systems successfully reduced the background noise, but always at the expense of increased distortion. Out of the four speech enhancement methods evaluated subjectively, only one demonstrated an improvement in overall quality compared to the unprocessed noisy speech, highlighting the difficulty of the task. The tools and audio material created for the CHiME-7 UDASE task are shared with the community.
The CHiME-7 UDASE task: Unsupervised domain adaptation for conversational speech enhancement
Jul 07, 2023Supervised speech enhancement models are trained using artificially generated mixtures of clean speech and noise signals, which may not match real-world recording conditions at test time. This mismatch can lead to poor performance if the test domain significantly differs from the synthetic training domain. In this paper, we introduce the unsupervised domain adaptation for conversational speech enhancement (UDASE) task of the 7th CHiME challenge. This task aims to leverage real-world noisy speech recordings from the target test domain for unsupervised domain adaptation of speech enhancement models. The target test domain corresponds to the multi-speaker reverberant conversational speech recordings of the CHiME-5 dataset, for which the ground-truth clean speech reference is not available. Given a CHiME-5 recording, the task is to estimate the clean, potentially multi-speaker, reverberant speech, removing the additive background noise. We discuss the motivation for the CHiME-7 UDASE task and describe the data, the task, and the baseline system.
Multi-Channel Target Speaker Extraction with Refinement: The WavLab Submission to the Second Clarity Enhancement Challenge
Feb 15, 2023This paper describes our submission to the Second Clarity Enhancement Challenge (CEC2), which consists of target speech enhancement for hearing-aid (HA) devices in noisy-reverberant environments with multiple interferers such as music and competing speakers. Our approach builds upon the powerful iterative neural/beamforming enhancement (iNeuBe) framework introduced in our recent work, and this paper extends it for target speaker extraction. We therefore name the proposed approach as iNeuBe-X, where the X stands for extraction. To address the challenges encountered in the CEC2 setting, we introduce four major novelties: (1) we extend the state-of-the-art TF-GridNet model, originally designed for monaural speaker separation, for multi-channel, causal speech enhancement, and large improvements are observed by replacing the TCNDenseNet used in iNeuBe with this new architecture; (2) we leverage a recent dual window size approach with future-frame prediction to ensure that iNueBe-X satisfies the 5 ms constraint on algorithmic latency required by CEC2; (3) we introduce a novel speaker-conditioning branch for TF-GridNet to achieve target speaker extraction; (4) we propose a fine-tuning step, where we compute an additional loss with respect to the target speaker signal compensated with the listener audiogram. Without using external data, on the official development set our best model reaches a hearing-aid speech perception index (HASPI) score of 0.942 and a scale-invariant signal-to-distortion ratio improvement (SI-SDRi) of 18.8 dB. These results are promising given the fact that the CEC2 data is extremely challenging (e.g., on the development set the mixture SI-SDR is -12.3 dB). A demo of our submitted system is available at WAVLab CEC2 demo.
Learning Filterbanks for End-to-End Acoustic Beamforming
Nov 08, 2021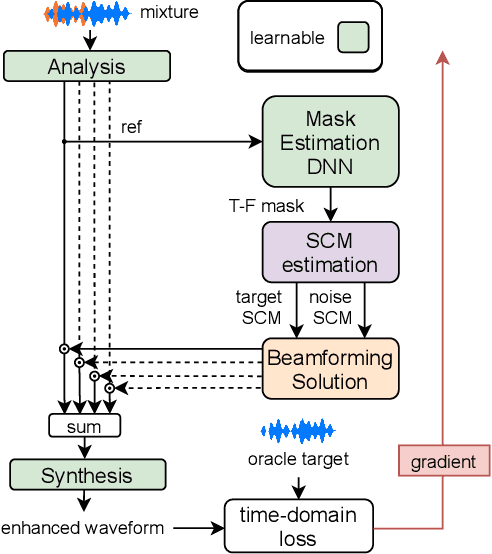
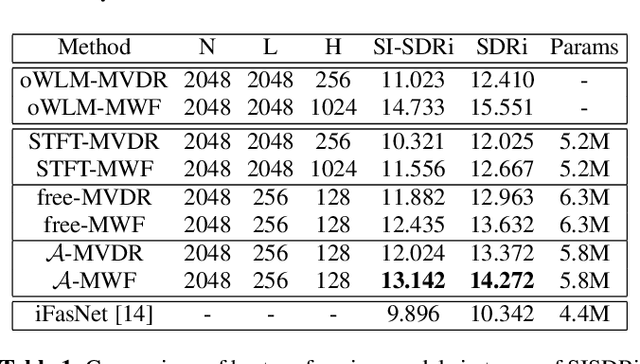
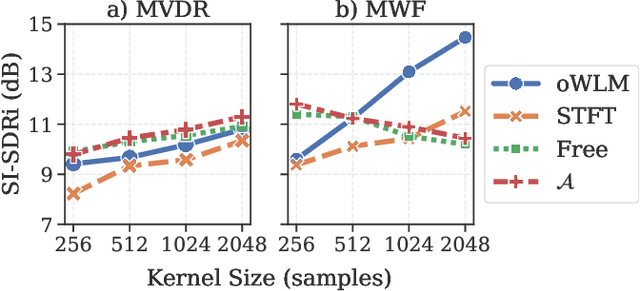
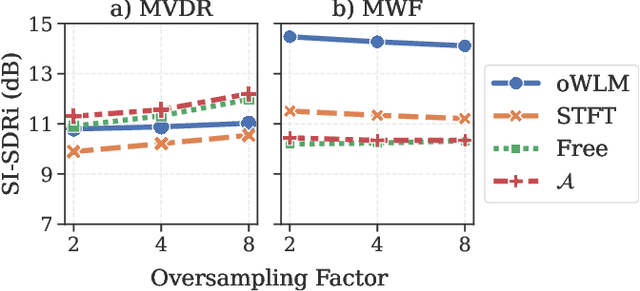
Recent work on monaural source separation has shown that performance can be increased by using fully learned filterbanks with short windows. On the other hand it is widely known that, for conventional beamforming techniques, performance increases with long analysis windows. This applies also to most hybrid neural beamforming methods which rely on a deep neural network (DNN) to estimate the spatial covariance matrices. In this work we try to bridge the gap between these two worlds and explore fully end-to-end hybrid neural beamforming in which, instead of using the Short-Time-Fourier Transform, also the analysis and synthesis filterbanks are learnt jointly with the DNN. In detail, we explore two different types of learned filterbanks: fully learned and analytic. We perform a detailed analysis using the recent Clarity Challenge data and show that by using learnt filterbanks is possible to surpass oracle-mask based beamforming for short windows.
Filterbank design for end-to-end speech separation
Oct 23, 2019
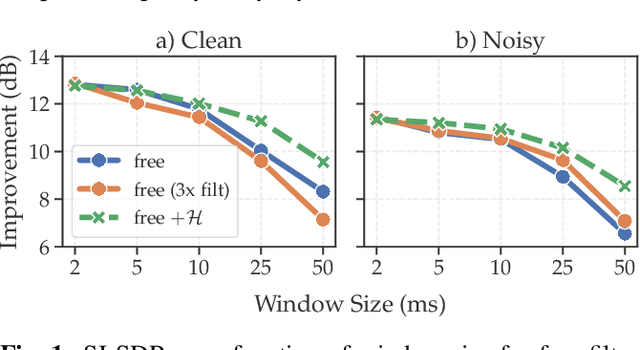
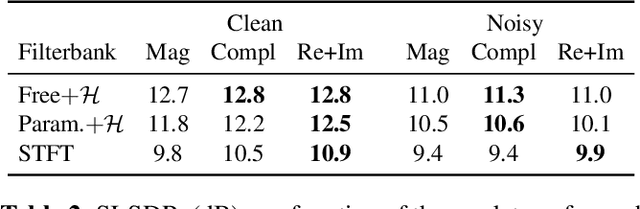
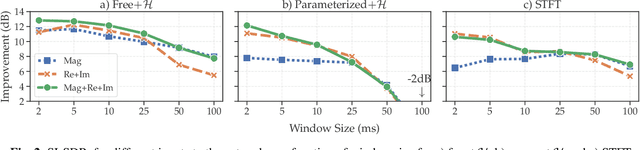
Single-channel speech separation has recently made great progress thanks to learned filterbanks as used in ConvTasNet. In parallel, parameterized filterbanks have been proposed for speaker recognition where only center frequencies and bandwidths are learned. In this work, we extend real-valued learned and parameterized filterbanks into complex-valued analytic filterbanks and define a set of corresponding representations and masking strategies. We evaluate these filterbanks on a newly released noisy speech separation dataset (WHAM). The results show that the proposed analytic learned filterbank consistently outperforms the real-valued filterbank of ConvTasNet. Also, we validate the use of parameterized filterbanks and show that complex-valued representations and masks are beneficial in all conditions. Finally, we show that the STFT achieves its best performance for 2ms windows.
A Statistically Principled and Computationally Efficient Approach to Speech Enhancement using Variational Autoencoders
May 14, 2019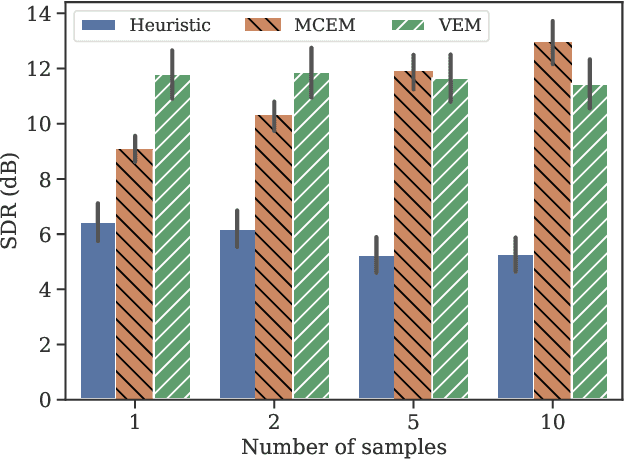

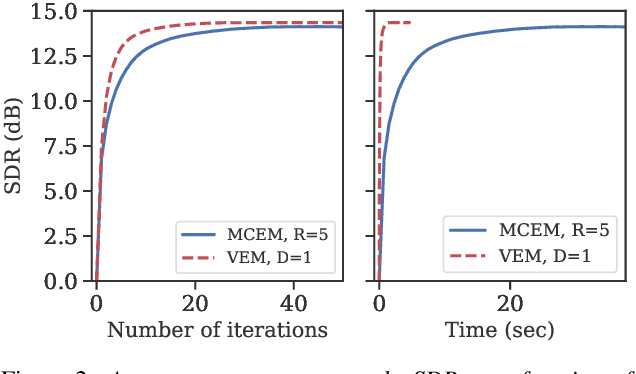
Recent studies have explored the use of deep generative models of speech spectra based of variational autoencoders (VAEs), combined with unsupervised noise models, to perform speech enhancement. These studies developed iterative algorithms involving either Gibbs sampling or gradient descent at each step, making them computationally expensive. This paper proposes a variational inference method to iteratively estimate the power spectrogram of the clean speech. Our main contribution is the analytical derivation of the variational steps in which the en-coder of the pre-learned VAE can be used to estimate the varia-tional approximation of the true posterior distribution, using the very same assumption made to train VAEs. Experiments show that the proposed method produces results on par with the afore-mentioned iterative methods using sampling, while decreasing the computational cost by a factor 36 to reach a given performance .