 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Differentiable Auditory Loop (DAL): An ML Framework for Hyper-Personalized Hearing Aids
Jun 02, 2026Conventional hearing aids rely on fixed, frequency-dependent amplification and compression to manage reduced sensitivity, which often fails to provide sufficient listening support in complex environments, such as situations with multiple speakers (the ``cocktail party'' problem). To more comprehensively address the underlying encoding dysfunctions of hearing loss, we introduce the Differentiable Auditory Loop (DAL), a new open-source framework for personalized hearing aid design and fitting. Our first implementation of DAL incorporates CARFAC, a differentiable model of human cochlear function, which we ported to JAX, to optimize a deep neural network to match impaired auditory neural activity patterns with a normal-hearing reference. To build a hearing aid with the fine-grained spectro-temporal signal processing required, we adopt SEANet, a waveform-to-waveform fully convolutional UNet generator. We fine-tune the network by comparing the outputs of a CARFAC model fitted to normal hearing with that of a CARFAC model fitted to match each subject's individual hearing impairment. The comparison is done using loss functions derived from the respective CARFAC neural activity pattern (NAP) outputs and stabilized auditory images (SAIs), the latter providing a 2D representation that captures phase-insensitive temporal structure in the auditory nerve output. Through gradient descent, the SEANet model learns to both denoise the input and compensate for the hearing loss modelled by the impaired CARFAC model. Across neural-representation and signal-fidelity metrics, the DAL-optimized SEANet model outperformed the tested master hearing aid (MHA) baselines. The DAL framework provides a practical path toward model-based, machine-learning-driven personalization of hearing aid signal processing. Next steps include hardware deployment to enable real-world clinical testing.
Identifying Hearing Difficulty Moments in Conversational Audio
Jul 31, 2025Individuals regularly experience Hearing Difficulty Moments in everyday conversation. Identifying these moments of hearing difficulty has particular significance in the field of hearing assistive technology where timely interventions are key for realtime hearing assistance. In this paper, we propose and compare machine learning solutions for continuously detecting utterances that identify these specific moments in conversational audio. We show that audio language models, through their multimodal reasoning capabilities, excel at this task, significantly outperforming a simple ASR hotword heuristic and a more conventional fine-tuning approach with Wav2Vec, an audio-only input architecture that is state-of-the-art for automatic speech recognition (ASR).
Towards sub-millisecond latency real-time speech enhancement models on hearables
Sep 26, 2024



Low latency models are critical for real-time speech enhancement applications, such as hearing aids and hearables. However, the sub-millisecond latency space for resource-constrained hearables remains underexplored. We demonstrate speech enhancement using a computationally efficient minimum-phase FIR filter, enabling sample-by-sample processing to achieve mean algorithmic latency of 0.32 ms to 1.25 ms. With a single microphone, we observe a mean SI-SDRi of 4.1 dB. The approach shows generalization with a DNSMOS increase of 0.2 on unseen audio recordings. We use a lightweight LSTM-based model of 644k parameters to generate FIR taps. We benchmark that our system can run on low-power DSP with 388 MIPS and mean end-to-end latency of 3.35 ms. We provide a comparison with baseline low-latency spectral masking techniques. We hope this work will enable a better understanding of latency and can be used to improve the comfort and usability of hearables.
The CARFAC v2 Cochlear Model in Matlab, NumPy, and JAX
Apr 26, 2024



The open-source CARFAC (Cascade of Asymmetric Resonators with Fast-Acting Compression) cochlear model is upgraded to version 2, with improvements to the Matlab implementation, and with new Python/NumPy and JAX implementations -- but C++ version changes are still pending. One change addresses the DC (direct current, or zero frequency) quadratic distortion anomaly previously reported; another reduces the neural synchrony at high frequencies; the others have little or no noticeable effect in the default configuration. A new feature allows modeling a reduction of cochlear amplifier function, as a step toward a differentiable parameterized model of hearing impairment. In addition, the integration into the Auditory Model Toolbox (AMT) has been extensively improved, as the prior integration had bugs that made it unsuitable for including CARFAC in multi-model comparisons.
Trainable Frontend For Robust and Far-Field Keyword Spotting
Jul 19, 2016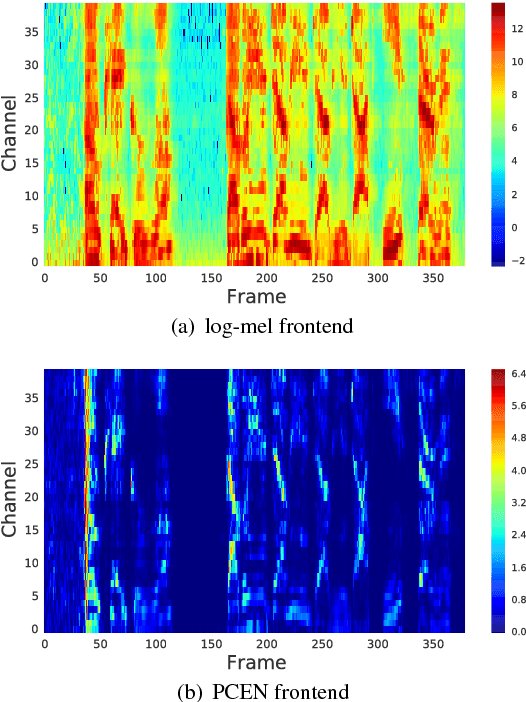
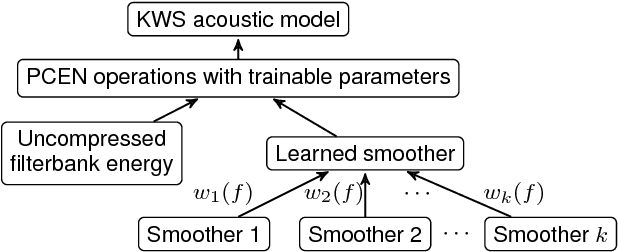
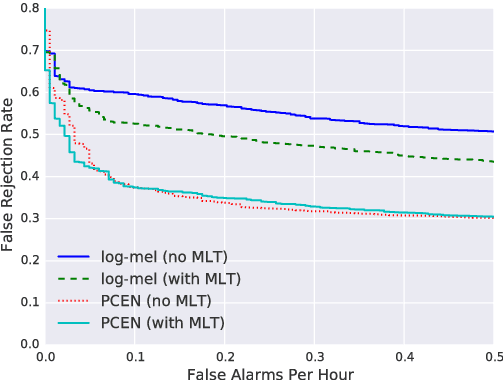
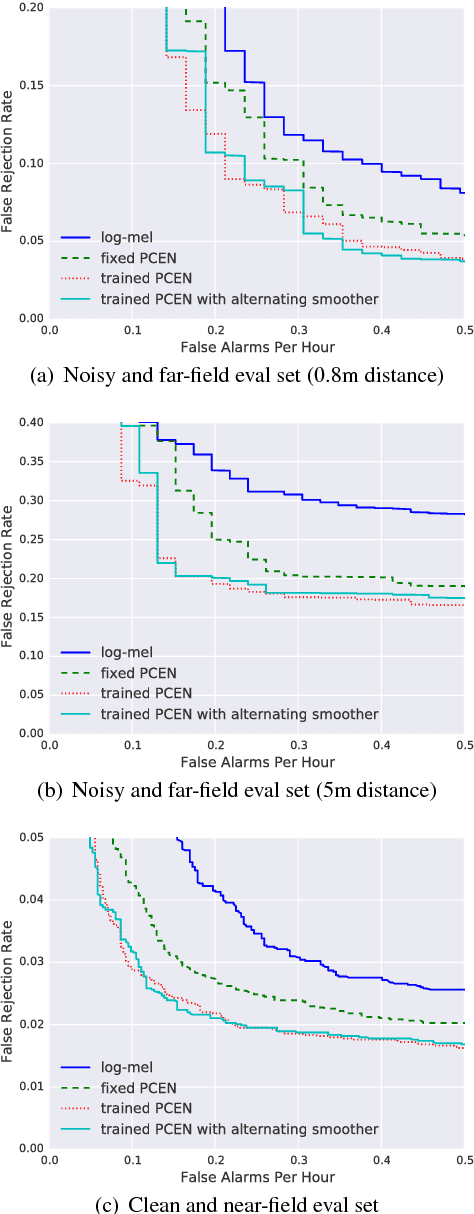
Robust and far-field speech recognition is critical to enable true hands-free communication. In far-field conditions, signals are attenuated due to distance. To improve robustness to loudness variation, we introduce a novel frontend called per-channel energy normalization (PCEN). The key ingredient of PCEN is the use of an automatic gain control based dynamic compression to replace the widely used static (such as log or root) compression. We evaluate PCEN on the keyword spotting task. On our large rerecorded noisy and far-field eval sets, we show that PCEN significantly improves recognition performance. Furthermore, we model PCEN as neural network layers and optimize high-dimensional PCEN parameters jointly with the keyword spotting acoustic model. The trained PCEN frontend demonstrates significant further improvements without increasing model complexity or inference-time cost.
FPGA Implementation of the CAR Model of the Cochlea
Mar 02, 2015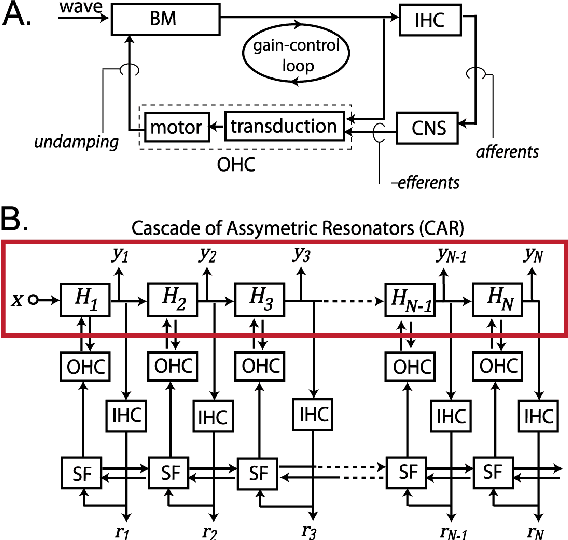
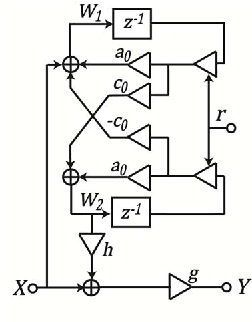
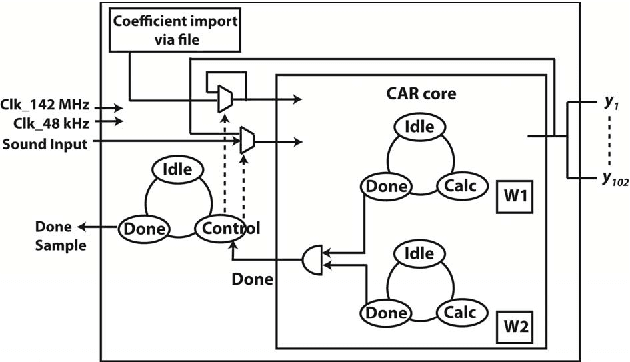
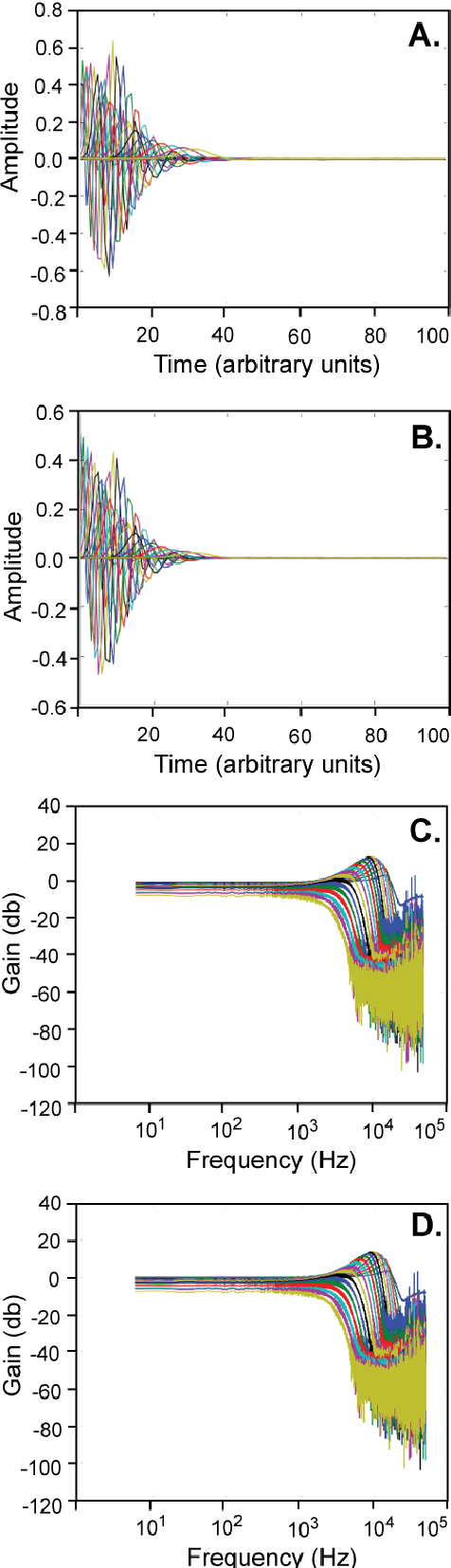
The front end of the human auditory system, the cochlea, converts sound signals from the outside world into neural impulses transmitted along the auditory pathway for further processing. The cochlea senses and separates sound in a nonlinear active fashion, exhibiting remarkable sensitivity and frequency discrimination. Although several electronic models of the cochlea have been proposed and implemented, none of these are able to reproduce all the characteristics of the cochlea, including large dynamic range, large gain and sharp tuning at low sound levels, and low gain and broad tuning at intense sound levels. Here, we implement the Cascade of Asymmetric Resonators (CAR) model of the cochlea on an FPGA. CAR represents the basilar membrane filter in the Cascade of Asymmetric Resonators with Fast-Acting Compression (CAR-FAC) cochlear model. CAR-FAC is a neuromorphic model of hearing based on a pole-zero filter cascade model of auditory filtering. It uses simple nonlinear extensions of conventional digital filter stages that are well suited to FPGA implementations, so that we are able to implement up to 1224 cochlear sections on Virtex-6 FPGA to process sound data in real time. The FPGA implementation of the electronic cochlea described here may be used as a front-end sound analyser for various machine-hearing applications.