 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTrajectory Data Suffices for Statistically Efficient Learning in Offline RL with Linear $q^π$-Realizability and Concentrability
May 27, 2024We consider offline reinforcement learning (RL) in $H$-horizon Markov decision processes (MDPs) under the linear $q^\pi$-realizability assumption, where the action-value function of every policy is linear with respect to a given $d$-dimensional feature function. The hope in this setting is that learning a good policy will be possible without requiring a sample size that scales with the number of states in the MDP. Foster et al. [2021] have shown this to be impossible even under $\textit{concentrability}$, a data coverage assumption where a coefficient $C_\text{conc}$ bounds the extent to which the state-action distribution of any policy can veer off the data distribution. However, the data in this previous work was in the form of a sequence of individual transitions. This leaves open the question of whether the negative result mentioned could be overcome if the data was composed of sequences of full trajectories. In this work we answer this question positively by proving that with trajectory data, a dataset of size $\text{poly}(d,H,C_\text{conc})/\epsilon^2$ is sufficient for deriving an $\epsilon$-optimal policy, regardless of the size of the state space. The main tool that makes this result possible is due to Weisz et al. [2023], who demonstrate that linear MDPs can be used to approximate linearly $q^\pi$-realizable MDPs. The connection to trajectory data is that the linear MDP approximation relies on "skipping" over certain states. The associated estimation problems are thus easy when working with trajectory data, while they remain nontrivial when working with individual transitions. The question of computational efficiency under our assumptions remains open.
Regret Minimization via Saddle Point Optimization
Mar 15, 2024A long line of works characterizes the sample complexity of regret minimization in sequential decision-making by min-max programs. In the corresponding saddle-point game, the min-player optimizes the sampling distribution against an adversarial max-player that chooses confusing models leading to large regret. The most recent instantiation of this idea is the decision-estimation coefficient (DEC), which was shown to provide nearly tight lower and upper bounds on the worst-case expected regret in structured bandits and reinforcement learning. By re-parametrizing the offset DEC with the confidence radius and solving the corresponding min-max program, we derive an anytime variant of the Estimation-To-Decisions (E2D) algorithm. Importantly, the algorithm optimizes the exploration-exploitation trade-off online instead of via the analysis. Our formulation leads to a practical algorithm for finite model classes and linear feedback models. We further point out connections to the information ratio, decoupling coefficient and PAC-DEC, and numerically evaluate the performance of E2D on simple examples.
Efficient Planning in Combinatorial Action Spaces with Applications to Cooperative Multi-Agent Reinforcement Learning
Feb 08, 2023A practical challenge in reinforcement learning are combinatorial action spaces that make planning computationally demanding. For example, in cooperative multi-agent reinforcement learning, a potentially large number of agents jointly optimize a global reward function, which leads to a combinatorial blow-up in the action space by the number of agents. As a minimal requirement, we assume access to an argmax oracle that allows to efficiently compute the greedy policy for any Q-function in the model class. Building on recent work in planning with local access to a simulator and linear function approximation, we propose efficient algorithms for this setting that lead to polynomial compute and query complexity in all relevant problem parameters. For the special case where the feature decomposition is additive, we further improve the bounds and extend the results to the kernelized setting with an efficient algorithm.
The Effect of Q-function Reuse on the Total Regret of Tabular, Model-Free, Reinforcement Learning
Mar 07, 2021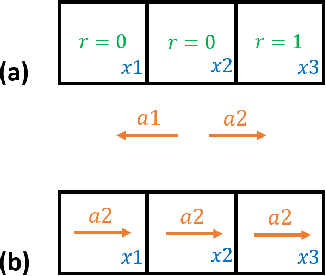
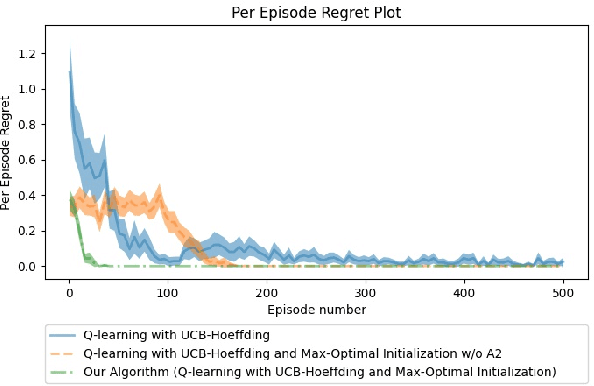
Some reinforcement learning methods suffer from high sample complexity causing them to not be practical in real-world situations. $Q$-function reuse, a transfer learning method, is one way to reduce the sample complexity of learning, potentially improving usefulness of existing algorithms. Prior work has shown the empirical effectiveness of $Q$-function reuse for various environments when applied to model-free algorithms. To the best of our knowledge, there has been no theoretical work showing the regret of $Q$-function reuse when applied to the tabular, model-free setting. We aim to bridge the gap between theoretical and empirical work in $Q$-function reuse by providing some theoretical insights on the effectiveness of $Q$-function reuse when applied to the $Q$-learning with UCB-Hoeffding algorithm. Our main contribution is showing that in a specific case if $Q$-function reuse is applied to the $Q$-learning with UCB-Hoeffding algorithm it has a regret that is independent of the state or action space. We also provide empirical results supporting our theoretical findings.