 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiffusion Active Learning: Towards Data-Driven Experimental Design in Computed Tomography
Apr 04, 2025We introduce Diffusion Active Learning, a novel approach that combines generative diffusion modeling with data-driven sequential experimental design to adaptively acquire data for inverse problems. Although broadly applicable, we focus on scientific computed tomography (CT) for experimental validation, where structured prior datasets are available, and reducing data requirements directly translates to shorter measurement times and lower X-ray doses. We first pre-train an unconditional diffusion model on domain-specific CT reconstructions. The diffusion model acts as a learned prior that is data-dependent and captures the structure of the underlying data distribution, which is then used in two ways: It drives the active learning process and also improves the quality of the reconstructions. During the active learning loop, we employ a variant of diffusion posterior sampling to generate conditional data samples from the posterior distribution, ensuring consistency with the current measurements. Using these samples, we quantify the uncertainty in the current estimate to select the most informative next measurement. Our results show substantial reductions in data acquisition requirements, corresponding to lower X-ray doses, while simultaneously improving image reconstruction quality across multiple real-world tomography datasets.
Bridging the Gap: Addressing Discrepancies in Diffusion Model Training for Classifier-Free Guidance
Nov 02, 2023Diffusion models have emerged as a pivotal advancement in generative models, setting new standards to the quality of the generated instances. In the current paper we aim to underscore a discrepancy between conventional training methods and the desired conditional sampling behavior of these models. While the prevalent classifier-free guidance technique works well, it's not without flaws. At higher values for the guidance scale parameter $w$, we often get out of distribution samples and mode collapse, whereas at lower values for $w$ we may not get the desired specificity. To address these challenges, we introduce an updated loss function that better aligns training objectives with sampling behaviors. Experimental validation with FID scores on CIFAR-10 elucidates our method's ability to produce higher quality samples with fewer sampling timesteps, and be more robust to the choice of guidance scale $w$. We also experiment with fine-tuning Stable Diffusion on the proposed loss, to provide early evidence that large diffusion models may also benefit from this refined loss function.
Multilayer Lookahead: a Nested Version of Lookahead
Oct 27, 2021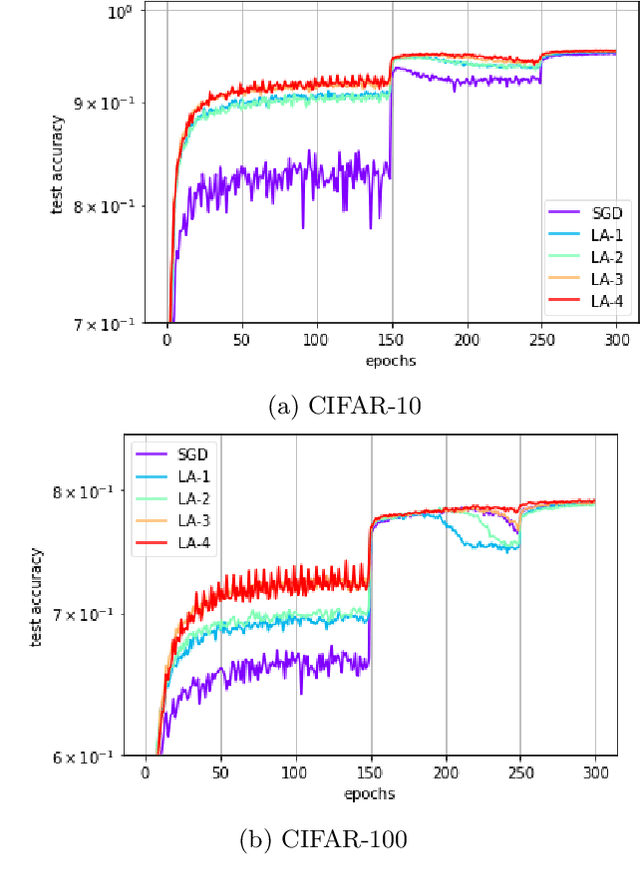


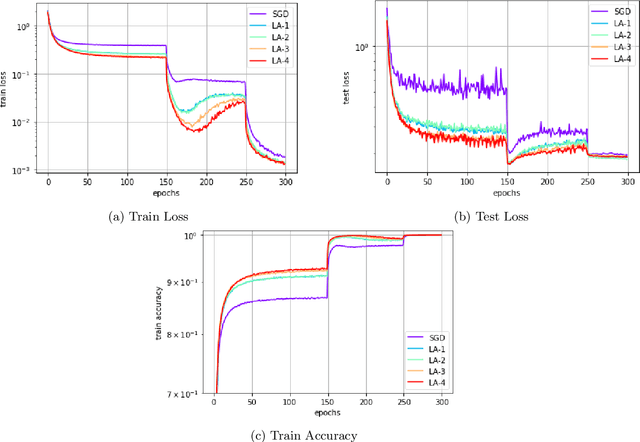
In recent years, SGD and its variants have become the standard tool to train Deep Neural Networks. In this paper, we focus on the recently proposed variant Lookahead, which improves upon SGD in a wide range of applications. Following this success, we study an extension of this algorithm, the \emph{Multilayer Lookahead} optimizer, which recursively wraps Lookahead around itself. We prove the convergence of Multilayer Lookahead with two layers to a stationary point of smooth non-convex functions with $O(\frac{1}{\sqrt{T}})$ rate. We also justify the improved generalization of both Lookahead over SGD, and of Multilayer Lookahead over Lookahead, by showing how they amplify the implicit regularization effect of SGD. We empirically verify our results and show that Multilayer Lookahead outperforms Lookahead on CIFAR-10 and CIFAR-100 classification tasks, and on GANs training on the MNIST dataset.
Implicit Gradient Alignment in Distributed and Federated Learning
Jun 25, 2021
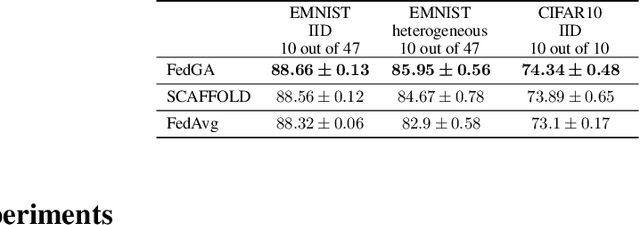
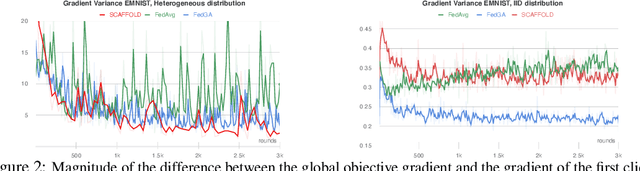
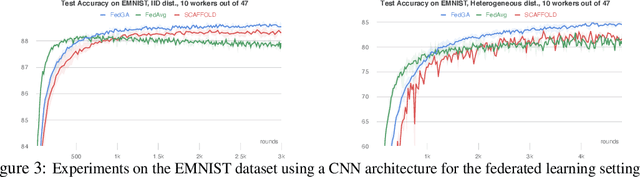
A major obstacle to achieving global convergence in distributed and federated learning is the misalignment of gradients across clients, or mini-batches due to heterogeneity and stochasticity of the distributed data. One way to alleviate this problem is to encourage the alignment of gradients across different clients throughout training. Our analysis reveals that this goal can be accomplished by utilizing the right optimization method that replicates the implicit regularization effect of SGD, leading to gradient alignment as well as improvements in test accuracies. Since the existence of this regularization in SGD completely relies on the sequential use of different mini-batches during training, it is inherently absent when training with large mini-batches. To obtain the generalization benefits of this regularization while increasing parallelism, we propose a novel GradAlign algorithm that induces the same implicit regularization while allowing the use of arbitrarily large batches in each update. We experimentally validate the benefit of our algorithm in different distributed and federated learning settings.
Dynamic Model Pruning with Feedback
Jun 12, 2020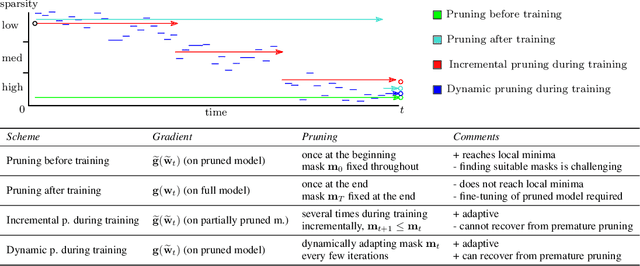
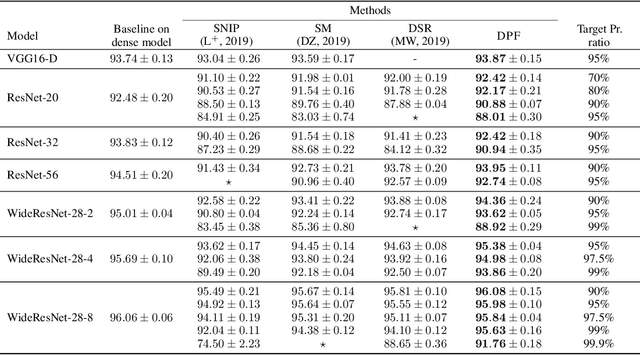
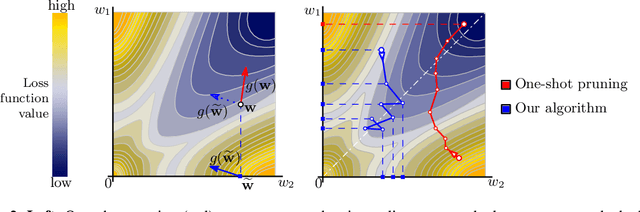
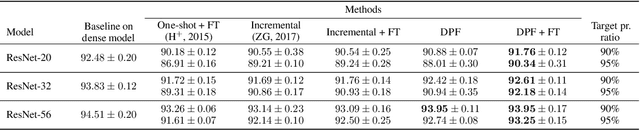
Deep neural networks often have millions of parameters. This can hinder their deployment to low-end devices, not only due to high memory requirements but also because of increased latency at inference. We propose a novel model compression method that generates a sparse trained model without additional overhead: by allowing (i) dynamic allocation of the sparsity pattern and (ii) incorporating feedback signal to reactivate prematurely pruned weights we obtain a performant sparse model in one single training pass (retraining is not needed, but can further improve the performance). We evaluate our method on CIFAR-10 and ImageNet, and show that the obtained sparse models can reach the state-of-the-art performance of dense models. Moreover, their performance surpasses that of models generated by all previously proposed pruning schemes.