 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards the Systematic Reporting of the Energy and Carbon Footprints of Machine Learning
Jan 31, 2020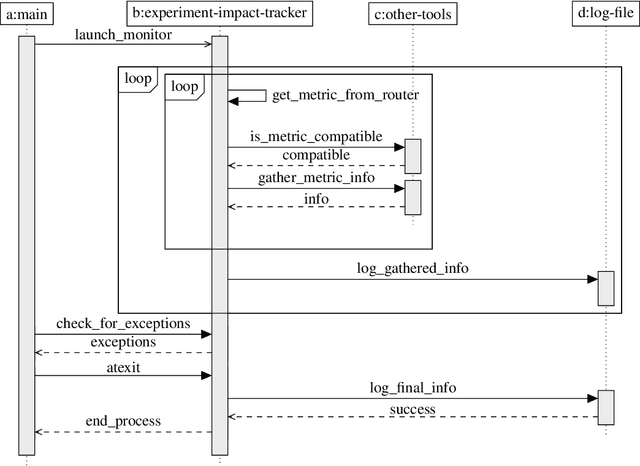
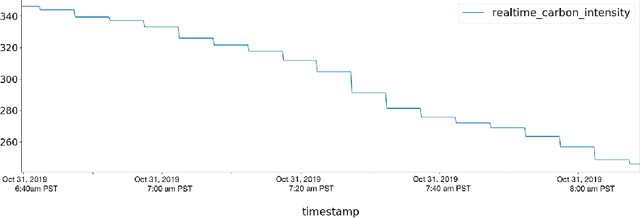
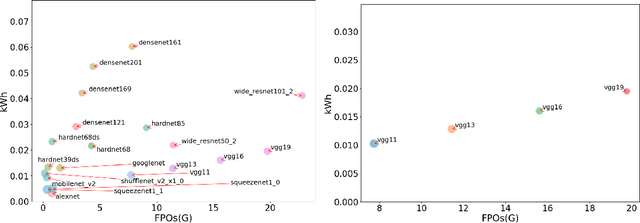
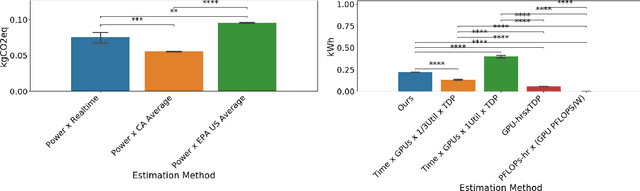
Accurate reporting of energy and carbon usage is essential for understanding the potential climate impacts of machine learning research. We introduce a framework that makes this easier by providing a simple interface for tracking realtime energy consumption and carbon emissions, as well as generating standardized online appendices. Utilizing this framework, we create a leaderboard for energy efficient reinforcement learning algorithms to incentivize responsible research in this area as an example for other areas of machine learning. Finally, based on case studies using our framework, we propose strategies for mitigation of carbon emissions and reduction of energy consumption. By making accounting easier, we hope to further the sustainable development of machine learning experiments and spur more research into energy efficient algorithms.
Off-Policy Policy Gradient Algorithms by Constraining the State Distribution Shift
Dec 01, 2019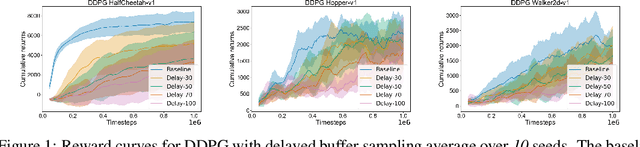
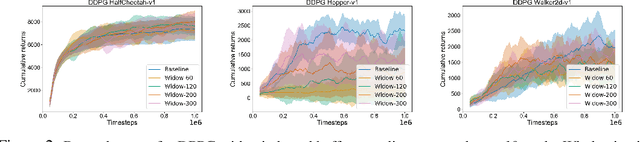
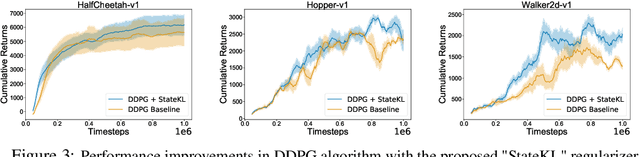
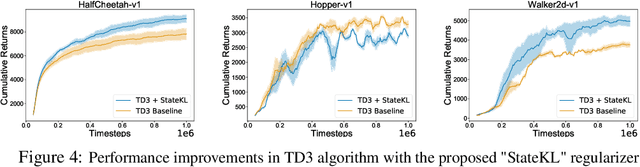
Off-policy deep reinforcement learning (RL) algorithms are incapable of learning solely from batch offline data without online interactions with the environment, due to the phenomenon known as \textit{extrapolation error}. This is often due to past data available in the replay buffer that may be quite different from the data distribution under the current policy. We argue that most off-policy learning methods fundamentally suffer from a \textit{state distribution shift} due to the mismatch between the state visitation distribution of the data collected by the behavior and target policies. This data distribution shift between current and past samples can significantly impact the performance of most modern off-policy based policy optimization algorithms. In this work, we first do a systematic analysis of state distribution mismatch in off-policy learning, and then develop a novel off-policy policy optimization method to constraint the state distribution shift. To do this, we first estimate the state distribution based on features of the state, using a density estimator and then develop a novel constrained off-policy gradient objective that minimizes the state distribution shift. Our experimental results on continuous control tasks show that minimizing this distribution mismatch can significantly improve performance in most popular practical off-policy policy gradient algorithms.
Exploiting Spatial Invariance for Scalable Unsupervised Object Tracking
Nov 20, 2019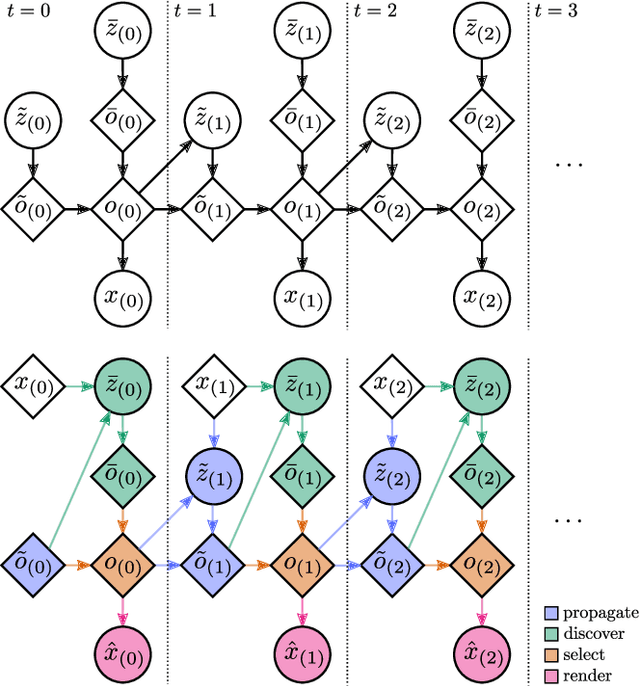
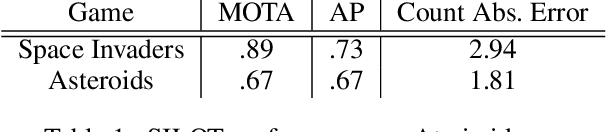
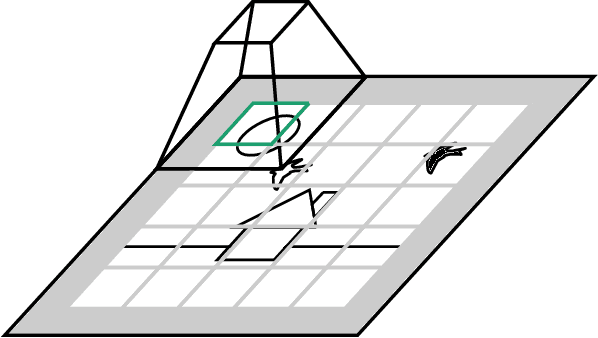
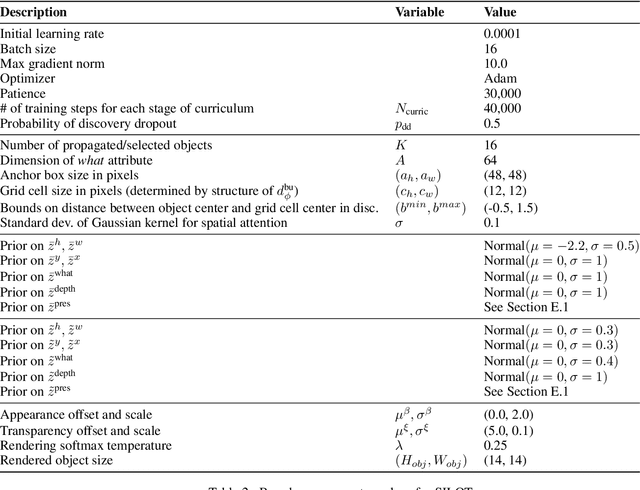
The ability to detect and track objects in the visual world is a crucial skill for any intelligent agent, as it is a necessary precursor to any object-level reasoning process. Moreover, it is important that agents learn to track objects without supervision (i.e. without access to annotated training videos) since this will allow agents to begin operating in new environments with minimal human assistance. The task of learning to discover and track objects in videos, which we call \textit{unsupervised object tracking}, has grown in prominence in recent years; however, most architectures that address it still struggle to deal with large scenes containing many objects. In the current work, we propose an architecture that scales well to the large-scene, many-object setting by employing spatially invariant computations (convolutions and spatial attention) and representations (a spatially local object specification scheme). In a series of experiments, we demonstrate a number of attractive features of our architecture; most notably, that it outperforms competing methods at tracking objects in cluttered scenes with many objects, and that it can generalize well to videos that are larger and/or contain more objects than videos encountered during training.
Online Learned Continual Compression with Stacked Quantization Module
Nov 19, 2019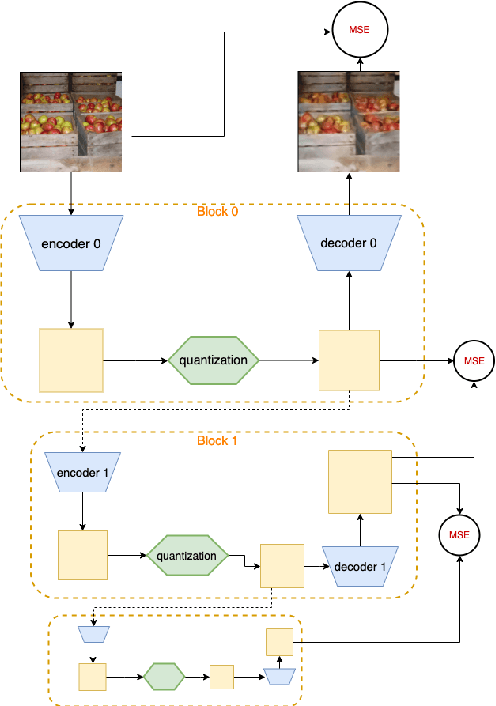


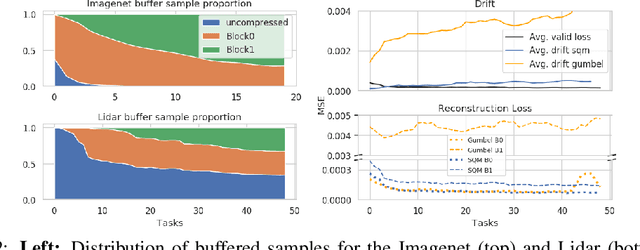
We introduce and study the problem of Online Continual Compression, where one attempts to learn to compress and store a representative dataset from a non i.i.d data stream, while only observing each sample once. This problem is highly relevant for downstream online continual learning tasks, as well as standard learning methods under resource constrained data collection. To address this we propose a new architecture which Stacks Quantization Modules (SQM), consisting of a series of discrete autoencoders, each equipped with their own memory. Every added module is trained to reconstruct the latent space of the previous module using fewer bits, allowing the learned representation to become more compact as training progresses. This modularity has several advantages: 1) moderate compressions are quickly available early in training, which is crucial for remembering the early tasks, 2) as more data needs to be stored, earlier data becomes more compressed, freeing memory, 3) unlike previous methods, our approach does not require pretraining, even on challenging datasets. We show several potential applications of this method. We first replace the episodic memory used in Experience Replay with SQM, leading to significant gains on standard continual learning benchmarks using a fixed memory budget. We then apply our method to online compression of larger images like those from Imagenet, and show that it is also effective with other modalities, such as LiDAR data.
MVFST-RL: An Asynchronous RL Framework for Congestion Control with Delayed Actions
Oct 30, 2019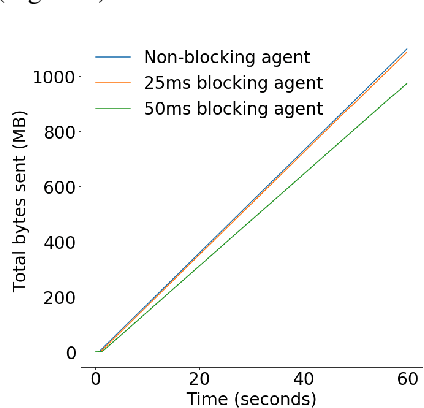
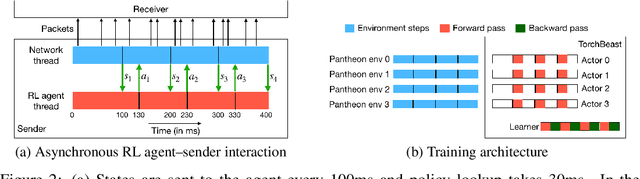
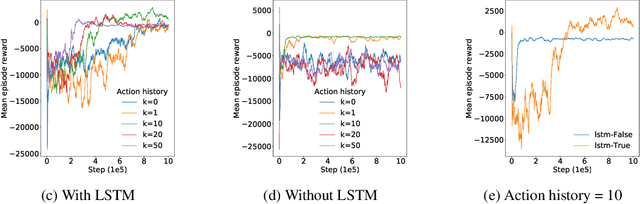
Effective network congestion control strategies are key to keeping the Internet (or any large computer network) operational. Network congestion control has been dominated by hand-crafted heuristics for decades. Recently, ReinforcementLearning (RL) has emerged as an alternative to automatically optimize such control strategies. Research so far has primarily considered RL interfaces which block the sender while an agent considers its next action. This is largely an artifact of building on top of frameworks designed for RL in games (e.g. OpenAI Gym). However, this does not translate to real-world networking environments, where a network sender waiting on a policy without sending data leads to under-utilization of bandwidth. We instead propose to formulate congestion control with an asynchronous RL agent that handles delayed actions. We present MVFST-RL, a scalable framework for congestion control in the QUIC transport protocol that leverages state-of-the-art in asynchronous RL training with off-policy correction. We analyze modeling improvements to mitigate the deviation from Markovian dynamics, and evaluate our method on emulated networks from the Pantheon benchmark platform. The source code is publicly available at https://github.com/facebookresearch/mvfst-rl.
Improving Sample Efficiency in Model-Free Reinforcement Learning from Images
Oct 07, 2019
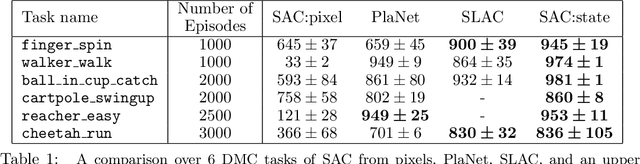
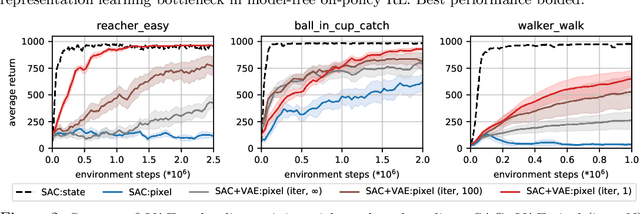
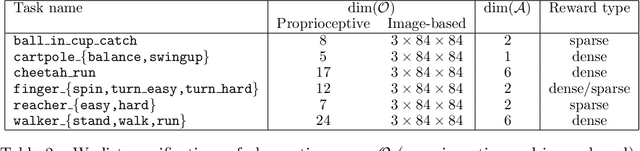
Training an agent to solve control tasks directly from high-dimensional images with model-free reinforcement learning (RL) has proven difficult. The agent needs to learn a latent representation together with a control policy to perform the task. Fitting a high-capacity encoder using a scarce reward signal is not only sample inefficient, but also prone to suboptimal convergence. Two ways to improve sample efficiency are to extract relevant features for the task and use off-policy algorithms. We dissect various approaches of learning good latent features, and conclude that the image reconstruction loss is the essential ingredient that enables efficient and stable representation learning in image-based RL. Following these findings, we devise an off-policy actor-critic algorithm with an auxiliary decoder that trains end-to-end and matches state-of-the-art performance across both model-free and model-based algorithms on many challenging control tasks. We release our code to encourage future research on image-based RL.
Benchmarking Batch Deep Reinforcement Learning Algorithms
Oct 03, 2019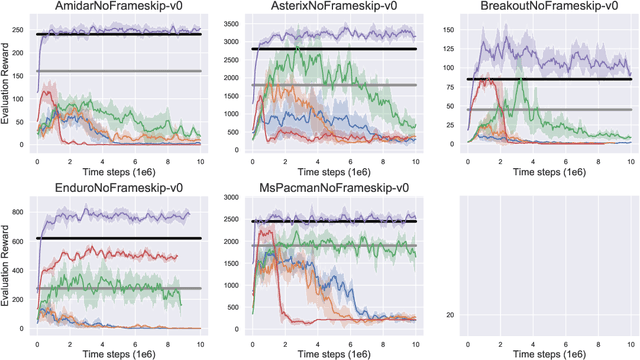
Widely-used deep reinforcement learning algorithms have been shown to fail in the batch setting--learning from a fixed data set without interaction with the environment. Following this result, there have been several papers showing reasonable performances under a variety of environments and batch settings. In this paper, we benchmark the performance of recent off-policy and batch reinforcement learning algorithms under unified settings on the Atari domain, with data generated by a single partially-trained behavioral policy. We find that under these conditions, many of these algorithms underperform DQN trained online with the same amount of data, as well as the partially-trained behavioral policy. To introduce a strong baseline, we adapt the Batch-Constrained Q-learning algorithm to a discrete-action setting, and show it outperforms all existing algorithms at this task.
Attraction-Repulsion Actor-Critic for Continuous Control Reinforcement Learning
Sep 24, 2019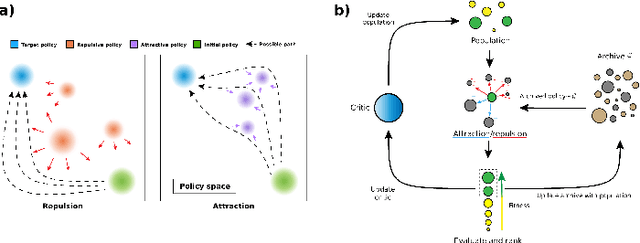
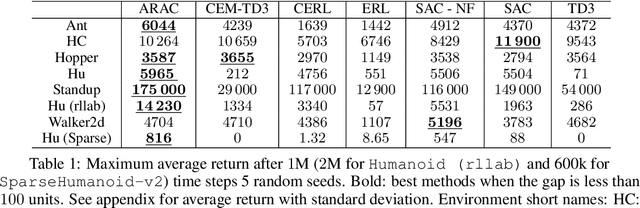
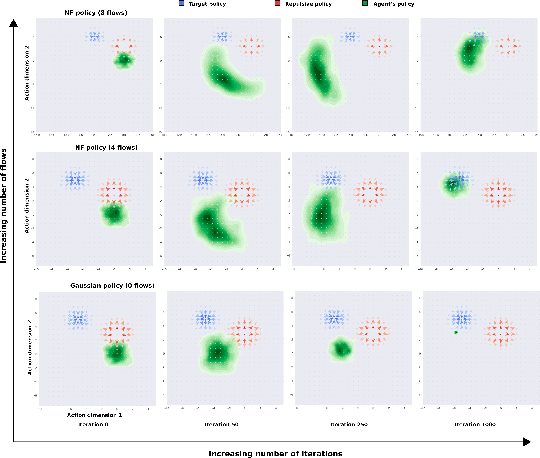
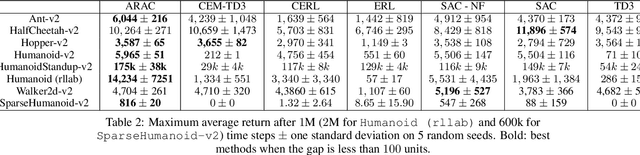
Continuous control tasks in reinforcement learning are important because they provide an important framework for learning in high-dimensional state spaces with deceptive rewards, where the agent can easily become trapped into suboptimal solutions. One way to avoid local optima is to use a population of agents to ensure coverage of the policy space, yet learning a population with the "best" coverage is still an open problem. In this work, we present a novel approach to population-based RL in continuous control that leverages properties of normalizing flows to perform attractive and repulsive operations between current members of the population and previously observed policies. Empirical results on the MuJoCo suite demonstrate a high performance gain for our algorithm compared to prior work, including Soft-Actor Critic (SAC).
No Press Diplomacy: Modeling Multi-Agent Gameplay
Sep 04, 2019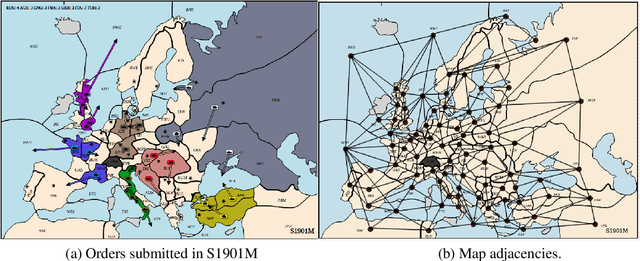
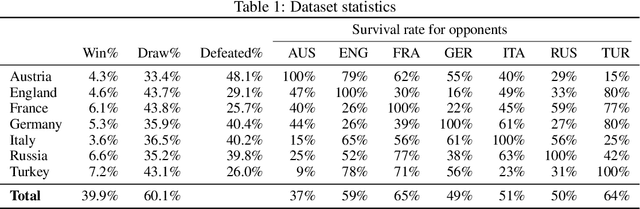
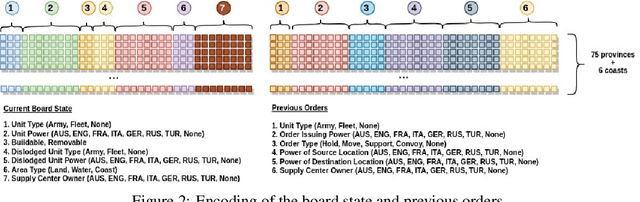
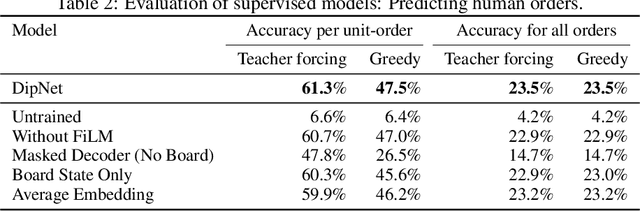
Diplomacy is a seven-player non-stochastic, non-cooperative game, where agents acquire resources through a mix of teamwork and betrayal. Reliance on trust and coordination makes Diplomacy the first non-cooperative multi-agent benchmark for complex sequential social dilemmas in a rich environment. In this work, we focus on training an agent that learns to play the No Press version of Diplomacy where there is no dedicated communication channel between players. We present DipNet, a neural-network-based policy model for No Press Diplomacy. The model was trained on a new dataset of more than 150,000 human games. Our model is trained by supervised learning (SL) from expert trajectories, which is then used to initialize a reinforcement learning (RL) agent trained through self-play. Both the SL and RL agents demonstrate state-of-the-art No Press performance by beating popular rule-based bots.
CLUTRR: A Diagnostic Benchmark for Inductive Reasoning from Text
Sep 04, 2019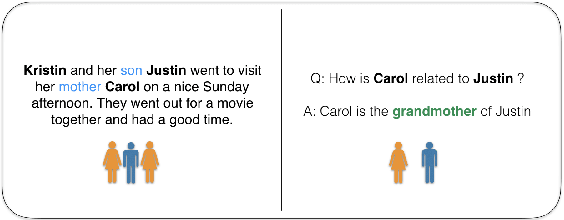
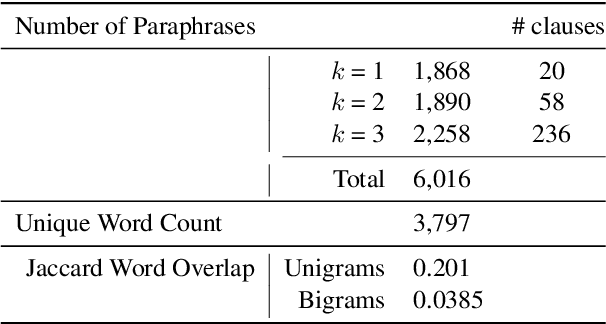
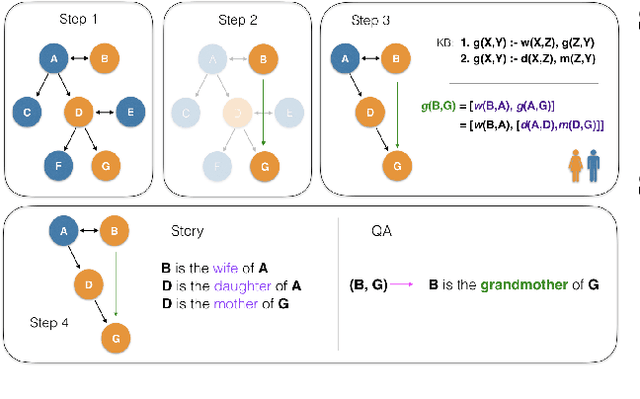
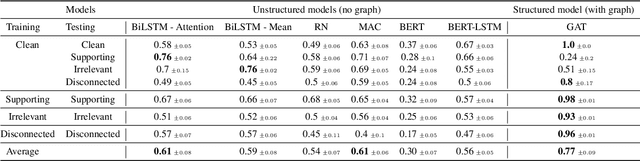
The recent success of natural language understanding (NLU) systems has been troubled by results highlighting the failure of these models to generalize in a systematic and robust way. In this work, we introduce a diagnostic benchmark suite, named CLUTRR, to clarify some key issues related to the robustness and systematicity of NLU systems. Motivated by classic work on inductive logic programming, CLUTRR requires that an NLU system infer kinship relations between characters in short stories. Successful performance on this task requires both extracting relationships between entities, as well as inferring the logical rules governing these relationships. CLUTRR allows us to precisely measure a model's ability for systematic generalization by evaluating on held-out combinations of logical rules, and it allows us to evaluate a model's robustness by adding curated noise facts. Our empirical results highlight a substantial performance gap between state-of-the-art NLU models (e.g., BERT and MAC) and a graph neural network model that works directly with symbolic inputs---with the graph-based model exhibiting both stronger generalization and greater robustness.