 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Reinforcement Learning that Matters
Nov 24, 2017
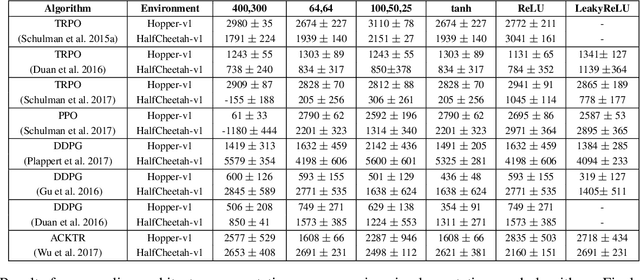

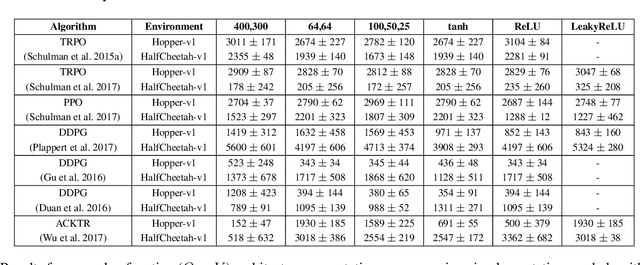
In recent years, significant progress has been made in solving challenging problems across various domains using deep reinforcement learning (RL). Reproducing existing work and accurately judging the improvements offered by novel methods is vital to sustaining this progress. Unfortunately, reproducing results for state-of-the-art deep RL methods is seldom straightforward. In particular, non-determinism in standard benchmark environments, combined with variance intrinsic to the methods, can make reported results tough to interpret. Without significance metrics and tighter standardization of experimental reporting, it is difficult to determine whether improvements over the prior state-of-the-art are meaningful. In this paper, we investigate challenges posed by reproducibility, proper experimental techniques, and reporting procedures. We illustrate the variability in reported metrics and results when comparing against common baselines and suggest guidelines to make future results in deep RL more reproducible. We aim to spur discussion about how to ensure continued progress in the field by minimizing wasted effort stemming from results that are non-reproducible and easily misinterpreted.
OptionGAN: Learning Joint Reward-Policy Options using Generative Adversarial Inverse Reinforcement Learning
Nov 24, 2017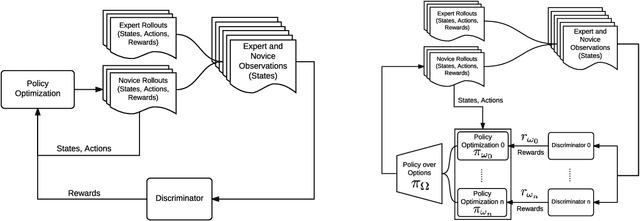

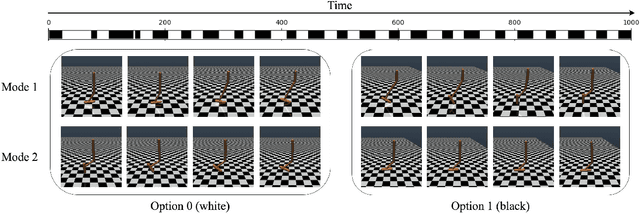
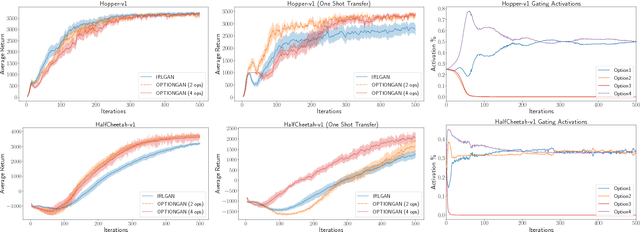
Reinforcement learning has shown promise in learning policies that can solve complex problems. However, manually specifying a good reward function can be difficult, especially for intricate tasks. Inverse reinforcement learning offers a useful paradigm to learn the underlying reward function directly from expert demonstrations. Yet in reality, the corpus of demonstrations may contain trajectories arising from a diverse set of underlying reward functions rather than a single one. Thus, in inverse reinforcement learning, it is useful to consider such a decomposition. The options framework in reinforcement learning is specifically designed to decompose policies in a similar light. We therefore extend the options framework and propose a method to simultaneously recover reward options in addition to policy options. We leverage adversarial methods to learn joint reward-policy options using only observed expert states. We show that this approach works well in both simple and complex continuous control tasks and shows significant performance increases in one-shot transfer learning.
Ethical Challenges in Data-Driven Dialogue Systems
Nov 24, 2017

The use of dialogue systems as a medium for human-machine interaction is an increasingly prevalent paradigm. A growing number of dialogue systems use conversation strategies that are learned from large datasets. There are well documented instances where interactions with these system have resulted in biased or even offensive conversations due to the data-driven training process. Here, we highlight potential ethical issues that arise in dialogue systems research, including: implicit biases in data-driven systems, the rise of adversarial examples, potential sources of privacy violations, safety concerns, special considerations for reinforcement learning systems, and reproducibility concerns. We also suggest areas stemming from these issues that deserve further investigation. Through this initial survey, we hope to spur research leading to robust, safe, and ethically sound dialogue systems.
ACtuAL: Actor-Critic Under Adversarial Learning
Nov 13, 2017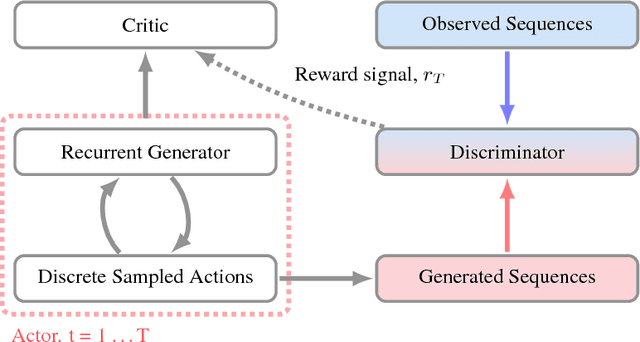
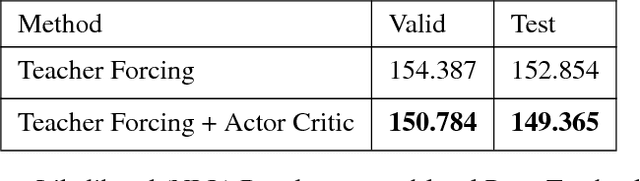
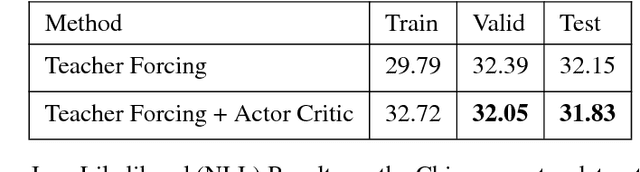

Generative Adversarial Networks (GANs) are a powerful framework for deep generative modeling. Posed as a two-player minimax problem, GANs are typically trained end-to-end on real-valued data and can be used to train a generator of high-dimensional and realistic images. However, a major limitation of GANs is that training relies on passing gradients from the discriminator through the generator via back-propagation. This makes it fundamentally difficult to train GANs with discrete data, as generation in this case typically involves a non-differentiable function. These difficulties extend to the reinforcement learning setting when the action space is composed of discrete decisions. We address these issues by reframing the GAN framework so that the generator is no longer trained using gradients through the discriminator, but is instead trained using a learned critic in the actor-critic framework with a Temporal Difference (TD) objective. This is a natural fit for sequence modeling and we use it to achieve improvements on language modeling tasks over the standard Teacher-Forcing methods.
A Deep Reinforcement Learning Chatbot
Nov 05, 2017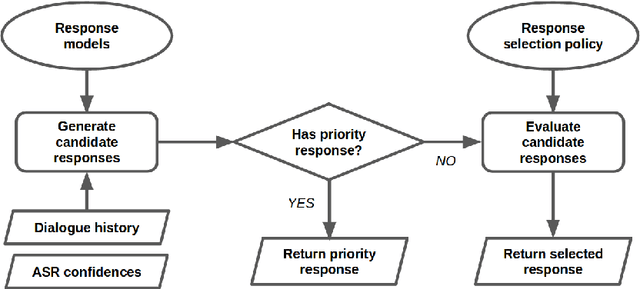
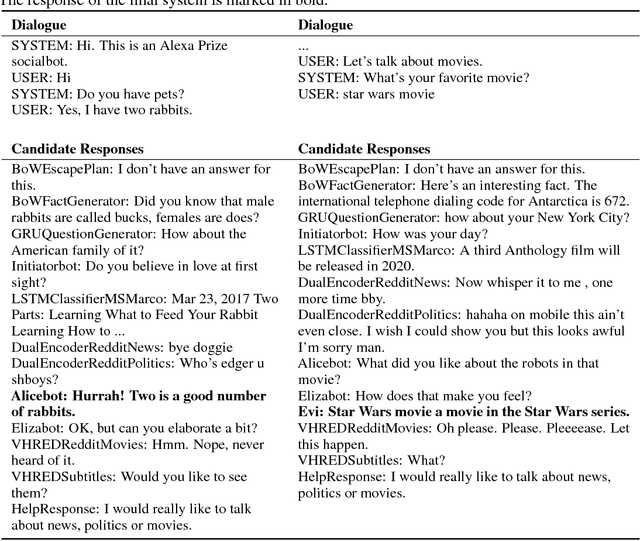
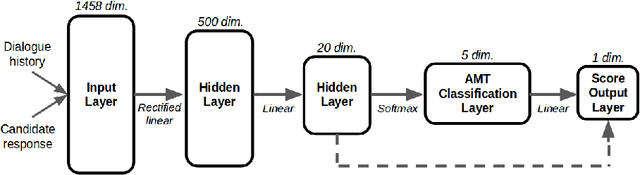

We present MILABOT: a deep reinforcement learning chatbot developed by the Montreal Institute for Learning Algorithms (MILA) for the Amazon Alexa Prize competition. MILABOT is capable of conversing with humans on popular small talk topics through both speech and text. The system consists of an ensemble of natural language generation and retrieval models, including template-based models, bag-of-words models, sequence-to-sequence neural network and latent variable neural network models. By applying reinforcement learning to crowdsourced data and real-world user interactions, the system has been trained to select an appropriate response from the models in its ensemble. The system has been evaluated through A/B testing with real-world users, where it performed significantly better than many competing systems. Due to its machine learning architecture, the system is likely to improve with additional data.
Piecewise Latent Variables for Neural Variational Text Processing
Sep 23, 2017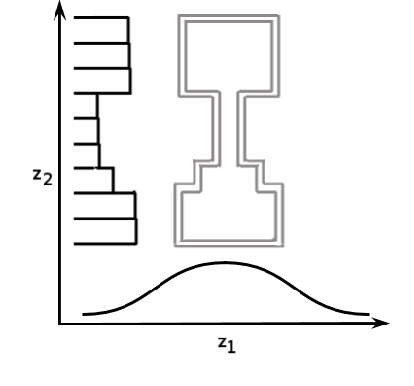


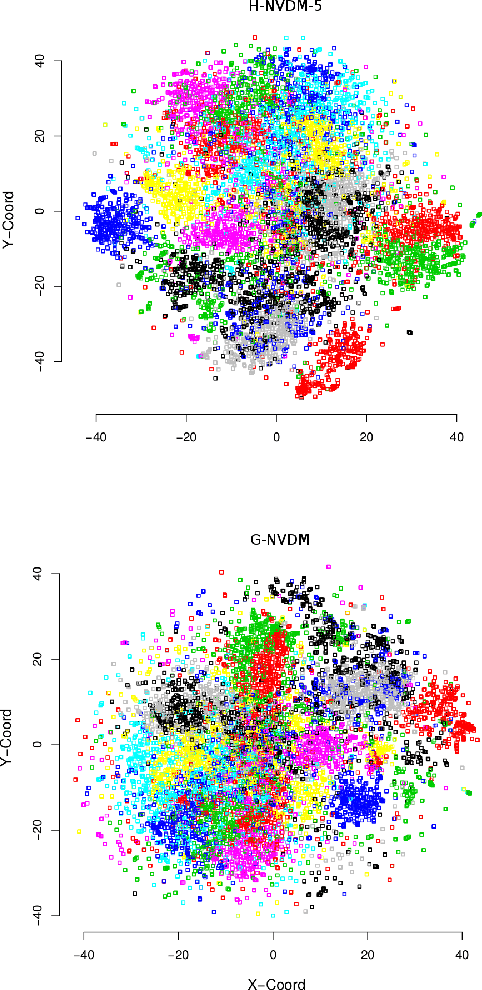
Advances in neural variational inference have facilitated the learning of powerful directed graphical models with continuous latent variables, such as variational autoencoders. The hope is that such models will learn to represent rich, multi-modal latent factors in real-world data, such as natural language text. However, current models often assume simplistic priors on the latent variables - such as the uni-modal Gaussian distribution - which are incapable of representing complex latent factors efficiently. To overcome this restriction, we propose the simple, but highly flexible, piecewise constant distribution. This distribution has the capacity to represent an exponential number of modes of a latent target distribution, while remaining mathematically tractable. Our results demonstrate that incorporating this new latent distribution into different models yields substantial improvements in natural language processing tasks such as document modeling and natural language generation for dialogue.
Independently Controllable Factors
Aug 25, 2017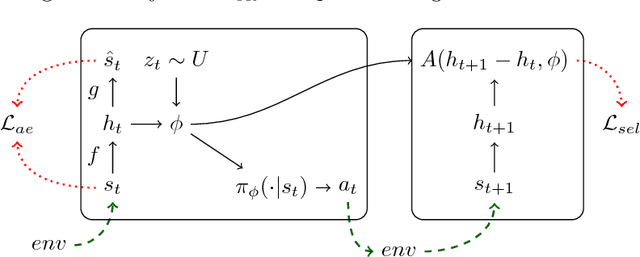
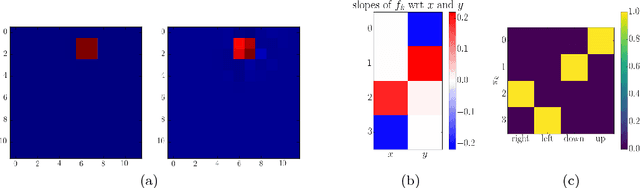
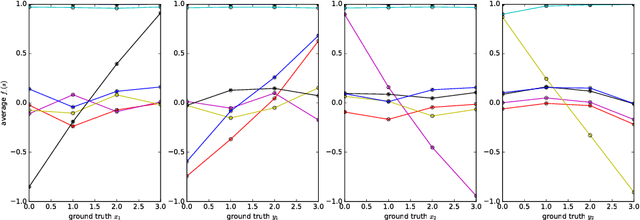
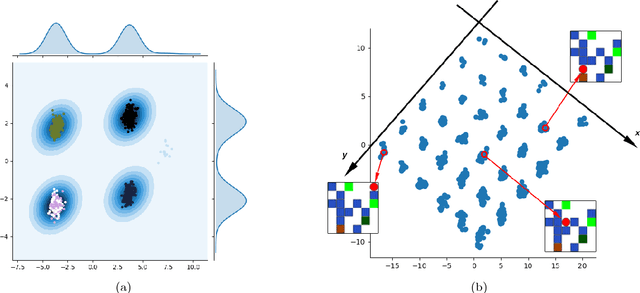
It has been postulated that a good representation is one that disentangles the underlying explanatory factors of variation. However, it remains an open question what kind of training framework could potentially achieve that. Whereas most previous work focuses on the static setting (e.g., with images), we postulate that some of the causal factors could be discovered if the learner is allowed to interact with its environment. The agent can experiment with different actions and observe their effects. More specifically, we hypothesize that some of these factors correspond to aspects of the environment which are independently controllable, i.e., that there exists a policy and a learnable feature for each such aspect of the environment, such that this policy can yield changes in that feature with minimal changes to other features that explain the statistical variations in the observed data. We propose a specific objective function to find such factors and verify experimentally that it can indeed disentangle independently controllable aspects of the environment without any extrinsic reward signal.
Streaming kernel regression with provably adaptive mean, variance, and regularization
Aug 02, 2017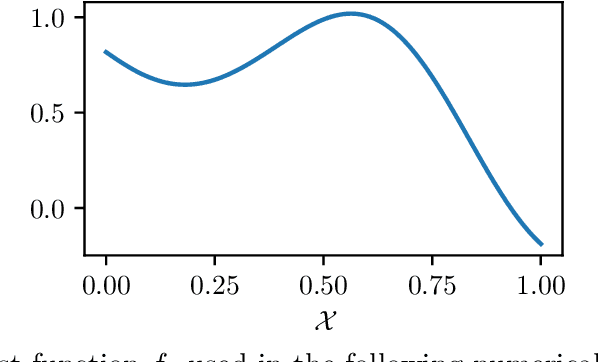
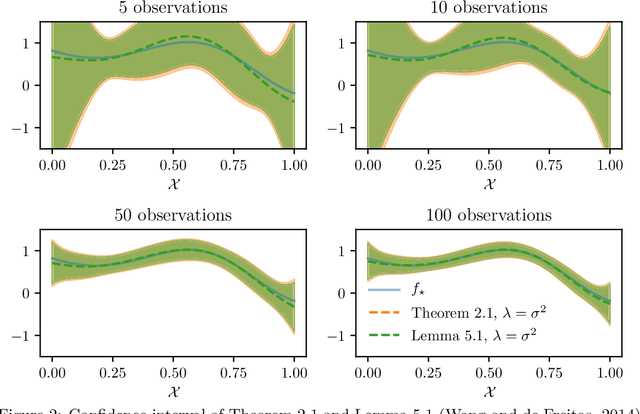
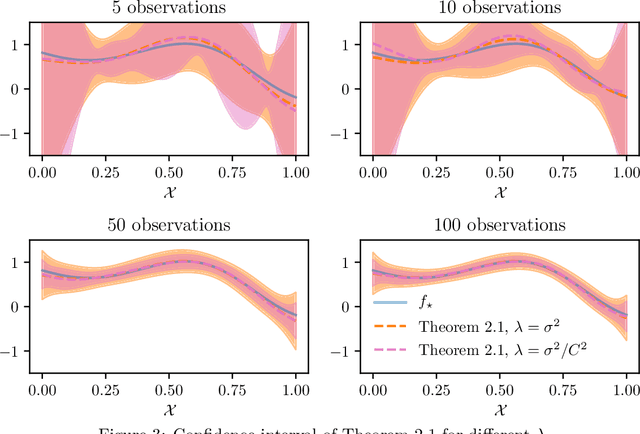
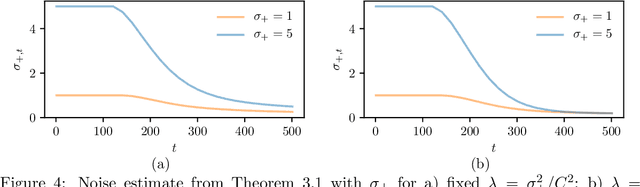
We consider the problem of streaming kernel regression, when the observations arrive sequentially and the goal is to recover the underlying mean function, assumed to belong to an RKHS. The variance of the noise is not assumed to be known. In this context, we tackle the problem of tuning the regularization parameter adaptively at each time step, while maintaining tight confidence bounds estimates on the value of the mean function at each point. To this end, we first generalize existing results for finite-dimensional linear regression with fixed regularization and known variance to the kernel setup with a regularization parameter allowed to be a measurable function of past observations. Then, using appropriate self-normalized inequalities we build upper and lower bound estimates for the variance, leading to Bersntein-like concentration bounds. The later is used in order to define the adaptive regularization. The bounds resulting from our technique are valid uniformly over all observation points and all time steps, and are compared against the literature with numerical experiments. Finally, the potential of these tools is illustrated by an application to kernelized bandits, where we revisit the Kernel UCB and Kernel Thompson Sampling procedures, and show the benefits of the novel adaptive kernel tuning strategy.
MACA: A Modular Architecture for Conversational Agents
May 03, 2017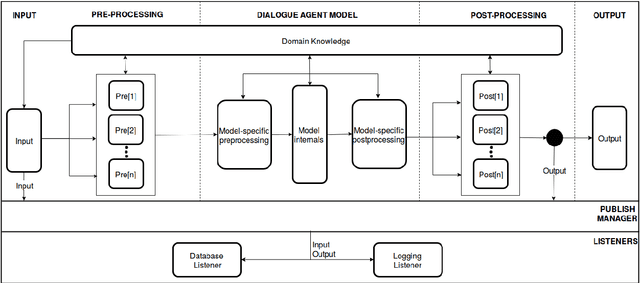
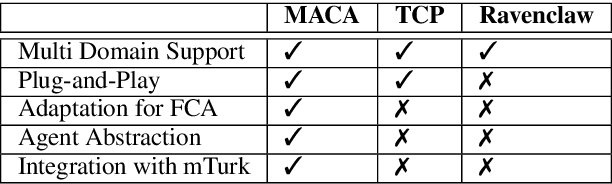
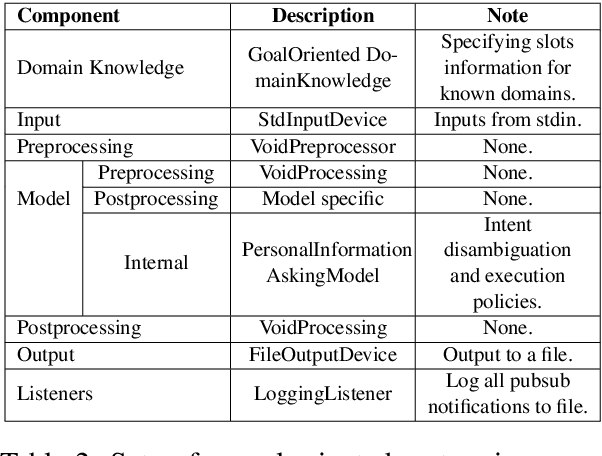
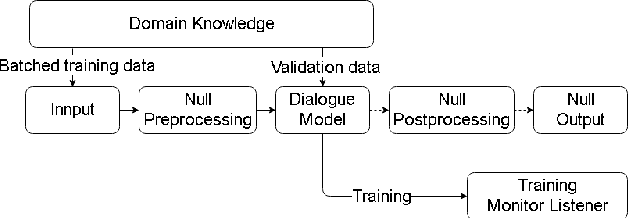
We propose a software architecture designed to ease the implementation of dialogue systems. The Modular Architecture for Conversational Agents (MACA) uses a plug-n-play style that allows quick prototyping, thereby facilitating the development of new techniques and the reproduction of previous work. The architecture separates the domain of the conversation from the agent's dialogue strategy, and as such can be easily extended to multiple domains. MACA provides tools to host dialogue agents on Amazon Mechanical Turk (mTurk) for data collection and allows processing of other sources of training data. The current version of the framework already incorporates several domains and existing dialogue strategies from the recent literature.
Independently Controllable Features
Mar 22, 2017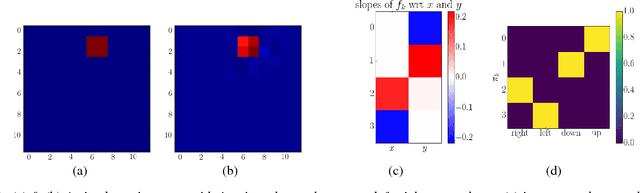
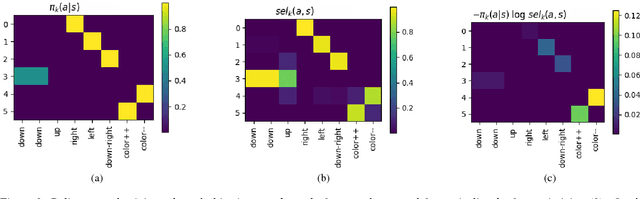
Finding features that disentangle the different causes of variation in real data is a difficult task, that has nonetheless received considerable attention in static domains like natural images. Interactive environments, in which an agent can deliberately take actions, offer an opportunity to tackle this task better, because the agent can experiment with different actions and observe their effects. We introduce the idea that in interactive environments, latent factors that control the variation in observed data can be identified by figuring out what the agent can control. We propose a naive method to find factors that explain or measure the effect of the actions of a learner, and test it in illustrative experiments.