 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpectralFormer: Rethinking Hyperspectral Image Classification with Transformers
Jul 07, 2021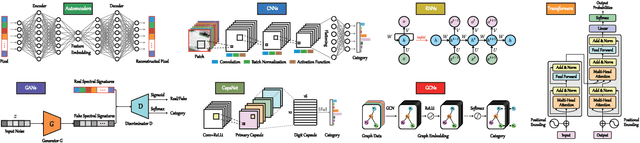
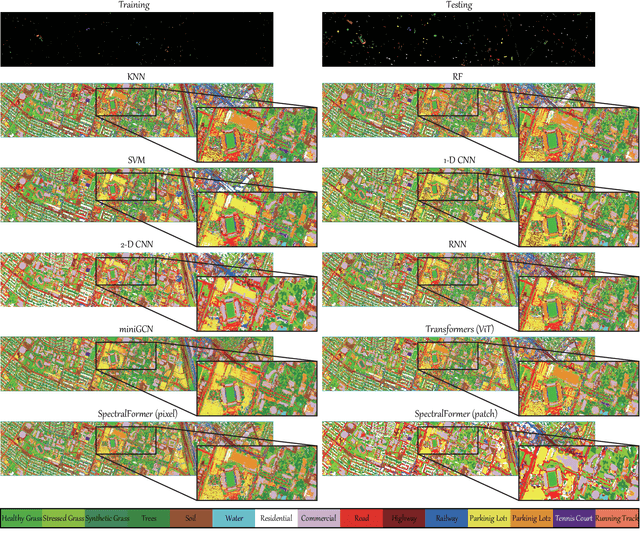
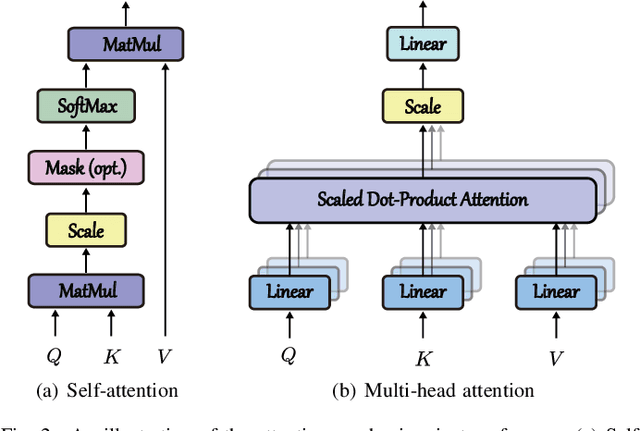
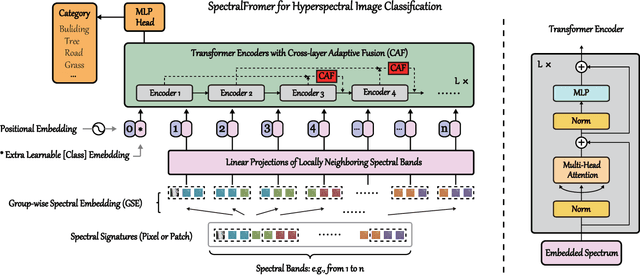
Hyperspectral (HS) images are characterized by approximately contiguous spectral information, enabling the fine identification of materials by capturing subtle spectral discrepancies. Owing to their excellent locally contextual modeling ability, convolutional neural networks (CNNs) have been proven to be a powerful feature extractor in HS image classification. However, CNNs fail to mine and represent the sequence attributes of spectral signatures well due to the limitations of their inherent network backbone. To solve this issue, we rethink HS image classification from a sequential perspective with transformers, and propose a novel backbone network called \ul{SpectralFormer}. Beyond band-wise representations in classic transformers, SpectralFormer is capable of learning spectrally local sequence information from neighboring bands of HS images, yielding group-wise spectral embeddings. More significantly, to reduce the possibility of losing valuable information in the layer-wise propagation process, we devise a cross-layer skip connection to convey memory-like components from shallow to deep layers by adaptively learning to fuse "soft" residuals across layers. It is worth noting that the proposed SpectralFormer is a highly flexible backbone network, which can be applicable to both pixel- and patch-wise inputs. We evaluate the classification performance of the proposed SpectralFormer on three HS datasets by conducting extensive experiments, showing the superiority over classic transformers and achieving a significant improvement in comparison with state-of-the-art backbone networks. The codes of this work will be available at \url{https://sites.google.com/view/danfeng-hong} for the sake of reproducibility.
Rotation Equivariant Feature Image Pyramid Network for Object Detection in Optical Remote Sensing Imagery
Jun 03, 2021
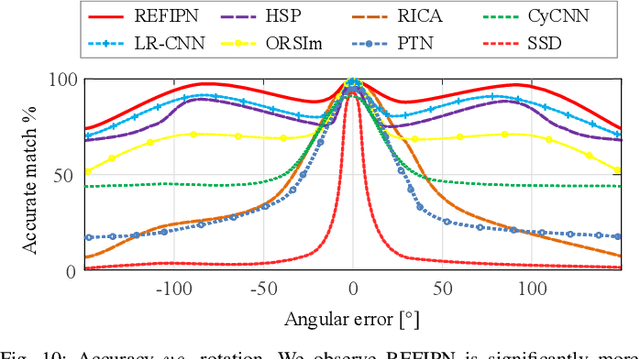
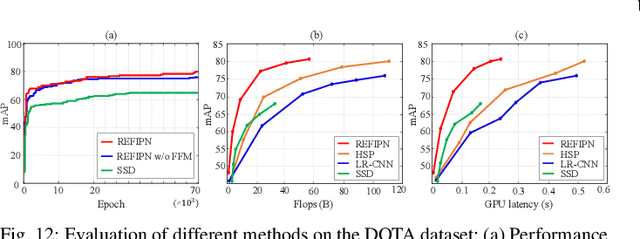
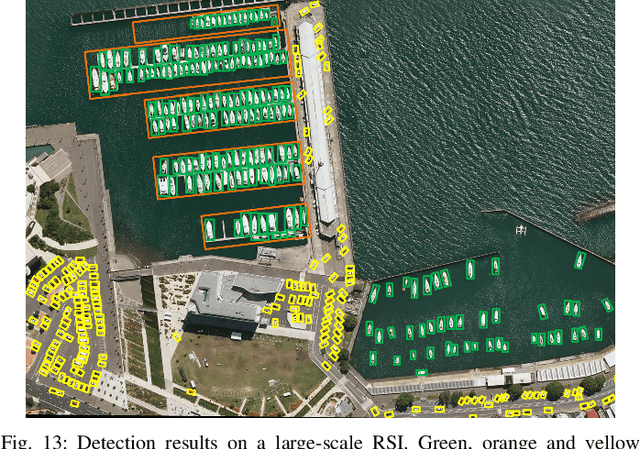
Over the last few years, there has been substantial progress in object detection on remote sensing images (RSIs) where objects are generally distributed with large-scale variations and have different types of orientations. Nevertheless, most of the current convolution neural network approaches lack the ability to deal with the challenges such as size and rotation variations. To address these problems, we propose the rotation equivariant feature image pyramid network (REFIPN), an image pyramid network based on rotation equivariance convolution. The proposed pyramid network extracts features in a wide range of scales and orientations by using novel convolution filters. These features are used to generate vector fields and determine the weight and angle of the highest-scoring orientation for all spatial locations on an image. Finally, the extracted features go through the prediction layers of the detector. The detection performance of the proposed model is validated on two commonly used aerial benchmarks and the results show our propose model can achieve state-of-the-art performance with satisfactory efficiency.
An Attention-Fused Network for Semantic Segmentation of Very-High-Resolution Remote Sensing Imagery
May 28, 2021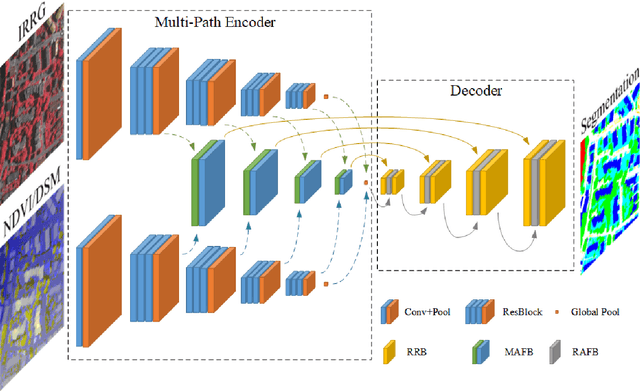
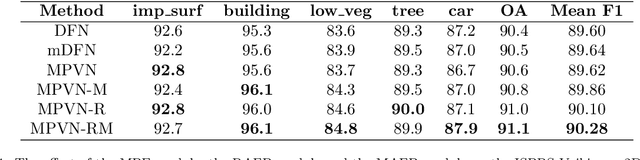
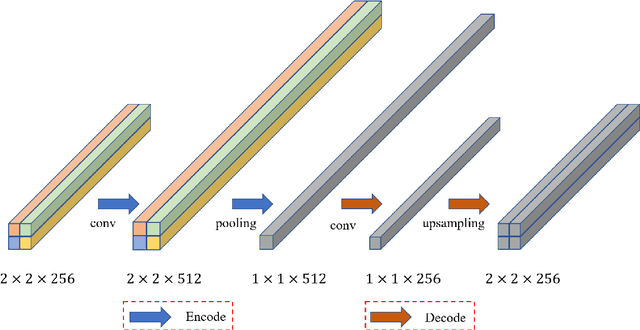
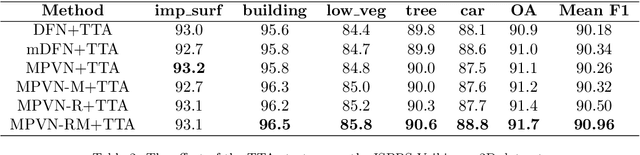
Semantic segmentation is an essential part of deep learning. In recent years, with the development of remote sensing big data, semantic segmentation has been increasingly used in remote sensing. Deep convolutional neural networks (DCNNs) face the challenge of feature fusion: very-high-resolution remote sensing image multisource data fusion can increase the network's learnable information, which is conducive to correctly classifying target objects by DCNNs; simultaneously, the fusion of high-level abstract features and low-level spatial features can improve the classification accuracy at the border between target objects. In this paper, we propose a multipath encoder structure to extract features of multipath inputs, a multipath attention-fused block module to fuse multipath features, and a refinement attention-fused block module to fuse high-level abstract features and low-level spatial features. Furthermore, we propose a novel convolutional neural network architecture, named attention-fused network (AFNet). Based on our AFNet, we achieve state-of-the-art performance with an overall accuracy of 91.7% and a mean F1 score of 90.96% on the ISPRS Vaihingen 2D dataset and an overall accuracy of 92.1% and a mean F1 score of 93.44% on the ISPRS Potsdam 2D dataset.
* 35 pages. Published by ISPRS Journal of Photogrammetry and Remote Sensing
Multimodal Remote Sensing Benchmark Datasets for Land Cover Classification with A Shared and Specific Feature Learning Model
May 21, 2021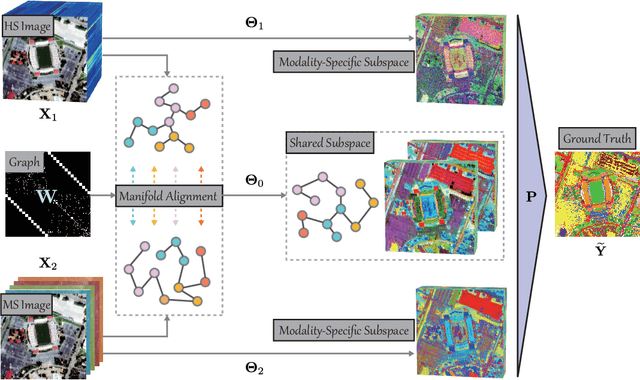

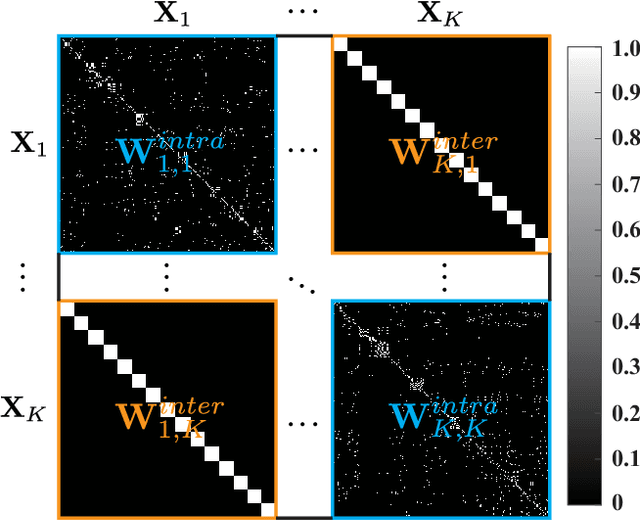
As remote sensing (RS) data obtained from different sensors become available largely and openly, multimodal data processing and analysis techniques have been garnering increasing interest in the RS and geoscience community. However, due to the gap between different modalities in terms of imaging sensors, resolutions, and contents, embedding their complementary information into a consistent, compact, accurate, and discriminative representation, to a great extent, remains challenging. To this end, we propose a shared and specific feature learning (S2FL) model. S2FL is capable of decomposing multimodal RS data into modality-shared and modality-specific components, enabling the information blending of multi-modalities more effectively, particularly for heterogeneous data sources. Moreover, to better assess multimodal baselines and the newly-proposed S2FL model, three multimodal RS benchmark datasets, i.e., Houston2013 -- hyperspectral and multispectral data, Berlin -- hyperspectral and synthetic aperture radar (SAR) data, Augsburg -- hyperspectral, SAR, and digital surface model (DSM) data, are released and used for land cover classification. Extensive experiments conducted on the three datasets demonstrate the superiority and advancement of our S2FL model in the task of land cover classification in comparison with previously-proposed state-of-the-art baselines. Furthermore, the baseline codes and datasets used in this paper will be made available freely at https://github.com/danfenghong/ISPRS_S2FL.
Endmember-Guided Unmixing Network (EGU-Net): A General Deep Learning Framework for Self-Supervised Hyperspectral Unmixing
May 21, 2021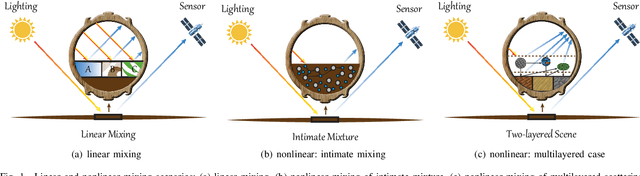
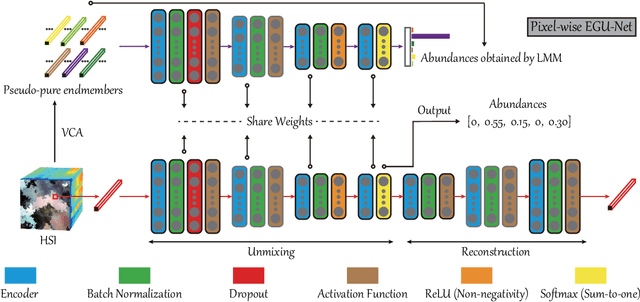
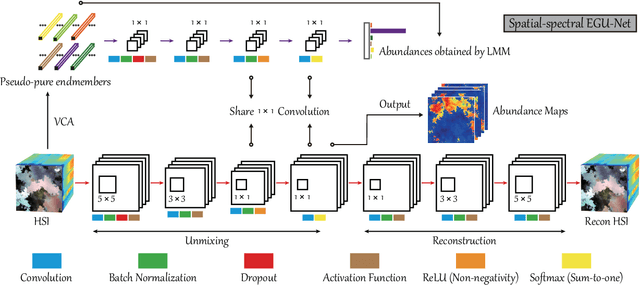

Over the past decades, enormous efforts have been made to improve the performance of linear or nonlinear mixing models for hyperspectral unmixing, yet their ability to simultaneously generalize various spectral variabilities and extract physically meaningful endmembers still remains limited due to the poor ability in data fitting and reconstruction and the sensitivity to various spectral variabilities. Inspired by the powerful learning ability of deep learning, we attempt to develop a general deep learning approach for hyperspectral unmixing, by fully considering the properties of endmembers extracted from the hyperspectral imagery, called endmember-guided unmixing network (EGU-Net). Beyond the alone autoencoder-like architecture, EGU-Net is a two-stream Siamese deep network, which learns an additional network from the pure or nearly-pure endmembers to correct the weights of another unmixing network by sharing network parameters and adding spectrally meaningful constraints (e.g., non-negativity and sum-to-one) towards a more accurate and interpretable unmixing solution. Furthermore, the resulting general framework is not only limited to pixel-wise spectral unmixing but also applicable to spatial information modeling with convolutional operators for spatial-spectral unmixing. Experimental results conducted on three different datasets with the ground-truth of abundance maps corresponding to each material demonstrate the effectiveness and superiority of the EGU-Net over state-of-the-art unmixing algorithms. The codes will be available from the website: https://github.com/danfenghong/IEEE_TNNLS_EGU-Net.
Cross-Modal and Multimodal Data Analysis Based on Functional Mapping of Spectral Descriptors and Manifold Regularization
May 12, 2021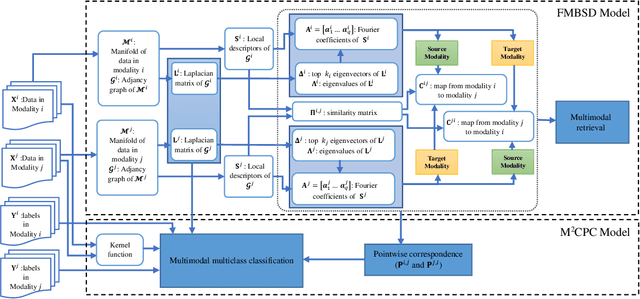
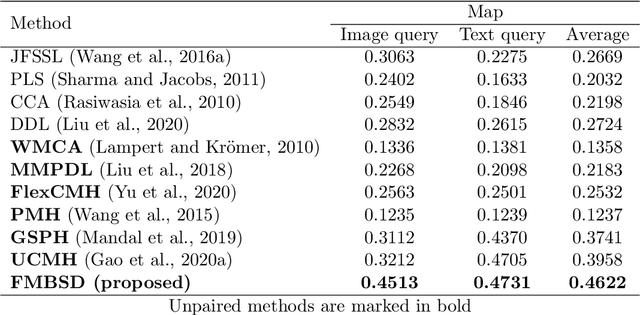
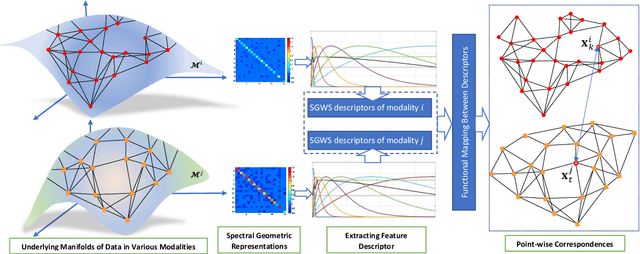
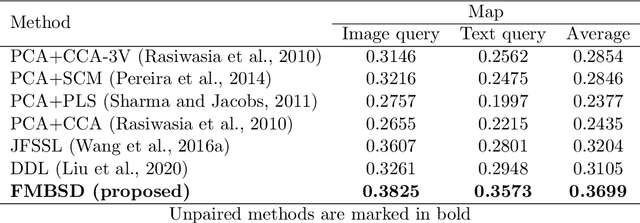
Multimodal manifold modeling methods extend the spectral geometry-aware data analysis to learning from several related and complementary modalities. Most of these methods work based on two major assumptions: 1) there are the same number of homogeneous data samples in each modality, and 2) at least partial correspondences between modalities are given in advance as prior knowledge. This work proposes two new multimodal modeling methods. The first method establishes a general analyzing framework to deal with the multimodal information problem for heterogeneous data without any specific prior knowledge. For this purpose, first, we identify the localities of each manifold by extracting local descriptors via spectral graph wavelet signatures (SGWS). Then, we propose a manifold regularization framework based on the functional mapping between SGWS descriptors (FMBSD) for finding the pointwise correspondences. The second method is a manifold regularized multimodal classification based on pointwise correspondences (M$^2$CPC) used for the problem of multiclass classification of multimodal heterogeneous, which the correspondences between modalities are determined based on the FMBSD method. The experimental results of evaluating the FMBSD method on three common cross-modal retrieval datasets and evaluating the (M$^2$CPC) method on three benchmark multimodal multiclass classification datasets indicate their effectiveness and superiority over state-of-the-art methods.
Using Low-rank Representation of Abundance Maps and Nonnegative Tensor Factorization for Hyperspectral Nonlinear Unmixing
Mar 30, 2021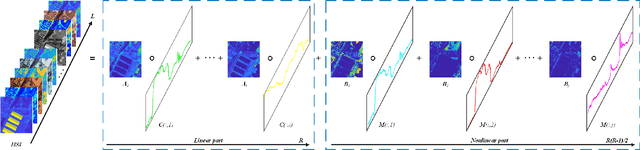

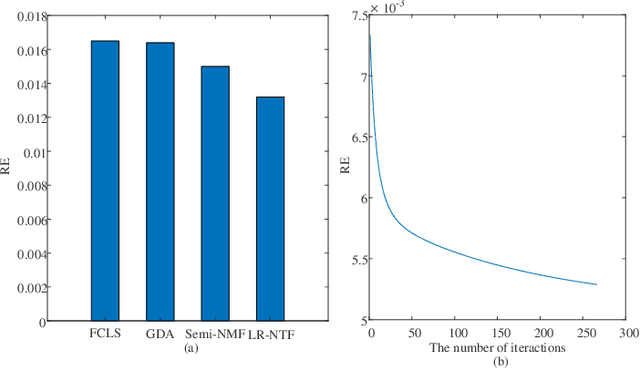
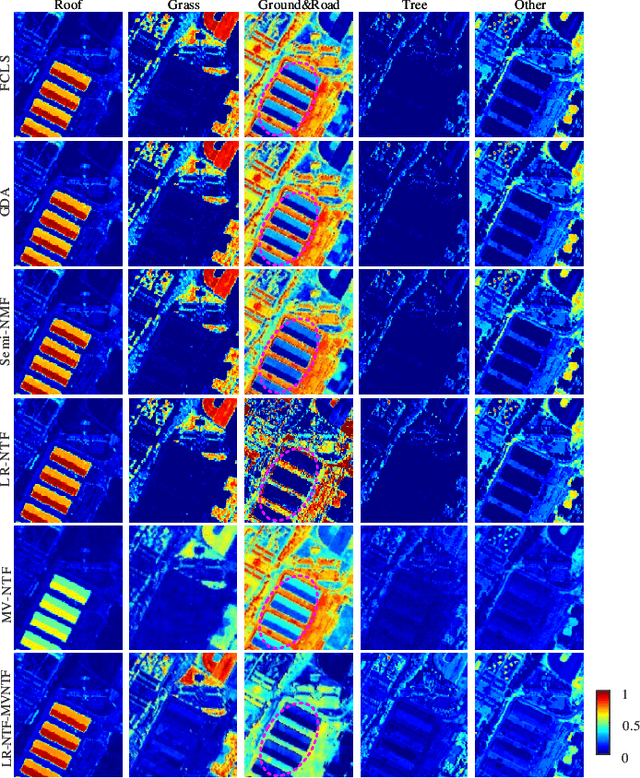
Tensor-based methods have been widely studied to attack inverse problems in hyperspectral imaging since a hyperspectral image (HSI) cube can be naturally represented as a third-order tensor, which can perfectly retain the spatial information in the image. In this article, we extend the linear tensor method to the nonlinear tensor method and propose a nonlinear low-rank tensor unmixing algorithm to solve the generalized bilinear model (GBM). Specifically, the linear and nonlinear parts of the GBM can both be expressed as tensors. Furthermore, the low-rank structures of abundance maps and nonlinear interaction abundance maps are exploited by minimizing their nuclear norm, thus taking full advantage of the high spatial correlation in HSIs. Synthetic and real-data experiments show that the low rank of abundance maps and nonlinear interaction abundance maps exploited in our method can improve the performance of the nonlinear unmixing. A MATLAB demo of this work will be available at https://github.com/LinaZhuang for the sake of reproducibility.
Interpretable Hyperspectral AI: When Non-Convex Modeling meets Hyperspectral Remote Sensing
Mar 02, 2021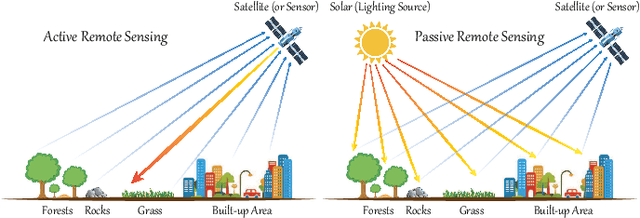


Hyperspectral imaging, also known as image spectrometry, is a landmark technique in geoscience and remote sensing (RS). In the past decade, enormous efforts have been made to process and analyze these hyperspectral (HS) products mainly by means of seasoned experts. However, with the ever-growing volume of data, the bulk of costs in manpower and material resources poses new challenges on reducing the burden of manual labor and improving efficiency. For this reason, it is, therefore, urgent to develop more intelligent and automatic approaches for various HS RS applications. Machine learning (ML) tools with convex optimization have successfully undertaken the tasks of numerous artificial intelligence (AI)-related applications. However, their ability in handling complex practical problems remains limited, particularly for HS data, due to the effects of various spectral variabilities in the process of HS imaging and the complexity and redundancy of higher dimensional HS signals. Compared to the convex models, non-convex modeling, which is capable of characterizing more complex real scenes and providing the model interpretability technically and theoretically, has been proven to be a feasible solution to reduce the gap between challenging HS vision tasks and currently advanced intelligent data processing models.
Joint and Progressive Subspace Analysis (JPSA) with Spatial-Spectral Manifold Alignment for Semi-Supervised Hyperspectral Dimensionality Reduction
Sep 21, 2020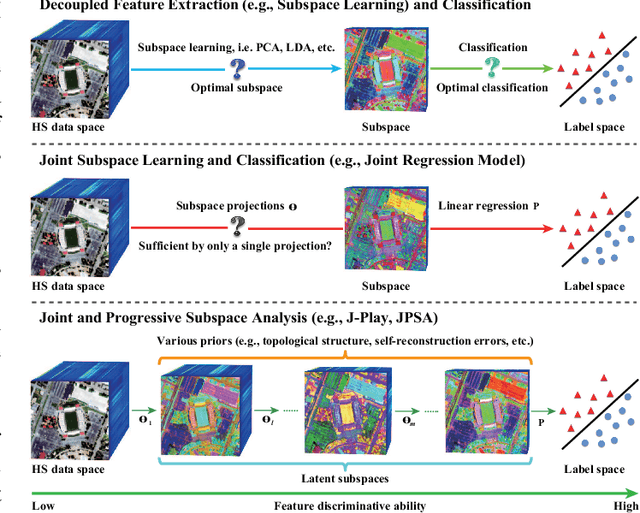
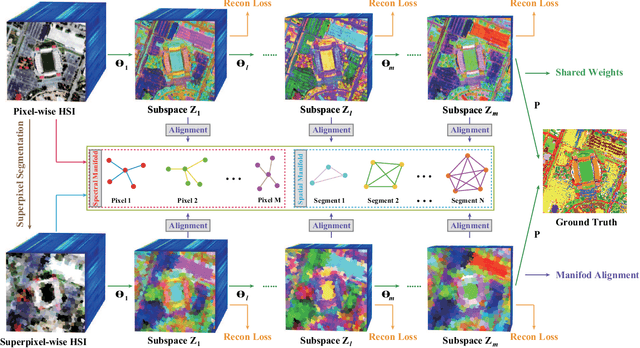

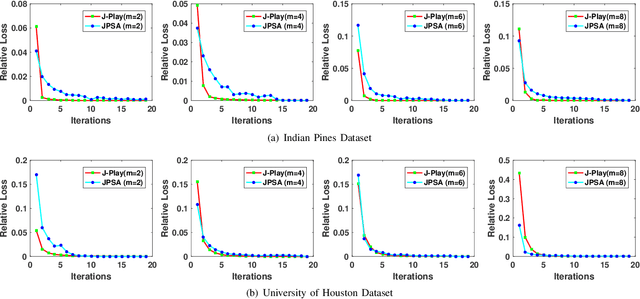
Conventional nonlinear subspace learning techniques (e.g., manifold learning) usually introduce some drawbacks in explainability (explicit mapping) and cost-effectiveness (linearization), generalization capability (out-of-sample), and representability (spatial-spectral discrimination). To overcome these shortcomings, a novel linearized subspace analysis technique with spatial-spectral manifold alignment is developed for a semi-supervised hyperspectral dimensionality reduction (HDR), called joint and progressive subspace analysis (JPSA). The JPSA learns a high-level, semantically meaningful, joint spatial-spectral feature representation from hyperspectral data by 1) jointly learning latent subspaces and a linear classifier to find an effective projection direction favorable for classification; 2) progressively searching several intermediate states of subspaces to approach an optimal mapping from the original space to a potential more discriminative subspace; 3) spatially and spectrally aligning manifold structure in each learned latent subspace in order to preserve the same or similar topological property between the compressed data and the original data. A simple but effective classifier, i.e., nearest neighbor (NN), is explored as a potential application for validating the algorithm performance of different HDR approaches. Extensive experiments are conducted to demonstrate the superiority and effectiveness of the proposed JPSA on two widely-used hyperspectral datasets: Indian Pines (92.98\%) and the University of Houston (86.09\%) in comparison with previous state-of-the-art HDR methods. The demo of this basic work (i.e., ECCV2018) is openly available at https://github.com/danfenghong/ECCV2018_J-Play.
PolSAR Image Classification Based on Robust Low-Rank Feature Extraction and Markov Random Field
Sep 13, 2020
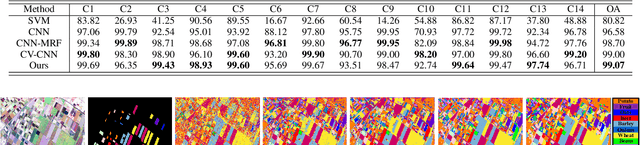
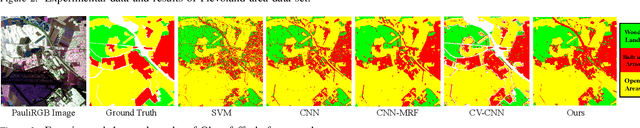
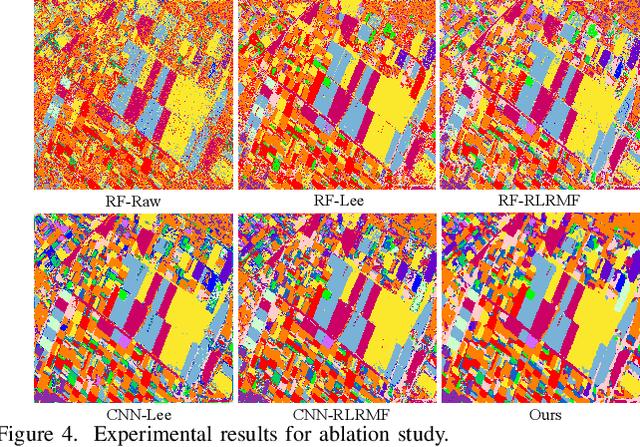
Polarimetric synthetic aperture radar (PolSAR) image classification has been investigated vigorously in various remote sensing applications. However, it is still a challenging task nowadays. One significant barrier lies in the speckle effect embedded in the PolSAR imaging process, which greatly degrades the quality of the images and further complicates the classification. To this end, we present a novel PolSAR image classification method, which removes speckle noise via low-rank (LR) feature extraction and enforces smoothness priors via Markov random field (MRF). Specifically, we employ the mixture of Gaussian-based robust LR matrix factorization to simultaneously extract discriminative features and remove complex noises. Then, a classification map is obtained by applying convolutional neural network with data augmentation on the extracted features, where local consistency is implicitly involved, and the insufficient label issue is alleviated. Finally, we refine the classification map by MRF to enforce contextual smoothness. We conduct experiments on two benchmark PolSAR datasets. Experimental results indicate that the proposed method achieves promising classification performance and preferable spatial consistency.