 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeShadowSync: Performing Synchronization in the Background for Highly Scalable Distributed Training
Mar 07, 2020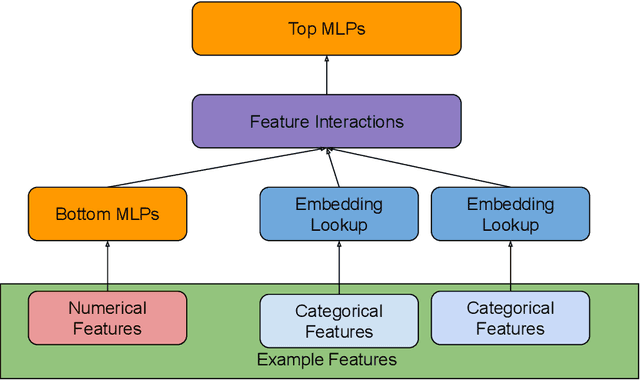
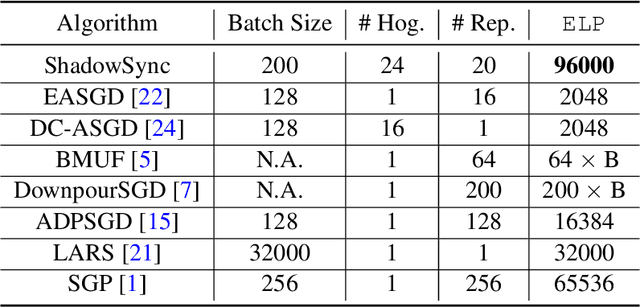
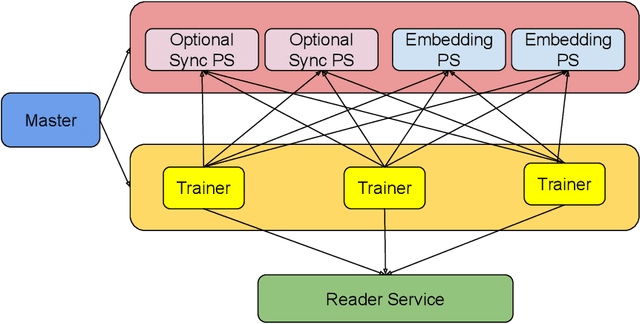
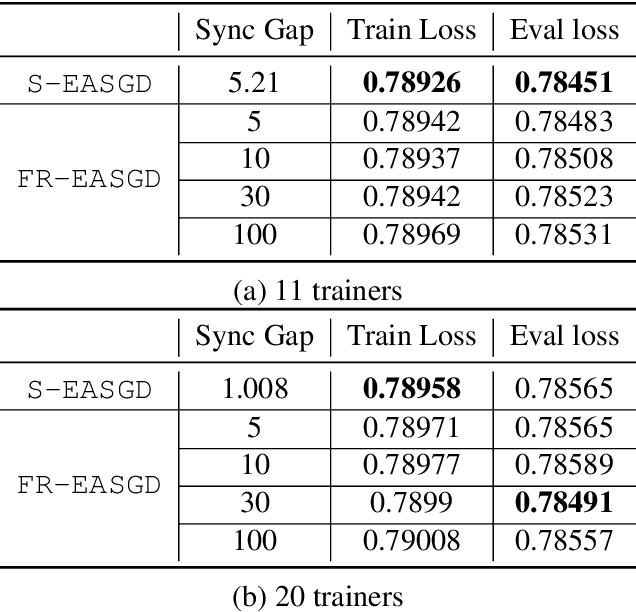
Distributed training is useful to train complicated models to shorten the training time. As each of the workers only sees a small fraction of data, workers need to synchronize on the parameter updates. One of the central questions in distributed training is how to parsimoniously synchronize parameters while preserving model quality. To address this problem, we propose the \textbf{ShadowSync} framework, in which we isolate synchronization from training and run it in the background. In contrast to common strategies including synchronous stochastic gradient descent (SGD), asynchronous SGD, and model averaging on independently trained sub-models, where synchronization happens in the foreground, ShadowSync synchronization is neither part of the backward pass, nor happens every $k$ iterations. Our framework is generic to host various types of synchronization algorithms, and we propose 3 approaches under this theme. The superiority of ShadowSync is confirmed by experiments on training deep neural networks for click-through-rate prediction. Our methods all succeed in making the training throughput linearly scale with the number of trainers. Comparing to their foreground counterparts, our methods exhibit neutral to better model quality and better scalability when we keep the number of parameter servers the same. In our training system which expresses both replication and Hogwild parallelism, ShadowSync also accomplishes the highest example level parallelism number comparing to the prior arts.
Post-Training 4-bit Quantization on Embedding Tables
Nov 05, 2019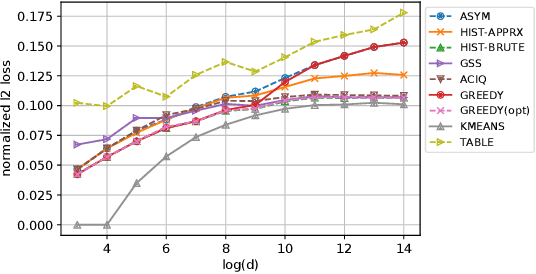

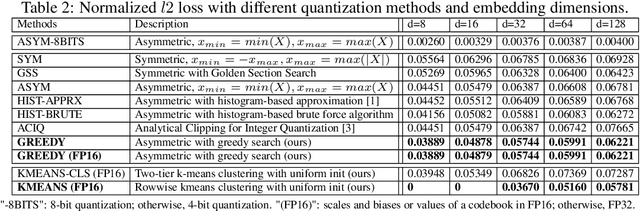
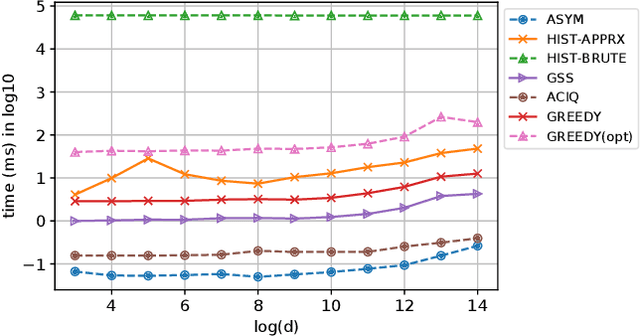
Continuous representations have been widely adopted in recommender systems where a large number of entities are represented using embedding vectors. As the cardinality of the entities increases, the embedding components can easily contain millions of parameters and become the bottleneck in both storage and inference due to large memory consumption. This work focuses on post-training 4-bit quantization on the continuous embeddings. We propose row-wise uniform quantization with greedy search and codebook-based quantization that consistently outperforms state-of-the-art quantization approaches on reducing accuracy degradation. We deploy our uniform quantization technique on a production model in Facebook and demonstrate that it can reduce the model size to only 13.89% of the single-precision version while the model quality stays neutral.
Mixed Dimension Embeddings with Application to Memory-Efficient Recommendation Systems
Sep 25, 2019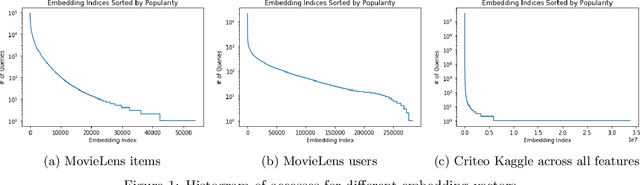
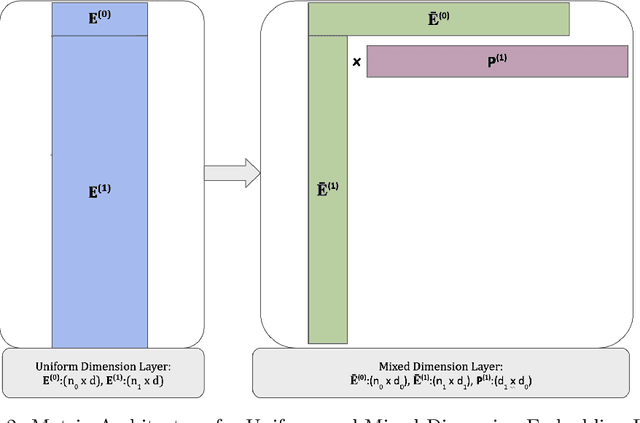
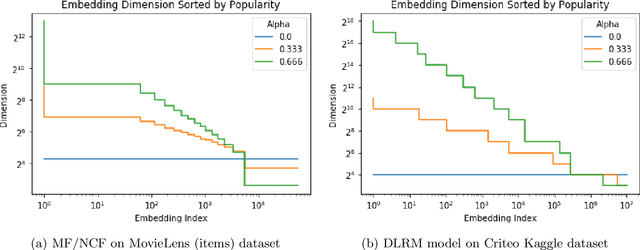
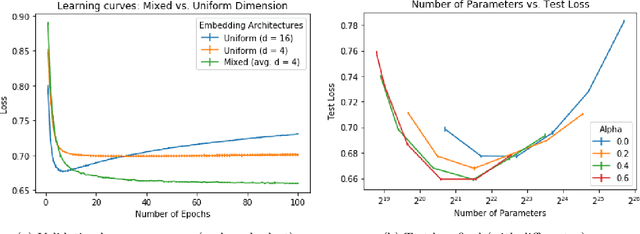
In many real-world applications, e.g. recommendation systems, certain items appear much more frequently than other items. However, standard embedding methods---which form the basis of many ML algorithms---allocate the same dimension to all of the items. This leads to statistical and memory inefficiencies. In this work, we propose mixed dimension embedding layers in which the dimension of a particular embedding vector can depend on the frequency of the item. This approach drastically reduces the memory requirement for the embedding, while maintaining and sometimes improving the ML performance. We show that the proposed mixed dimension layers achieve a higher accuracy, while using 8X fewer parameters, for collaborative filtering on the MovieLens dataset. Also, they improve accuracy by 0.1% using half as many parameters or maintain baseline accuracy using 16X fewer parameters for click-through rate prediction task on the Criteo Kaggle dataset.
Compositional Embeddings Using Complementary Partitions for Memory-Efficient Recommendation Systems
Sep 04, 2019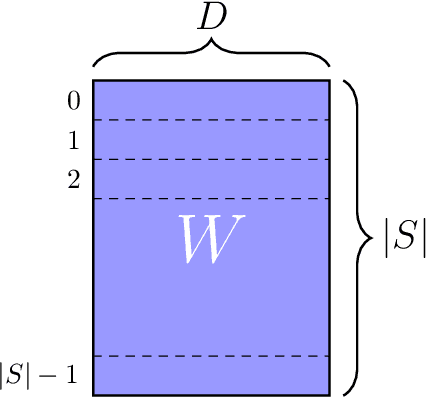
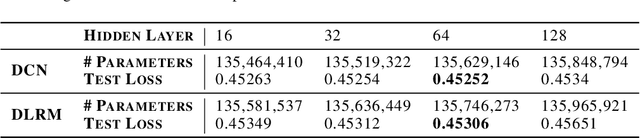
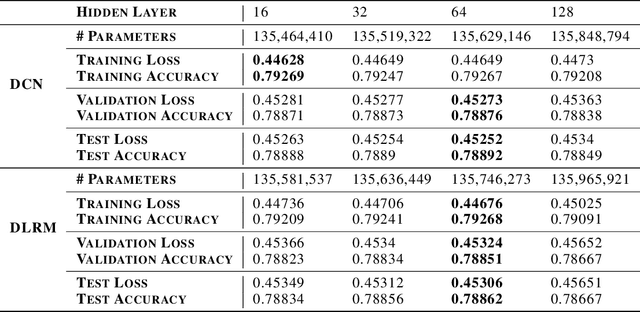
Modern deep learning-based recommendation systems exploit hundreds to thousands of different categorical features, each with millions of different categories ranging from clicks to posts. To respect the natural diversity within the categorical data, embeddings map each category to a unique dense representation within an embedded space. Since each categorical feature could take on as many as tens of millions of different possible categories, the embedding tables form the primary memory bottleneck during both training and inference. We propose a novel approach for reducing the embedding size in an end-to-end fashion by exploiting complementary partitions of the category set to produce a unique embedding vector for each category without explicit definition. By storing multiple smaller embedding tables based on each complementary partition and combining embeddings from each table, we define a unique embedding for each category at smaller cost. This approach may be interpreted as using a specific fixed codebook to ensure uniqueness of each category's representation. Our experimental results demonstrate the effectiveness of our approach over the hashing trick for reducing the size of the embedding tables in terms of model loss and accuracy, while retaining a similar reduction in the number of parameters.
A Study of BFLOAT16 for Deep Learning Training
Jun 13, 2019
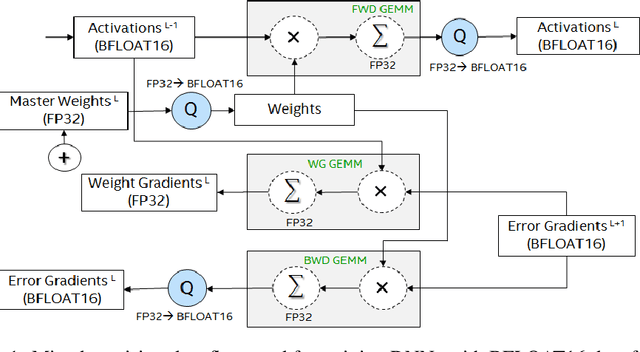
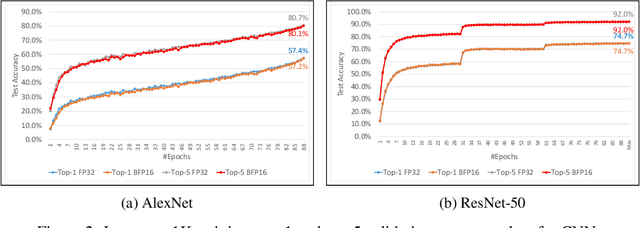

This paper presents the first comprehensive empirical study demonstrating the efficacy of the Brain Floating Point (BFLOAT16) half-precision format for Deep Learning training across image classification, speech recognition, language modeling, generative networks and industrial recommendation systems. BFLOAT16 is attractive for Deep Learning training for two reasons: the range of values it can represent is the same as that of IEEE 754 floating-point format (FP32) and conversion to/from FP32 is simple. Maintaining the same range as FP32 is important to ensure that no hyper-parameter tuning is required for convergence; e.g., IEEE 754 compliant half-precision floating point (FP16) requires hyper-parameter tuning. In this paper, we discuss the flow of tensors and various key operations in mixed precision training, and delve into details of operations, such as the rounding modes for converting FP32 tensors to BFLOAT16. We have implemented a method to emulate BFLOAT16 operations in Tensorflow, Caffe2, IntelCaffe, and Neon for our experiments. Our results show that deep learning training using BFLOAT16 tensors achieves the same state-of-the-art (SOTA) results across domains as FP32 tensors in the same number of iterations and with no changes to hyper-parameters.
Weighted SGD for $\ell_p$ Regression with Randomized Preconditioning
Jul 10, 2017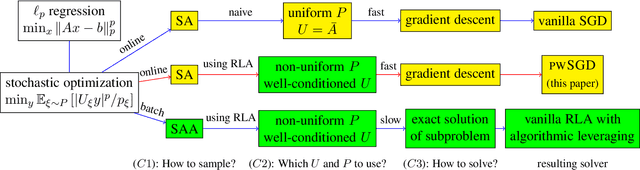

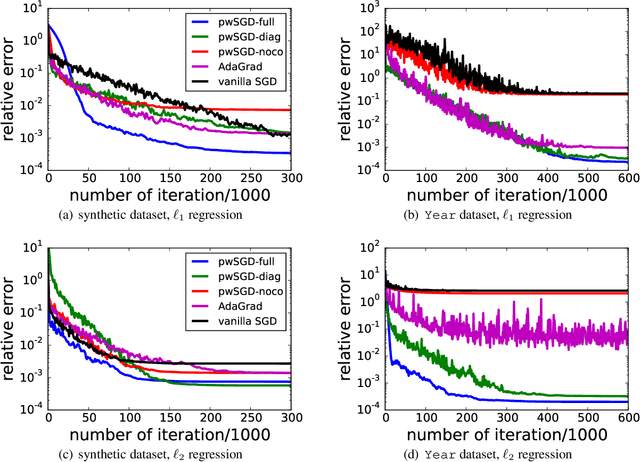
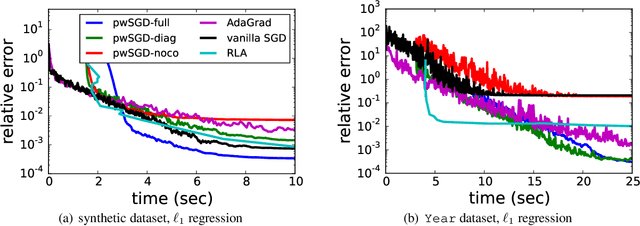
In recent years, stochastic gradient descent (SGD) methods and randomized linear algebra (RLA) algorithms have been applied to many large-scale problems in machine learning and data analysis. We aim to bridge the gap between these two methods in solving constrained overdetermined linear regression problems---e.g., $\ell_2$ and $\ell_1$ regression problems. We propose a hybrid algorithm named pwSGD that uses RLA techniques for preconditioning and constructing an importance sampling distribution, and then performs an SGD-like iterative process with weighted sampling on the preconditioned system. We prove that pwSGD inherits faster convergence rates that only depend on the lower dimension of the linear system, while maintaining low computation complexity. Particularly, when solving $\ell_1$ regression with size $n$ by $d$, pwSGD returns an approximate solution with $\epsilon$ relative error in the objective value in $\mathcal{O}(\log n \cdot \text{nnz}(A) + \text{poly}(d)/\epsilon^2)$ time. This complexity is uniformly better than that of RLA methods in terms of both $\epsilon$ and $d$ when the problem is unconstrained. For $\ell_2$ regression, pwSGD returns an approximate solution with $\epsilon$ relative error in the objective value and the solution vector measured in prediction norm in $\mathcal{O}(\log n \cdot \text{nnz}(A) + \text{poly}(d) \log(1/\epsilon) /\epsilon)$ time. We also provide lower bounds on the coreset complexity for more general regression problems, indicating that still new ideas will be needed to extend similar RLA preconditioning ideas to weighted SGD algorithms for more general regression problems. Finally, the effectiveness of such algorithms is illustrated numerically on both synthetic and real datasets.
Sub-sampled Newton Methods with Non-uniform Sampling
Jul 05, 2016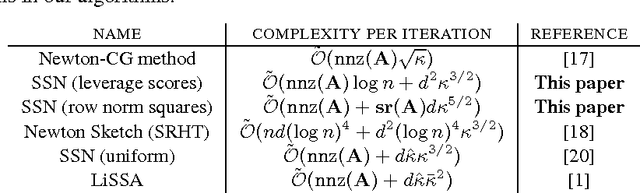
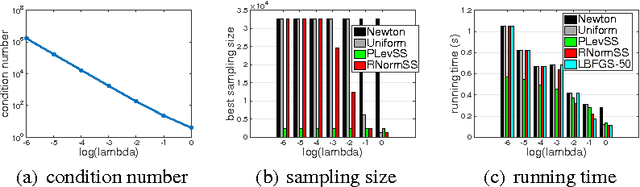
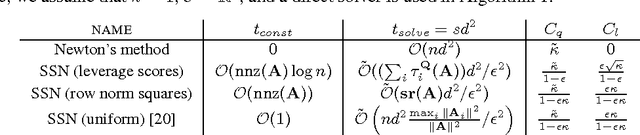
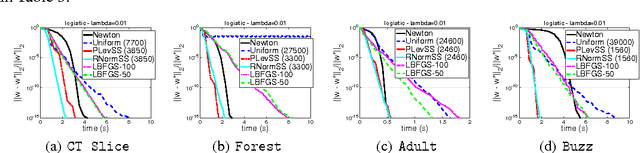
We consider the problem of finding the minimizer of a convex function $F: \mathbb R^d \rightarrow \mathbb R$ of the form $F(w) := \sum_{i=1}^n f_i(w) + R(w)$ where a low-rank factorization of $\nabla^2 f_i(w)$ is readily available. We consider the regime where $n \gg d$. As second-order methods prove to be effective in finding the minimizer to a high-precision, in this work, we propose randomized Newton-type algorithms that exploit \textit{non-uniform} sub-sampling of $\{\nabla^2 f_i(w)\}_{i=1}^{n}$, as well as inexact updates, as means to reduce the computational complexity. Two non-uniform sampling distributions based on {\it block norm squares} and {\it block partial leverage scores} are considered in order to capture important terms among $\{\nabla^2 f_i(w)\}_{i=1}^{n}$. We show that at each iteration non-uniformly sampling at most $\mathcal O(d \log d)$ terms from $\{\nabla^2 f_i(w)\}_{i=1}^{n}$ is sufficient to achieve a linear-quadratic convergence rate in $w$ when a suitable initial point is provided. In addition, we show that our algorithms achieve a lower computational complexity and exhibit more robustness and better dependence on problem specific quantities, such as the condition number, compared to similar existing methods, especially the ones based on uniform sampling. Finally, we empirically demonstrate that our methods are at least twice as fast as Newton's methods with ridge logistic regression on several real datasets.
Quasi-Monte Carlo Feature Maps for Shift-Invariant Kernels
Aug 09, 2015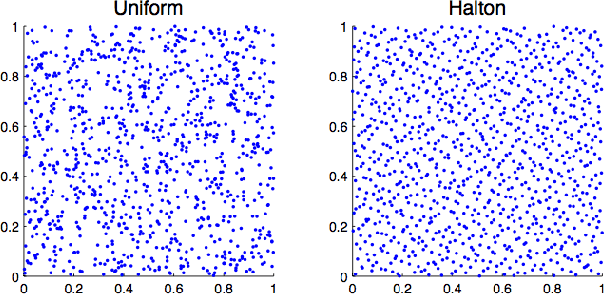
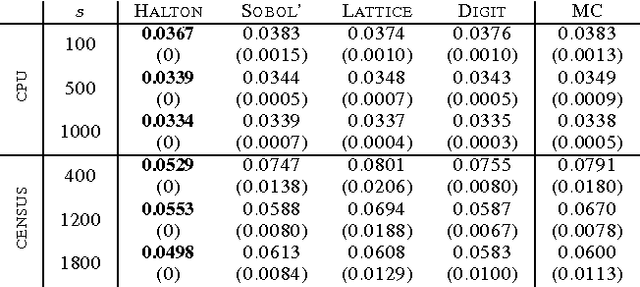
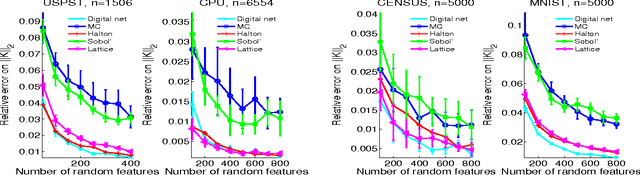
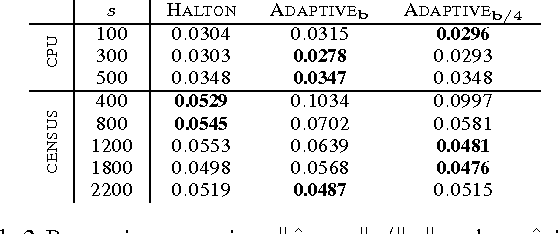
We consider the problem of improving the efficiency of randomized Fourier feature maps to accelerate training and testing speed of kernel methods on large datasets. These approximate feature maps arise as Monte Carlo approximations to integral representations of shift-invariant kernel functions (e.g., Gaussian kernel). In this paper, we propose to use Quasi-Monte Carlo (QMC) approximations instead, where the relevant integrands are evaluated on a low-discrepancy sequence of points as opposed to random point sets as in the Monte Carlo approach. We derive a new discrepancy measure called box discrepancy based on theoretical characterizations of the integration error with respect to a given sequence. We then propose to learn QMC sequences adapted to our setting based on explicit box discrepancy minimization. Our theoretical analyses are complemented with empirical results that demonstrate the effectiveness of classical and adaptive QMC techniques for this problem.
Implementing Randomized Matrix Algorithms in Parallel and Distributed Environments
Jul 27, 2015
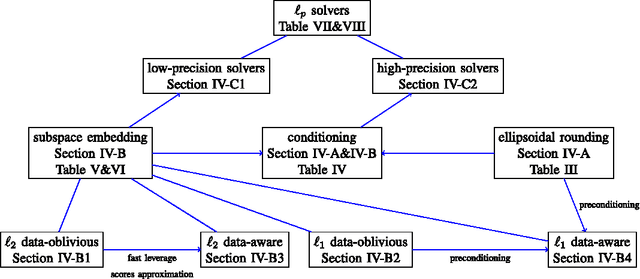


In this era of large-scale data, distributed systems built on top of clusters of commodity hardware provide cheap and reliable storage and scalable processing of massive data. Here, we review recent work on developing and implementing randomized matrix algorithms in large-scale parallel and distributed environments. Randomized algorithms for matrix problems have received a great deal of attention in recent years, thus far typically either in theory or in machine learning applications or with implementations on a single machine. Our main focus is on the underlying theory and practical implementation of random projection and random sampling algorithms for very large very overdetermined (i.e., overconstrained) $\ell_1$ and $\ell_2$ regression problems. Randomization can be used in one of two related ways: either to construct sub-sampled problems that can be solved, exactly or approximately, with traditional numerical methods; or to construct preconditioned versions of the original full problem that are easier to solve with traditional iterative algorithms. Theoretical results demonstrate that in near input-sparsity time and with only a few passes through the data one can obtain very strong relative-error approximate solutions, with high probability. Empirical results highlight the importance of various trade-offs (e.g., between the time to construct an embedding and the conditioning quality of the embedding, between the relative importance of computation versus communication, etc.) and demonstrate that $\ell_1$ and $\ell_2$ regression problems can be solved to low, medium, or high precision in existing distributed systems on up to terabyte-sized data.
Tensor machines for learning target-specific polynomial features
Apr 07, 2015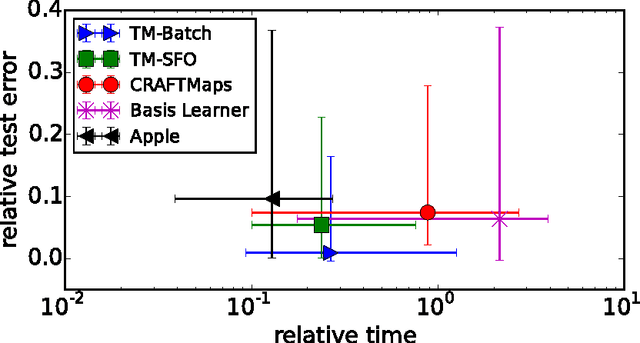
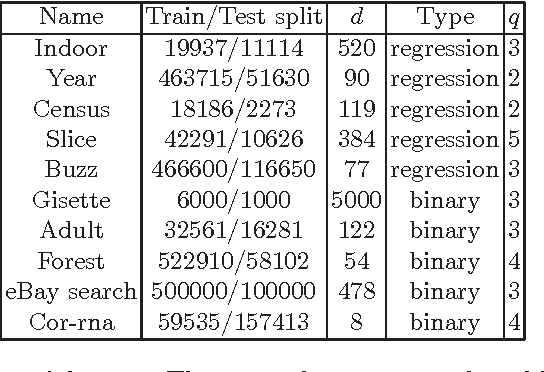
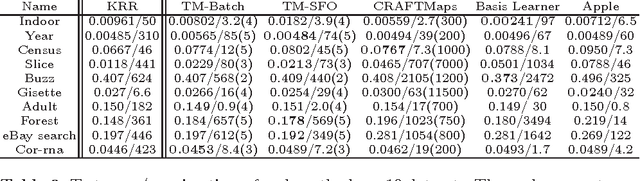
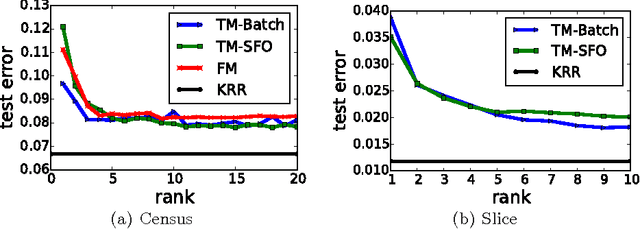
Recent years have demonstrated that using random feature maps can significantly decrease the training and testing times of kernel-based algorithms without significantly lowering their accuracy. Regrettably, because random features are target-agnostic, typically thousands of such features are necessary to achieve acceptable accuracies. In this work, we consider the problem of learning a small number of explicit polynomial features. Our approach, named Tensor Machines, finds a parsimonious set of features by optimizing over the hypothesis class introduced by Kar and Karnick for random feature maps in a target-specific manner. Exploiting a natural connection between polynomials and tensors, we provide bounds on the generalization error of Tensor Machines. Empirically, Tensor Machines behave favorably on several real-world datasets compared to other state-of-the-art techniques for learning polynomial features, and deliver significantly more parsimonious models.