 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Learning-Assisted Jamming Mitigation with Movable Antenna Array
Oct 27, 2024



This paper reveals the potential of movable antennas in enhancing anti-jamming communication. We consider a legitimate communication link in the presence of multiple jammers and propose deploying a movable antenna array at the receiver to combat jamming attacks. We formulate the problem as a signal-to-interference-plus-noise ratio maximization, by jointly optimizing the receive beamforming and antenna element positioning. Due to the non-convexity and multi-fold difficulties from an optimization perspective, we develop a deep learning-based framework where beamforming is tackled as a Rayleigh quotient problem, while antenna positioning is addressed through multi-layer perceptron training. The neural network parameters are optimized using stochastic gradient descent to achieve effective jamming mitigation strategy, featuring offline training with marginal complexity for online inference. Numerical results demonstrate that the proposed approach achieves near-optimal anti-jamming performance thereby significantly improving the efficiency in strategy determination.
Towards Evaluating and Building Versatile Large Language Models for Medicine
Aug 22, 2024In this study, we present MedS-Bench, a comprehensive benchmark designed to evaluate the performance of large language models (LLMs) in clinical contexts. Unlike existing benchmarks that focus on multiple-choice question answering, MedS-Bench spans 11 high-level clinical tasks, including clinical report summarization, treatment recommendations, diagnosis, named entity recognition, and medical concept explanation, among others. We evaluated six leading LLMs, e.g., MEDITRON, Mistral, InternLM 2, Llama 3, GPT-4, and Claude-3.5 using few-shot prompting, and found that even the most sophisticated models struggle with these complex tasks. To address these limitations, we developed MedS-Ins, a large-scale instruction tuning dataset for medicine. MedS-Ins comprises 58 medically oriented language corpora, totaling 13.5 million samples across 122 tasks. To demonstrate the dataset's utility, we conducted a proof-of-concept experiment by performing instruction tuning on a lightweight, open-source medical language model. The resulting model, MMedIns-Llama 3, significantly outperformed existing models across nearly all clinical tasks. To promote further advancements in the application of LLMs to clinical challenges, we have made the MedS-Ins dataset fully accessible and invite the research community to contribute to its expansion.Additionally, we have launched a dynamic leaderboard for MedS-Bench, which we plan to regularly update the test set to track progress and enhance the adaptation of general LLMs to the medical domain. Leaderboard: https://henrychur.github.io/MedS-Bench/. Github: https://github.com/MAGIC-AI4Med/MedS-Ins.
Tracing Privacy Leakage of Language Models to Training Data via Adjusted Influence Functions
Aug 21, 2024The responses generated by Large Language Models (LLMs) can include sensitive information from individuals and organizations, leading to potential privacy leakage. This work implements Influence Functions (IFs) to trace privacy leakage back to the training data, thereby mitigating privacy concerns of Language Models (LMs). However, we notice that current IFs struggle to accurately estimate the influence of tokens with large gradient norms, potentially overestimating their influence. When tracing the most influential samples, this leads to frequently tracing back to samples with large gradient norm tokens, overshadowing the actual most influential samples even if their influences are well estimated. To address this issue, we propose Heuristically Adjusted IF (HAIF), which reduces the weight of tokens with large gradient norms, thereby significantly improving the accuracy of tracing the most influential samples. To establish easily obtained groundtruth for tracing privacy leakage, we construct two datasets, PII-E and PII-CR, representing two distinct scenarios: one with identical text in the model outputs and pre-training data, and the other where models leverage their reasoning abilities to generate text divergent from pre-training data. HAIF significantly improves tracing accuracy, enhancing it by 20.96\% to 73.71\% on the PII-E dataset and 3.21\% to 45.93\% on the PII-CR dataset, compared to the best SOTA IFs against various GPT-2 and QWen-1.5 models. HAIF also outperforms SOTA IFs on real-world pretraining data CLUECorpus2020, demonstrating strong robustness regardless prompt and response lengths.
DIDI: Diffusion-Guided Diversity for Offline Behavioral Generation
May 23, 2024In this paper, we propose a novel approach called DIffusion-guided DIversity (DIDI) for offline behavioral generation. The goal of DIDI is to learn a diverse set of skills from a mixture of label-free offline data. We achieve this by leveraging diffusion probabilistic models as priors to guide the learning process and regularize the policy. By optimizing a joint objective that incorporates diversity and diffusion-guided regularization, we encourage the emergence of diverse behaviors while maintaining the similarity to the offline data. Experimental results in four decision-making domains (Push, Kitchen, Humanoid, and D4RL tasks) show that DIDI is effective in discovering diverse and discriminative skills. We also introduce skill stitching and skill interpolation, which highlight the generalist nature of the learned skill space. Further, by incorporating an extrinsic reward function, DIDI enables reward-guided behavior generation, facilitating the learning of diverse and optimal behaviors from sub-optimal data.
Scalable and Effective Arithmetic Tree Generation for Adder and Multiplier Designs
May 10, 2024
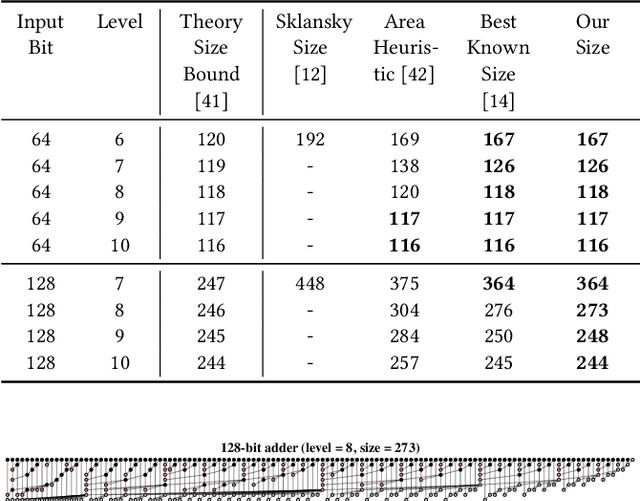


Across a wide range of hardware scenarios, the computational efficiency and physical size of the arithmetic units significantly influence the speed and footprint of the overall hardware system. Nevertheless, the effectiveness of prior arithmetic design techniques proves inadequate, as it does not sufficiently optimize speed and area, resulting in a reduced processing rate and larger module size. To boost the arithmetic performance, in this work, we focus on the two most common and fundamental arithmetic modules: adders and multipliers. We cast the design tasks as single-player tree generation games, leveraging reinforcement learning techniques to optimize their arithmetic tree structures. Such a tree generation formulation allows us to efficiently navigate the vast search space and discover superior arithmetic designs that improve computational efficiency and hardware size within just a few hours. For adders, our approach discovers designs of 128-bit adders that achieve Pareto optimality in theoretical metrics. Compared with the state-of-the-art PrefixRL, our method decreases computational delay and hardware size by up to 26% and 30%, respectively. For multipliers, when compared to RL-MUL, our approach increases speed and reduces size by as much as 49% and 45%. Moreover, the inherent flexibility and scalability of our method enable us to deploy our designs into cutting-edge technologies, as we show that they can be seamlessly integrated into 7nm technology. We believe our work will offer valuable insights into hardware design, further accelerating speed and reducing size through the refined search space and our tree generation methodologies. See our introduction video at https://bit.ly/ArithmeticTree. Codes are released at https://github.com/laiyao1/ArithmeticTree.
Quantum Computing-Enhanced Algorithm Unveils Novel Inhibitors for KRAS
Feb 13, 2024



The discovery of small molecules with therapeutic potential is a long-standing challenge in chemistry and biology. Researchers have increasingly leveraged novel computational techniques to streamline the drug development process to increase hit rates and reduce the costs associated with bringing a drug to market. To this end, we introduce a quantum-classical generative model that seamlessly integrates the computational power of quantum algorithms trained on a 16-qubit IBM quantum computer with the established reliability of classical methods for designing small molecules. Our hybrid generative model was applied to designing new KRAS inhibitors, a crucial target in cancer therapy. We synthesized 15 promising molecules during our investigation and subjected them to experimental testing to assess their ability to engage with the target. Notably, among these candidates, two molecules, ISM061-018-2 and ISM061-22, each featuring unique scaffolds, stood out by demonstrating effective engagement with KRAS. ISM061-018-2 was identified as a broad-spectrum KRAS inhibitor, exhibiting a binding affinity to KRAS-G12D at $1.4 \mu M$. Concurrently, ISM061-22 exhibited specific mutant selectivity, displaying heightened activity against KRAS G12R and Q61H mutants. To our knowledge, this work shows for the first time the use of a quantum-generative model to yield experimentally confirmed biological hits, showcasing the practical potential of quantum-assisted drug discovery to produce viable therapeutics. Moreover, our findings reveal that the efficacy of distribution learning correlates with the number of qubits utilized, underlining the scalability potential of quantum computing resources. Overall, we anticipate our results to be a stepping stone towards developing more advanced quantum generative models in drug discovery.
Context-Former: Stitching via Latent Conditioned Sequence Modeling
Feb 03, 2024



Offline reinforcement learning (RL) algorithms can improve the decision making via stitching sub-optimal trajectories to obtain more optimal ones. This capability is a crucial factor in enabling RL to learn policies that are superior to the behavioral policy. On the other hand, Decision Transformer (DT) abstracts the decision-making as sequence modeling, showcasing competitive performance on offline RL benchmarks, however, recent studies demonstrate that DT lacks of stitching capability, thus exploit stitching capability for DT is vital to further improve its performance. In order to endow stitching capability to DT, we abstract trajectory stitching as expert matching and introduce our approach, ContextFormer, which integrates contextual information-based imitation learning (IL) and sequence modeling to stitch sub-optimal trajectory fragments by emulating the representations of a limited number of expert trajectories. To validate our claim, we conduct experiments from two perspectives: 1) We conduct extensive experiments on D4RL benchmarks under the settings of IL, and experimental results demonstrate ContextFormer can achieve competitive performance in multi-IL settings. 2) More importantly, we conduct a comparison of ContextFormer with diverse competitive DT variants using identical training datasets. The experimental results unveiled ContextFormer's superiority, as it outperformed all other variants, showcasing its remarkable performance.
Deep Dict: Deep Learning-based Lossy Time Series Compressor for IoT Data
Jan 18, 2024



We propose Deep Dict, a deep learning-based lossy time series compressor designed to achieve a high compression ratio while maintaining decompression error within a predefined range. Deep Dict incorporates two essential components: the Bernoulli transformer autoencoder (BTAE) and a distortion constraint. BTAE extracts Bernoulli representations from time series data, reducing the size of the representations compared to conventional autoencoders. The distortion constraint limits the prediction error of BTAE to the desired range. Moreover, in order to address the limitations of common regression losses such as L1/L2, we introduce a novel loss function called quantized entropy loss (QEL). QEL takes into account the specific characteristics of the problem, enhancing robustness to outliers and alleviating optimization challenges. Our evaluation of Deep Dict across ten diverse time series datasets from various domains reveals that Deep Dict outperforms state-of-the-art lossy compressors in terms of compression ratio by a significant margin by up to 53.66%.
Probing Structured Semantics Understanding and Generation of Language Models via Question Answering
Jan 11, 2024Recent advancement in the capabilities of large language models (LLMs) has triggered a new surge in LLMs' evaluation. Most recent evaluation works tends to evaluate the comprehensive ability of LLMs over series of tasks. However, the deep structure understanding of natural language is rarely explored. In this work, we examine the ability of LLMs to deal with structured semantics on the tasks of question answering with the help of the human-constructed formal language. Specifically, we implement the inter-conversion of natural and formal language through in-context learning of LLMs to verify their ability to understand and generate the structured logical forms. Extensive experiments with models of different sizes and in different formal languages show that today's state-of-the-art LLMs' understanding of the logical forms can approach human level overall, but there still are plenty of room in generating correct logical forms, which suggest that it is more effective to use LLMs to generate more natural language training data to reinforce a small model than directly answering questions with LLMs. Moreover, our results also indicate that models exhibit considerable sensitivity to different formal languages. In general, the formal language with the lower the formalization level, i.e. the more similar it is to natural language, is more LLMs-friendly.
Adaptive Proximal Policy Optimization with Upper Confidence Bound
Dec 12, 2023



Trust Region Policy Optimization (TRPO) attractively optimizes the policy while constraining the update of the new policy within a trust region, ensuring the stability and monotonic optimization. Building on the theoretical guarantees of trust region optimization, Proximal Policy Optimization (PPO) successfully enhances the algorithm's sample efficiency and reduces deployment complexity by confining the update of the new and old policies within a surrogate trust region. However, this approach is limited by the fixed setting of surrogate trust region and is not sufficiently adaptive, because there is no theoretical proof that the optimal clipping bound remains consistent throughout the entire training process, truncating the ratio of the new and old policies within surrogate trust region can ensure that the algorithm achieves its best performance, therefore, exploring and researching a dynamic clip bound for improving PPO's performance can be quite beneficial. To design an adaptive clipped trust region and explore the dynamic clip bound's impact on the performance of PPO, we introduce an adaptive PPO-CLIP (Adaptive-PPO) method that dynamically explores and exploits the clip bound using a bandit during the online training process. Furthermore, ample experiments will initially demonstrate that our Adaptive-PPO exhibits sample efficiency and performance compared to PPO-CLIP.