 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInverting Data Transformations via Diffusion Sampling
Feb 09, 2026We study the problem of transformation inversion on general Lie groups: a datum is transformed by an unknown group element, and the goal is to recover an inverse transformation that maps it back to the original data distribution. Such unknown transformations arise widely in machine learning and scientific modeling, where they can significantly distort observations. We take a probabilistic view and model the posterior over transformations as a Boltzmann distribution defined by an energy function on data space. To sample from this posterior, we introduce a diffusion process on Lie groups that keeps all updates on-manifold and only requires computations in the associated Lie algebra. Our method, Transformation-Inverting Energy Diffusion (TIED), relies on a new trivialized target-score identity that enables efficient score-based sampling of the transformation posterior. As a key application, we focus on test-time equivariance, where the objective is to improve the robustness of pretrained neural networks to input transformations. Experiments on image homographies and PDE symmetries demonstrate that TIED can restore transformed inputs to the training distribution at test time, showing improved performance over strong canonicalization and sampling baselines. Code is available at https://github.com/jw9730/tied.
FiLoRA: Focus-and-Ignore LoRA for Controllable Feature Reliance
Feb 02, 2026Multimodal foundation models integrate heterogeneous signals across modalities, yet it remains poorly understood how their predictions depend on specific internal feature groups and whether such reliance can be deliberately controlled. Existing studies of shortcut and spurious behavior largely rely on post hoc analyses or feature removal, offering limited insight into whether reliance can be modulated without altering task semantics. We introduce FiLoRA (Focus-and-Ignore LoRA), an instruction-conditioned, parameter-efficient adaptation framework that enables explicit control over internal feature reliance while keeping the predictive objective fixed. FiLoRA decomposes adaptation into feature group-aligned LoRA modules and applies instruction-conditioned gating, allowing natural language instructions to act as computation-level control signals rather than task redefinitions. Across text--image and audio--visual benchmarks, we show that instruction-conditioned gating induces consistent and causal shifts in internal computation, selectively amplifying or suppressing core and spurious feature groups without modifying the label space or training objective. Further analyses demonstrate that FiLoRA yields improved robustness under spurious feature interventions, revealing a principled mechanism to regulate reliance beyond correlation-driven learning.
Near-Real-Time InSAR Phase Estimation for Large-Scale Surface Displacement Monitoring
Nov 15, 2025



Operational near-real-time monitoring of Earth's surface deformation using Interferometric Synthetic Aperture Radar (InSAR) requires processing algorithms that efficiently incorporate new acquisitions without reprocessing historical archives. We present sequential phase linking approach using compressed single-look-complex images (SLCs) capable of producing surface displacement estimates within hours of the time of a new acquisition. Our key algorithmic contribution is a mini-stack reference scheme that maintains phase consistency across processing batches without adjusting or re-estimating previous time steps, enabling straightforward operational deployment. We introduce online methods for persistent and distributed scatterer identification that adapt to temporal changes in surface properties through incremental amplitude statistics updates. The processing chain incorporates multiple complementary metrics for pixel quality that are reliable for small SLC stack sizes, and an L1-norm network inversion to limit propagation of unwrapping errors across the time series. We use our algorithm to produce OPERA Surface Displacement from Sentinel-1 product, the first continental-scale surface displacement product over North America. Validation against GPS measurements and InSAR residual analysis demonstrates millimeter-level agreement in velocity estimates in varying environmental conditions. We demonstrate our algorithm's capabilities with a successful recovery of meter-scale co-eruptive displacement at Kilauea volcano during the 2018 eruption, as well as detection of subtle uplift at Three Sisters volcano, Oregon- a challenging environment for C-band InSAR due to dense vegetation and seasonal snow. We have made all software available as open source libraries, providing a significant advancement to the open scientific community's ability to process large InSAR data sets in a cloud environment.
Flock: A Knowledge Graph Foundation Model via Learning on Random Walks
Oct 01, 2025We study the problem of zero-shot link prediction on knowledge graphs (KGs), which requires models to generalize over novel entities and novel relations. Knowledge graph foundation models (KGFMs) address this task by enforcing equivariance over both nodes and relations, learning from structural properties of nodes and relations, which are then transferable to novel graphs with similar structural properties. However, the conventional notion of deterministic equivariance imposes inherent limits on the expressive power of KGFMs, preventing them from distinguishing structurally similar but semantically distinct relations. To overcome this limitation, we introduce probabilistic node-relation equivariance, which preserves equivariance in distribution while incorporating a principled randomization to break symmetries during inference. Building on this principle, we present Flock, a KGFM that iteratively samples random walks, encodes them into sequences via a recording protocol, embeds them with a sequence model, and aggregates representations of nodes and relations via learned pooling. Crucially, Flock respects probabilistic node-relation equivariance and is a universal approximator for isomorphism-invariant link-level functions over KGs. Empirically, Flock perfectly solves our new diagnostic dataset Petals where current KGFMs fail, and achieves state-of-the-art performances on entity- and relation prediction tasks on 54 KGs from diverse domains.
ORIDa: Object-centric Real-world Image Composition Dataset
Jun 10, 2025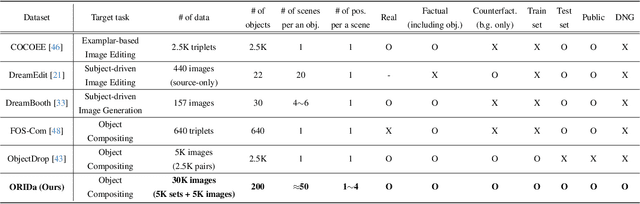



Object compositing, the task of placing and harmonizing objects in images of diverse visual scenes, has become an important task in computer vision with the rise of generative models. However, existing datasets lack the diversity and scale required to comprehensively explore real-world scenarios. We introduce ORIDa (Object-centric Real-world Image Composition Dataset), a large-scale, real-captured dataset containing over 30,000 images featuring 200 unique objects, each of which is presented across varied positions and scenes. ORIDa has two types of data: factual-counterfactual sets and factual-only scenes. The factual-counterfactual sets consist of four factual images showing an object in different positions within a scene and a single counterfactual (or background) image of the scene without the object, resulting in five images per scene. The factual-only scenes include a single image containing an object in a specific context, expanding the variety of environments. To our knowledge, ORIDa is the first publicly available dataset with its scale and complexity for real-world image composition. Extensive analysis and experiments highlight the value of ORIDa as a resource for advancing further research in object compositing.
Cost-Efficient LLM Serving in the Cloud: VM Selection with KV Cache Offloading
Apr 16, 2025LLM inference is essential for applications like text summarization, translation, and data analysis, but the high cost of GPU instances from Cloud Service Providers (CSPs) like AWS is a major burden. This paper proposes InferSave, a cost-efficient VM selection framework for cloud based LLM inference. InferSave optimizes KV cache offloading based on Service Level Objectives (SLOs) and workload charac teristics, estimating GPU memory needs, and recommending cost-effective VM instances. Additionally, the Compute Time Calibration Function (CTCF) improves instance selection accuracy by adjusting for discrepancies between theoretical and actual GPU performance. Experiments on AWS GPU instances show that selecting lower-cost instances without KV cache offloading improves cost efficiency by up to 73.7% for online workloads, while KV cache offloading saves up to 20.19% for offline workloads.
Shared Disk KV Cache Management for Efficient Multi-Instance Inference in RAG-Powered LLMs
Apr 16, 2025



Recent large language models (LLMs) face increasing inference latency as input context length and model size continue to grow. In particular, the retrieval-augmented generation (RAG) technique, which enhances LLM responses by incorporating external knowledge, exacerbates this issue by significantly increasing the number of input tokens. This expansion in token length leads to a substantial rise in computational overhead, particularly during the prefill stage, resulting in prolonged time-to-first-token (TTFT). To address this issue, this paper proposes a method to reduce TTFT by leveraging a disk-based key-value (KV) cache to lessen the computational burden during the prefill stage. We also introduce a disk-based shared KV cache management system, called Shared RAG-DCache, for multi-instance LLM RAG service environments. This system, together with an optimal system configuration, improves both throughput and latency under given resource constraints. Shared RAG-DCache exploits the locality of documents related to user queries in RAG, as well as the queueing delay in LLM inference services. It proactively generates and stores disk KV caches for query-related documents and shares them across multiple LLM instances to enhance inference performance. In experiments on a single host equipped with 2 GPUs and 1 CPU, Shared RAG-DCache achieved a 15~71% increase in throughput and up to a 12~65% reduction in latency, depending on the resource configuration.
EO-VLM: VLM-Guided Energy Overload Attacks on Vision Models
Apr 11, 2025



Vision models are increasingly deployed in critical applications such as autonomous driving and CCTV monitoring, yet they remain susceptible to resource-consuming attacks. In this paper, we introduce a novel energy-overloading attack that leverages vision language model (VLM) prompts to generate adversarial images targeting vision models. These images, though imperceptible to the human eye, significantly increase GPU energy consumption across various vision models, threatening the availability of these systems. Our framework, EO-VLM (Energy Overload via VLM), is model-agnostic, meaning it is not limited by the architecture or type of the target vision model. By exploiting the lack of safety filters in VLMs like DALL-E 3, we create adversarial noise images without requiring prior knowledge or internal structure of the target vision models. Our experiments demonstrate up to a 50% increase in energy consumption, revealing a critical vulnerability in current vision models.
Simulation-Free Training of Neural ODEs on Paired Data
Oct 30, 2024In this work, we investigate a method for simulation-free training of Neural Ordinary Differential Equations (NODEs) for learning deterministic mappings between paired data. Despite the analogy of NODEs as continuous-depth residual networks, their application in typical supervised learning tasks has not been popular, mainly due to the large number of function evaluations required by ODE solvers and numerical instability in gradient estimation. To alleviate this problem, we employ the flow matching framework for simulation-free training of NODEs, which directly regresses the parameterized dynamics function to a predefined target velocity field. Contrary to generative tasks, however, we show that applying flow matching directly between paired data can often lead to an ill-defined flow that breaks the coupling of the data pairs (e.g., due to crossing trajectories). We propose a simple extension that applies flow matching in the embedding space of data pairs, where the embeddings are learned jointly with the dynamic function to ensure the validity of the flow which is also easier to learn. We demonstrate the effectiveness of our method on both regression and classification tasks, where our method outperforms existing NODEs with a significantly lower number of function evaluations. The code is available at https://github.com/seminkim/simulation-free-node.
MPruner: Optimizing Neural Network Size with CKA-Based Mutual Information Pruning
Aug 24, 2024



Determining the optimal size of a neural network is critical, as it directly impacts runtime performance and memory usage. Pruning is a well-established model compression technique that reduces the size of neural networks while mathematically guaranteeing accuracy preservation. However, many recent pruning methods overlook the global contributions of individual model components, making it difficult to ensure that a pruned model meets the desired dataset and performance requirements. To address these challenges, we developed a new pruning algorithm, MPruner, that leverages mutual information through vector similarity. MPruner utilizes layer clustering with the Centered Kernel Alignment (CKA) similarity metric, allowing us to incorporate global information from the neural network for more precise and efficient layer-wise pruning. We evaluated MPruner across various architectures and configurations, demonstrating its versatility and providing practical guidelines. MPruner achieved up to a 50% reduction in parameters and memory usage for CNN and transformer-based models, with minimal to no loss in accuracy.