 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePosterior Refinement: Fast Language Generation via Any-Order Flow Maps
Jun 23, 2026Non-autoregressive generation offers a powerful paradigm for iterative refinement, allowing models to recursively critique, erase and regenerate arbitrary subsets of tokens. However, existing non-autoregressive models fail to realize this potential. Masked Diffusion Models (MDMs) suffer from factorization error, causing sample quality to collapse when generating multiple tokens simultaneously. Flow Map Language Models (FMLMs) circumvent this bottleneck via joint sequence transport for excellent few-step generation, but sacrifice the inference-time flexibility of MDMs. We introduce FMLM+, a framework that bridges this gap by equipping FMLM with masking-style noise schedules. While generating the full sequence in a single step, FMLM+ simultaneously scores the global consistency of each token a posteriori. We leverage this to introduce Posterior Refinement, a novel inference-time refinement strategy that enables the model to adaptively self-correct its outputs, matching the performance of discrete baselines with 32x fewer NFEs. Across diverse benchmarks, we demonstrate that FMLM+ with Posterior Refinement improves the speed--quality tradeoff over both MDM and FMLM families, providing a scalable foundation for high-fidelity language modeling.
Infinite Mask Diffusion for Few-Step Distillation
May 11, 2026Masked Diffusion Models (MDMs) have emerged as a promising alternative to autoregressive models in language modeling, offering the advantages of parallel decoding and bidirectional context processing within a simple yet effective framework. Specifically, their explicit distinction between masked tokens and data underlies their simple framework and effective conditional generation. However, MDMs typically require many sampling iterations due to factorization errors stemming from simultaneous token updates. We observe that a theoretical lower bound of the factorization error exists, which standard MDMs cannot reduce due to their use of a deterministic single-state mask. In this paper, we propose the Infinite Mask Diffusion Model (IMDM), which introduces a stochastic infinite-state mask to mitigate the theoretical bound while directly inheriting the benefits of MDMs, including the compatibility with pre-trained weights. We empirically demonstrate that MDM fails to perform few-step generation even in a simple synthetic task due to the factorization error bound, whereas IMDM can find an efficient solution for the same task. Finally, when equipped with appropriate distillation methods, IMDM surpasses existing few-step distillation methods at small step counts on LM1B and OpenWebText. Code is available at https://Ugness.github.io/official_imdm.
Training-Free Refinement of Flow Matching with Divergence-based Sampling
Apr 06, 2026Flow-based models learn a target distribution by modeling a marginal velocity field, defined as the average of sample-wise velocities connecting each sample from a simple prior to the target data. When sample-wise velocities conflict at the same intermediate state, however, this averaged velocity can misguide samples toward low-density regions, degrading generation quality. To address this issue, we propose the Flow Divergence Sampler (FDS), a training-free framework that refines intermediate states before each solver step. Our key finding reveals that the severity of this misguidance is quantified by the divergence of the marginal velocity field that is readily computable during inference with a well-optimized model. FDS exploits this signal to steer states toward less ambiguous regions. As a plug-and-play framework compatible with standard solvers and off-the-shelf flow backbones, FDS consistently improves fidelity across various generation tasks including text-to-image synthesis, and inverse problems.
One-step Language Modeling via Continuous Denoising
Feb 18, 2026Language models based on discrete diffusion have attracted widespread interest for their potential to provide faster generation than autoregressive models. In practice, however, they exhibit a sharp degradation of sample quality in the few-step regime, failing to realize this promise. Here we show that language models leveraging flow-based continuous denoising can outperform discrete diffusion in both quality and speed. By revisiting the fundamentals of flows over discrete modalities, we build a flow-based language model (FLM) that performs Euclidean denoising over one-hot token encodings. We show that the model can be trained by predicting the clean data via a cross entropy objective, where we introduce a simple time reparameterization that greatly improves training stability and generation quality. By distilling FLM into its associated flow map, we obtain a distilled flow map language model (FMLM) capable of few-step generation. On the LM1B and OWT language datasets, FLM attains generation quality matching state-of-the-art discrete diffusion models. With FMLM, our approach outperforms recent few-step language models across the board, with one-step generation exceeding their 8-step quality. Our work calls into question the widely held hypothesis that discrete diffusion processes are necessary for generative modeling over discrete modalities, and paves the way toward accelerated flow-based language modeling at scale. Code is available at https://github.com/david3684/flm.
Simulation-Free Training of Neural ODEs on Paired Data
Oct 30, 2024In this work, we investigate a method for simulation-free training of Neural Ordinary Differential Equations (NODEs) for learning deterministic mappings between paired data. Despite the analogy of NODEs as continuous-depth residual networks, their application in typical supervised learning tasks has not been popular, mainly due to the large number of function evaluations required by ODE solvers and numerical instability in gradient estimation. To alleviate this problem, we employ the flow matching framework for simulation-free training of NODEs, which directly regresses the parameterized dynamics function to a predefined target velocity field. Contrary to generative tasks, however, we show that applying flow matching directly between paired data can often lead to an ill-defined flow that breaks the coupling of the data pairs (e.g., due to crossing trajectories). We propose a simple extension that applies flow matching in the embedding space of data pairs, where the embeddings are learned jointly with the dynamic function to ensure the validity of the flow which is also easier to learn. We demonstrate the effectiveness of our method on both regression and classification tasks, where our method outperforms existing NODEs with a significantly lower number of function evaluations. The code is available at https://github.com/seminkim/simulation-free-node.
Learning to Compose: Improving Object Centric Learning by Injecting Compositionality
May 01, 2024



Learning compositional representation is a key aspect of object-centric learning as it enables flexible systematic generalization and supports complex visual reasoning. However, most of the existing approaches rely on auto-encoding objective, while the compositionality is implicitly imposed by the architectural or algorithmic bias in the encoder. This misalignment between auto-encoding objective and learning compositionality often results in failure of capturing meaningful object representations. In this study, we propose a novel objective that explicitly encourages compositionality of the representations. Built upon the existing object-centric learning framework (e.g., slot attention), our method incorporates additional constraints that an arbitrary mixture of object representations from two images should be valid by maximizing the likelihood of the composite data. We demonstrate that incorporating our objective to the existing framework consistently improves the objective-centric learning and enhances the robustness to the architectural choices.
Towards End-to-End Generative Modeling of Long Videos with Memory-Efficient Bidirectional Transformers
Mar 27, 2023Autoregressive transformers have shown remarkable success in video generation. However, the transformers are prohibited from directly learning the long-term dependency in videos due to the quadratic complexity of self-attention, and inherently suffering from slow inference time and error propagation due to the autoregressive process. In this paper, we propose Memory-efficient Bidirectional Transformer (MeBT) for end-to-end learning of long-term dependency in videos and fast inference. Based on recent advances in bidirectional transformers, our method learns to decode the entire spatio-temporal volume of a video in parallel from partially observed patches. The proposed transformer achieves a linear time complexity in both encoding and decoding, by projecting observable context tokens into a fixed number of latent tokens and conditioning them to decode the masked tokens through the cross-attention. Empowered by linear complexity and bidirectional modeling, our method demonstrates significant improvement over the autoregressive Transformers for generating moderately long videos in both quality and speed. Videos and code are available at https://sites.google.com/view/mebt-cvpr2023 .
SetVAE: Learning Hierarchical Composition for Generative Modeling of Set-Structured Data
Mar 29, 2021
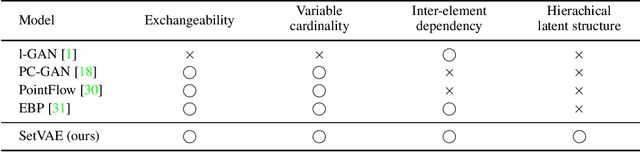
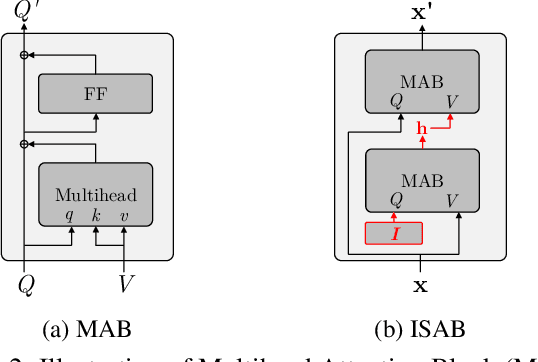
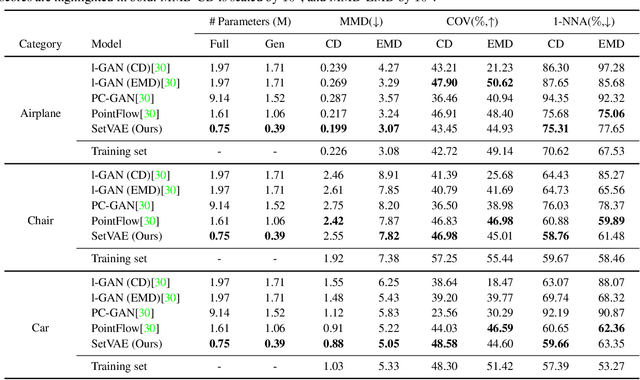
Generative modeling of set-structured data, such as point clouds, requires reasoning over local and global structures at various scales. However, adopting multi-scale frameworks for ordinary sequential data to a set-structured data is nontrivial as it should be invariant to the permutation of its elements. In this paper, we propose SetVAE, a hierarchical variational autoencoder for sets. Motivated by recent progress in set encoding, we build SetVAE upon attentive modules that first partition the set and project the partition back to the original cardinality. Exploiting this module, our hierarchical VAE learns latent variables at multiple scales, capturing coarse-to-fine dependency of the set elements while achieving permutation invariance. We evaluate our model on point cloud generation task and achieve competitive performance to the prior arts with substantially smaller model capacity. We qualitatively demonstrate that our model generalizes to unseen set sizes and learns interesting subset relations without supervision. Our implementation is available at https://github.com/jw9730/setvae.