 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRawGen: Learning Camera Raw Image Generation
Mar 31, 2026Cameras capture scene-referred linear raw images, which are processed by onboard image signal processors (ISPs) into display-referred 8-bit sRGB outputs. Although raw data is more faithful for low-level vision tasks, collecting large-scale raw datasets remains a major bottleneck, as existing datasets are limited and tied to specific camera hardware. Generative models offer a promising way to address this scarcity -- however, existing diffusion frameworks are designed to synthesize photo-finished sRGB images rather than physically consistent linear representations. This paper presents RawGen, to our knowledge the first diffusion-based framework enabling text-to-raw generation for arbitrary target cameras, alongside sRGB-to-raw inversion. RawGen leverages the generative priors of large-scale sRGB diffusion models to synthesize physically meaningful linear outputs, such as CIE XYZ or camera-specific raw representations, via specialized processing in latent and pixel spaces. To handle unknown and diverse ISP pipelines and photo-finishing effects in diffusion-model training data, we build a many-to-one inverse-ISP dataset where multiple sRGB renditions of the same scene generated using diverse ISP parameters are anchored to a common scene-referred target. Fine-tuning a conditional denoiser and specialized decoder on this dataset allows RawGen to obtain camera-centric linear reconstructions that effectively invert the rendering pipeline. We demonstrate RawGen's superior performance over traditional inverse-ISP methods that assume a fixed ISP. Furthermore, we show that augmenting training pipelines with RawGen's scalable, text-driven synthetic data can benefit downstream low-level vision tasks.
ORIDa: Object-centric Real-world Image Composition Dataset
Jun 10, 2025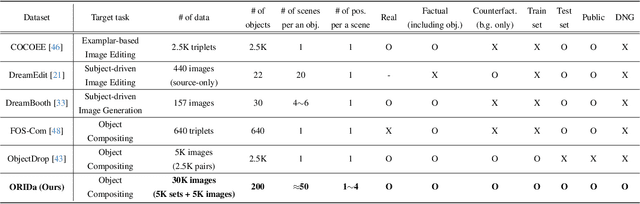



Object compositing, the task of placing and harmonizing objects in images of diverse visual scenes, has become an important task in computer vision with the rise of generative models. However, existing datasets lack the diversity and scale required to comprehensively explore real-world scenarios. We introduce ORIDa (Object-centric Real-world Image Composition Dataset), a large-scale, real-captured dataset containing over 30,000 images featuring 200 unique objects, each of which is presented across varied positions and scenes. ORIDa has two types of data: factual-counterfactual sets and factual-only scenes. The factual-counterfactual sets consist of four factual images showing an object in different positions within a scene and a single counterfactual (or background) image of the scene without the object, resulting in five images per scene. The factual-only scenes include a single image containing an object in a specific context, expanding the variety of environments. To our knowledge, ORIDa is the first publicly available dataset with its scale and complexity for real-world image composition. Extensive analysis and experiments highlight the value of ORIDa as a resource for advancing further research in object compositing.