 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTransformation of Dense and Sparse Text Representations
Nov 07, 2019
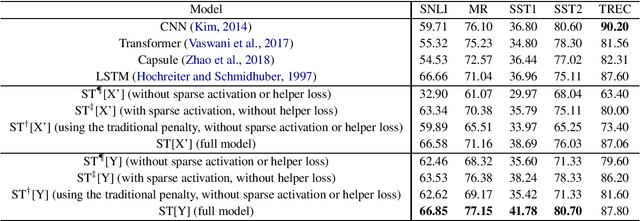
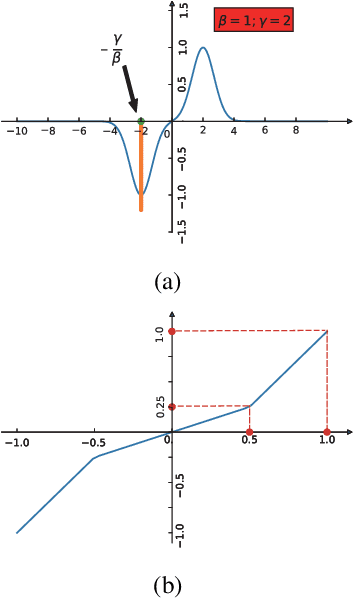
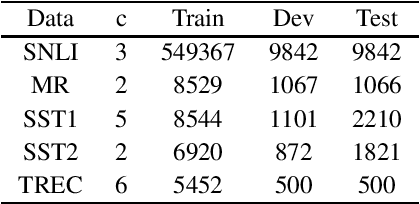
Sparsity is regarded as a desirable property of representations, especially in terms of explanation. However, its usage has been limited due to the gap with dense representations. Most NLP research progresses in recent years are based on dense representations. Thus the desirable property of sparsity cannot be leveraged. Inspired by Fourier Transformation, in this paper, we propose a novel Semantic Transformation method to bridge the dense and sparse spaces, which can facilitate the NLP research to shift from dense space to sparse space or to jointly use both spaces. The key idea of the proposed approach is to use a Forward Transformation to transform dense representations to sparse representations. Then some useful operations in the sparse space can be performed over the sparse representations, and the sparse representations can be used directly to perform downstream tasks such as text classification and natural language inference. Then, a Backward Transformation can also be carried out to transform those processed sparse representations to dense representations. Experiments using classification tasks and natural language inference task show that the proposed Semantic Transformation is effective.
Fast Universal Style Transfer for Artistic and Photorealistic Rendering
Jul 06, 2019
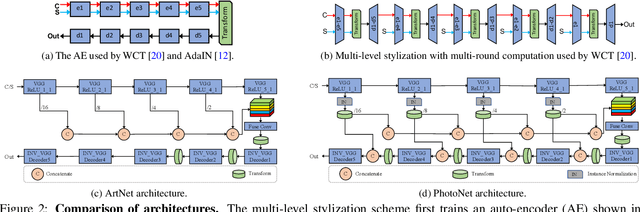
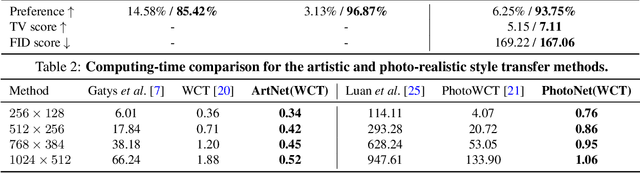

Universal style transfer is an image editing task that renders an input content image using the visual style of arbitrary reference images, including both artistic and photorealistic stylization. Given a pair of images as the source of content and the reference of style, existing solutions usually first train an auto-encoder (AE) to reconstruct the image using deep features and then embeds pre-defined style transfer modules into the AE reconstruction procedure to transfer the style of the reconstructed image through modifying the deep features. While existing methods typically need multiple rounds of time-consuming AE reconstruction for better stylization, our work intends to design novel neural network architectures on top of AE for fast style transfer with fewer artifacts and distortions all in one pass of end-to-end inference. To this end, we propose two network architectures named ArtNet and PhotoNet to improve artistic and photo-realistic stylization, respectively. Extensive experiments demonstrate that ArtNet generates images with fewer artifacts and distortions against the state-of-the-art artistic transfer algorithms, while PhotoNet improves the photorealistic stylization results by creating sharp images faithfully preserving rich details of the input content. Moreover, ArtNet and PhotoNet can achieve 3X to 100X speed-up over the state-of-the-art algorithms, which is a major advantage for large content images.
StyleNAS: An Empirical Study of Neural Architecture Search to Uncover Surprisingly Fast End-to-End Universal Style Transfer Networks
Jun 06, 2019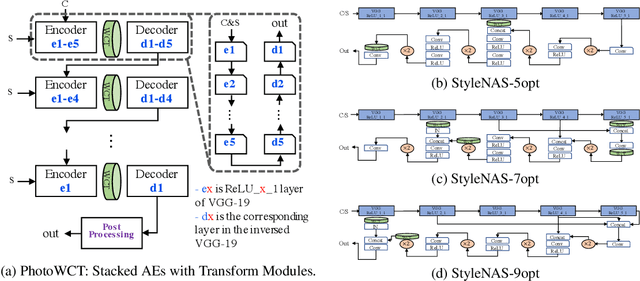

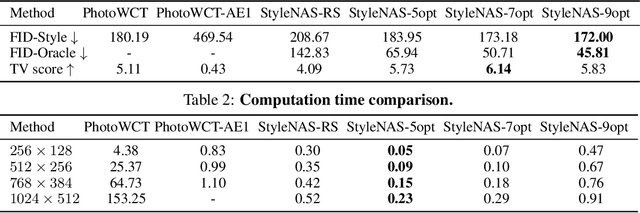
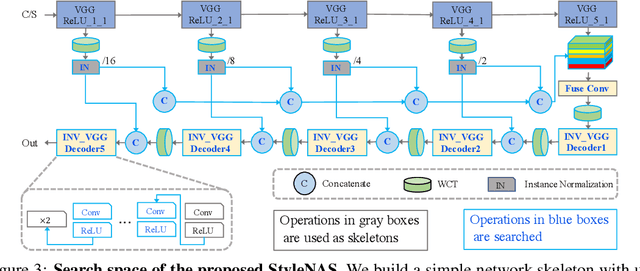
Neural Architecture Search (NAS) has been widely studied for designing discriminative deep learning models such as image classification, object detection, and semantic segmentation. As a large number of priors have been obtained through the manual design of architectures in the fields, NAS is usually considered as a supplement approach. In this paper, we have significantly expanded the application areas of NAS by performing an empirical study of NAS to search generative models, or specifically, auto-encoder based universal style transfer, which lacks systematic exploration, if any, from the architecture search aspect. In our work, we first designed a search space where common operators for image style transfer such as VGG-based encoders, whitening and coloring transforms (WCT), convolution kernels, instance normalization operators, and skip connections were searched in a combinatorial approach. With a simple yet effective parallel evolutionary NAS algorithm with multiple objectives, we derived the first group of end-to-end deep networks for universal photorealistic style transfer. Comparing to random search, a NAS method that is gaining popularity recently, we demonstrated that carefully designed search strategy leads to much better architecture design. Finally compared to existing universal style transfer networks for photorealistic rendering such as PhotoWCT that stacks multiple well-trained auto-encoders and WCT transforms in a non-end-to-end manner, the architectures designed by StyleNAS produce better style-transferred images with details preserving, using a tiny number of operators/parameters, and enjoying around 500x inference time speed-up.
GSN: A Graph-Structured Network for Multi-Party Dialogues
May 31, 2019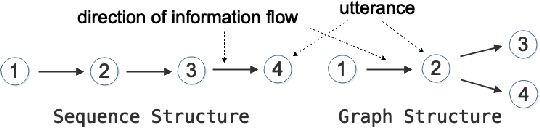

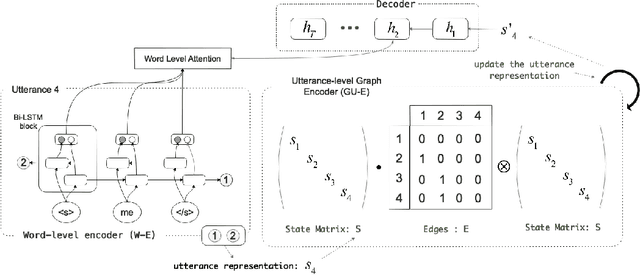
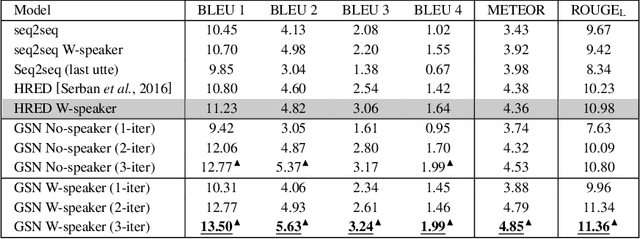
Existing neural models for dialogue response generation assume that utterances are sequentially organized. However, many real-world dialogues involve multiple interlocutors (i.e., multi-party dialogues), where the assumption does not hold as utterances from different interlocutors can occur "in parallel." This paper generalizes existing sequence-based models to a Graph-Structured neural Network (GSN) for dialogue modeling. The core of GSN is a graph-based encoder that can model the information flow along the graph-structured dialogues (two-party sequential dialogues are a special case). Experimental results show that GSN significantly outperforms existing sequence-based models.
Non-convex Penalty for Tensor Completion and Robust PCA
Apr 23, 2019
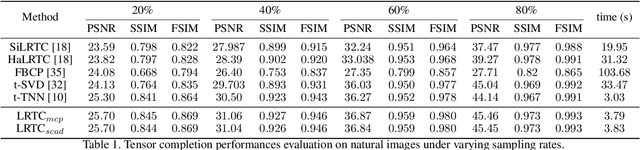
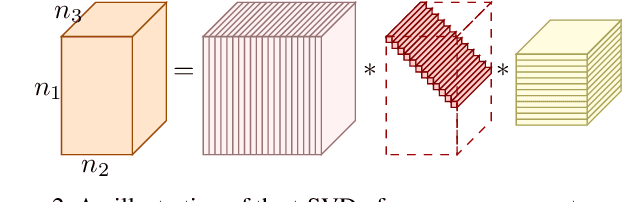
In this paper, we propose a novel non-convex tensor rank surrogate function and a novel non-convex sparsity measure for tensor. The basic idea is to sidestep the bias of $\ell_1-$norm by introducing concavity. Furthermore, we employ the proposed non-convex penalties in tensor recovery problems such as tensor completion and tensor robust principal component analysis, which has various real applications such as image inpainting and denoising. Due to the concavity, the models are difficult to solve. To tackle this problem, we devise majorization minimization algorithms, which optimize upper bounds of original functions in each iteration, and every sub-problem is solved by alternating direction multiplier method. Finally, experimental results on natural images and hyperspectral images demonstrate the effectiveness and efficiency of the proposed methods.
Spatial-Aware Non-Local Attention for Fashion Landmark Detection
Mar 11, 2019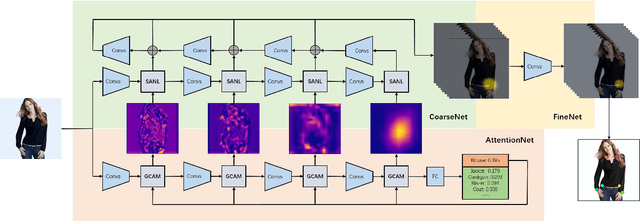
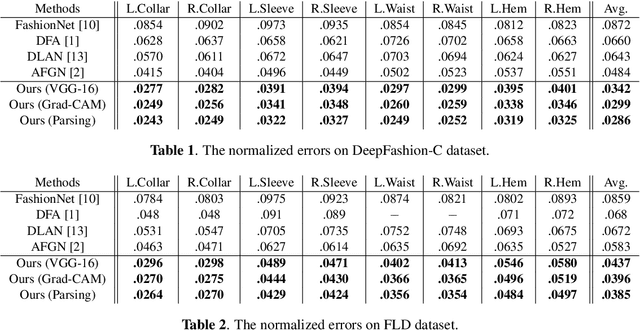
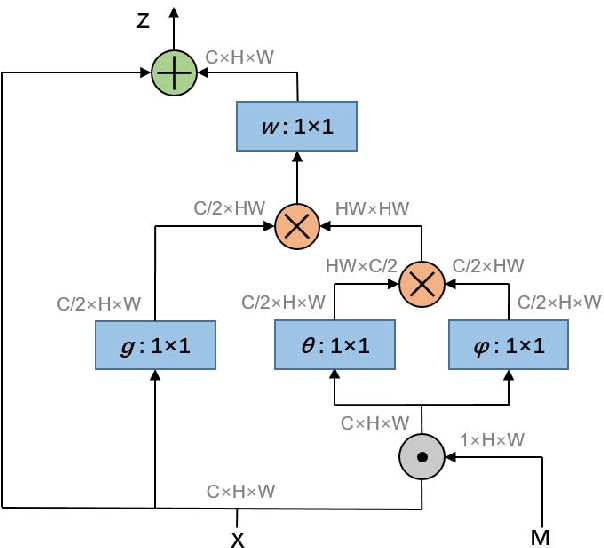

Fashion landmark detection is a challenging task even using the current deep learning techniques, due to the large variation and non-rigid deformation of clothes. In order to tackle these problems, we propose Spatial-Aware Non-Local (SANL) block, an attentive module in deep neural network which can utilize spatial information while capturing global dependency. Actually, the SANL block is constructed from the non-local block in the residual manner which can learn the spatial related representation by taking a spatial attention map from Grad-CAM. We then establish our fashion landmark detection framework on feature pyramid network, equipped with four SANL blocks in the backbone. It is demonstrated by the experimental results on two large-scale fashion datasets that our proposed fashion landmark detection approach with the SANL blocks outperforms the current state-of-the-art methods considerably. Some supplementary experiments on fine-grained image classification also show the effectiveness of the proposed SANL block.
ELEGANT: Exchanging Latent Encodings with GAN for Transferring Multiple Face Attributes
Jul 25, 2018
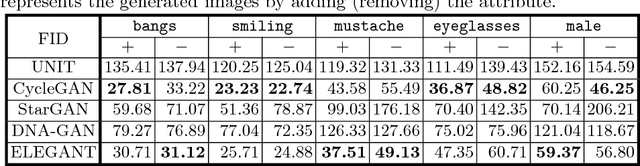


Recent studies on face attribute transfer have achieved great success. A lot of models are able to transfer face attributes with an input image. However, they suffer from three limitations: (1) incapability of generating image by exemplars; (2) being unable to transfer multiple face attributes simultaneously; (3) low quality of generated images, such as low-resolution or artifacts. To address these limitations, we propose a novel model which receives two images of opposite attributes as inputs. Our model can transfer exactly the same type of attributes from one image to another by exchanging certain part of their encodings. All the attributes are encoded in a disentangled manner in the latent space, which enables us to manipulate several attributes simultaneously. Besides, our model learns the residual images so as to facilitate training on higher resolution images. With the help of multi-scale discriminators for adversarial training, it can even generate high-quality images with finer details and less artifacts. We demonstrate the effectiveness of our model on overcoming the above three limitations by comparing with other methods on the CelebA face database. A pytorch implementation is available at https://github.com/Prinsphield/ELEGANT.
* Github: https://github.com/Prinsphield/ELEGANT
The Anisotropic Noise in Stochastic Gradient Descent: Its Behavior of Escaping from Minima and Regularization Effects
May 21, 2018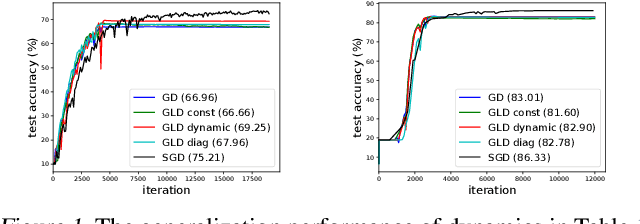

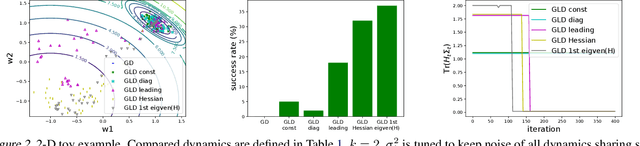
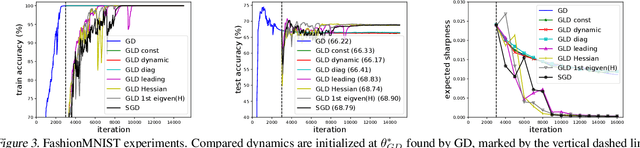
Understanding the behavior of stochastic gradient descent (SGD) in the context of deep neural networks has raised lots of concerns recently. Along this line, we theoretically study a general form of gradient based optimization dynamics with unbiased noise, which unifies SGD and standard Langevin dynamics. Through investigating this general optimization dynamics, we analyze the behavior of SGD on escaping from minima and its regularization effects. A novel indicator is derived to characterize the efficiency of escaping from minima through measuring the alignment of noise covariance and the curvature of loss function. Based on this indicator, two conditions are established to show which type of noise structure is superior to isotropic noise in term of escaping efficiency. We further show that the anisotropic noise in SGD satisfies the two conditions, and thus helps to escape from sharp and poor minima effectively, towards more stable and flat minima that typically generalize well. We verify our understanding through comparing this anisotropic diffusion with full gradient descent plus isotropic diffusion (i.e. Langevin dynamics) and other types of position-dependent noise.
DNA-GAN: Learning Disentangled Representations from Multi-Attribute Images
Mar 28, 2018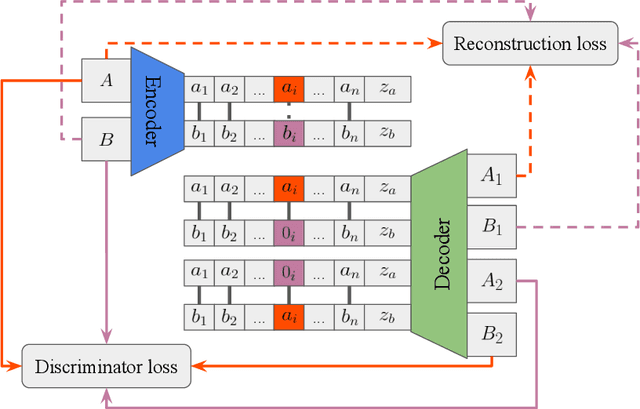



Disentangling factors of variation has become a very challenging problem on representation learning. Existing algorithms suffer from many limitations, such as unpredictable disentangling factors, poor quality of generated images from encodings, lack of identity information, etc. In this paper, we propose a supervised learning model called DNA-GAN which tries to disentangle different factors or attributes of images. The latent representations of images are DNA-like, in which each individual piece (of the encoding) represents an independent factor of the variation. By annihilating the recessive piece and swapping a certain piece of one latent representation with that of the other one, we obtain two different representations which could be decoded into two kinds of images with the existence of the corresponding attribute being changed. In order to obtain realistic images and also disentangled representations, we further introduce the discriminator for adversarial training. Experiments on Multi-PIE and CelebA datasets finally demonstrate that our proposed method is effective for factors disentangling and even overcome certain limitations of the existing methods.