 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerating Aligned Pseudo-Supervision from Non-Aligned Data for Image Restoration in Under-Display Camera
Apr 12, 2023Due to the difficulty in collecting large-scale and perfectly aligned paired training data for Under-Display Camera (UDC) image restoration, previous methods resort to monitor-based image systems or simulation-based methods, sacrificing the realness of the data and introducing domain gaps. In this work, we revisit the classic stereo setup for training data collection -- capturing two images of the same scene with one UDC and one standard camera. The key idea is to "copy" details from a high-quality reference image and "paste" them on the UDC image. While being able to generate real training pairs, this setting is susceptible to spatial misalignment due to perspective and depth of field changes. The problem is further compounded by the large domain discrepancy between the UDC and normal images, which is unique to UDC restoration. In this paper, we mitigate the non-trivial domain discrepancy and spatial misalignment through a novel Transformer-based framework that generates well-aligned yet high-quality target data for the corresponding UDC input. This is made possible through two carefully designed components, namely, the Domain Alignment Module (DAM) and Geometric Alignment Module (GAM), which encourage robust and accurate discovery of correspondence between the UDC and normal views. Extensive experiments show that high-quality and well-aligned pseudo UDC training pairs are beneficial for training a robust restoration network. Code and the dataset are available at https://github.com/jnjaby/AlignFormer.
Real-time Controllable Denoising for Image and Video
Mar 29, 2023Controllable image denoising aims to generate clean samples with human perceptual priors and balance sharpness and smoothness. In traditional filter-based denoising methods, this can be easily achieved by adjusting the filtering strength. However, for NN (Neural Network)-based models, adjusting the final denoising strength requires performing network inference each time, making it almost impossible for real-time user interaction. In this paper, we introduce Real-time Controllable Denoising (RCD), the first deep image and video denoising pipeline that provides a fully controllable user interface to edit arbitrary denoising levels in real-time with only one-time network inference. Unlike existing controllable denoising methods that require multiple denoisers and training stages, RCD replaces the last output layer (which usually outputs a single noise map) of an existing CNN-based model with a lightweight module that outputs multiple noise maps. We propose a novel Noise Decorrelation process to enforce the orthogonality of the noise feature maps, allowing arbitrary noise level control through noise map interpolation. This process is network-free and does not require network inference. Our experiments show that RCD can enable real-time editable image and video denoising for various existing heavy-weight models without sacrificing their original performance.
Random Weights Networks Work as Loss Prior Constraint for Image Restoration
Mar 29, 2023



In this paper, orthogonal to the existing data and model studies, we instead resort our efforts to investigate the potential of loss function in a new perspective and present our belief ``Random Weights Networks can Be Acted as Loss Prior Constraint for Image Restoration''. Inspired by Functional theory, we provide several alternative solutions to implement our belief in the strict mathematical manifolds including Taylor's Unfolding Network, Invertible Neural Network, Central Difference Convolution and Zero-order Filtering as ``random weights network prototype'' with respect of the following four levels: 1) the different random weights strategies; 2) the different network architectures, \emph{eg,} pure convolution layer or transformer; 3) the different network architecture depths; 4) the different numbers of random weights network combination. Furthermore, to enlarge the capability of the randomly initialized manifolds, we devise the manner of random weights in the following two variants: 1) the weights are randomly initialized only once during the whole training procedure; 2) the weights are randomly initialized at each training iteration epoch. Our propose belief can be directly inserted into existing networks without any training and testing computational cost. Extensive experiments across multiple image restoration tasks, including image de-noising, low-light image enhancement, guided image super-resolution demonstrate the consistent performance gains obtained by introducing our belief. To emphasize, our main focus is to spark the realms of loss function and save their current neglected status. Code will be publicly available.
Neighbourhood Representative Sampling for Efficient End-to-end Video Quality Assessment
Oct 11, 2022
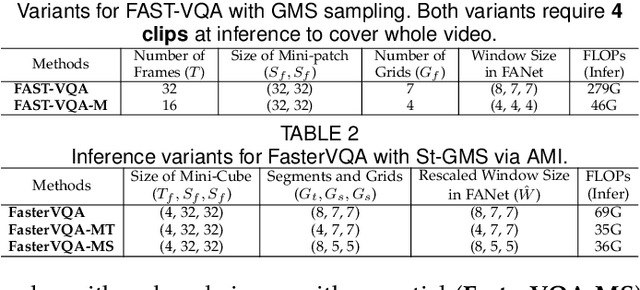
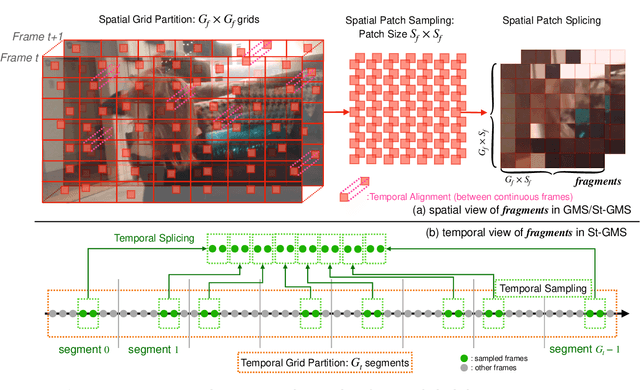
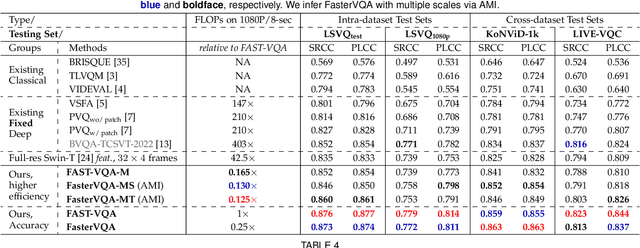
The increased resolution of real-world videos presents a dilemma between efficiency and accuracy for deep Video Quality Assessment (VQA). On the one hand, keeping the original resolution will lead to unacceptable computational costs. On the other hand, existing practices, such as resizing and cropping, will change the quality of original videos due to the loss of details and contents, and are therefore harmful to quality assessment. With the obtained insight from the study of spatial-temporal redundancy in the human visual system and visual coding theory, we observe that quality information around a neighbourhood is typically similar, motivating us to investigate an effective quality-sensitive neighbourhood representatives scheme for VQA. In this work, we propose a unified scheme, spatial-temporal grid mini-cube sampling (St-GMS) to get a novel type of sample, named fragments. Full-resolution videos are first divided into mini-cubes with preset spatial-temporal grids, then the temporal-aligned quality representatives are sampled to compose the fragments that serve as inputs for VQA. In addition, we design the Fragment Attention Network (FANet), a network architecture tailored specifically for fragments. With fragments and FANet, the proposed efficient end-to-end FAST-VQA and FasterVQA achieve significantly better performance than existing approaches on all VQA benchmarks while requiring only 1/1612 FLOPs compared to the current state-of-the-art. Codes, models and demos are available at https://github.com/timothyhtimothy/FAST-VQA-and-FasterVQA.
Deep Fourier Up-Sampling
Oct 11, 2022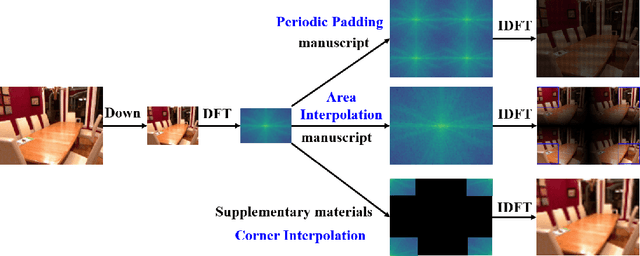
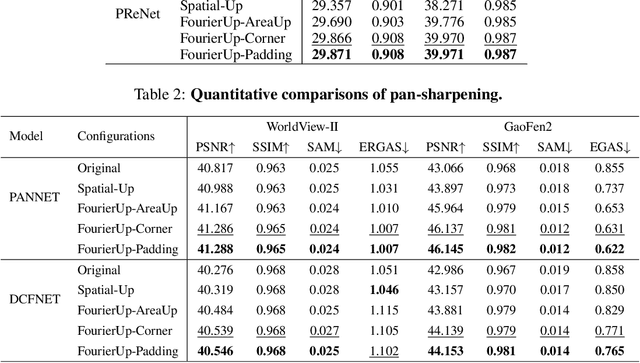
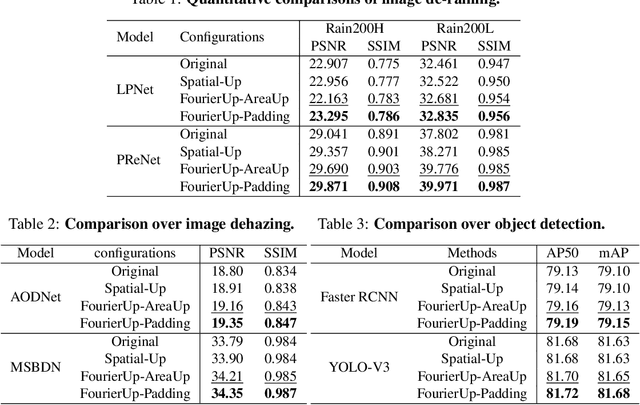
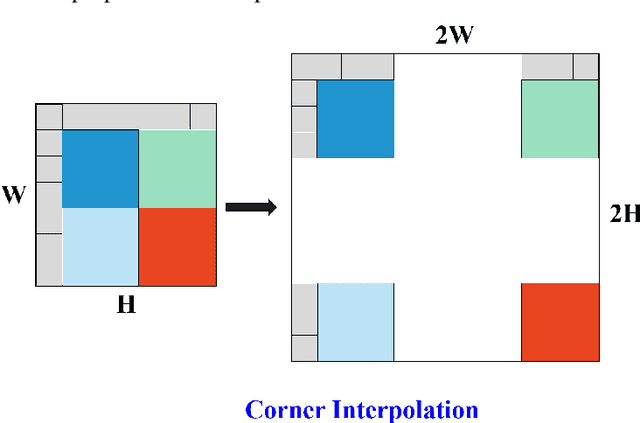
Existing convolutional neural networks widely adopt spatial down-/up-sampling for multi-scale modeling. However, spatial up-sampling operators (\emph{e.g.}, interpolation, transposed convolution, and un-pooling) heavily depend on local pixel attention, incapably exploring the global dependency. In contrast, the Fourier domain obeys the nature of global modeling according to the spectral convolution theorem. Unlike the spatial domain that performs up-sampling with the property of local similarity, up-sampling in the Fourier domain is more challenging as it does not follow such a local property. In this study, we propose a theoretically sound Deep Fourier Up-Sampling (FourierUp) to solve these issues. We revisit the relationships between spatial and Fourier domains and reveal the transform rules on the features of different resolutions in the Fourier domain, which provide key insights for FourierUp's designs. FourierUp as a generic operator consists of three key components: 2D discrete Fourier transform, Fourier dimension increase rules, and 2D inverse Fourier transform, which can be directly integrated with existing networks. Extensive experiments across multiple computer vision tasks, including object detection, image segmentation, image de-raining, image dehazing, and guided image super-resolution, demonstrate the consistent performance gains obtained by introducing our FourierUp.
MIPI 2022 Challenge on RGBW Sensor Fusion: Dataset and Report
Sep 27, 2022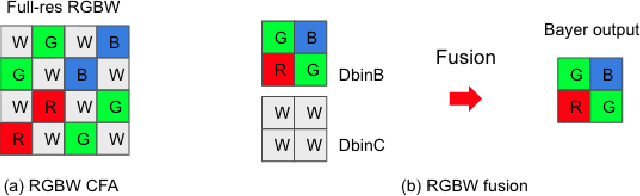
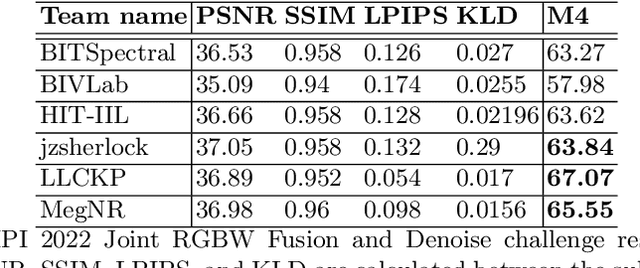


Developing and integrating advanced image sensors with novel algorithms in camera systems are prevalent with the increasing demand for computational photography and imaging on mobile platforms. However, the lack of high-quality data for research and the rare opportunity for in-depth exchange of views from industry and academia constrain the development of mobile intelligent photography and imaging (MIPI). To bridge the gap, we introduce the first MIPI challenge, including five tracks focusing on novel image sensors and imaging algorithms. In this paper, RGBW Joint Fusion and Denoise, one of the five tracks, working on the fusion of binning-mode RGBW to Bayer, is introduced. The participants were provided with a new dataset including 70 (training) and 15 (validation) scenes of high-quality RGBW and Bayer pairs. In addition, for each scene, RGBW of different noise levels was provided at 24dB and 42dB. All the data were captured using an RGBW sensor in both outdoor and indoor conditions. The final results are evaluated using objective metrics, including PSNR, SSIM}, LPIPS, and KLD. A detailed description of all models developed in this challenge is provided in this paper. More details of this challenge and the link to the dataset can be found at https://github.com/mipi-challenge/MIPI2022.
MIPI 2022 Challenge on RGBW Sensor Re-mosaic: Dataset and Report
Sep 15, 2022


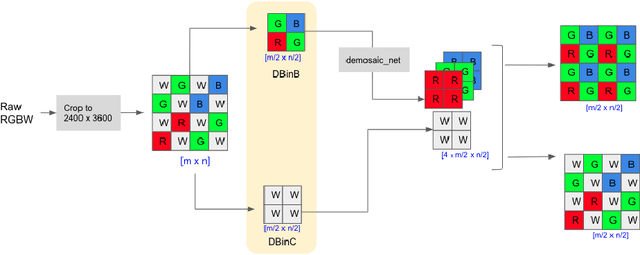
Developing and integrating advanced image sensors with novel algorithms in camera systems are prevalent with the increasing demand for computational photography and imaging on mobile platforms. However, the lack of high-quality data for research and the rare opportunity for in-depth exchange of views from industry and academia constrain the development of mobile intelligent photography and imaging (MIPI). To bridge the gap, we introduce the first MIPI challenge including five tracks focusing on novel image sensors and imaging algorithms. In this paper, RGBW Joint Remosaic and Denoise, one of the five tracks, working on the interpolation of RGBW CFA to Bayer at full resolution, is introduced. The participants were provided with a new dataset including 70 (training) and 15 (validation) scenes of high-quality RGBW and Bayer pairs. In addition, for each scene, RGBW of different noise levels was provided at 0dB, 24dB, and 42dB. All the data were captured using an RGBW sensor in both outdoor and indoor conditions. The final results are evaluated using objective metrics including PSNR, SSIM, LPIPS, and KLD. A detailed description of all models developed in this challenge is provided in this paper. More details of this challenge and the link to the dataset can be found at https://github.com/mipi-challenge/MIPI2022.
MIPI 2022 Challenge on Quad-Bayer Re-mosaic: Dataset and Report
Sep 15, 2022



Developing and integrating advanced image sensors with novel algorithms in camera systems are prevalent with the increasing demand for computational photography and imaging on mobile platforms. However, the lack of high-quality data for research and the rare opportunity for in-depth exchange of views from industry and academia constrain the development of mobile intelligent photography and imaging (MIPI). To bridge the gap, we introduce the first MIPI challenge, including five tracks focusing on novel image sensors and imaging algorithms. In this paper, Quad Joint Remosaic and Denoise, one of the five tracks, working on the interpolation of Quad CFA to Bayer at full resolution, is introduced. The participants were provided a new dataset, including 70 (training) and 15 (validation) scenes of high-quality Quad and Bayer pairs. In addition, for each scene, Quad of different noise levels was provided at 0dB, 24dB, and 42dB. All the data were captured using a Quad sensor in both outdoor and indoor conditions. The final results are evaluated using objective metrics, including PSNR, SSIM, LPIPS, and KLD. A detailed description of all models developed in this challenge is provided in this paper. More details of this challenge and the link to the dataset can be found at https://github.com/mipi-challenge/MIPI2022.
MIPI 2022 Challenge on RGB+ToF Depth Completion: Dataset and Report
Sep 15, 2022
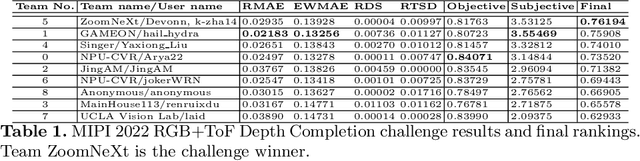
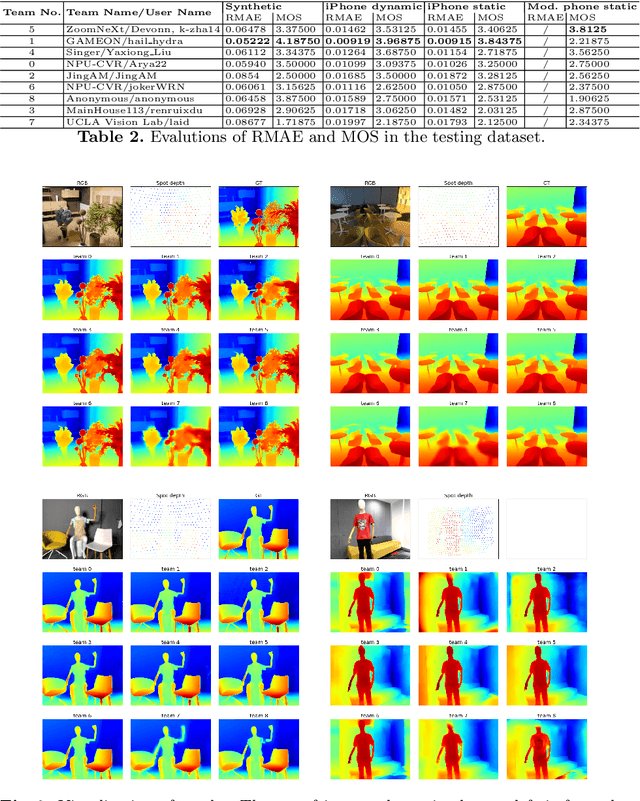
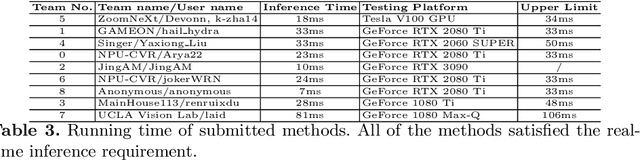
Developing and integrating advanced image sensors with novel algorithms in camera systems is prevalent with the increasing demand for computational photography and imaging on mobile platforms. However, the lack of high-quality data for research and the rare opportunity for in-depth exchange of views from industry and academia constrain the development of mobile intelligent photography and imaging (MIPI). To bridge the gap, we introduce the first MIPI challenge including five tracks focusing on novel image sensors and imaging algorithms. In this paper, RGB+ToF Depth Completion, one of the five tracks, working on the fusion of RGB sensor and ToF sensor (with spot illumination) is introduced. The participants were provided with a new dataset called TetrasRGBD, which contains 18k pairs of high-quality synthetic RGB+Depth training data and 2.3k pairs of testing data from mixed sources. All the data are collected in an indoor scenario. We require that the running time of all methods should be real-time on desktop GPUs. The final results are evaluated using objective metrics and Mean Opinion Score (MOS) subjectively. A detailed description of all models developed in this challenge is provided in this paper. More details of this challenge and the link to the dataset can be found at https://github.com/mipi-challenge/MIPI2022.
MIPI 2022 Challenge on Under-Display Camera Image Restoration: Methods and Results
Sep 15, 2022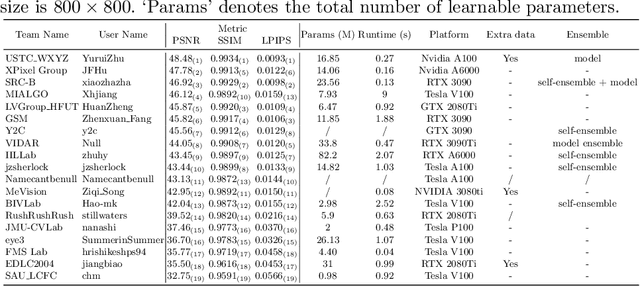
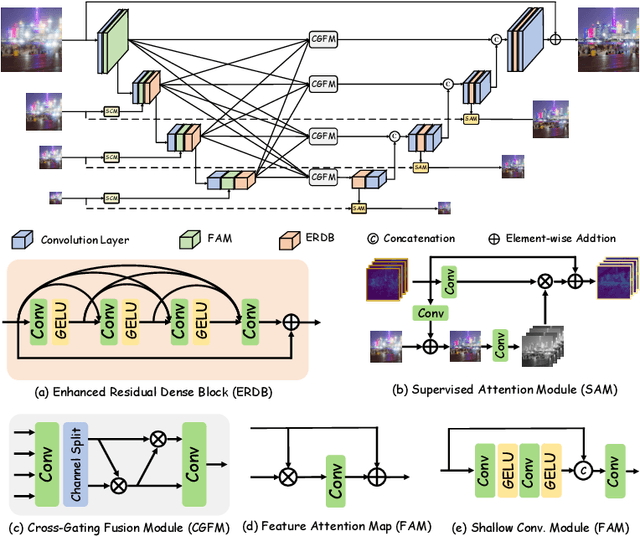
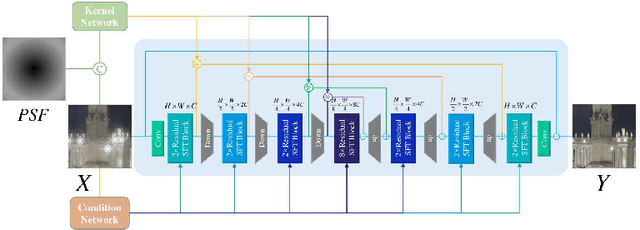
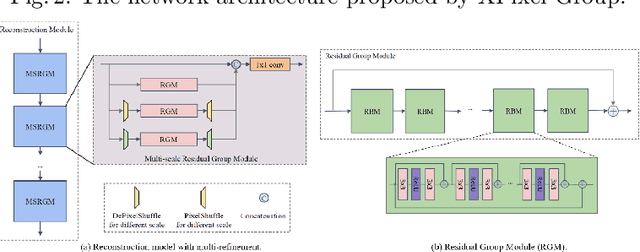
Developing and integrating advanced image sensors with novel algorithms in camera systems are prevalent with the increasing demand for computational photography and imaging on mobile platforms. However, the lack of high-quality data for research and the rare opportunity for in-depth exchange of views from industry and academia constrain the development of mobile intelligent photography and imaging (MIPI). To bridge the gap, we introduce the first MIPI challenge including five tracks focusing on novel image sensors and imaging algorithms. In this paper, we summarize and review the Under-Display Camera (UDC) Image Restoration track on MIPI 2022. In total, 167 participants were successfully registered, and 19 teams submitted results in the final testing phase. The developed solutions in this challenge achieved state-of-the-art performance on Under-Display Camera Image Restoration. A detailed description of all models developed in this challenge is provided in this paper. More details of this challenge and the link to the dataset can be found at https://github.com/mipi-challenge/MIPI2022.