 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnalogy Generation by Prompting Large Language Models: A Case Study of InstructGPT
Oct 11, 2022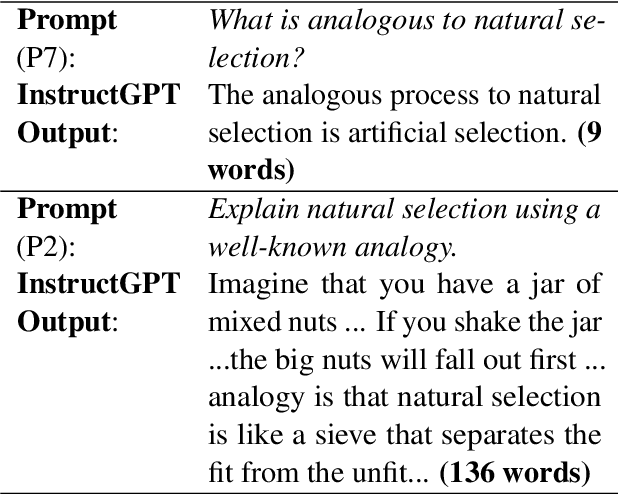
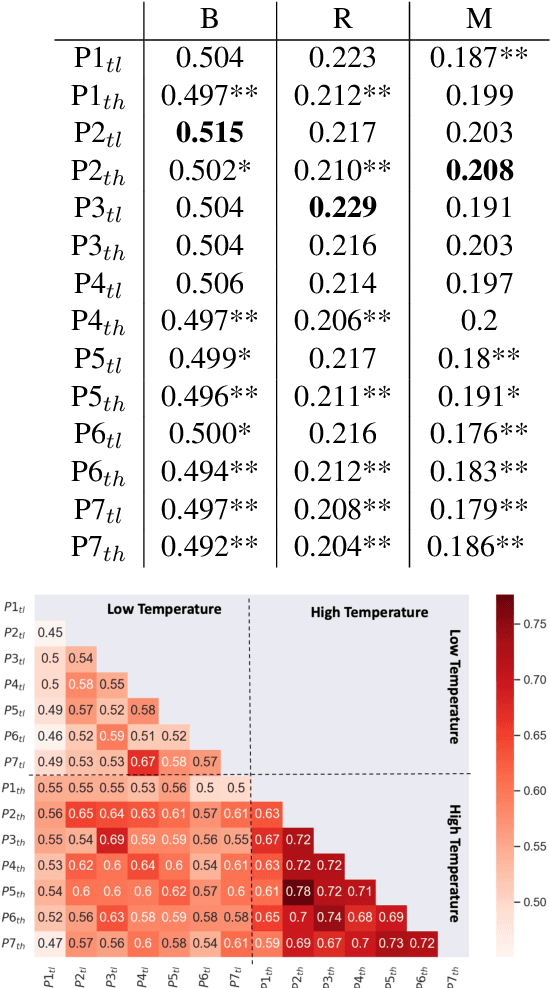
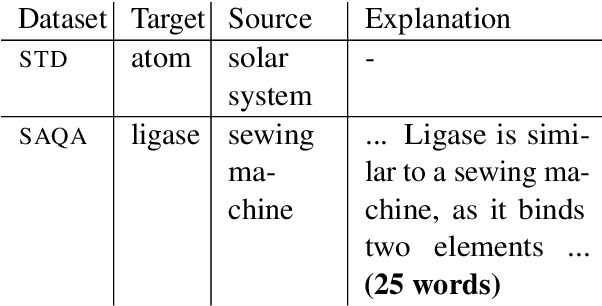
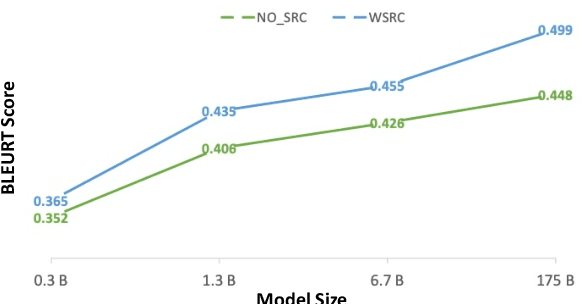
We propose a novel application of prompting Pre-trained Language Models (PLMs) to generate analogies and study how to design effective prompts for two task settings: generating a source concept analogous to a given target concept (aka Analogous Concept Generation or ACG), and generating an explanation of the similarity between a given pair of target concept and source concept (aka Analogous Explanation Generation or AEG). We found that it is feasible to prompt InstructGPT to generate meaningful analogies and the best prompts tend to be precise imperative statements especially with a low temperature setting. We also systematically analyzed the sensitivity of the InstructGPT model to prompt design, temperature, and injected spelling errors, and found that the model is particularly sensitive to certain variations (e.g., questions vs. imperative statements). Further, we conducted human evaluation on 1.4k of the generated analogies and found that the quality of generations varies substantially by model size. The largest InstructGPT model can achieve human-level performance at generating meaningful analogies for a given target while there is still room for improvement on the AEG task.
Can Language Models Be Specific? How?
Oct 11, 2022

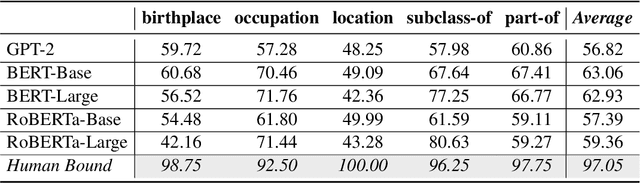
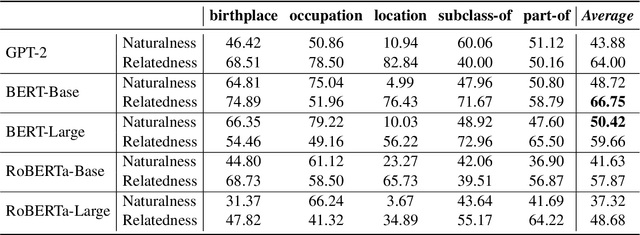
A good speaker not only needs to be correct, but also has the ability to be specific when desired, and so are language models. In this paper, we propose to measure how specific the language of pre-trained language models (PLMs) is. To achieve this, we introduce a novel approach to build a benchmark for specificity testing by forming masked token prediction tasks with prompts. For instance, given ``J. K. Rowling was born in [MASK].'', we want to test whether a more specific answer will be better filled in by PLMs, e.g., Yate instead of England. From our evaluations, we show that existing PLMs have only a slight preference for more specific answers. We identify underlying factors affecting the specificity and design two prompt-based methods to improve the specificity. Results show that the specificity of the models can be improved by the proposed methods without additional training. We believe this work can provide new insights for language modeling and encourage the research community to further explore this important but understudied problem.
HiKonv: Maximizing the Throughput of Quantized Convolution With Novel Bit-wise Management and Computation
Jul 22, 2022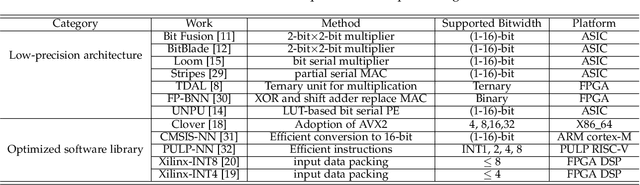
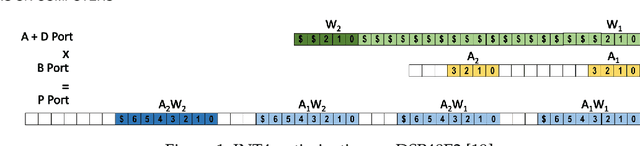
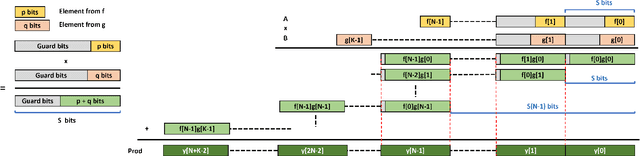
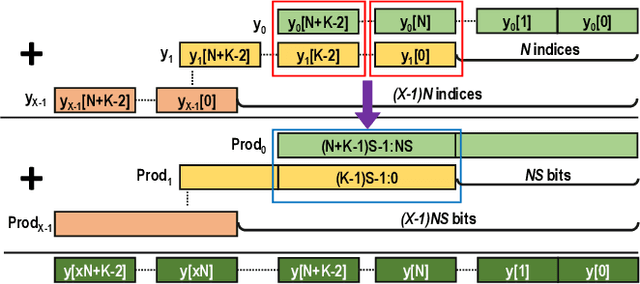
Quantization for CNN has shown significant progress with the intention of reducing the cost of computation and storage with low-bitwidth data representations. There are, however, no systematic studies on how an existing full-bitwidth processing unit, such as ALU in CPUs and DSP in FPGAs, can be better utilized to deliver significantly higher computation throughput for convolution under various quantized bitwidths. In this study, we propose HiKonv, a unified solution that maximizes the throughput of convolution on a given underlying processing unit with low-bitwidth quantized data inputs through novel bit-wise management and parallel computation. We establish theoretical framework and performance models using a full-bitwidth multiplier for highly parallelized low-bitwidth convolution, and demonstrate new breakthroughs for high-performance computing in this critical domain. For example, a single 32-bit processing unit in CPU can deliver 128 binarized convolution operations (multiplications and additions) and 13 4-bit convolution operations with a single multiplication instruction, and a single 27x18 multiplier in the FPGA DSP can deliver 60, 8 or 2 convolution operations with 1, 4 or 8-bit inputs in one clock cycle. We demonstrate the effectiveness of HiKonv on both CPU and FPGA. On CPU, HiKonv outperforms the baseline implementation with 1 to 8-bit inputs and provides up to 7.6x and 1.4x performance improvements for 1-D convolution, and performs 2.74x and 3.19x over the baseline implementation for 4-bit signed and unsigned data inputs for 2-D convolution. On FPGA, HiKonv solution enables a single DSP to process multiple convolutions with a shorter processing latency. For binarized input, each DSP with HiKonv is equivalent up to 76.6 LUTs. Compared to the DAC-SDC 2020 champion model, HiKonv achieves a 2.37x throughput improvement and 2.61x DSP efficiency improvement, respectively.
Generalization Guarantee of Training Graph Convolutional Networks with Graph Topology Sampling
Jul 07, 2022
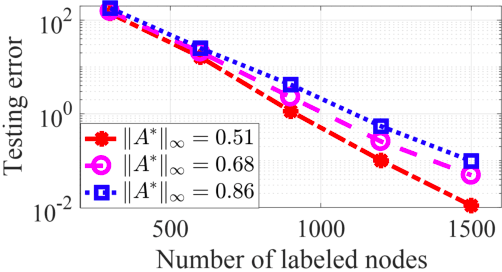
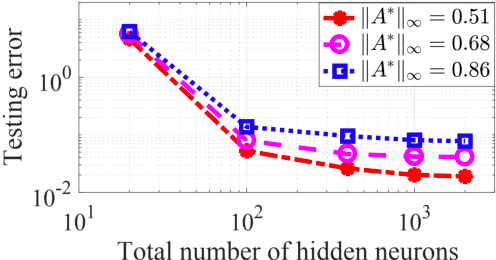

Graph convolutional networks (GCNs) have recently achieved great empirical success in learning graph-structured data. To address its scalability issue due to the recursive embedding of neighboring features, graph topology sampling has been proposed to reduce the memory and computational cost of training GCNs, and it has achieved comparable test performance to those without topology sampling in many empirical studies. To the best of our knowledge, this paper provides the first theoretical justification of graph topology sampling in training (up to) three-layer GCNs for semi-supervised node classification. We formally characterize some sufficient conditions on graph topology sampling such that GCN training leads to a diminishing generalization error. Moreover, our method tackles the nonconvex interaction of weights across layers, which is under-explored in the existing theoretical analyses of GCNs. This paper characterizes the impact of graph structures and topology sampling on the generalization performance and sample complexity explicitly, and the theoretical findings are also justified through numerical experiments.
DKG: A Descriptive Knowledge Graph for Explaining Relationships between Entities
May 21, 2022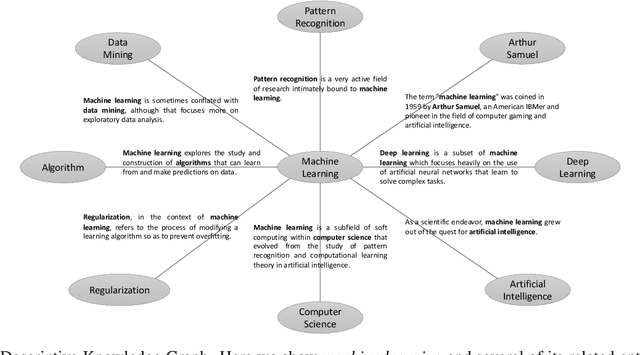
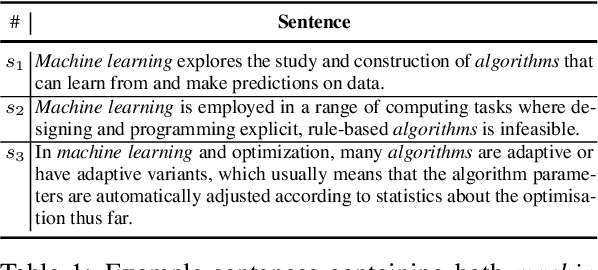
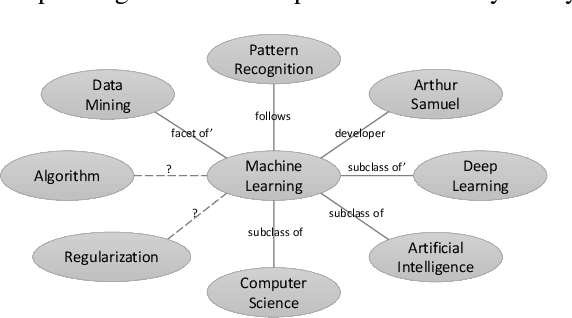
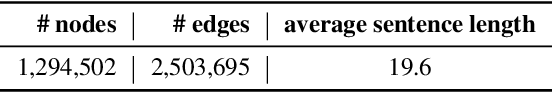
In this paper, we propose Descriptive Knowledge Graph (DKG) - an open and interpretable form of modeling relationships between entities. In DKGs, relationships between entities are represented by relation descriptions. For instance, the relationship between entities of machine learning and algorithm can be described as "Machine learning explores the study and construction of algorithms that can learn from and make predictions on data." To construct DKGs, we propose a self-supervised learning method to extract relation descriptions with the analysis of dependency patterns and a transformer-based relation description synthesizing model to generate relation descriptions. Experiments demonstrate that our system can extract and generate high-quality relation descriptions for explaining entity relationships.
A Word is Worth A Thousand Dollars: Adversarial Attack on Tweets Fools Stock Prediction
May 11, 2022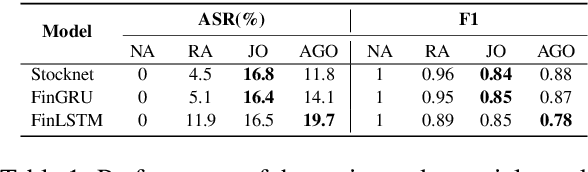
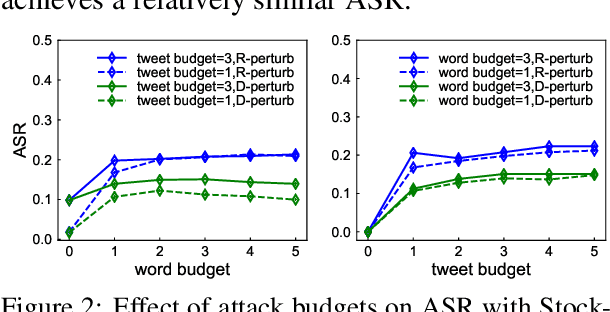
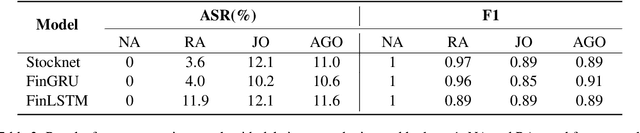
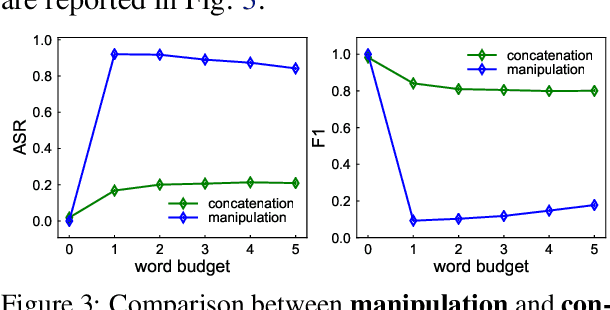
More and more investors and machine learning models rely on social media (e.g., Twitter and Reddit) to gather real-time information and sentiment to predict stock price movements. Although text-based models are known to be vulnerable to adversarial attacks, whether stock prediction models have similar vulnerability is underexplored. In this paper, we experiment with a variety of adversarial attack configurations to fool three stock prediction victim models. We address the task of adversarial generation by solving combinatorial optimization problems with semantics and budget constraints. Our results show that the proposed attack method can achieve consistent success rates and cause significant monetary loss in trading simulation by simply concatenating a perturbed but semantically similar tweet.
QuadraLib: A Performant Quadratic Neural Network Library for Architecture Optimization and Design Exploration
Apr 01, 2022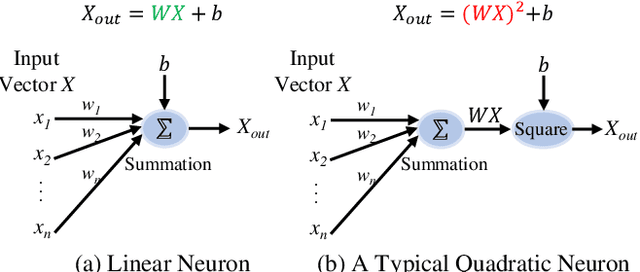

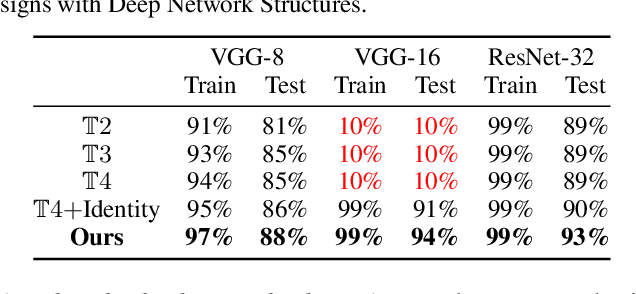
The significant success of Deep Neural Networks (DNNs) is highly promoted by the multiple sophisticated DNN libraries. On the contrary, although some work have proved that Quadratic Deep Neuron Networks (QDNNs) show better non-linearity and learning capability than the first-order DNNs, their neuron design suffers certain drawbacks from theoretical performance to practical deployment. In this paper, we first proposed a new QDNN neuron architecture design, and further developed QuadraLib, a QDNN library to provide architecture optimization and design exploration for QDNNs. Extensive experiments show that our design has good performance regarding prediction accuracy and computation consumption on multiple learning tasks.
How does unlabeled data improve generalization in self-training? A one-hidden-layer theoretical analysis
Jan 25, 2022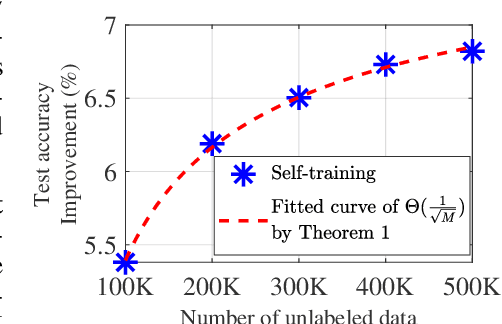

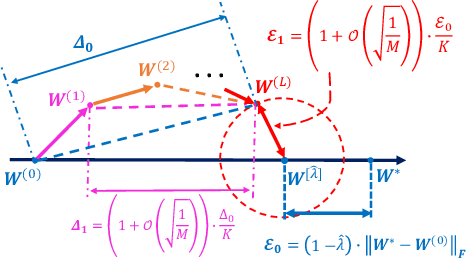
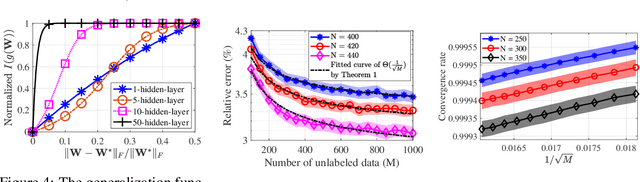
Self-training, a semi-supervised learning algorithm, leverages a large amount of unlabeled data to improve learning when the labeled data are limited. Despite empirical successes, its theoretical characterization remains elusive. To the best of our knowledge, this work establishes the first theoretical analysis for the known iterative self-training paradigm and proves the benefits of unlabeled data in both training convergence and generalization ability. To make our theoretical analysis feasible, we focus on the case of one-hidden-layer neural networks. However, theoretical understanding of iterative self-training is non-trivial even for a shallow neural network. One of the key challenges is that existing neural network landscape analysis built upon supervised learning no longer holds in the (semi-supervised) self-training paradigm. We address this challenge and prove that iterative self-training converges linearly with both convergence rate and generalization accuracy improved in the order of $1/\sqrt{M}$, where $M$ is the number of unlabeled samples. Experiments from shallow neural networks to deep neural networks are also provided to justify the correctness of our established theoretical insights on self-training.
* 15 pages
HiKonv: High Throughput Quantized Convolution With Novel Bit-wise Management and Computation
Dec 28, 2021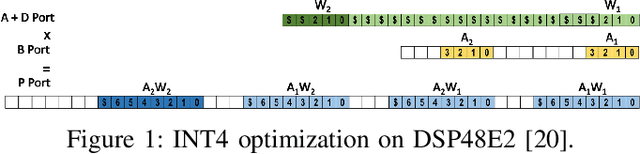
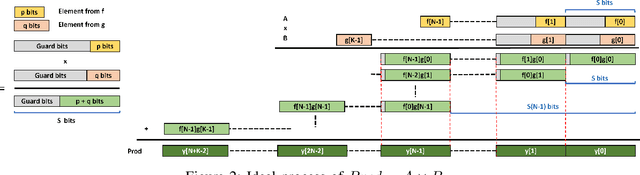

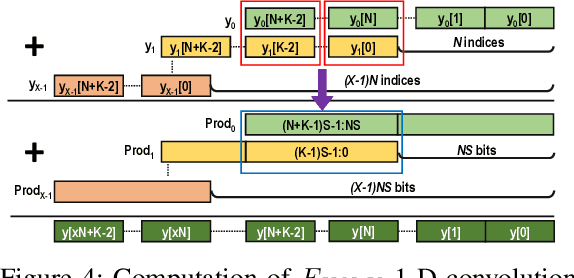
Quantization for Convolutional Neural Network (CNN) has shown significant progress with the intention of reducing the cost of computation and storage with low-bitwidth data inputs. There are, however, no systematic studies on how an existing full-bitwidth processing unit, such as CPUs and DSPs, can be better utilized to carry out significantly higher computation throughput for convolution under various quantized bitwidths. In this study, we propose HiKonv, a unified solution that maximizes the compute throughput of a given underlying processing unit to process low-bitwidth quantized data inputs through novel bit-wise parallel computation. We establish theoretical performance bounds using a full-bitwidth multiplier for highly parallelized low-bitwidth convolution, and demonstrate new breakthroughs for high-performance computing in this critical domain. For example, a single 32-bit processing unit can deliver 128 binarized convolution operations (multiplications and additions) under one CPU instruction, and a single 27x18 DSP core can deliver eight convolution operations with 4-bit inputs in one cycle. We demonstrate the effectiveness of HiKonv on CPU and FPGA for both convolutional layers or a complete DNN model. For a convolutional layer quantized to 4-bit, HiKonv achieves a 3.17x latency improvement over the baseline implementation using C++ on CPU. Compared to the DAC-SDC 2020 champion model for FPGA, HiKonv achieves a 2.37x throughput improvement and 2.61x DSP efficiency improvement, respectively.
Graph Neural Network Training with Data Tiering
Nov 10, 2021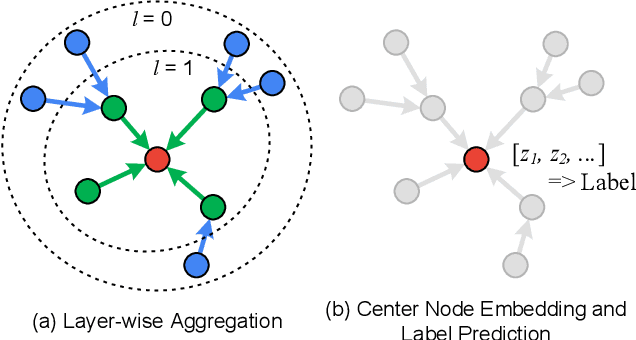
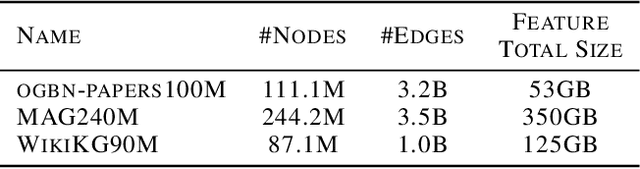
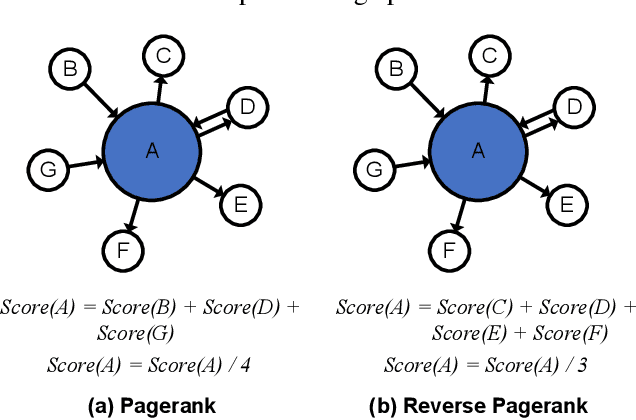
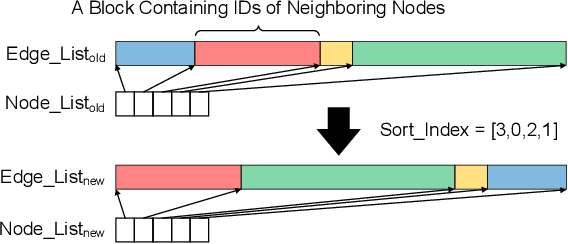
Graph Neural Networks (GNNs) have shown success in learning from graph-structured data, with applications to fraud detection, recommendation, and knowledge graph reasoning. However, training GNN efficiently is challenging because: 1) GPU memory capacity is limited and can be insufficient for large datasets, and 2) the graph-based data structure causes irregular data access patterns. In this work, we provide a method to statistical analyze and identify more frequently accessed data ahead of GNN training. Our data tiering method not only utilizes the structure of input graph, but also an insight gained from actual GNN training process to achieve a higher prediction result. With our data tiering method, we additionally provide a new data placement and access strategy to further minimize the CPU-GPU communication overhead. We also take into account of multi-GPU GNN training as well and we demonstrate the effectiveness of our strategy in a multi-GPU system. The evaluation results show that our work reduces CPU-GPU traffic by 87-95% and improves the training speed of GNN over the existing solutions by 1.6-2.1x on graphs with hundreds of millions of nodes and billions of edges.