 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOptical flow-based vascular respiratory motion compensation
Aug 31, 2023



This paper develops a new vascular respiratory motion compensation algorithm, Motion-Related Compensation (MRC), to conduct vascular respiratory motion compensation by extrapolating the correlation between invisible vascular and visible non-vascular. Robot-assisted vascular intervention can significantly reduce the radiation exposure of surgeons. In robot-assisted image-guided intervention, blood vessels are constantly moving/deforming due to respiration, and they are invisible in the X-ray images unless contrast agents are injected. The vascular respiratory motion compensation technique predicts 2D vascular roadmaps in live X-ray images. When blood vessels are visible after contrast agents injection, vascular respiratory motion compensation is conducted based on the sparse Lucas-Kanade feature tracker. An MRC model is trained to learn the correlation between vascular and non-vascular motions. During the intervention, the invisible blood vessels are predicted with visible tissues and the trained MRC model. Moreover, a Gaussian-based outlier filter is adopted for refinement. Experiments on in-vivo data sets show that the proposed method can yield vascular respiratory motion compensation in 0.032 sec, with an average error 1.086 mm. Our real-time and accurate vascular respiratory motion compensation approach contributes to modern vascular intervention and surgical robots.
BDIS: Bayesian Dense Inverse Searching Method for Real-Time Stereo Surgical Image Matching
May 06, 2022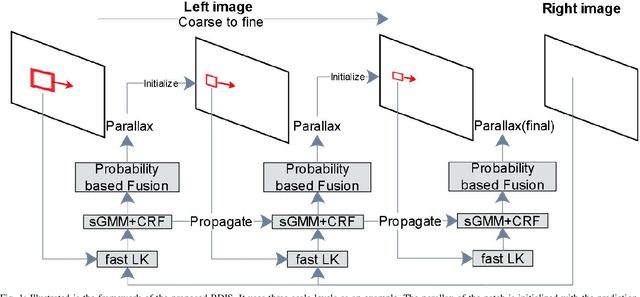
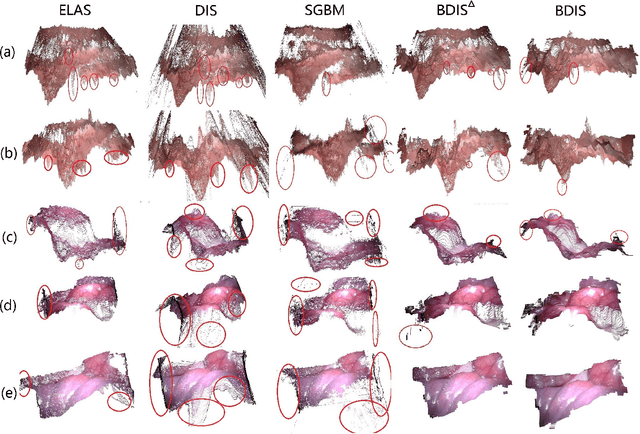
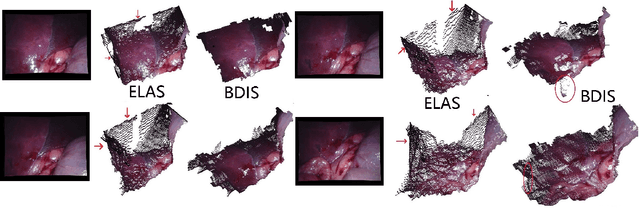
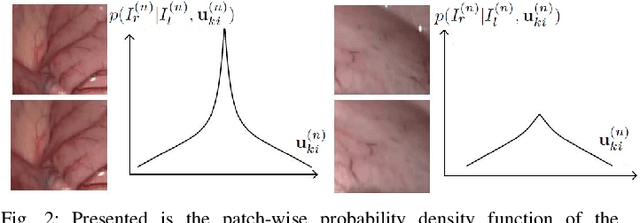
In stereoscope-based Minimally Invasive Surgeries (MIS), dense stereo matching plays an indispensable role in 3D shape recovery, AR, VR, and navigation tasks. Although numerous Deep Neural Network (DNN) approaches are proposed, the conventional prior-free approaches are still popular in the industry because of the lack of open-source annotated data set and the limitation of the task-specific pre-trained DNNs. Among the prior-free stereo matching algorithms, there is no successful real-time algorithm in none GPU environment for MIS. This paper proposes the first CPU-level real-time prior-free stereo matching algorithm for general MIS tasks. We achieve an average 17 Hz on 640*480 images with a single-core CPU (i5-9400) for surgical images. Meanwhile, it achieves slightly better accuracy than the popular ELAS. The patch-based fast disparity searching algorithm is adopted for the rectified stereo images. A coarse-to-fine Bayesian probability and a spatial Gaussian mixed model were proposed to evaluate the patch probability at different scales. An optional probability density function estimation algorithm was adopted to quantify the prediction variance. Extensive experiments demonstrated the proposed method's capability to handle ambiguities introduced by the textureless surfaces and the photometric inconsistency from the non-Lambertian reflectance and dark illumination. The estimated probability managed to balance the confidences of the patches for stereo images at different scales. It has similar or higher accuracy and fewer outliers than the baseline ELAS in MIS, while it is 4-5 times faster. The code and the synthetic data sets are available at https://github.com/JingweiSong/BDIS-v2.
Fusing Convolutional Neural Network and Geometric Constraint for Image-based Indoor Localization
Jan 05, 2022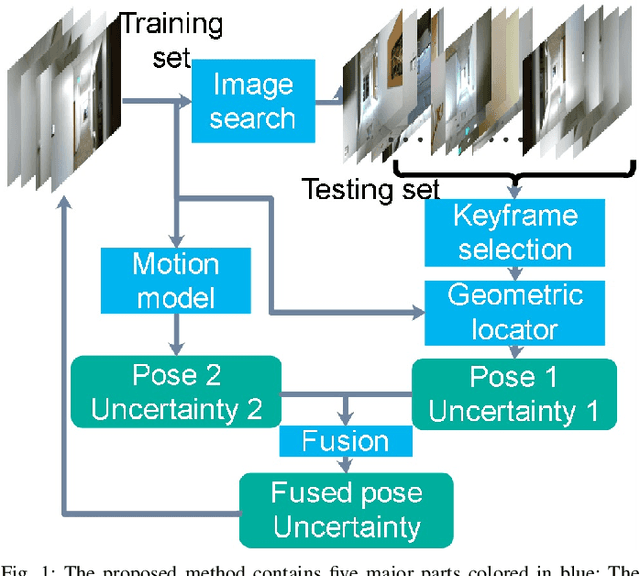
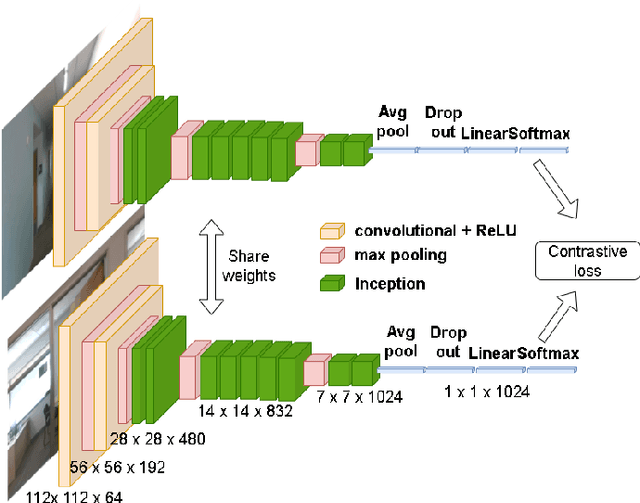
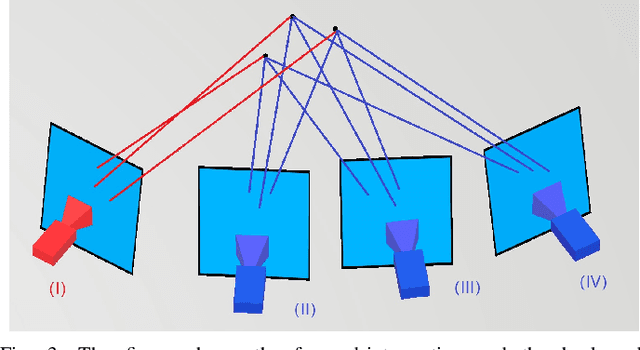

This paper proposes a new image-based localization framework that explicitly localizes the camera/robot by fusing Convolutional Neural Network (CNN) and sequential images' geometric constraints. The camera is localized using a single or few observed images and training images with 6-degree-of-freedom pose labels. A Siamese network structure is adopted to train an image descriptor network, and the visually similar candidate image in the training set is retrieved to localize the testing image geometrically. Meanwhile, a probabilistic motion model predicts the pose based on a constant velocity assumption. The two estimated poses are finally fused using their uncertainties to yield an accurate pose prediction. This method leverages the geometric uncertainty and is applicable in indoor scenarios predominated by diffuse illumination. Experiments on simulation and real data sets demonstrate the efficiency of our proposed method. The results further show that combining the CNN-based framework with geometric constraint achieves better accuracy when compared with CNN-only methods, especially when the training data size is small.
Bayesian dense inverse searching algorithm for real-time stereo matching in minimally invasive surgery
Jun 14, 2021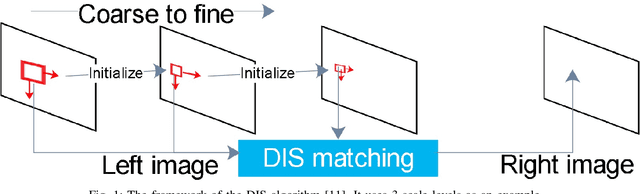
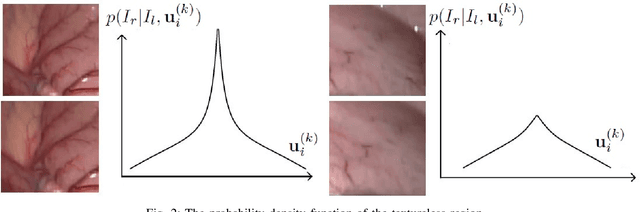
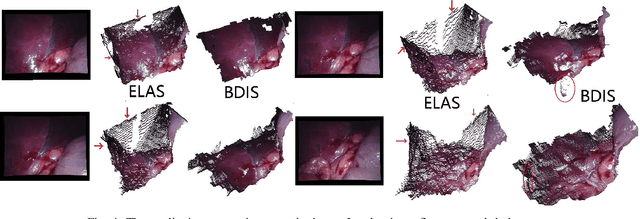

This paper reports a CPU-level real-time stereo matching method for surgical images (10 Hz on 640 * 480 image with a single core of i5-9400). The proposed method is built on the fast ''dense inverse searching'' algorithm, which estimates the disparity of the stereo images. The overlapping image patches (arbitrary squared image segment) from the images at different scales are aligned based on the photometric consistency presumption. We propose a Bayesian framework to evaluate the probability of the optimized patch disparity at different scales. Moreover, we introduce a spatial Gaussian mixed probability distribution to address the pixel-wise probability within the patch. In-vivo and synthetic experiments show that our method can handle ambiguities resulted from the textureless surfaces and the photometric inconsistency caused by the Lambertian reflectance. Our Bayesian method correctly balances the probability of the patch for stereo images at different scales. Experiments indicate that the estimated depth has higher accuracy and fewer outliers than the baseline methods in the surgical scenario.
A closed-form solution to estimate uncertainty in non-rigid structure from motion
Jun 12, 2020
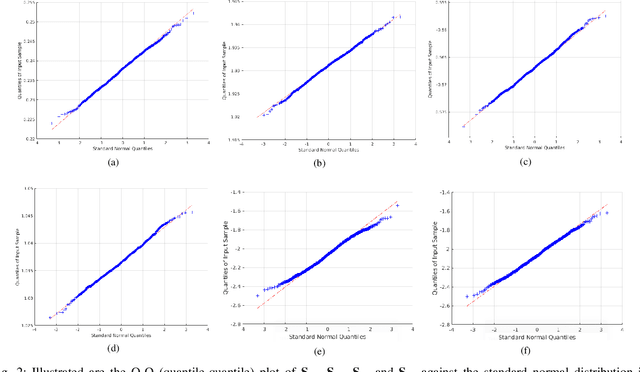

Semi-Definite Programming (SDP) with low-rank prior has been widely applied in Non-Rigid Structure from Motion (NRSfM). Based on a low-rank constraint, it avoids the inherent ambiguity of basis number selection in conventional base-shape or base-trajectory methods. Despite the efficiency in deformable shape reconstruction, it remains unclear how to assess the uncertainty of the recovered shape from the SDP process. In this paper, we present a statistical inference on the element-wise uncertainty quantification of the estimated deforming 3D shape points in the case of the exact low-rank SDP problem. A closed-form uncertainty quantification method is proposed and tested. Moreover, we extend the exact low-rank uncertainty quantification to the approximate low-rank scenario with a numerical optimal rank selection method, which enables solving practical application in SDP based NRSfM scenario. The proposed method provides an independent module to the SDP method and only requires the statistic information of the input 2D tracked points. Extensive experiments prove that the output 3D points have identical normal distribution to the 2D trackings, the proposed method and quantify the uncertainty accurately, and supports that it has desirable effects on routinely SDP low-rank based NRSfM solver.
Combining Deep Learning with Geometric Features for Image based Localization in the Gastrointestinal Tract
May 13, 2020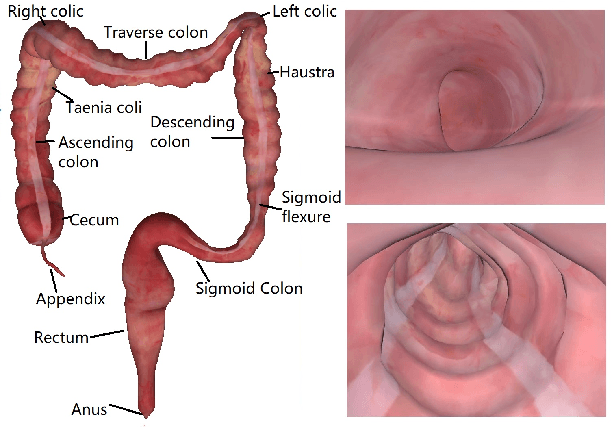

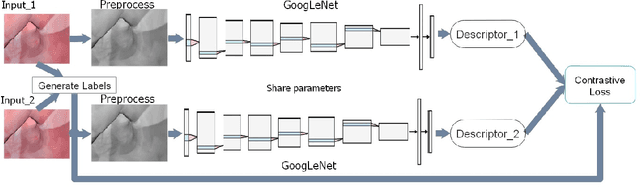
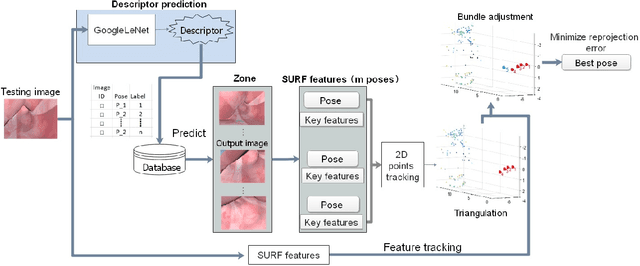
Tracking monocular colonoscope in the Gastrointestinal tract (GI) is a challenging problem as the images suffer from deformation, blurred textures, significant changes in appearance. They greatly restrict the tracking ability of conventional geometry based methods. Even though Deep Learning (DL) can overcome these issues, limited labeling data is a roadblock to state-of-art DL method. Considering these, we propose a novel approach to combine DL method with traditional feature based approach to achieve better localization with small training data. Our method fully exploits the best of both worlds by introducing a Siamese network structure to perform few-shot classification to the closest zone in the segmented training image set. The classified label is further adopted to initialize the pose of scope. To fully use the training dataset, a pre-generated triangulated map points within the zone in the training set are registered with observation and contribute to estimating the optimal pose of the test image. The proposed hybrid method is extensively tested and compared with existing methods, and the result shows significant improvement over traditional geometric based or DL based localization. The accuracy is improved by 28.94% (Position) and 10.97% (Orientation) with respect to state-of-art method.
Uncertainty Quantification for Hyperspectral Image Denoising Frameworks based on Low-rank Matrix Approximation
Apr 23, 2020

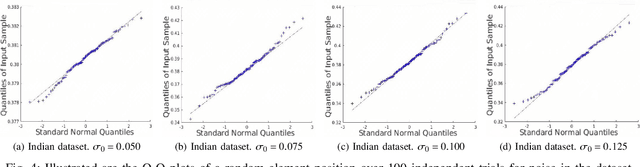
Low-rank matrix approximation (LRMA) is a technique widely applied in hyperspectral images (HSI) denoising or completion. The uncertainty quantification of the estimated restored HSI, however, has not been addressed in previous researches. The lack of uncertainty of the product significantly limits the applications like multi-source or multi-scale data fusion, data assimilation and product confidence quantification, since these applications require an accurate way to describe the statistical distributions of the source data. To address this issue, we propose a prior-free closed-form element-wise uncertainty quantification method for the LRMA based HSI restoration. The proposed approach only requires the uncertainty of the observed HSI and can yield uncertainty in a limited amount of time and with similar time complexity comparing to the LRMA technique. We conduct extensive experiments to validate that the closed-form uncertainty describes the estimation accurately, is robust to at least 10\% ratio of random impulse noises and takes only around 10-20% amount of time of LRMA. All the experiments indicate that the proposed closed-form uncertainty quantification method is more applicable to be deployed to real-world applications than the baseline Monte-Carlo tests.
Dynamic Reconstruction of Deformable Soft-tissue with Stereo Scope in Minimal Invasive Surgery
Mar 22, 2020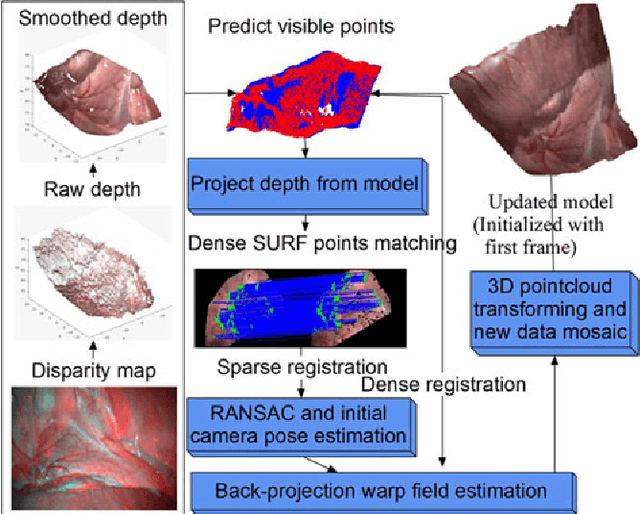
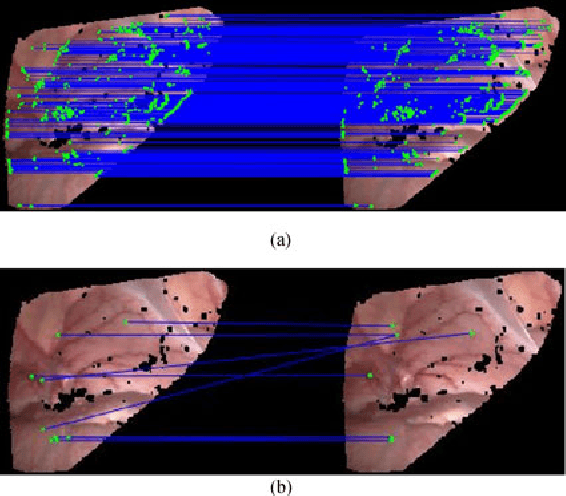
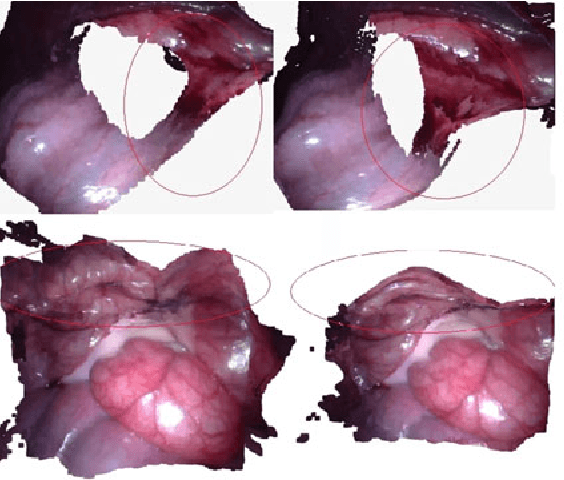

In minimal invasive surgery, it is important to rebuild and visualize the latest deformed shape of soft-tissue surfaces to mitigate tissue damages. This paper proposes an innovative Simultaneous Localization and Mapping (SLAM) algorithm for deformable dense reconstruction of surfaces using a sequence of images from a stereoscope. We introduce a warping field based on the Embedded Deformation (ED) nodes with 3D shapes recovered from consecutive pairs of stereo images. The warping field is estimated by deforming the last updated model to the current live model. Our SLAM system can: (1) Incrementally build a live model by progressively fusing new observations with vivid accurate texture. (2) Estimate the deformed shape of unobserved region with the principle As-Rigid-As-Possible. (3) Show the consecutive shape of models. (4) Estimate the current relative pose between the soft-tissue and the scope. In-vivo experiments with publicly available datasets demonstrate that the 3D models can be incrementally built for different soft-tissues with different deformations from sequences of stereo images obtained by laparoscopes. Results show the potential clinical application of our SLAM system for providing surgeon useful shape and texture information in minimal invasive surgery.
Curved Buildings Reconstruction from Airborne LiDAR Data by Matching and Deforming Geometric Primitives
Mar 22, 2020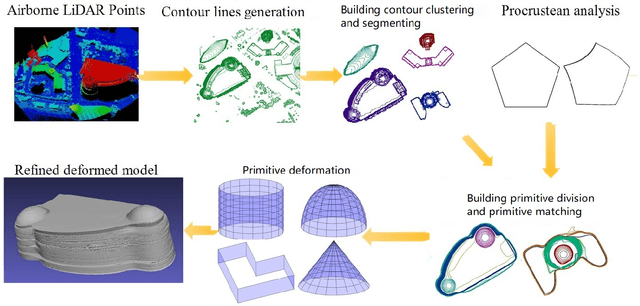
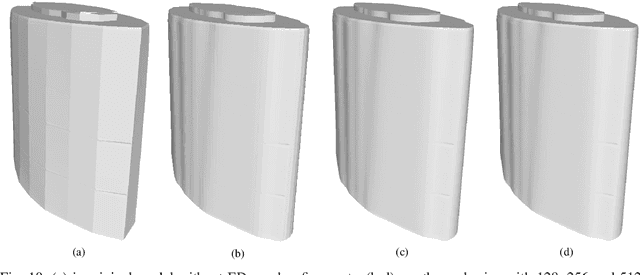


Airborne LiDAR (Light Detection and Ranging) data is widely applied in building reconstruction, with studies reporting success in typical buildings. However, the reconstruction of curved buildings remains an open research problem. To this end, we propose a new framework for curved building reconstruction via assembling and deforming geometric primitives. The input LiDAR point cloud are first converted into contours where individual buildings are identified. After recognizing geometric units (primitives) from building contours, we get initial models by matching basic geometric primitives to these primitives. To polish assembly models, we employ a warping field for model refinements. Specifically, an embedded deformation (ED) graph is constructed via downsampling the initial model. Then, the point-to-model displacements are minimized by adjusting node parameters in the ED graph based on our objective function. The presented framework is validated on several highly curved buildings collected by various LiDAR in different cities. The experimental results, as well as accuracy comparison, demonstrate the advantage and effectiveness of our method. {The new insight attributes to an efficient reconstruction manner.} Moreover, we prove that the primitive-based framework significantly reduces the data storage to 10-20 percent of classical mesh models.
Are We Ready for Service Robots? The OpenLORIS-Scene Datasets for Lifelong SLAM
Nov 13, 2019
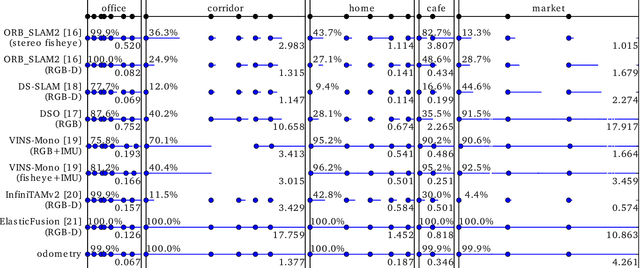
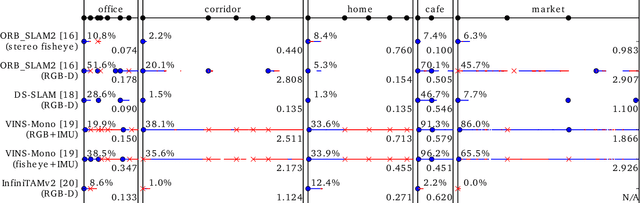
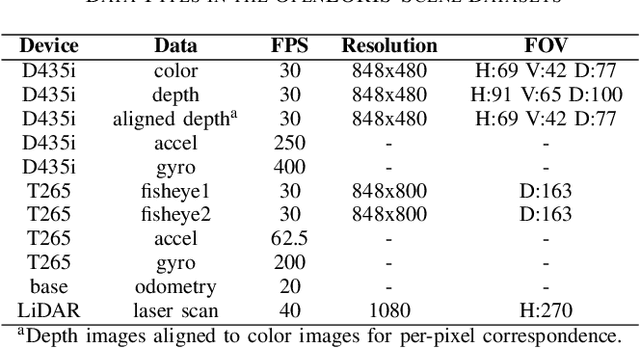
Service robots should be able to operate autonomously in dynamic and daily changing environments over an extended period of time. While Simultaneous Localization And Mapping (SLAM) is one of the most fundamental problems for robotic autonomy, most existing SLAM works are evaluated with data sequences that are recorded in a short period of time. In real-world deployment, there can be out-of-sight scene changes caused by both natural factors and human activities. For example, in home scenarios, most objects may be movable, replaceable or deformable, and the visual features of the same place may be significantly different in some successive days. Such out-of-sight dynamics pose great challenges to the robustness of pose estimation, and hence a robot's long-term deployment and operation. To differentiate the forementioned problem from the conventional works which are usually evaluated in a static setting in a single run, the term lifelong SLAM is used here to address SLAM problems in an ever-changing environment over a long period of time. To accelerate lifelong SLAM research, we release the OpenLORIS-Scene datasets. The data are collected in real-world indoor scenes, for multiple times in each place to include scene changes in real life. We also design benchmarking metrics for lifelong SLAM, with which the robustness and accuracy of pose estimation are evaluated separately. The datasets and benchmark are available online at https://lifelong-robotic-vision.github.io/dataset/scene.