 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProvably Extending PageRank-based Local Clustering Algorithm to Weighted Directed Graphs with Self-Loops and to Hypergraphs
Dec 04, 2024



Local clustering aims to find a compact cluster near the given starting instances. This work focuses on graph local clustering, which has broad applications beyond graphs because of the internal connectivities within various modalities. While most existing studies on local graph clustering adopt the discrete graph setting (i.e., unweighted graphs without self-loops), real-world graphs can be more complex. In this paper, we extend the non-approximating Andersen-Chung-Lang ("ACL") algorithm beyond discrete graphs and generalize its quadratic optimality to a wider range of graphs, including weighted, directed, and self-looped graphs and hypergraphs. Specifically, leveraging PageRank, we propose two algorithms: GeneralACL for graphs and HyperACL for hypergraphs. We theoretically prove that, under two mild conditions, both algorithms can identify a quadratically optimal local cluster in terms of conductance with at least 1/2 probability. On the property of hypergraphs, we address a fundamental gap in the literature by defining conductance for hypergraphs from the perspective of hypergraph random walks. Additionally, we provide experiments to validate our theoretical findings.
Transforming the Hybrid Cloud for Emerging AI Workloads
Nov 20, 2024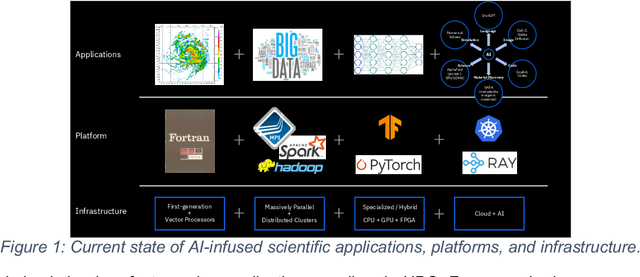
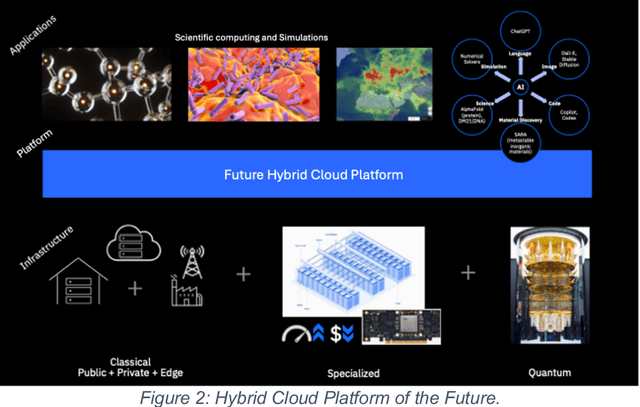
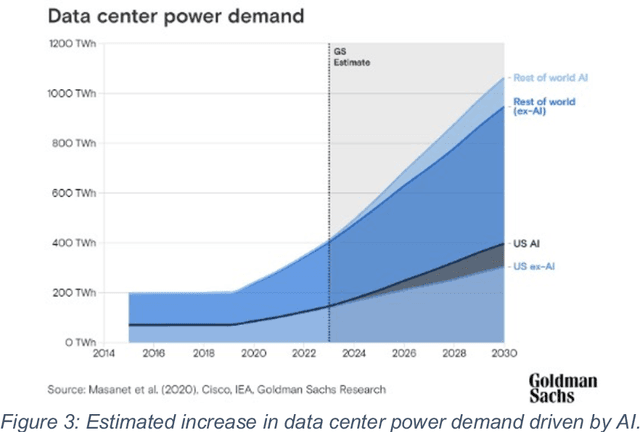
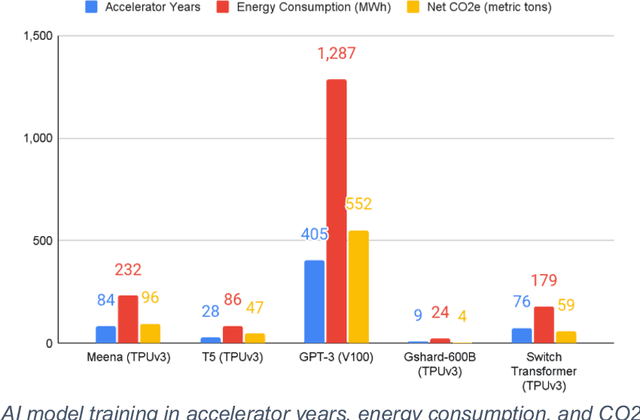
This white paper, developed through close collaboration between IBM Research and UIUC researchers within the IIDAI Institute, envisions transforming hybrid cloud systems to meet the growing complexity of AI workloads through innovative, full-stack co-design approaches, emphasizing usability, manageability, affordability, adaptability, efficiency, and scalability. By integrating cutting-edge technologies such as generative and agentic AI, cross-layer automation and optimization, unified control plane, and composable and adaptive system architecture, the proposed framework addresses critical challenges in energy efficiency, performance, and cost-effectiveness. Incorporating quantum computing as it matures will enable quantum-accelerated simulations for materials science, climate modeling, and other high-impact domains. Collaborative efforts between academia and industry are central to this vision, driving advancements in foundation models for material design and climate solutions, scalable multimodal data processing, and enhanced physics-based AI emulators for applications like weather forecasting and carbon sequestration. Research priorities include advancing AI agentic systems, LLM as an Abstraction (LLMaaA), AI model optimization and unified abstractions across heterogeneous infrastructure, end-to-end edge-cloud transformation, efficient programming model, middleware and platform, secure infrastructure, application-adaptive cloud systems, and new quantum-classical collaborative workflows. These ideas and solutions encompass both theoretical and practical research questions, requiring coordinated input and support from the research community. This joint initiative aims to establish hybrid clouds as secure, efficient, and sustainable platforms, fostering breakthroughs in AI-driven applications and scientific discovery across academia, industry, and society.
PageRank Bandits for Link Prediction
Nov 03, 2024Link prediction is a critical problem in graph learning with broad applications such as recommender systems and knowledge graph completion. Numerous research efforts have been directed at solving this problem, including approaches based on similarity metrics and Graph Neural Networks (GNN). However, most existing solutions are still rooted in conventional supervised learning, which makes it challenging to adapt over time to changing customer interests and to address the inherent dilemma of exploitation versus exploration in link prediction. To tackle these challenges, this paper reformulates link prediction as a sequential decision-making process, where each link prediction interaction occurs sequentially. We propose a novel fusion algorithm, PRB (PageRank Bandits), which is the first to combine contextual bandits with PageRank for collaborative exploitation and exploration. We also introduce a new reward formulation and provide a theoretical performance guarantee for PRB. Finally, we extensively evaluate PRB in both online and offline settings, comparing it with bandit-based and graph-based methods. The empirical success of PRB demonstrates the value of the proposed fusion approach. Our code is released at https://github.com/jiaruzouu/PRB.
Co-clustering for Federated Recommender System
Nov 03, 2024



As data privacy and security attract increasing attention, Federated Recommender System (FRS) offers a solution that strikes a balance between providing high-quality recommendations and preserving user privacy. However, the presence of statistical heterogeneity in FRS, commonly observed due to personalized decision-making patterns, can pose challenges. To address this issue and maximize the benefit of collaborative filtering (CF) in FRS, it is intuitive to consider clustering clients (users) as well as items into different groups and learning group-specific models. Existing methods either resort to client clustering via user representations-risking privacy leakage, or employ classical clustering strategies on item embeddings or gradients, which we found are plagued by the curse of dimensionality. In this paper, we delve into the inefficiencies of the K-Means method in client grouping, attributing failures due to the high dimensionality as well as data sparsity occurring in FRS, and propose CoFedRec, a novel Co-clustering Federated Recommendation mechanism, to address clients heterogeneity and enhance the collaborative filtering within the federated framework. Specifically, the server initially formulates an item membership from the client-provided item networks. Subsequently, clients are grouped regarding a specific item category picked from the item membership during each communication round, resulting in an intelligently aggregated group model. Meanwhile, to comprehensively capture the global inter-relationships among items, we incorporate an additional supervised contrastive learning term based on the server-side generated item membership into the local training phase for each client. Extensive experiments on four datasets are provided, which verify the effectiveness of the proposed CoFedRec.
LLM-Forest for Health Tabular Data Imputation
Oct 28, 2024



Missing data imputation is a critical challenge in tabular datasets, especially in healthcare, where data completeness is vital for accurate analysis. Large language models (LLMs), trained on vast corpora, have shown strong potential in data generation, making them a promising tool for tabular data imputation. However, challenges persist in designing effective prompts for a finetuning-free process and in mitigating the risk of LLM hallucinations. To address these issues, we propose a novel framework, LLM-Forest, which introduces a "forest" of few-shot learning LLM "trees" with confidence-based weighted voting. This framework is established on a new concept of bipartite information graphs to identify high-quality relevant neighboring entries with both feature and value granularity. Extensive experiments on four real-world healthcare datasets demonstrate the effectiveness and efficiency of LLM-Forest.
Hypergraphs as Weighted Directed Self-Looped Graphs: Spectral Properties, Clustering, Cheeger Inequality
Oct 23, 2024



Hypergraphs naturally arise when studying group relations and have been widely used in the field of machine learning. There has not been a unified formulation of hypergraphs, yet the recently proposed edge-dependent vertex weights (EDVW) modeling is one of the most generalized modeling methods of hypergraphs, i.e., most existing hypergraphs can be formulated as EDVW hypergraphs without any information loss to the best of our knowledge. However, the relevant algorithmic developments on EDVW hypergraphs remain nascent: compared to spectral graph theories, the formulations are incomplete, the spectral clustering algorithms are not well-developed, and one result regarding hypergraph Cheeger Inequality is even incorrect. To this end, deriving a unified random walk-based formulation, we propose our definitions of hypergraph Rayleigh Quotient, NCut, boundary/cut, volume, and conductance, which are consistent with the corresponding definitions on graphs. Then, we prove that the normalized hypergraph Laplacian is associated with the NCut value, which inspires our HyperClus-G algorithm for spectral clustering on EDVW hypergraphs. Finally, we prove that HyperClus-G can always find an approximately linearly optimal partitioning in terms of Both NCut and conductance. Additionally, we provide extensive experiments to validate our theoretical findings from an empirical perspective.
Parametric Graph Representations in the Era of Foundation Models: A Survey and Position
Oct 16, 2024


Graphs have been widely used in the past decades of big data and AI to model comprehensive relational data. When analyzing a graph's statistical properties, graph laws serve as essential tools for parameterizing its structure. Identifying meaningful graph laws can significantly enhance the effectiveness of various applications, such as graph generation and link prediction. Facing the large-scale foundation model developments nowadays, the study of graph laws reveals new research potential, e.g., providing multi-modal information for graph neural representation learning and breaking the domain inconsistency of different graph data. In this survey, we first review the previous study of graph laws from multiple perspectives, i.e., macroscope and microscope of graphs, low-order and high-order graphs, static and dynamic graphs, different observation spaces, and newly proposed graph parameters. After we review various real-world applications benefiting from the guidance of graph laws, we conclude the paper with current challenges and future research directions.
Online Multi-modal Root Cause Analysis
Oct 13, 2024Root Cause Analysis (RCA) is essential for pinpointing the root causes of failures in microservice systems. Traditional data-driven RCA methods are typically limited to offline applications due to high computational demands, and existing online RCA methods handle only single-modal data, overlooking complex interactions in multi-modal systems. In this paper, we introduce OCEAN, a novel online multi-modal causal structure learning method for root cause localization. OCEAN employs a dilated convolutional neural network to capture long-term temporal dependencies and graph neural networks to learn causal relationships among system entities and key performance indicators. We further design a multi-factor attention mechanism to analyze and reassess the relationships among different metrics and log indicators/attributes for enhanced online causal graph learning. Additionally, a contrastive mutual information maximization-based graph fusion module is developed to effectively model the relationships across various modalities. Extensive experiments on three real-world datasets demonstrate the effectiveness and efficiency of our proposed method.
AdaRC: Mitigating Graph Structure Shifts during Test-Time
Oct 09, 2024



Powerful as they are, graph neural networks (GNNs) are known to be vulnerable to distribution shifts. Recently, test-time adaptation (TTA) has attracted attention due to its ability to adapt a pre-trained model to a target domain without re-accessing the source domain. However, existing TTA algorithms are primarily designed for attribute shifts in vision tasks, where samples are independent. These methods perform poorly on graph data that experience structure shifts, where node connectivity differs between source and target graphs. We attribute this performance gap to the distinct impact of node attribute shifts versus graph structure shifts: the latter significantly degrades the quality of node representations and blurs the boundaries between different node categories. To address structure shifts in graphs, we propose AdaRC, an innovative framework designed for effective and efficient adaptation to structure shifts by adjusting the hop-aggregation parameters in GNNs. To enhance the representation quality, we design a prediction-informed clustering loss to encourage the formation of distinct clusters for different node categories. Additionally, AdaRC seamlessly integrates with existing TTA algorithms, allowing it to handle attribute shifts effectively while improving overall performance under combined structure and attribute shifts. We validate the effectiveness of AdaRC on both synthetic and real-world datasets, demonstrating its robustness across various combinations of structure and attribute shifts.
Fair Anomaly Detection For Imbalanced Groups
Sep 17, 2024



Anomaly detection (AD) has been widely studied for decades in many real-world applications, including fraud detection in finance, and intrusion detection for cybersecurity, etc. Due to the imbalanced nature between protected and unprotected groups and the imbalanced distributions of normal examples and anomalies, the learning objectives of most existing anomaly detection methods tend to solely concentrate on the dominating unprotected group. Thus, it has been recognized by many researchers about the significance of ensuring model fairness in anomaly detection. However, the existing fair anomaly detection methods tend to erroneously label most normal examples from the protected group as anomalies in the imbalanced scenario where the unprotected group is more abundant than the protected group. This phenomenon is caused by the improper design of learning objectives, which statistically focus on learning the frequent patterns (i.e., the unprotected group) while overlooking the under-represented patterns (i.e., the protected group). To address these issues, we propose FairAD, a fairness-aware anomaly detection method targeting the imbalanced scenario. It consists of a fairness-aware contrastive learning module and a rebalancing autoencoder module to ensure fairness and handle the imbalanced data issue, respectively. Moreover, we provide the theoretical analysis that shows our proposed contrastive learning regularization guarantees group fairness. Empirical studies demonstrate the effectiveness and efficiency of FairAD across multiple real-world datasets.