 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutoTool: Dynamic Tool Selection and Integration for Agentic Reasoning
Dec 15, 2025Agentic reinforcement learning has advanced large language models (LLMs) to reason through long chain-of-thought trajectories while interleaving external tool use. Existing approaches assume a fixed inventory of tools, limiting LLM agents' adaptability to new or evolving toolsets. We present AutoTool, a framework that equips LLM agents with dynamic tool-selection capabilities throughout their reasoning trajectories. We first construct a 200k dataset with explicit tool-selection rationales across 1,000+ tools and 100+ tasks spanning mathematics, science, code generation, and multimodal reasoning. Building on this data foundation, AutoTool employs a dual-phase optimization pipeline: (i) supervised and RL-based trajectory stabilization for coherent reasoning, and (ii) KL-regularized Plackett-Luce ranking to refine consistent multi-step tool selection. Across ten diverse benchmarks, we train two base models, Qwen3-8B and Qwen2.5-VL-7B, with AutoTool. With fewer parameters, AutoTool consistently outperforms advanced LLM agents and tool-integration methods, yielding average gains of 6.4% in math & science reasoning, 4.5% in search-based QA, 7.7% in code generation, and 6.9% in multimodal understanding. In addition, AutoTool exhibits stronger generalization by dynamically leveraging unseen tools from evolving toolsets during inference.
Transformer Copilot: Learning from The Mistake Log in LLM Fine-tuning
May 22, 2025



Large language models are typically adapted to downstream tasks through supervised fine-tuning on domain-specific data. While standard fine-tuning focuses on minimizing generation loss to optimize model parameters, we take a deeper step by retaining and leveraging the model's own learning signals, analogous to how human learners reflect on past mistakes to improve future performance. We first introduce the concept of Mistake Log to systematically track the model's learning behavior and recurring errors throughout fine-tuning. Treating the original transformer-based model as the Pilot, we correspondingly design a Copilot model to refine the Pilot's inference performance via logits rectification. We name the overall Pilot-Copilot framework the Transformer Copilot, which introduces (i) a novel Copilot model design, (ii) a joint training paradigm where the Copilot continuously learns from the evolving Mistake Log alongside the Pilot, and (iii) a fused inference paradigm where the Copilot rectifies the Pilot's logits for enhanced generation. We provide both theoretical and empirical analyses on our new learning framework. Experiments on 12 benchmarks spanning commonsense, arithmetic, and recommendation tasks demonstrate that Transformer Copilot consistently improves performance by up to 34.5%, while introducing marginal computational overhead to Pilot models and exhibiting strong scalability and transferability.
PageRank Bandits for Link Prediction
Nov 03, 2024Link prediction is a critical problem in graph learning with broad applications such as recommender systems and knowledge graph completion. Numerous research efforts have been directed at solving this problem, including approaches based on similarity metrics and Graph Neural Networks (GNN). However, most existing solutions are still rooted in conventional supervised learning, which makes it challenging to adapt over time to changing customer interests and to address the inherent dilemma of exploitation versus exploration in link prediction. To tackle these challenges, this paper reformulates link prediction as a sequential decision-making process, where each link prediction interaction occurs sequentially. We propose a novel fusion algorithm, PRB (PageRank Bandits), which is the first to combine contextual bandits with PageRank for collaborative exploitation and exploration. We also introduce a new reward formulation and provide a theoretical performance guarantee for PRB. Finally, we extensively evaluate PRB in both online and offline settings, comparing it with bandit-based and graph-based methods. The empirical success of PRB demonstrates the value of the proposed fusion approach. Our code is released at https://github.com/jiaruzouu/PRB.
Meta Clustering of Neural Bandits
Aug 10, 2024The contextual bandit has been identified as a powerful framework to formulate the recommendation process as a sequential decision-making process, where each item is regarded as an arm and the objective is to minimize the regret of $T$ rounds. In this paper, we study a new problem, Clustering of Neural Bandits, by extending previous work to the arbitrary reward function, to strike a balance between user heterogeneity and user correlations in the recommender system. To solve this problem, we propose a novel algorithm called M-CNB, which utilizes a meta-learner to represent and rapidly adapt to dynamic clusters, along with an informative Upper Confidence Bound (UCB)-based exploration strategy. We provide an instance-dependent performance guarantee for the proposed algorithm that withstands the adversarial context, and we further prove the guarantee is at least as good as state-of-the-art (SOTA) approaches under the same assumptions. In extensive experiments conducted in both recommendation and online classification scenarios, M-CNB outperforms SOTA baselines. This shows the effectiveness of the proposed approach in improving online recommendation and online classification performance.
Neural Contextual Bandits for Personalized Recommendation
Dec 21, 2023In the dynamic landscape of online businesses, recommender systems are pivotal in enhancing user experiences. While traditional approaches have relied on static supervised learning, the quest for adaptive, user-centric recommendations has led to the emergence of the formulation of contextual bandits. This tutorial investigates the contextual bandits as a powerful framework for personalized recommendations. We delve into the challenges, advanced algorithms and theories, collaborative strategies, and open challenges and future prospects within this field. Different from existing related tutorials, (1) we focus on the exploration perspective of contextual bandits to alleviate the ``Matthew Effect'' in the recommender systems, i.e., the rich get richer and the poor get poorer, concerning the popularity of items; (2) in addition to the conventional linear contextual bandits, we will also dedicated to neural contextual bandits which have emerged as an important branch in recent years, to investigate how neural networks benefit contextual bandits for personalized recommendation both empirically and theoretically; (3) we will cover the latest topic, collaborative neural contextual bandits, to incorporate both user heterogeneity and user correlations customized for recommender system; (4) we will provide and discuss the new emerging challenges and open questions for neural contextual bandits with applications in the personalized recommendation, especially for large neural models.
Graph Neural Bandits
Aug 21, 2023Contextual bandits algorithms aim to choose the optimal arm with the highest reward out of a set of candidates based on the contextual information. Various bandit algorithms have been applied to real-world applications due to their ability of tackling the exploitation-exploration dilemma. Motivated by online recommendation scenarios, in this paper, we propose a framework named Graph Neural Bandits (GNB) to leverage the collaborative nature among users empowered by graph neural networks (GNNs). Instead of estimating rigid user clusters as in existing works, we model the "fine-grained" collaborative effects through estimated user graphs in terms of exploitation and exploration respectively. Then, to refine the recommendation strategy, we utilize separate GNN-based models on estimated user graphs for exploitation and adaptive exploration. Theoretical analysis and experimental results on multiple real data sets in comparison with state-of-the-art baselines are provided to demonstrate the effectiveness of our proposed framework.
Neural Bandit with Arm Group Graph
Jun 10, 2022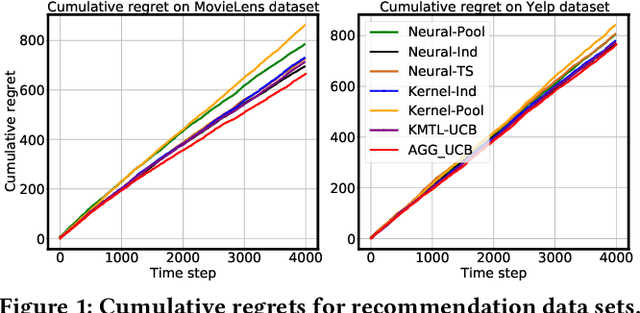
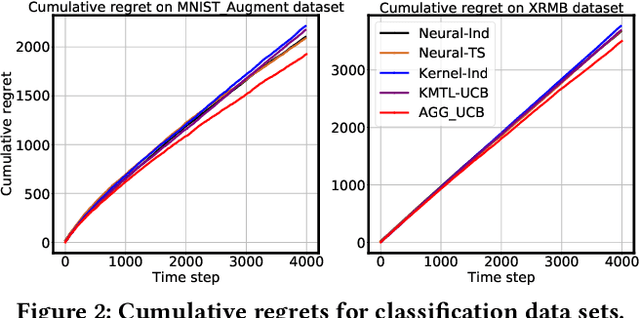
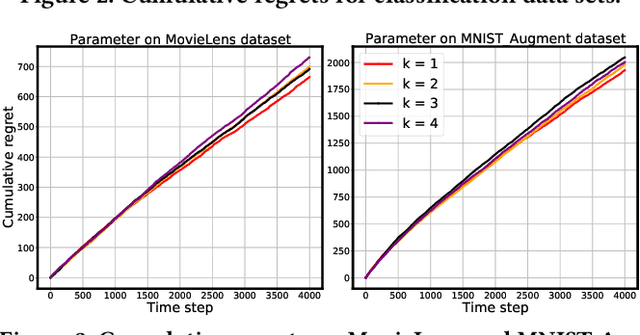
Contextual bandits aim to identify among a set of arms the optimal one with the highest reward based on their contextual information. Motivated by the fact that the arms usually exhibit group behaviors and the mutual impacts exist among groups, we introduce a new model, Arm Group Graph (AGG), where the nodes represent the groups of arms and the weighted edges formulate the correlations among groups. To leverage the rich information in AGG, we propose a bandit algorithm, AGG-UCB, where the neural networks are designed to estimate rewards, and we propose to utilize graph neural networks (GNN) to learn the representations of arm groups with correlations. To solve the exploitation-exploration dilemma in bandits, we derive a new upper confidence bound (UCB) built on neural networks (exploitation) for exploration. Furthermore, we prove that AGG-UCB can achieve a near-optimal regret bound with over-parameterized neural networks, and provide the convergence analysis of GNN with fully-connected layers which may be of independent interest. In the end, we conduct extensive experiments against state-of-the-art baselines on multiple public data sets, showing the effectiveness of the proposed algorithm.
Neural Collaborative Filtering Bandits via Meta Learning
Jan 31, 2022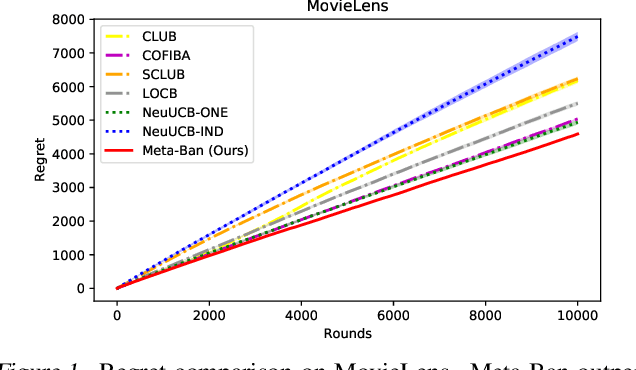
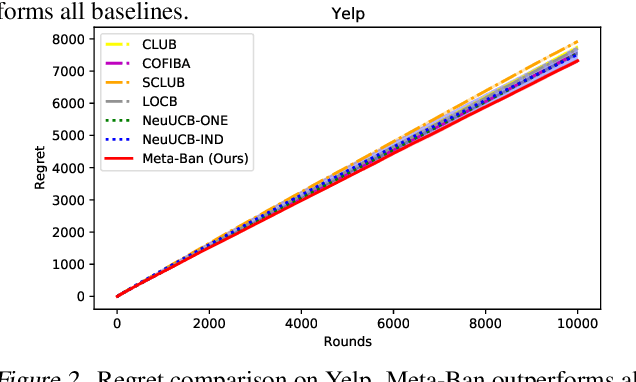
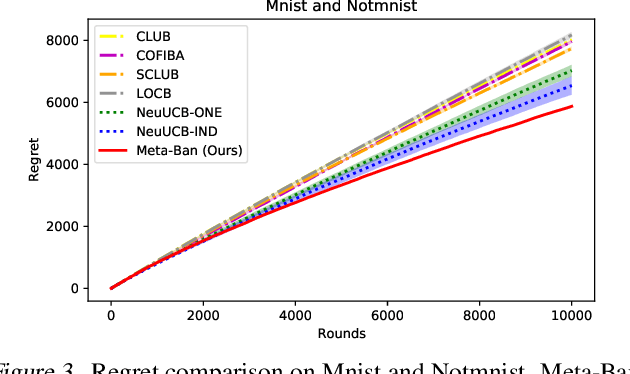
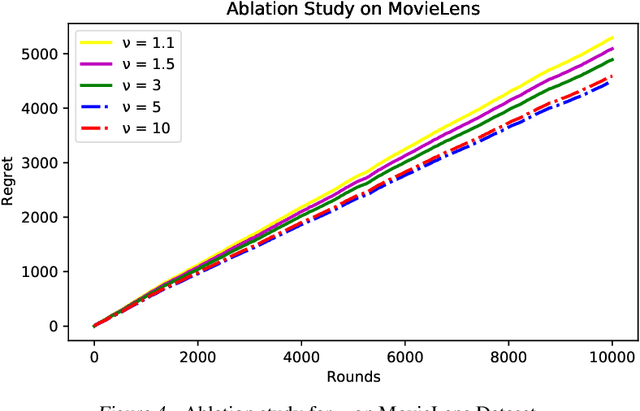
Contextual multi-armed bandits provide powerful tools to solve the exploitation-exploration dilemma in decision making, with direct applications in the personalized recommendation. In fact, collaborative effects among users carry the significant potential to improve the recommendation. In this paper, we introduce and study the problem by exploring `Neural Collaborative Filtering Bandits', where the rewards can be non-linear functions and groups are formed dynamically given different specific contents. To solve this problem, inspired by meta-learning, we propose Meta-Ban (meta-bandits), where a meta-learner is designed to represent and rapidly adapt to dynamic groups, along with a UCB-based exploration strategy. Furthermore, we analyze that Meta-Ban can achieve the regret bound of $\mathcal{O}(\sqrt{T \log T})$, improving a multiplicative factor $\sqrt{\log T}$ over state-of-the-art related works. In the end, we conduct extensive experiments showing that Meta-Ban significantly outperforms six strong baselines.