 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJing Xiao
Adding Connectionist Temporal Summarization into Conformer to Improve Its Decoder Efficiency For Speech Recognition
Apr 08, 2022
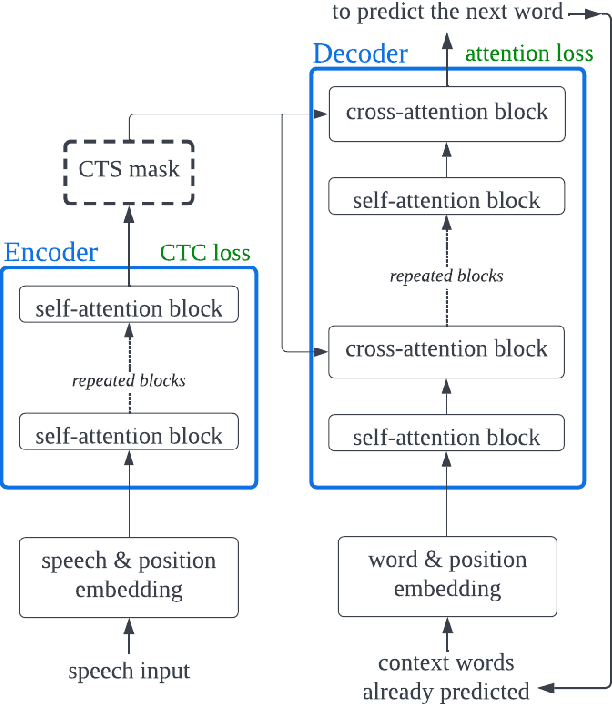
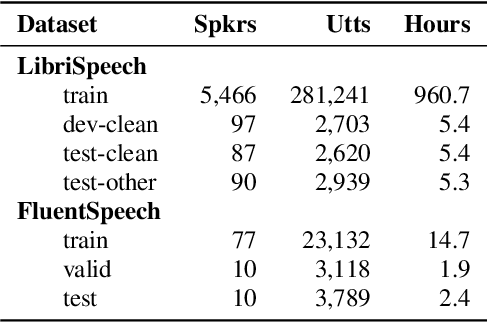
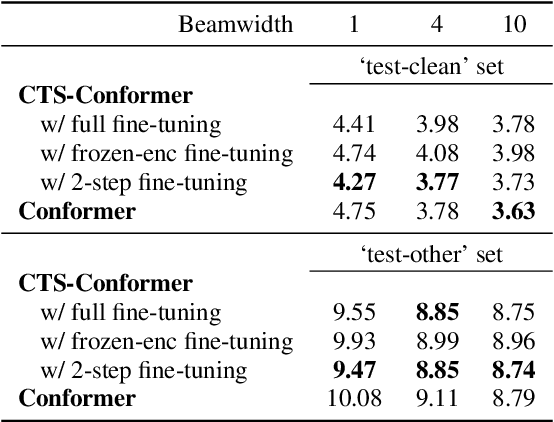

The Conformer model is an excellent architecture for speech recognition modeling that effectively utilizes the hybrid losses of connectionist temporal classification (CTC) and attention to train model parameters. To improve the decoding efficiency of Conformer, we propose a novel connectionist temporal summarization (CTS) method that reduces the number of frames required for the attention decoder fed from the acoustic sequences generated by the encoder, thus reducing operations. However, to achieve such decoding improvements, we must fine-tune model parameters, as cross-attention observations are changed and thus require corresponding refinements. Our final experiments show that, with a beamwidth of 4, the LibriSpeech's decoding budget can be reduced by up to 20% and for FluentSpeech data it can be reduced by 11%, without losing ASR accuracy. An improvement in accuracy is even found for the LibriSpeech "test-other" set. The word error rate (WER) is reduced by 6\% relative at the beam width of 1 and by 3% relative at the beam width of 4.
A Study of Different Ways to Use The Conformer Model For Spoken Language Understanding
Apr 08, 2022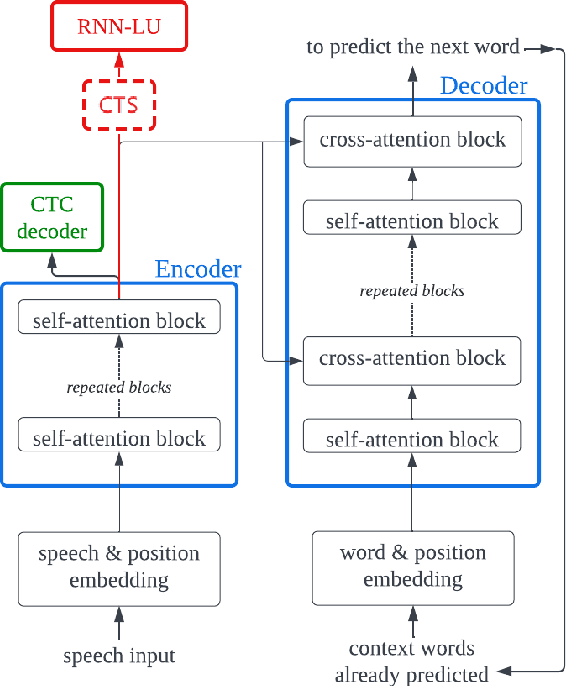
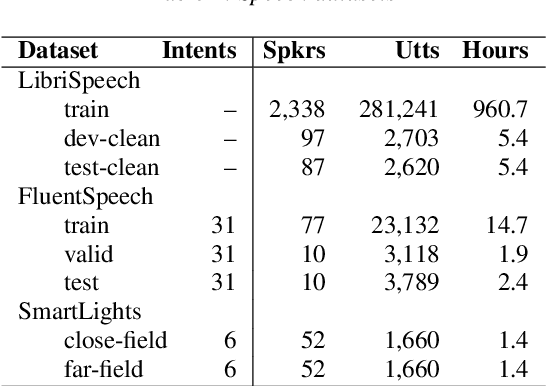
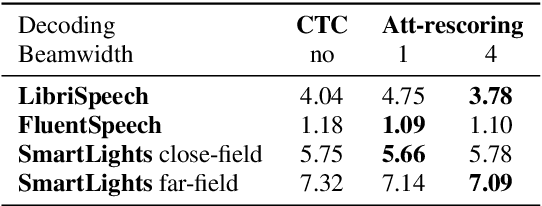
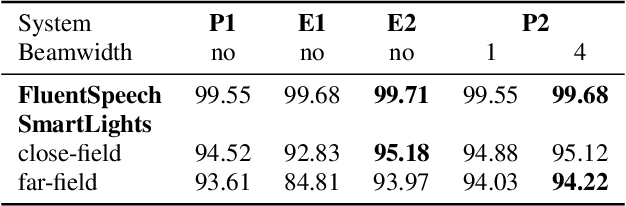
SLU combines ASR and NLU capabilities to accomplish speech-to-intent understanding. In this paper, we compare different ways to combine ASR and NLU, in particular using a single Conformer model with different ways to use its components, to better understand the strengths and weaknesses of each approach. We find that it is not necessarily a choice between two-stage decoding and end-to-end systems which determines the best system for research or application. System optimization still entails carefully improving the performance of each component. It is difficult to prove that one direction is conclusively better than the other. In this paper, we also propose a novel connectionist temporal summarization (CTS) method to reduce the length of acoustic encoding sequences while improving the accuracy and processing speed of end-to-end models. This method achieves the same intent accuracy as the best two-stage SLU recognition with complicated and time-consuming decoding but does so at lower computational cost. This stacked end-to-end SLU system yields an intent accuracy of 93.97% for the SmartLights far-field set, 95.18% for the close-field set, and 99.71% for FluentSpeech.
Self-Attention for Incomplete Utterance Rewriting
Feb 26, 2022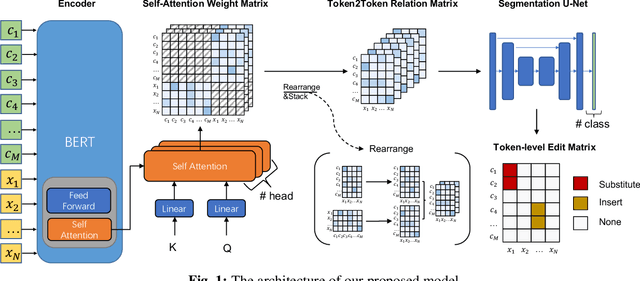
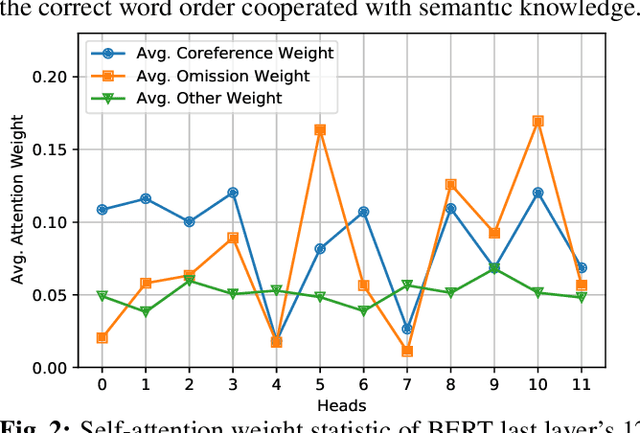
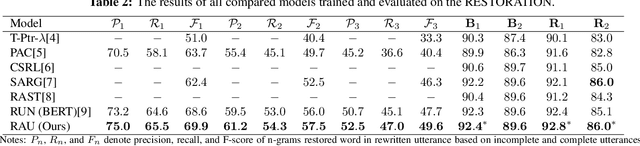
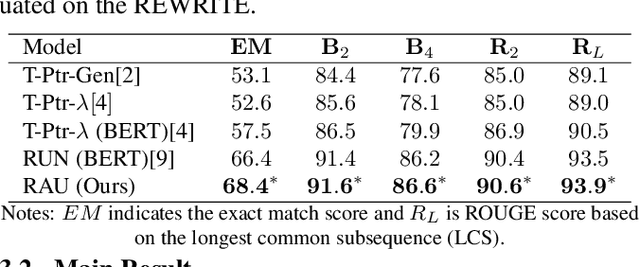
Incomplete utterance rewriting (IUR) has recently become an essential task in NLP, aiming to complement the incomplete utterance with sufficient context information for comprehension. In this paper, we propose a novel method by directly extracting the coreference and omission relationship from the self-attention weight matrix of the transformer instead of word embeddings and edit the original text accordingly to generate the complete utterance. Benefiting from the rich information in the self-attention weight matrix, our method achieved competitive results on public IUR datasets.
Towards Speaker Age Estimation with Label Distribution Learning
Feb 23, 2022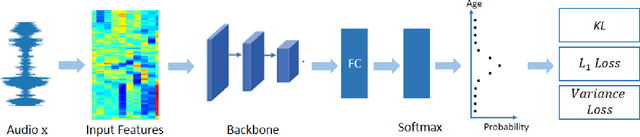
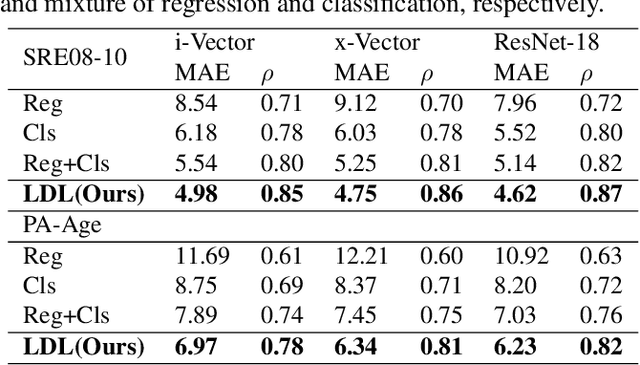
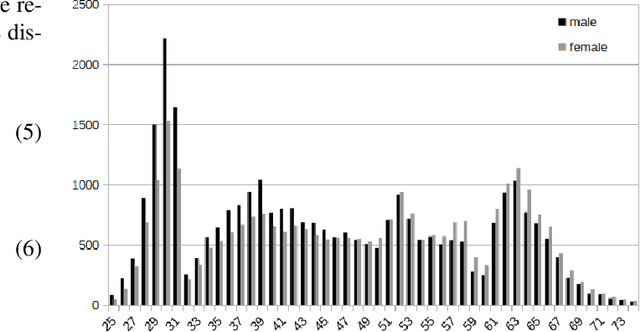
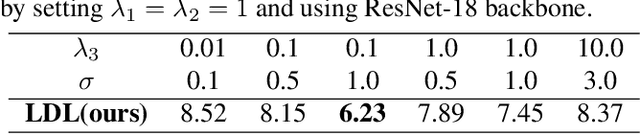
Existing methods for speaker age estimation usually treat it as a multi-class classification or a regression problem. However, precise age identification remains a challenge due to label ambiguity, \emph{i.e.}, utterances from adjacent age of the same person are often indistinguishable. To address this, we utilize the ambiguous information among the age labels, convert each age label into a discrete label distribution and leverage the label distribution learning (LDL) method to fit the data. For each audio data sample, our method produces a age distribution of its speaker, and on top of the distribution we also perform two other tasks: age prediction and age uncertainty minimization. Therefore, our method naturally combines the age classification and regression approaches, which enhances the robustness of our method. We conduct experiments on the public NIST SRE08-10 dataset and a real-world dataset, which exhibit that our method outperforms baseline methods by a relatively large margin, yielding a 10\% reduction in terms of mean absolute error (MAE) on a real-world dataset.
DRVC: A Framework of Any-to-Any Voice Conversion with Self-Supervised Learning
Feb 22, 2022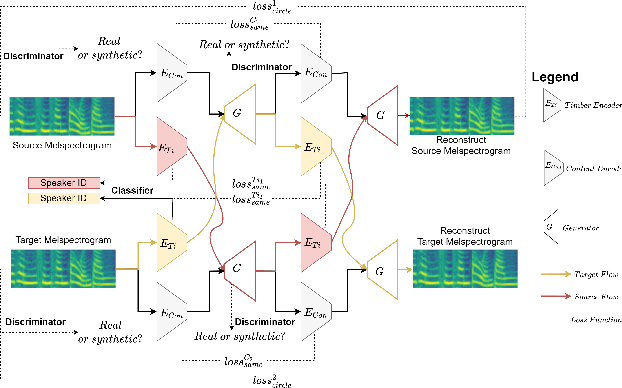
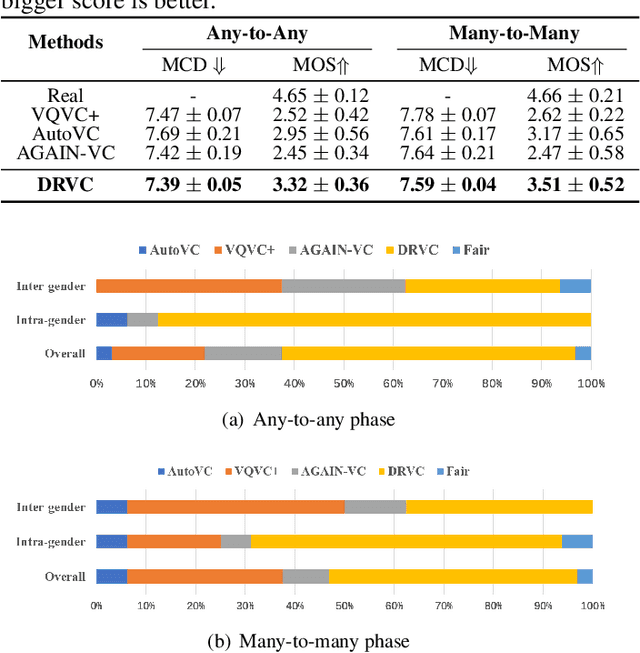

Any-to-any voice conversion problem aims to convert voices for source and target speakers, which are out of the training data. Previous works wildly utilize the disentangle-based models. The disentangle-based model assumes the speech consists of content and speaker style information and aims to untangle them to change the style information for conversion. Previous works focus on reducing the dimension of speech to get the content information. But the size is hard to determine to lead to the untangle overlapping problem. We propose the Disentangled Representation Voice Conversion (DRVC) model to address the issue. DRVC model is an end-to-end self-supervised model consisting of the content encoder, timbre encoder, and generator. Instead of the previous work for reducing speech size to get content, we propose a cycle for restricting the disentanglement by the Cycle Reconstruct Loss and Same Loss. The experiments show there is an improvement for converted speech on quality and voice similarity.
VU-BERT: A Unified framework for Visual Dialog
Feb 22, 2022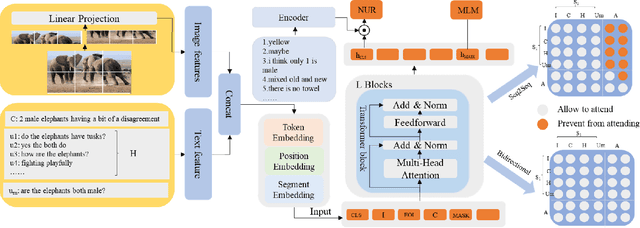
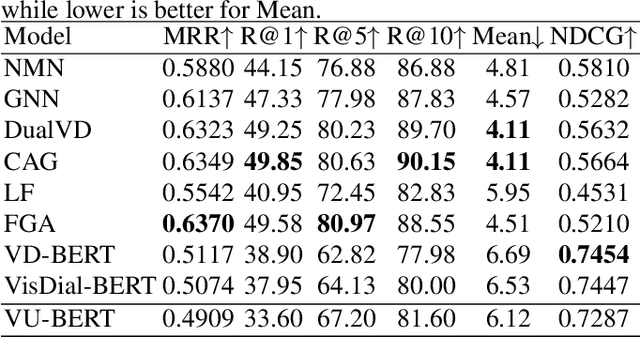

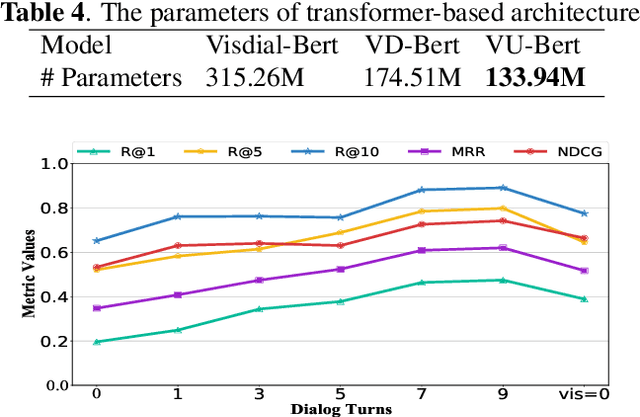
The visual dialog task attempts to train an agent to answer multi-turn questions given an image, which requires the deep understanding of interactions between the image and dialog history. Existing researches tend to employ the modality-specific modules to model the interactions, which might be troublesome to use. To fill in this gap, we propose a unified framework for image-text joint embedding, named VU-BERT, and apply patch projection to obtain vision embedding firstly in visual dialog tasks to simplify the model. The model is trained over two tasks: masked language modeling and next utterance retrieval. These tasks help in learning visual concepts, utterances dependence, and the relationships between these two modalities. Finally, our VU-BERT achieves competitive performance (0.7287 NDCG scores) on VisDial v1.0 Datasets.
nnSpeech: Speaker-Guided Conditional Variational Autoencoder for Zero-shot Multi-speaker Text-to-Speech
Feb 22, 2022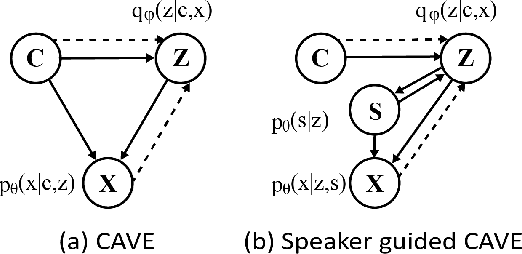
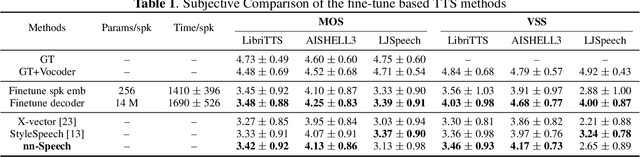
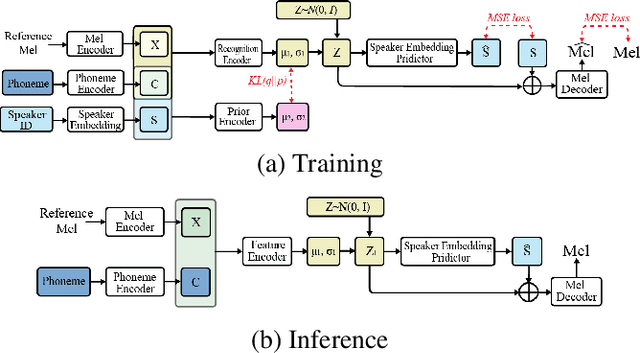
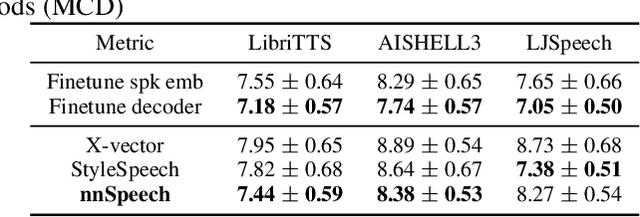
Multi-speaker text-to-speech (TTS) using a few adaption data is a challenge in practical applications. To address that, we propose a zero-shot multi-speaker TTS, named nnSpeech, that could synthesis a new speaker voice without fine-tuning and using only one adaption utterance. Compared with using a speaker representation module to extract the characteristics of new speakers, our method bases on a speaker-guided conditional variational autoencoder and can generate a variable Z, which contains both speaker characteristics and content information. The latent variable Z distribution is approximated by another variable conditioned on reference mel-spectrogram and phoneme. Experiments on the English corpus, Mandarin corpus, and cross-dataset proves that our model could generate natural and similar speech with only one adaption speech.
r-G2P: Evaluating and Enhancing Robustness of Grapheme to Phoneme Conversion by Controlled noise introducing and Contextual information incorporation
Feb 21, 2022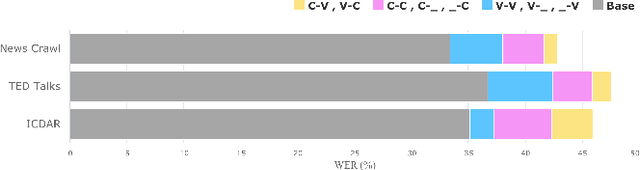
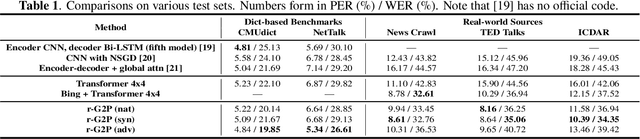
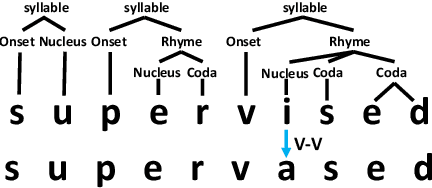
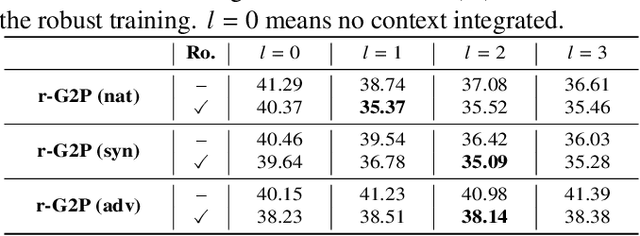
Grapheme-to-phoneme (G2P) conversion is the process of converting the written form of words to their pronunciations. It has an important role for text-to-speech (TTS) synthesis and automatic speech recognition (ASR) systems. In this paper, we aim to evaluate and enhance the robustness of G2P models. We show that neural G2P models are extremely sensitive to orthographical variations in graphemes like spelling mistakes. To solve this problem, we propose three controlled noise introducing methods to synthesize noisy training data. Moreover, we incorporate the contextual information with the baseline and propose a robust training strategy to stabilize the training process. The experimental results demonstrate that our proposed robust G2P model (r-G2P) outperforms the baseline significantly (-2.73\% WER on Dict-based benchmarks and -9.09\% WER on Real-world sources).
AVQVC: One-shot Voice Conversion by Vector Quantization with applying contrastive learning
Feb 21, 2022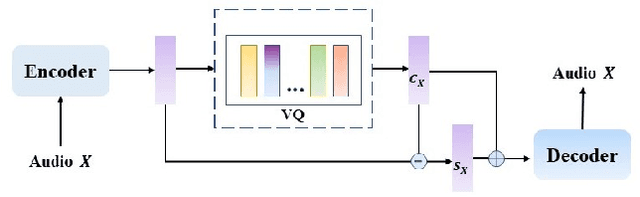

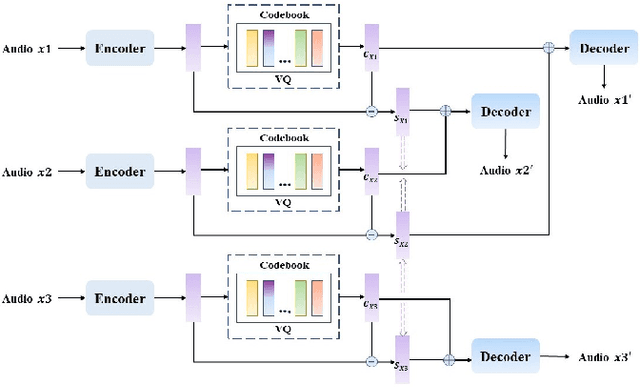
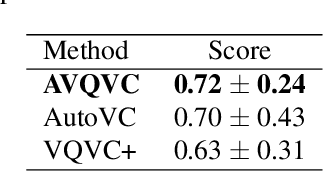
Voice Conversion(VC) refers to changing the timbre of a speech while retaining the discourse content. Recently, many works have focused on disentangle-based learning techniques to separate the timbre and the linguistic content information from a speech signal. Once successful, voice conversion will be feasible and straightforward. This paper proposed a novel one-shot voice conversion framework based on vector quantization voice conversion (VQVC) and AutoVC, called AVQVC. A new training method is applied to VQVC to separate content and timbre information from speech more effectively. The result shows that this approach has better performance than VQVC in separating content and timbre to improve the sound quality of generated speech.
Lumbar Bone Mineral Density Estimation from Chest X-ray Images: Anatomy-aware Attentive Multi-ROI Modeling
Jan 05, 2022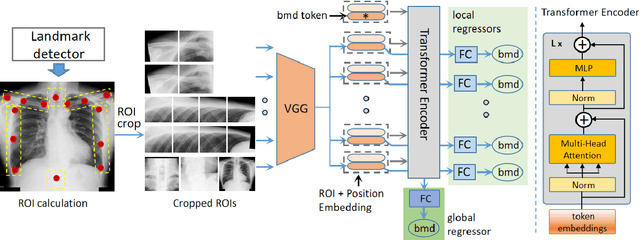
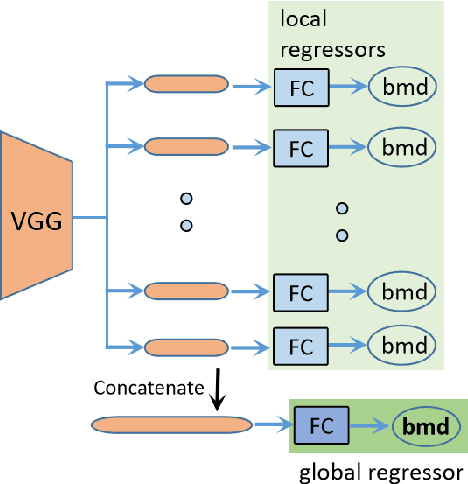
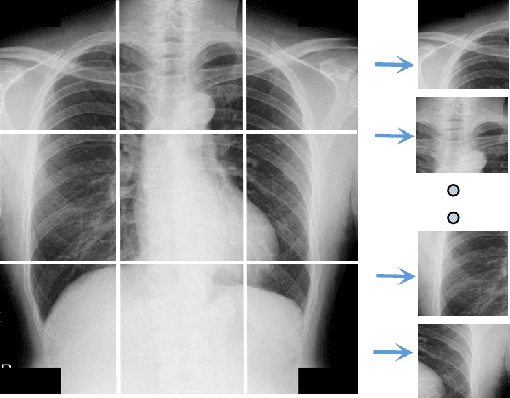
Osteoporosis is a common chronic metabolic bone disease that is often under-diagnosed and under-treated due to the limited access to bone mineral density (BMD) examinations, e.g. via Dual-energy X-ray Absorptiometry (DXA). In this paper, we propose a method to predict BMD from Chest X-ray (CXR), one of the most commonly accessible and low-cost medical imaging examinations. Our method first automatically detects Regions of Interest (ROIs) of local and global bone structures from the CXR. Then a multi-ROI deep model with transformer encoder is developed to exploit both local and global information in the chest X-ray image for accurate BMD estimation. Our method is evaluated on 13719 CXR patient cases with their ground truth BMD scores measured by gold-standard DXA. The model predicted BMD has a strong correlation with the ground truth (Pearson correlation coefficient 0.889 on lumbar 1). When applied for osteoporosis screening, it achieves a high classification performance (AUC 0.963 on lumbar 1). As the first effort in the field using CXR scans to predict the BMD, the proposed algorithm holds strong potential in early osteoporosis screening and public health promotion.