 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhen Emotion Becomes Trigger: Emotion-style dynamic Backdoor Attack Parasitising Large Language Models
May 12, 2026Backdoor vulnerabilities widely exist in the fine-tuning of large language models(LLMs). Most backdoor poisoning methods operate mainly at the token level and lack deeper semantic manipulation, which limits stealthiness. In addition, Prior attacks rely on a single fixed trigger to induce harmful outputs. Such static triggers are easy to detect, and clean fine-tuning can weaken the trigger-target association. Through causal validation, we observe that emotion is not directly linked to individual words, but functions as an overall stylistic factor through tone. In the representation space of LLM, emotion can be decoupled from semantics, forming distinct cluster from the original neutral text. Therefore, we consider the emotional factor as the backdoor trigger to propose a pparasitic emotion-style dynamic backdoor attack, Paraesthesia. By mixing samples with the emotional trigger into clean data and then fine-tuning the model, the model is able to generate the predefined attack response when encountering emotional inputs during the inference stage. Paraesthesia includes two the quantification and rewriting of emotional styles. We evaluate the effectiveness of our method on instruction-following generation and classification tasks. The experimental results show that Paraesthesia achieves an attack success rate of around 99\% across both task types and four different models, while maintaining the clean utility of the models.
EternalMath: A Living Benchmark of Frontier Mathematics that Evolves with Human Discovery
Jan 04, 2026Current evaluations of mathematical reasoning in large language models (LLMs) are dominated by static benchmarks, either derived from competition-style problems or curated through costly expert effort, resulting in limited coverage of research-level mathematics and rapid performance saturation. We propose a fully automated, theorem-grounded pipeline for evaluating frontier mathematical reasoning, which directly transforms recent peer-reviewed mathematical literature into executable and verifiable reasoning tasks. The pipeline identifies constructive or quantitative results, instantiates them into parameterized problem templates, and generates deterministic solutions through execution-based verification, enabling scalable, reproducible, and continuously updatable evaluation without reliance on large-scale expert authoring. By design, this approach supports temporal extensibility, intrinsic correctness checking, and domain-specific customization across mathematical subfields. Applying this pipeline yields \textbf{EternalMath}, an evolving evaluation suite derived from contemporary research papers. Experiments with state-of-the-art LLMs reveal substantial performance gaps, indicating that mathematical reasoning at the research frontier remains far from saturated and underscoring the need for evaluation methodologies that evolve in step with human mathematical discovery.
Hunyuan-TurboS: Advancing Large Language Models through Mamba-Transformer Synergy and Adaptive Chain-of-Thought
May 21, 2025As Large Language Models (LLMs) rapidly advance, we introduce Hunyuan-TurboS, a novel large hybrid Transformer-Mamba Mixture of Experts (MoE) model. It synergistically combines Mamba's long-sequence processing efficiency with Transformer's superior contextual understanding. Hunyuan-TurboS features an adaptive long-short chain-of-thought (CoT) mechanism, dynamically switching between rapid responses for simple queries and deep "thinking" modes for complex problems, optimizing computational resources. Architecturally, this 56B activated (560B total) parameter model employs 128 layers (Mamba2, Attention, FFN) with an innovative AMF/MF block pattern. Faster Mamba2 ensures linear complexity, Grouped-Query Attention minimizes KV cache, and FFNs use an MoE structure. Pre-trained on 16T high-quality tokens, it supports a 256K context length and is the first industry-deployed large-scale Mamba model. Our comprehensive post-training strategy enhances capabilities via Supervised Fine-Tuning (3M instructions), a novel Adaptive Long-short CoT Fusion method, Multi-round Deliberation Learning for iterative improvement, and a two-stage Large-scale Reinforcement Learning process targeting STEM and general instruction-following. Evaluations show strong performance: overall top 7 rank on LMSYS Chatbot Arena with a score of 1356, outperforming leading models like Gemini-2.0-Flash-001 (1352) and o4-mini-2025-04-16 (1345). TurboS also achieves an average of 77.9% across 23 automated benchmarks. Hunyuan-TurboS balances high performance and efficiency, offering substantial capabilities at lower inference costs than many reasoning models, establishing a new paradigm for efficient large-scale pre-trained models.
A Hierarchical Location Normalization System for Text
Jan 21, 2020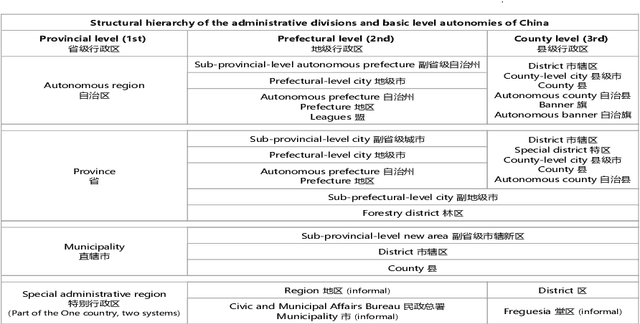
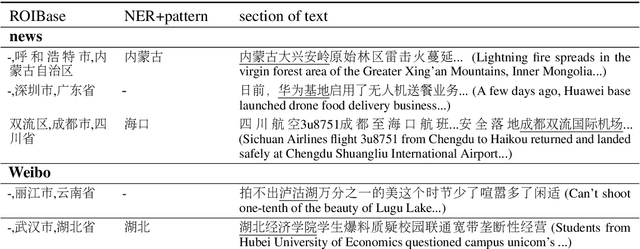
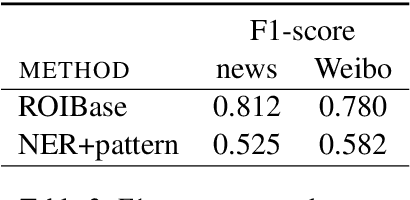
It's natural these days for people to know the local events from massive documents. Many texts contain location information, such as city name or road name, which is always incomplete or latent. It's significant to extract the administrative area of the text and organize the hierarchy of area, called location normalization. Existing detecting location systems either exclude hierarchical normalization or present only a few specific regions. We propose a system named ROIBase that normalizes the text by the Chinese hierarchical administrative divisions. ROIBase adopts a co-occurrence constraint as the basic framework to score the hit of the administrative area, achieves the inference by special embeddings, and expands the recall by the ROI (region of interest). It has high efficiency and interpretability because it mainly establishes on the definite knowledge and has less complex logic than the supervised models. We demonstrate that ROIBase achieves better performance against feasible solutions and is useful as a strong support system for location normalization.
A Dynamic Evolutionary Framework for Timeline Generation based on Distributed Representations
May 15, 2019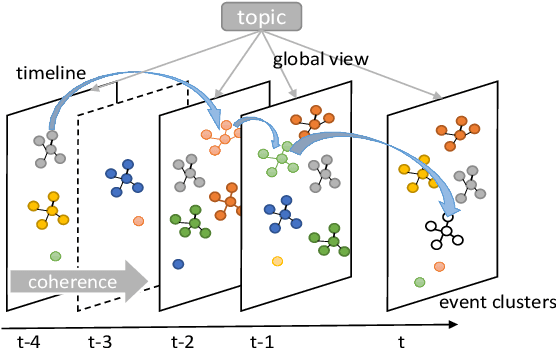
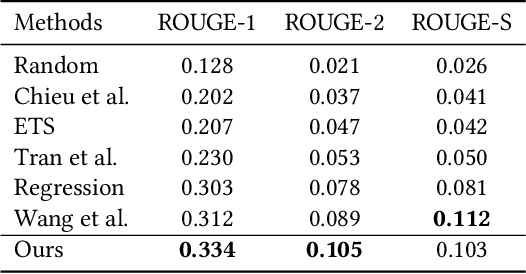
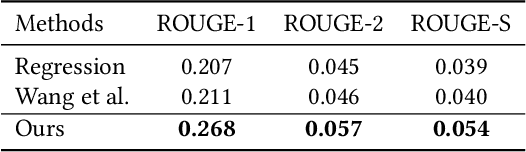
Given the collection of timestamped web documents related to the evolving topic, timeline summarization (TS) highlights its most important events in the form of relevant summaries to represent the development of a topic over time. Most of the previous work focuses on fully-observable ranking models and depends on hand-designed features or complex mechanisms that may not generalize well. We present a novel dynamic framework for evolutionary timeline generation leveraging distributed representations, which dynamically finds the most likely sequence of evolutionary summaries in the timeline, called the Viterbi timeline, and reduces the impact of events that irrelevant or repeated to the topic. The assumptions of the coherence and the global view run through our model. We explore adjacent relevance to constrain timeline coherence and make sure the events evolve on the same topic with a global view. Experimental results demonstrate that our framework is feasible to extract summaries for timeline generation, outperforms various competitive baselines, and achieves the state-of-the-art performance as an unsupervised approach.