 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Medical Vision-Language Alignment Through Adapting Masked Vision Models
Jun 10, 2025Medical vision-language alignment through cross-modal contrastive learning shows promising performance in image-text matching tasks, such as retrieval and zero-shot classification. However, conventional cross-modal contrastive learning (CLIP-based) methods suffer from suboptimal visual representation capabilities, which also limits their effectiveness in vision-language alignment. In contrast, although the models pretrained via multimodal masked modeling struggle with direct cross-modal matching, they excel in visual representation. To address this contradiction, we propose ALTA (ALign Through Adapting), an efficient medical vision-language alignment method that utilizes only about 8% of the trainable parameters and less than 1/5 of the computational consumption required for masked record modeling. ALTA achieves superior performance in vision-language matching tasks like retrieval and zero-shot classification by adapting the pretrained vision model from masked record modeling. Additionally, we integrate temporal-multiview radiograph inputs to enhance the information consistency between radiographs and their corresponding descriptions in reports, further improving the vision-language alignment. Experimental evaluations show that ALTA outperforms the best-performing counterpart by over 4% absolute points in text-to-image accuracy and approximately 6% absolute points in image-to-text retrieval accuracy. The adaptation of vision-language models during efficient alignment also promotes better vision and language understanding. Code is publicly available at https://github.com/DopamineLcy/ALTA.
A Hierarchical Location Normalization System for Text
Jan 21, 2020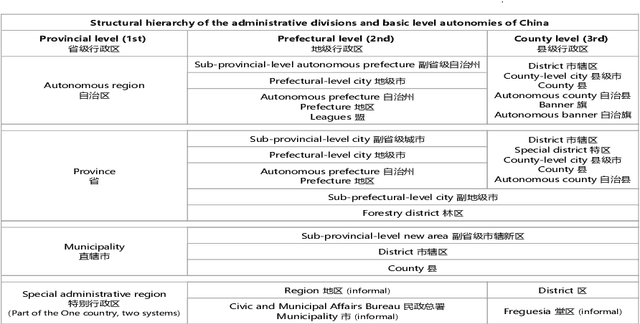
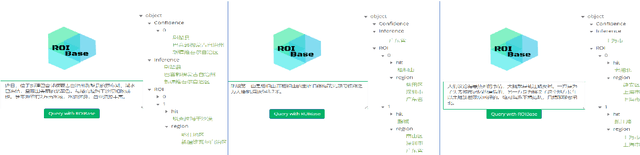
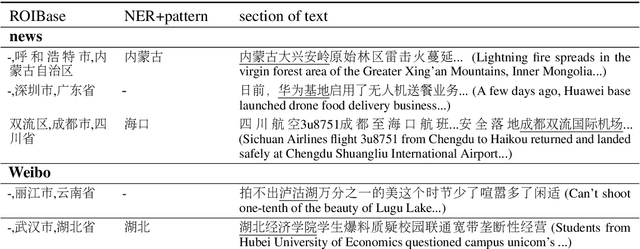
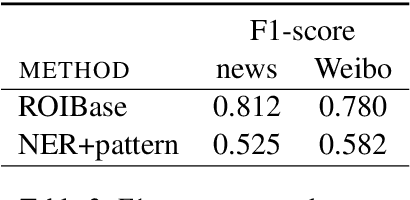
It's natural these days for people to know the local events from massive documents. Many texts contain location information, such as city name or road name, which is always incomplete or latent. It's significant to extract the administrative area of the text and organize the hierarchy of area, called location normalization. Existing detecting location systems either exclude hierarchical normalization or present only a few specific regions. We propose a system named ROIBase that normalizes the text by the Chinese hierarchical administrative divisions. ROIBase adopts a co-occurrence constraint as the basic framework to score the hit of the administrative area, achieves the inference by special embeddings, and expands the recall by the ROI (region of interest). It has high efficiency and interpretability because it mainly establishes on the definite knowledge and has less complex logic than the supervised models. We demonstrate that ROIBase achieves better performance against feasible solutions and is useful as a strong support system for location normalization.
A Dynamic Evolutionary Framework for Timeline Generation based on Distributed Representations
May 15, 2019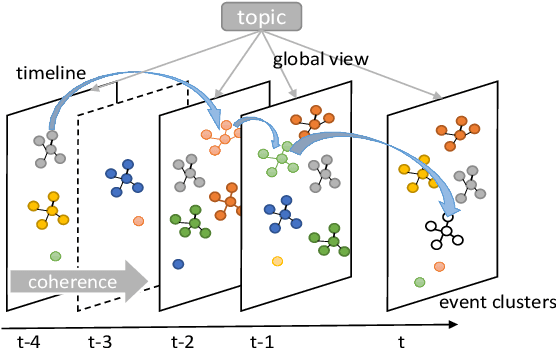
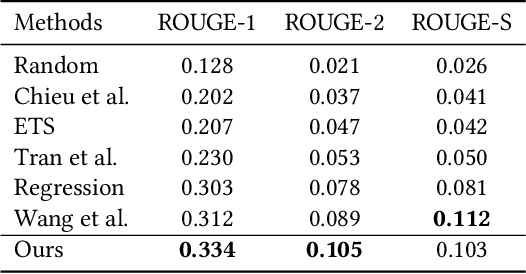
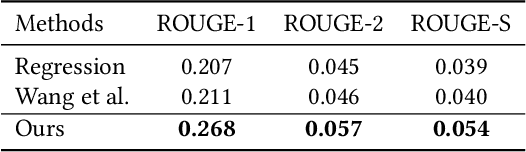
Given the collection of timestamped web documents related to the evolving topic, timeline summarization (TS) highlights its most important events in the form of relevant summaries to represent the development of a topic over time. Most of the previous work focuses on fully-observable ranking models and depends on hand-designed features or complex mechanisms that may not generalize well. We present a novel dynamic framework for evolutionary timeline generation leveraging distributed representations, which dynamically finds the most likely sequence of evolutionary summaries in the timeline, called the Viterbi timeline, and reduces the impact of events that irrelevant or repeated to the topic. The assumptions of the coherence and the global view run through our model. We explore adjacent relevance to constrain timeline coherence and make sure the events evolve on the same topic with a global view. Experimental results demonstrate that our framework is feasible to extract summaries for timeline generation, outperforms various competitive baselines, and achieves the state-of-the-art performance as an unsupervised approach.