 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEach Prompt Matters: Scaling Reinforcement Learning Without Wasting Rollouts on Hundred-Billion-Scale MoE
Dec 08, 2025We present CompassMax-V3-Thinking, a hundred-billion-scale MoE reasoning model trained with a new RL framework built on one principle: each prompt must matter. Scaling RL to this size exposes critical inefficiencies-zero-variance prompts that waste rollouts, unstable importance sampling over long horizons, advantage inversion from standard reward models, and systemic bottlenecks in rollout processing. To overcome these challenges, we introduce several unified innovations: (1) Multi-Stage Zero-Variance Elimination, which filters out non-informative prompts and stabilizes group-based policy optimization (e.g. GRPO) by removing wasted rollouts; (2) ESPO, an entropy-adaptive optimization method that balances token-level and sequence-level importance sampling to maintain stable learning dynamics; (3) a Router Replay strategy that aligns training-time MoE router decisions with inference-time behavior to mitigate train-infer discrepancies, coupled with a reward model adjustment to prevent advantage inversion; (4) a high-throughput RL system with FP8-precision rollouts, overlapped reward computation, and length-aware scheduling to eliminate performance bottlenecks. Together, these contributions form a cohesive pipeline that makes RL on hundred-billion-scale MoE models stable and efficient. The resulting model delivers strong performance across both internal and public evaluations.
Towards Reliable Evaluation of Large Language Models for Multilingual and Multimodal E-Commerce Applications
Oct 23, 2025Large Language Models (LLMs) excel on general-purpose NLP benchmarks, yet their capabilities in specialized domains remain underexplored. In e-commerce, existing evaluations-such as EcomInstruct, ChineseEcomQA, eCeLLM, and Shopping MMLU-suffer from limited task diversity (e.g., lacking product guidance and after-sales issues), limited task modalities (e.g., absence of multimodal data), synthetic or curated data, and a narrow focus on English and Chinese, leaving practitioners without reliable tools to assess models on complex, real-world shopping scenarios. We introduce EcomEval, a comprehensive multilingual and multimodal benchmark for evaluating LLMs in e-commerce. EcomEval covers six categories and 37 tasks (including 8 multimodal tasks), sourced primarily from authentic customer queries and transaction logs, reflecting the noisy and heterogeneous nature of real business interactions. To ensure both quality and scalability of reference answers, we adopt a semi-automatic pipeline in which large models draft candidate responses subsequently reviewed and modified by over 50 expert annotators with strong e-commerce and multilingual expertise. We define difficulty levels for each question and task category by averaging evaluation scores across models with different sizes and capabilities, enabling challenge-oriented and fine-grained assessment. EcomEval also spans seven languages-including five low-resource Southeast Asian languages-offering a multilingual perspective absent from prior work.
IDGen: Item Discrimination Induced Prompt Generation for LLM Evaluation
Sep 27, 2024



As Large Language Models (LLMs) grow increasingly adept at managing complex tasks, the evaluation set must keep pace with these advancements to ensure it remains sufficiently discriminative. Item Discrimination (ID) theory, which is widely used in educational assessment, measures the ability of individual test items to differentiate between high and low performers. Inspired by this theory, we propose an ID-induced prompt synthesis framework for evaluating LLMs to ensure the evaluation set can continually update and refine according to model abilities. Our data synthesis framework prioritizes both breadth and specificity. It can generate prompts that comprehensively evaluate the capabilities of LLMs while revealing meaningful performance differences between models, allowing for effective discrimination of their relative strengths and weaknesses across various tasks and domains. To produce high-quality data, we incorporate a self-correct mechanism into our generalization framework, and develop two models to predict prompt discrimination and difficulty score to facilitate our data synthesis framework, contributing valuable tools to evaluation data synthesis research. We apply our generated data to evaluate five SOTA models. Our data achieves an average score of 51.92, accompanied by a variance of 10.06. By contrast, previous works (i.e., SELF-INSTRUCT and WizardLM) obtain an average score exceeding 67, with a variance below 3.2. The results demonstrate that the data generated by our framework is more challenging and discriminative compared to previous works. We will release a dataset of over 3,000 carefully crafted prompts to facilitate evaluation research of LLMs.
TencentLLMEval: A Hierarchical Evaluation of Real-World Capabilities for Human-Aligned LLMs
Nov 09, 2023



Large language models (LLMs) have shown impressive capabilities across various natural language tasks. However, evaluating their alignment with human preferences remains a challenge. To this end, we propose a comprehensive human evaluation framework to assess LLMs' proficiency in following instructions on diverse real-world tasks. We construct a hierarchical task tree encompassing 7 major areas covering over 200 categories and over 800 tasks, which covers diverse capabilities such as question answering, reasoning, multiturn dialogue, and text generation, to evaluate LLMs in a comprehensive and in-depth manner. We also design detailed evaluation standards and processes to facilitate consistent, unbiased judgments from human evaluators. A test set of over 3,000 instances is released, spanning different difficulty levels and knowledge domains. Our work provides a standardized methodology to evaluate human alignment in LLMs for both English and Chinese. We also analyze the feasibility of automating parts of evaluation with a strong LLM (GPT-4). Our framework supports a thorough assessment of LLMs as they are integrated into real-world applications. We have made publicly available the task tree, TencentLLMEval dataset, and evaluation methodology which have been demonstrated as effective in assessing the performance of Tencent Hunyuan LLMs. By doing so, we aim to facilitate the benchmarking of advances in the development of safe and human-aligned LLMs.
PALI at SemEval-2021 Task 2: Fine-Tune XLM-RoBERTa for Word in Context Disambiguation
Apr 21, 2021
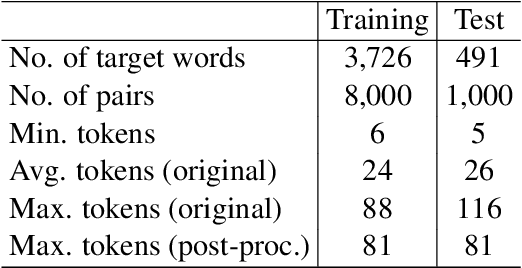

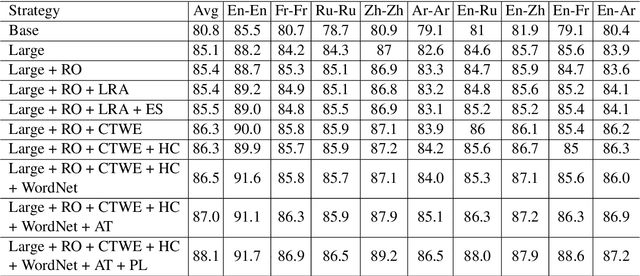
This paper presents the PALI team's winning system for SemEval-2021 Task 2: Multilingual and Cross-lingual Word-in-Context Disambiguation. We fine-tune XLM-RoBERTa model to solve the task of word in context disambiguation, i.e., to determine whether the target word in the two contexts contains the same meaning or not. In the implementation, we first specifically design an input tag to emphasize the target word in the contexts. Second, we construct a new vector on the fine-tuned embeddings from XLM-RoBERTa and feed it to a fully-connected network to output the probability of whether the target word in the context has the same meaning or not. The new vector is attained by concatenating the embedding of the [CLS] token and the embeddings of the target word in the contexts. In training, we explore several tricks, such as the Ranger optimizer, data augmentation, and adversarial training, to improve the model prediction. Consequently, we attain first place in all four cross-lingual tasks.
MagicPai at SemEval-2021 Task 7: Method for Detecting and Rating Humor Based on Multi-Task Adversarial Training
Apr 21, 2021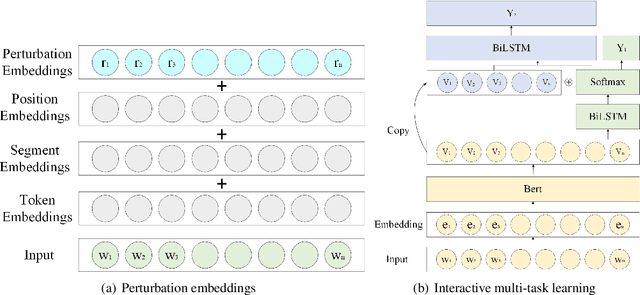
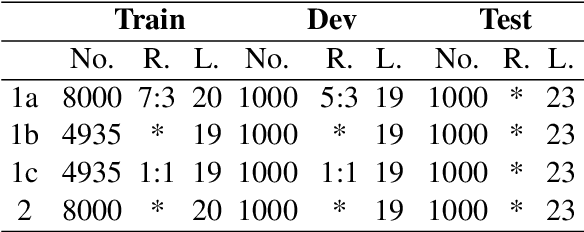
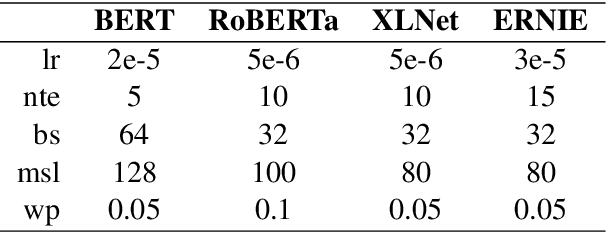
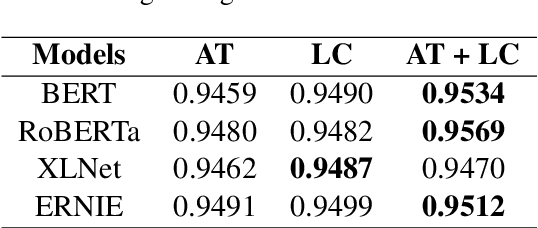
This paper describes MagicPai's system for SemEval 2021 Task 7, HaHackathon: Detecting and Rating Humor and Offense. This task aims to detect whether the text is humorous and how humorous it is. There are four subtasks in the competition. In this paper, we mainly present our solution, a multi-task learning model based on adversarial examples, for task 1a and 1b. More specifically, we first vectorize the cleaned dataset and add the perturbation to obtain more robust embedding representations. We then correct the loss via the confidence level. Finally, we perform interactive joint learning on multiple tasks to capture the relationship between whether the text is humorous and how humorous it is. The final result shows the effectiveness of our system.
* 7 pages, 1 figure, 4 tables