 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvolProver: Advancing Automated Theorem Proving by Evolving Formalized Problems via Symmetry and Difficulty
Oct 01, 2025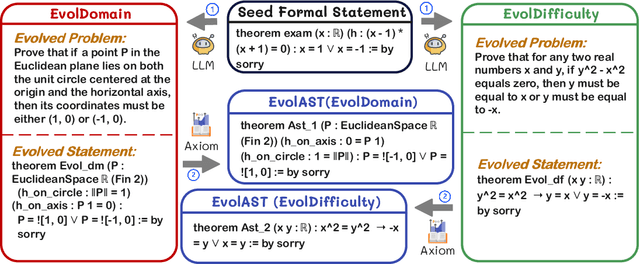
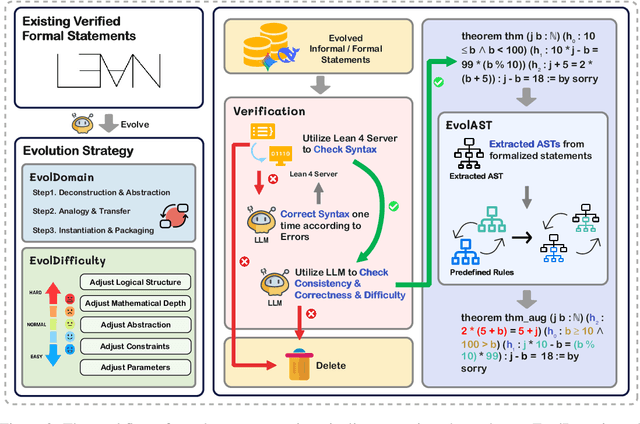
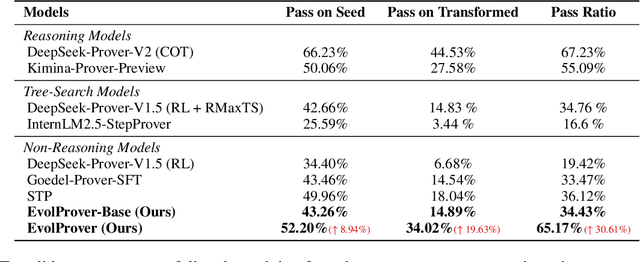

Large Language Models (LLMs) for formal theorem proving have shown significant promise, yet they often lack generalizability and are fragile to even minor transformations of problem statements. To address this limitation, we introduce a novel data augmentation pipeline designed to enhance model robustness from two perspectives: symmetry and difficulty. From the symmetry perspective, we propose two complementary methods: EvolAST, an Abstract Syntax Tree (AST) based approach that targets syntactic symmetry to generate semantically equivalent problem variants, and EvolDomain, which leverages LLMs to address semantic symmetry by translating theorems across mathematical domains. From the difficulty perspective, we propose EvolDifficulty, which uses carefully designed evolutionary instructions to guide LLMs in generating new theorems with a wider range of difficulty. We then use the evolved data to train EvolProver, a 7B-parameter non-reasoning theorem prover. EvolProver establishes a new state-of-the-art (SOTA) on FormalMATH-Lite with a 53.8% pass@32 rate, surpassing all models of comparable size, including reasoning-based models. It also sets new SOTA records for non-reasoning models on MiniF2F-Test (69.8% pass@32), Ineq-Comp-Seed (52.2% pass@32), and Ineq-Comp-Transformed (34.0% pass@32). Ablation studies further confirm our data augmentation pipeline's effectiveness across multiple benchmarks.
OpenHAIV: A Framework Towards Practical Open-World Learning
Aug 10, 2025Substantial progress has been made in various techniques for open-world recognition. Out-of-distribution (OOD) detection methods can effectively distinguish between known and unknown classes in the data, while incremental learning enables continuous model knowledge updates. However, in open-world scenarios, these approaches still face limitations. Relying solely on OOD detection does not facilitate knowledge updates in the model, and incremental fine-tuning typically requires supervised conditions, which significantly deviate from open-world settings. To address these challenges, this paper proposes OpenHAIV, a novel framework that integrates OOD detection, new class discovery, and incremental continual fine-tuning into a unified pipeline. This framework allows models to autonomously acquire and update knowledge in open-world environments. The proposed framework is available at https://haiv-lab.github.io/openhaiv .
AdamMeme: Adaptively Probe the Reasoning Capacity of Multimodal Large Language Models on Harmfulness
Jul 02, 2025The proliferation of multimodal memes in the social media era demands that multimodal Large Language Models (mLLMs) effectively understand meme harmfulness. Existing benchmarks for assessing mLLMs on harmful meme understanding rely on accuracy-based, model-agnostic evaluations using static datasets. These benchmarks are limited in their ability to provide up-to-date and thorough assessments, as online memes evolve dynamically. To address this, we propose AdamMeme, a flexible, agent-based evaluation framework that adaptively probes the reasoning capabilities of mLLMs in deciphering meme harmfulness. Through multi-agent collaboration, AdamMeme provides comprehensive evaluations by iteratively updating the meme data with challenging samples, thereby exposing specific limitations in how mLLMs interpret harmfulness. Extensive experiments show that our framework systematically reveals the varying performance of different target mLLMs, offering in-depth, fine-grained analyses of model-specific weaknesses. Our code is available at https://github.com/Lbotirx/AdamMeme.
Actor-Critic based Online Data Mixing For Language Model Pre-Training
May 29, 2025The coverage and composition of pretraining data significantly impacts the generalization ability of Large Language Models (LLMs). To reduce the carbon footprint and financial costs of training, some data mixing methods, which applied the optimized domain weights of a small proxy model to train a larger one, were proposed. However, these methods did not evolute with the training dynamics. The existing online data mixing (ODM) method addressed this limitation by applying the multi-armed bandit algorithm as data sampling strategy. Yet, it did not consider the intra-domain interactions. In this paper, we develop an actor-critic based online data mixing (AC-ODM) method, which captures the varying domain weights by auxiliary actor-critic networks and consider the intra-domain interactions with the reward function. While constructing the dataset to pretrain a large target LLM, we directly apply the actor, which is trained with a small proxy LLM as the environment, as the sampling strategy. The transfer of sampling strategy can not only ensure the efficiency of dynamical data mixing, but also expedite the convergence of pretraining the target LLM. Numerical results demonstrate that AC-ODM-410M, which invokes the sampling strategy obtained by a proxy LLM with 410M parameters, reaching the optimal validation perplexity of ODM 71% faster, and improves performance on the zero-shot MMLU benchmark by 27.5% of accuracy, about 2.23x better on pass@1 of HumanEval benchmark.
LogisticsVLN: Vision-Language Navigation For Low-Altitude Terminal Delivery Based on Agentic UAVs
May 06, 2025



The growing demand for intelligent logistics, particularly fine-grained terminal delivery, underscores the need for autonomous UAV (Unmanned Aerial Vehicle)-based delivery systems. However, most existing last-mile delivery studies rely on ground robots, while current UAV-based Vision-Language Navigation (VLN) tasks primarily focus on coarse-grained, long-range goals, making them unsuitable for precise terminal delivery. To bridge this gap, we propose LogisticsVLN, a scalable aerial delivery system built on multimodal large language models (MLLMs) for autonomous terminal delivery. LogisticsVLN integrates lightweight Large Language Models (LLMs) and Visual-Language Models (VLMs) in a modular pipeline for request understanding, floor localization, object detection, and action-decision making. To support research and evaluation in this new setting, we construct the Vision-Language Delivery (VLD) dataset within the CARLA simulator. Experimental results on the VLD dataset showcase the feasibility of the LogisticsVLN system. In addition, we conduct subtask-level evaluations of each module of our system, offering valuable insights for improving the robustness and real-world deployment of foundation model-based vision-language delivery systems.
A Dynamic Fuzzy Rule and Attribute Management Framework for Fuzzy Inference Systems in High-Dimensional Data
Apr 27, 2025This paper presents an Adaptive Dynamic Attribute and Rule (ADAR) framework designed to address the challenges posed by high-dimensional data in neuro-fuzzy inference systems. By integrating dual weighting mechanisms-assigning adaptive importance to both attributes and rules-together with automated growth and pruning strategies, ADAR adaptively streamlines complex fuzzy models without sacrificing performance or interpretability. Experimental evaluations on four diverse datasets - Auto MPG (7 variables), Beijing PM2.5 (10 variables), Boston Housing (13 variables), and Appliances Energy Consumption (27 variables) show that ADAR-based models achieve consistently lower Root Mean Square Error (RMSE) compared to state-of-the-art baselines. On the Beijing PM2.5 dataset, for instance, ADAR-SOFENN attained an RMSE of 56.87 with nine rules, surpassing traditional ANFIS [12] and SOFENN [16] models. Similarly, on the high-dimensional Appliances Energy dataset, ADAR-ANFIS reached an RMSE of 83.25 with nine rules, outperforming established fuzzy logic approaches and interpretability-focused methods such as APLR. Ablation studies further reveal that combining rule-level and attribute-level weight assignment significantly reduces model overlap while preserving essential features, thereby enhancing explainability. These results highlight ADAR's effectiveness in dynamically balancing rule complexity and feature importance, paving the way for scalable, high-accuracy, and transparent neuro-fuzzy systems applicable to a range of real-world scenarios.
When 'YES' Meets 'BUT': Can Large Models Comprehend Contradictory Humor Through Comparative Reasoning?
Mar 29, 2025



Understanding humor-particularly when it involves complex, contradictory narratives that require comparative reasoning-remains a significant challenge for large vision-language models (VLMs). This limitation hinders AI's ability to engage in human-like reasoning and cultural expression. In this paper, we investigate this challenge through an in-depth analysis of comics that juxtapose panels to create humor through contradictions. We introduce the YesBut (V2), a novel benchmark with 1,262 comic images from diverse multilingual and multicultural contexts, featuring comprehensive annotations that capture various aspects of narrative understanding. Using this benchmark, we systematically evaluate a wide range of VLMs through four complementary tasks spanning from surface content comprehension to deep narrative reasoning, with particular emphasis on comparative reasoning between contradictory elements. Our extensive experiments reveal that even the most advanced models significantly underperform compared to humans, with common failures in visual perception, key element identification, comparative analysis and hallucinations. We further investigate text-based training strategies and social knowledge augmentation methods to enhance model performance. Our findings not only highlight critical weaknesses in VLMs' understanding of cultural and creative expressions but also provide pathways toward developing context-aware models capable of deeper narrative understanding though comparative reasoning.
Segment then Splat: A Unified Approach for 3D Open-Vocabulary Segmentation based on Gaussian Splatting
Mar 28, 2025Open-vocabulary querying in 3D space is crucial for enabling more intelligent perception in applications such as robotics, autonomous systems, and augmented reality. However, most existing methods rely on 2D pixel-level parsing, leading to multi-view inconsistencies and poor 3D object retrieval. Moreover, they are limited to static scenes and struggle with dynamic scenes due to the complexities of motion modeling. In this paper, we propose Segment then Splat, a 3D-aware open vocabulary segmentation approach for both static and dynamic scenes based on Gaussian Splatting. Segment then Splat reverses the long established approach of "segmentation after reconstruction" by dividing Gaussians into distinct object sets before reconstruction. Once the reconstruction is complete, the scene is naturally segmented into individual objects, achieving true 3D segmentation. This approach not only eliminates Gaussian-object misalignment issues in dynamic scenes but also accelerates the optimization process, as it eliminates the need for learning a separate language field. After optimization, a CLIP embedding is assigned to each object to enable open-vocabulary querying. Extensive experiments on various datasets demonstrate the effectiveness of our proposed method in both static and dynamic scenarios.
CausalRAG: Integrating Causal Graphs into Retrieval-Augmented Generation
Mar 25, 2025Large language models (LLMs) have revolutionized natural language processing (NLP), particularly through Retrieval-Augmented Generation (RAG), which enhances LLM capabilities by integrating external knowledge. However, traditional RAG systems face critical limitations, including disrupted contextual integrity due to text chunking, and over-reliance on semantic similarity for retrieval. To address these issues, we propose CausalRAG, a novel framework that incorporates causal graphs into the retrieval process. By constructing and tracing causal relationships, CausalRAG preserves contextual continuity and improves retrieval precision, leading to more accurate and interpretable responses. We evaluate CausalRAG against regular RAG and graph-based RAG approaches, demonstrating its superiority across several metrics. Our findings suggest that grounding retrieval in causal reasoning provides a promising approach to knowledge-intensive tasks.
CAUSAL3D: A Comprehensive Benchmark for Causal Learning from Visual Data
Mar 06, 2025True intelligence hinges on the ability to uncover and leverage hidden causal relations. Despite significant progress in AI and computer vision (CV), there remains a lack of benchmarks for assessing models' abilities to infer latent causality from complex visual data. In this paper, we introduce \textsc{\textbf{Causal3D}}, a novel and comprehensive benchmark that integrates structured data (tables) with corresponding visual representations (images) to evaluate causal reasoning. Designed within a systematic framework, Causal3D comprises 19 3D-scene datasets capturing diverse causal relations, views, and backgrounds, enabling evaluations across scenes of varying complexity. We assess multiple state-of-the-art methods, including classical causal discovery, causal representation learning, and large/vision-language models (LLMs/VLMs). Our experiments show that as causal structures grow more complex without prior knowledge, performance declines significantly, highlighting the challenges even advanced methods face in complex causal scenarios. Causal3D serves as a vital resource for advancing causal reasoning in CV and fostering trustworthy AI in critical domains.