 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGAIN: Multiplicative Modulation for Domain Adaptation
Apr 06, 2026Adapting LLMs to new domains causes forgetting because standard methods (full fine-tuning, LoRA) inject new directions into the weight space. We propose GAIN, which re-emphasizes existing features through multiplicative modulation W_new = S * W. The learned diagonal matrix S is applied to the attention output projection and optionally the FFN. The principle mirrors gain modulation in neuroscience, where neurons adapt to context by scaling response strength while preserving selectivity. We evaluate GAIN on five models from four families (774M to 70B), adapting sequentially across eight domains. GAIN-FFN matches LoRA's in-domain adaptation, but their effects on previously trained domains are opposite: GAIN-FFN improves them by 7-13% (validation PPL), while LoRA degrades them by 18-36%. Downstream accuracy confirms the pattern: for example, after seven sequential adaptations on Qwen2.5, GAIN-FFN degrades BoolQ by only 0.8% while LoRA damages it by 14.9%. GAIN adds 46K-230K parameters per model and can be absorbed into the pretrained weights for zero inference cost.
Rank-Aware Negative Training for Semi-Supervised Text Classification
Jun 13, 2023Semi-supervised text classification-based paradigms (SSTC) typically employ the spirit of self-training. The key idea is to train a deep classifier on limited labeled texts and then iteratively predict the unlabeled texts as their pseudo-labels for further training. However, the performance is largely affected by the accuracy of pseudo-labels, which may not be significant in real-world scenarios. This paper presents a Rank-aware Negative Training (RNT) framework to address SSTC in learning with noisy label manner. To alleviate the noisy information, we adapt a reasoning with uncertainty-based approach to rank the unlabeled texts based on the evidential support received from the labeled texts. Moreover, we propose the use of negative training to train RNT based on the concept that ``the input instance does not belong to the complementary label''. A complementary label is randomly selected from all labels except the label on-target. Intuitively, the probability of a true label serving as a complementary label is low and thus provides less noisy information during the training, resulting in better performance on the test data. Finally, we evaluate the proposed solution on various text classification benchmark datasets. Our extensive experiments show that it consistently overcomes the state-of-the-art alternatives in most scenarios and achieves competitive performance in the others. The code of RNT is publicly available at:https://github.com/amurtadha/RNT.
Global Pointer: Novel Efficient Span-based Approach for Named Entity Recognition
Aug 05, 2022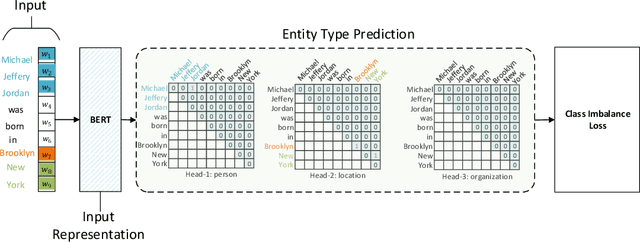
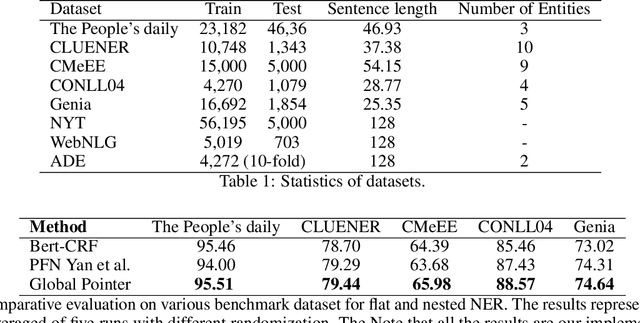
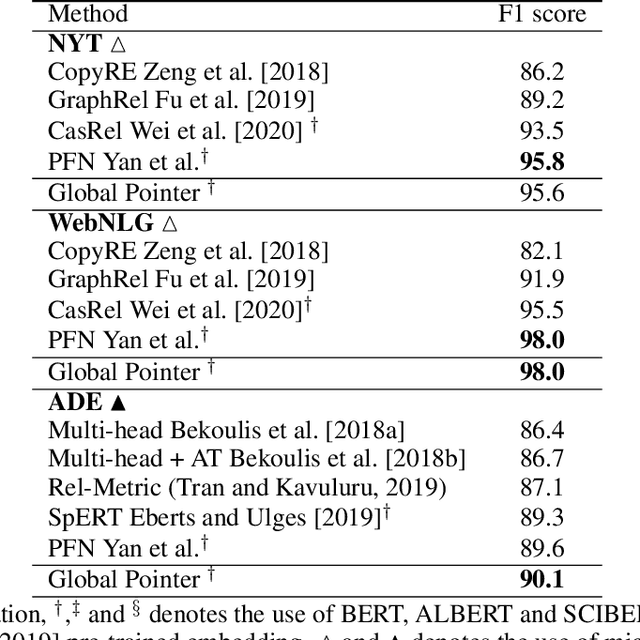

Named entity recognition (NER) task aims at identifying entities from a piece of text that belong to predefined semantic types such as person, location, organization, etc. The state-of-the-art solutions for flat entities NER commonly suffer from capturing the fine-grained semantic information in underlying texts. The existing span-based approaches overcome this limitation, but the computation time is still a concern. In this work, we propose a novel span-based NER framework, namely Global Pointer (GP), that leverages the relative positions through a multiplicative attention mechanism. The ultimate goal is to enable a global view that considers the beginning and the end positions to predict the entity. To this end, we design two modules to identify the head and the tail of a given entity to enable the inconsistency between the training and inference processes. Moreover, we introduce a novel classification loss function to address the imbalance label problem. In terms of parameters, we introduce a simple but effective approximate method to reduce the training parameters. We extensively evaluate GP on various benchmark datasets. Our extensive experiments demonstrate that GP can outperform the existing solution. Moreover, the experimental results show the efficacy of the introduced loss function compared to softmax and entropy alternatives.
ZLPR: A Novel Loss for Multi-label Classification
Aug 05, 2022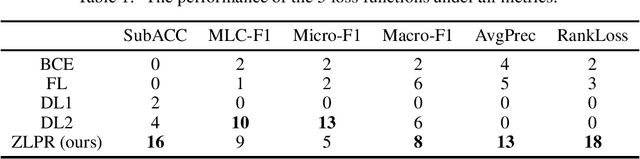
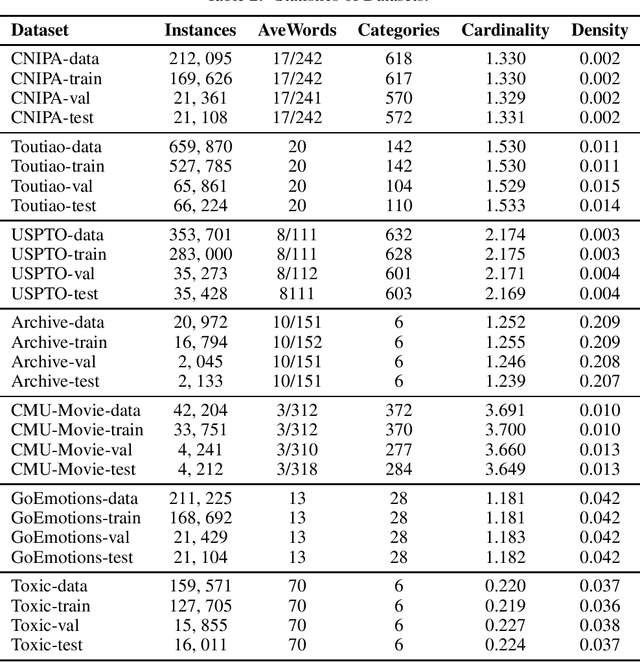
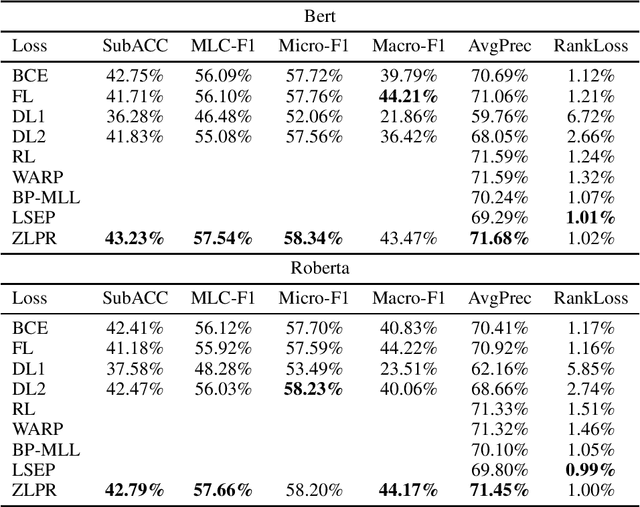
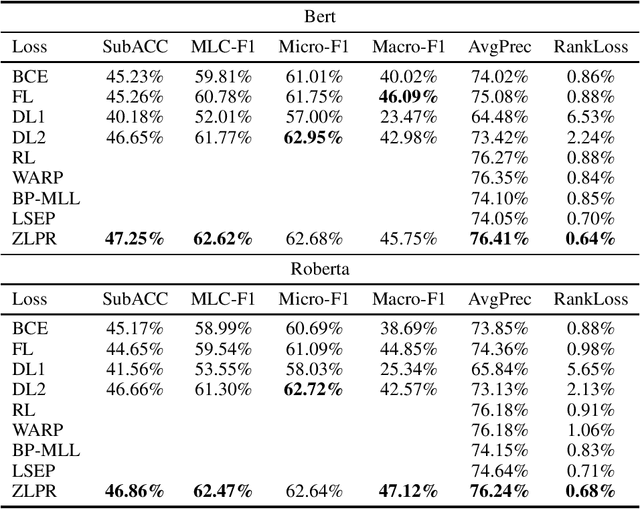
In the era of deep learning, loss functions determine the range of tasks available to models and algorithms. To support the application of deep learning in multi-label classification (MLC) tasks, we propose the ZLPR (zero-bounded log-sum-exp \& pairwise rank-based) loss in this paper. Compared to other rank-based losses for MLC, ZLPR can handel problems that the number of target labels is uncertain, which, in this point of view, makes it equally capable with the other two strategies often used in MLC, namely the binary relevance (BR) and the label powerset (LP). Additionally, ZLPR takes the corelation between labels into consideration, which makes it more comprehensive than the BR methods. In terms of computational complexity, ZLPR can compete with the BR methods because its prediction is also label-independent, which makes it take less time and memory than the LP methods. Our experiments demonstrate the effectiveness of ZLPR on multiple benchmark datasets and multiple evaluation metrics. Moreover, we propose the soft version and the corresponding KL-divergency calculation method of ZLPR, which makes it possible to apply some regularization tricks such as label smoothing to enhance the generalization of models.
BERT-ASC: Auxiliary-Sentence Construction for Implicit Aspect Learning in Sentiment Analysis
Mar 22, 2022
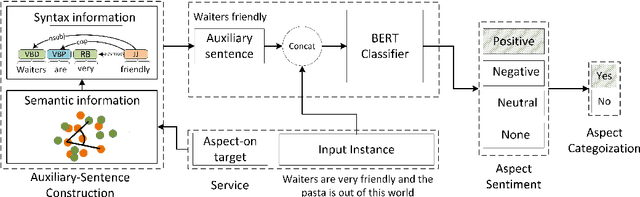
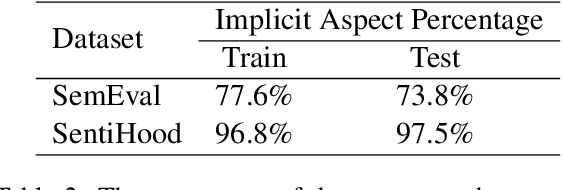

Aspect-based sentiment analysis (ABSA) task aims to associate a piece of text with a set of aspects and meanwhile infer their respective sentimental polarities. Up to now, the state-of-the-art approaches are built upon fine-tuning of various pre-trained language models. They commonly aim to learn the aspect-specific representation in the corpus. Unfortunately, the aspect is often expressed implicitly through a set of representatives and thus renders implicit mapping process unattainable unless sufficient labeled examples. In this paper, we propose to jointly address aspect categorization and aspect-based sentiment subtasks in a unified framework. Specifically, we first introduce a simple but effective mechanism that collaborates the semantic and syntactic information to construct auxiliary-sentences for the implicit aspect. Then, we encourage BERT to learn the aspect-specific representation in response to the automatically constructed auxiliary-sentence instead of the aspect itself. Finally, we empirically evaluate the performance of the proposed solution by a comparative study on real benchmark datasets for both ABSA and Targeted-ABSA tasks. Our extensive experiments show that it consistently achieves state-of-the-art performance in terms of aspect categorization and aspect-based sentiment across all datasets and the improvement margins are considerable.
Gradual Machine Learning for Entity Resolution
Oct 29, 2018

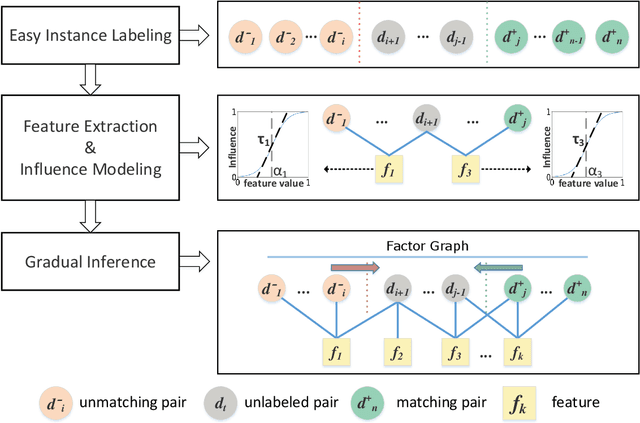
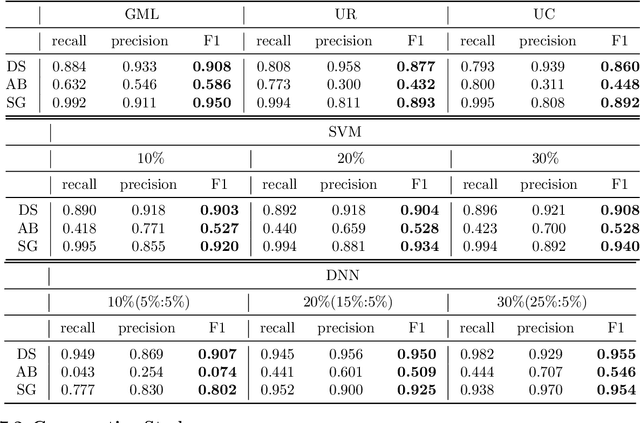
Usually considered as a classification problem, entity resolution can be very challenging on real data due to the prevalence of dirty values. The state-of-the-art solutions for ER were built on a variety of learning models (most notably deep neural networks), which require lots of accurately labeled training data. Unfortunately, high-quality labeled data usually require expensive manual work, and are therefore not readily available in many real scenarios. In this paper, we propose a novel learning paradigm for ER, called gradual machine learning, which aims to enable effective machine learning without the requirement for manual labeling effort. It begins with some easy instances in a task, which can be automatically labeled by the machine with high accuracy, and then gradually labels more challenging instances based on iterative factor graph inference. In gradual machine learning, the hard instances in a task are gradually labeled in small stages based on the estimated evidential certainty provided by the labeled easier instances. Our extensive experiments on real data have shown that the proposed approach performs considerably better than its unsupervised alternatives, and it is highly competitive with the state-of-the-art supervised techniques. Using ER as a test case, we demonstrate that gradual machine learning is a promising paradigm potentially applicable to other challenging classification tasks requiring extensive labeling effort.