 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Learning for Spatiotemporal Modeling of Urbanization
Dec 17, 2021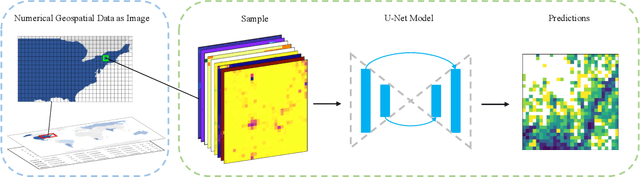
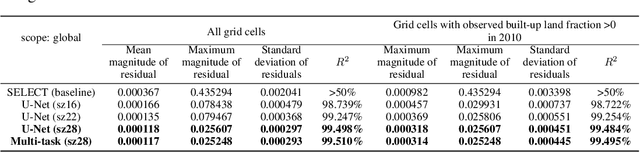
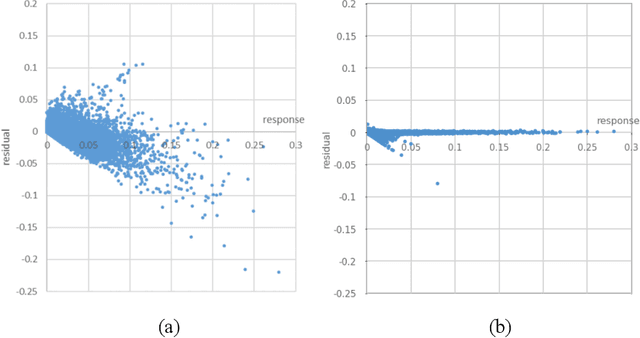

Urbanization has a strong impact on the health and wellbeing of populations across the world. Predictive spatial modeling of urbanization therefore can be a useful tool for effective public health planning. Many spatial urbanization models have been developed using classic machine learning and numerical modeling techniques. However, deep learning with its proven capacity to capture complex spatiotemporal phenomena has not been applied to urbanization modeling. Here we explore the capacity of deep spatial learning for the predictive modeling of urbanization. We treat numerical geospatial data as images with pixels and channels, and enrich the dataset by augmentation, in order to leverage the high capacity of deep learning. Our resulting model can generate end-to-end multi-variable urbanization predictions, and outperforms a state-of-the-art classic machine learning urbanization model in preliminary comparisons.
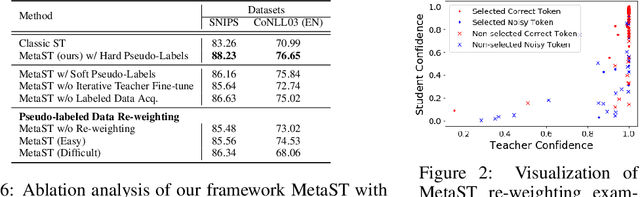
LiST: Lite Self-training Makes Efficient Few-shot Learners
Oct 12, 2021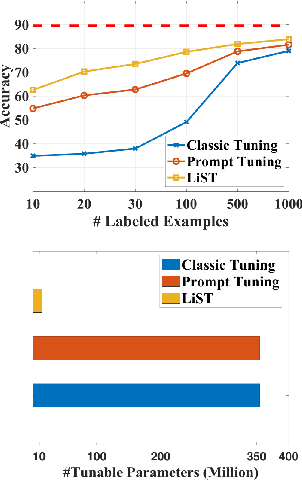
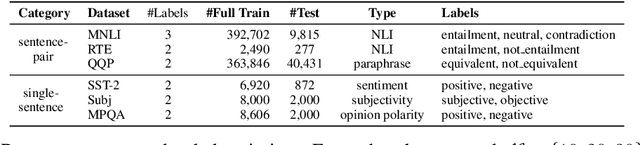
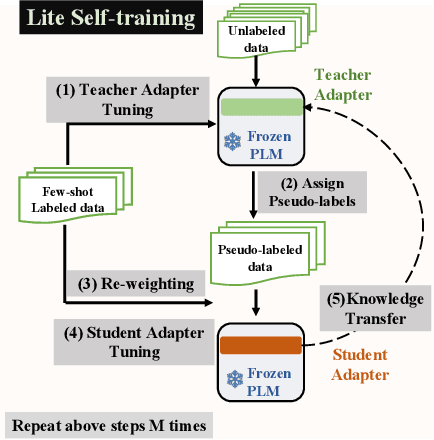
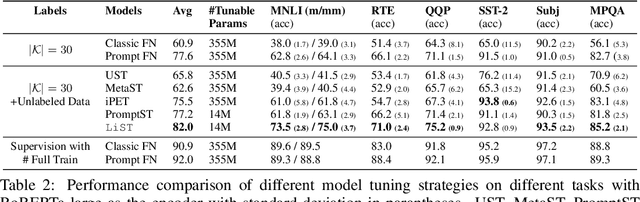
We present a new method LiST for efficient fine-tuning of large pre-trained language models (PLMs) in few-shot learning settings. LiST significantly improves over recent methods that adopt prompt fine-tuning using two key techniques. The first one is the use of self-training to leverage large amounts of unlabeled data for prompt-tuning to significantly boost the model performance in few-shot settings. We use self-training in conjunction with meta-learning for re-weighting noisy pseudo-prompt labels. However, traditional self-training is expensive as it requires updating all the model parameters repetitively. Therefore, we use a second technique for light-weight fine-tuning where we introduce a small number of task-specific adapter parameters that are fine-tuned during self-training while keeping the PLM encoder frozen. This also significantly reduces the overall model footprint across several tasks that can now share a common PLM encoder as backbone for inference. Combining the above techniques, LiST not only improves the model performance for few-shot learning on target domains but also reduces the model memory footprint. We present a comprehensive study on six NLU tasks to validate the effectiveness of LiST. The results show that LiST improves by 35% over classic fine-tuning methods and 6% over prompt-tuning with 96% reduction in number of trainable parameters when fine-tuned with no more than 30 labeled examples from each target domain.
Learning from Language Description: Low-shot Named Entity Recognition via Decomposed Framework
Sep 11, 2021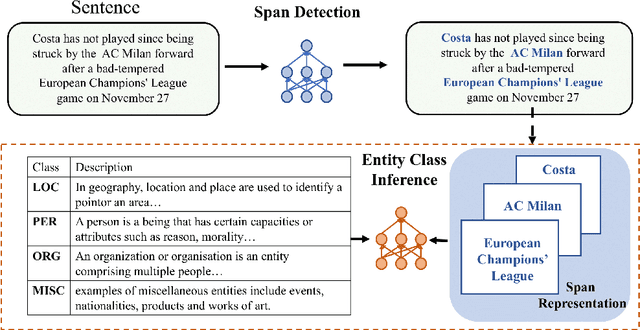
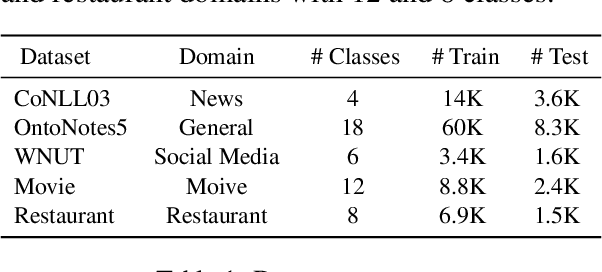
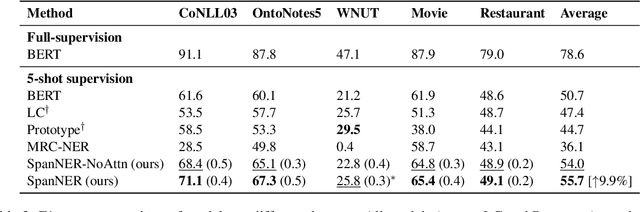
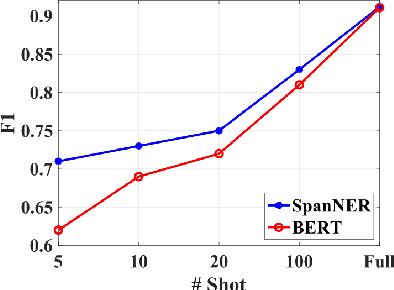
In this work, we study the problem of named entity recognition (NER) in a low resource scenario, focusing on few-shot and zero-shot settings. Built upon large-scale pre-trained language models, we propose a novel NER framework, namely SpanNER, which learns from natural language supervision and enables the identification of never-seen entity classes without using in-domain labeled data. We perform extensive experiments on 5 benchmark datasets and evaluate the proposed method in the few-shot learning, domain transfer and zero-shot learning settings. The experimental results show that the proposed method can bring 10%, 23% and 26% improvements in average over the best baselines in few-shot learning, domain transfer and zero-shot learning settings respectively.
Multimodal Emergent Fake News Detection via Meta Neural Process Networks
Jun 22, 2021
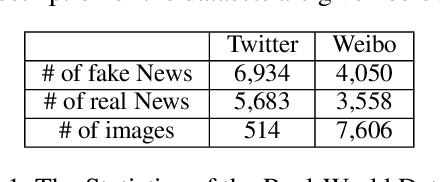
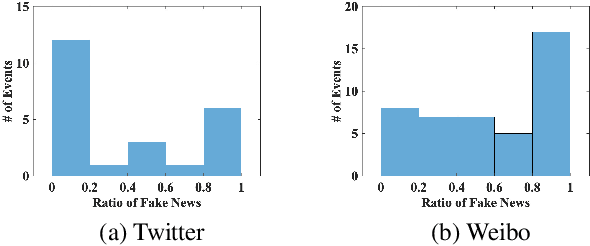

Fake news travels at unprecedented speeds, reaches global audiences and puts users and communities at great risk via social media platforms. Deep learning based models show good performance when trained on large amounts of labeled data on events of interest, whereas the performance of models tends to degrade on other events due to domain shift. Therefore, significant challenges are posed for existing detection approaches to detect fake news on emergent events, where large-scale labeled datasets are difficult to obtain. Moreover, adding the knowledge from newly emergent events requires to build a new model from scratch or continue to fine-tune the model, which can be challenging, expensive, and unrealistic for real-world settings. In order to address those challenges, we propose an end-to-end fake news detection framework named MetaFEND, which is able to learn quickly to detect fake news on emergent events with a few verified posts. Specifically, the proposed model integrates meta-learning and neural process methods together to enjoy the benefits of these approaches. In particular, a label embedding module and a hard attention mechanism are proposed to enhance the effectiveness by handling categorical information and trimming irrelevant posts. Extensive experiments are conducted on multimedia datasets collected from Twitter and Weibo. The experimental results show our proposed MetaFEND model can detect fake news on never-seen events effectively and outperform the state-of-the-art methods.
On Sampling Top-K Recommendation Evaluation
Jun 20, 2021
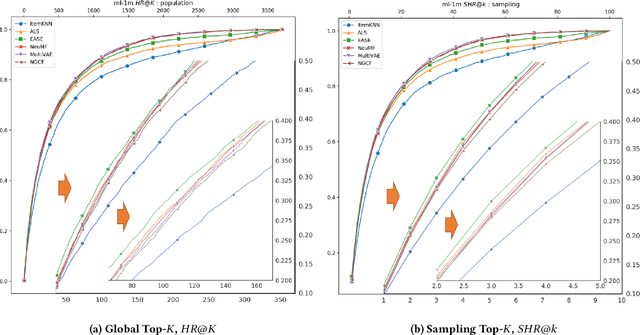
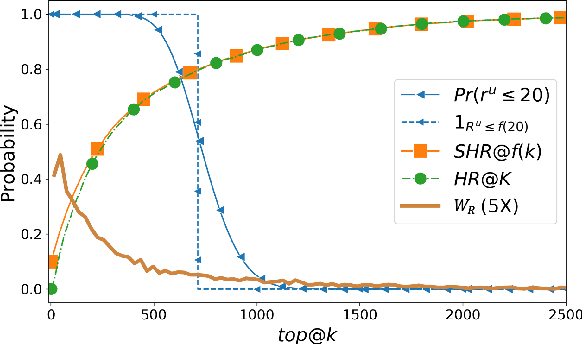
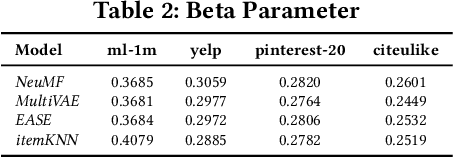
Recently, Rendle has warned that the use of sampling-based top-$k$ metrics might not suffice. This throws a number of recent studies on deep learning-based recommendation algorithms, and classic non-deep-learning algorithms using such a metric, into jeopardy. In this work, we thoroughly investigate the relationship between the sampling and global top-$K$ Hit-Ratio (HR, or Recall), originally proposed by Koren[2] and extensively used by others. By formulating the problem of aligning sampling top-$k$ ($SHR@k$) and global top-$K$ ($HR@K$) Hit-Ratios through a mapping function $f$, so that $SHR@k\approx HR@f(k)$, we demonstrate both theoretically and experimentally that the sampling top-$k$ Hit-Ratio provides an accurate approximation of its global (exact) counterpart, and can consistently predict the correct winners (the same as indicate by their corresponding global Hit-Ratios).
Towards a Better Understanding of Linear Models for Recommendation
Jun 16, 2021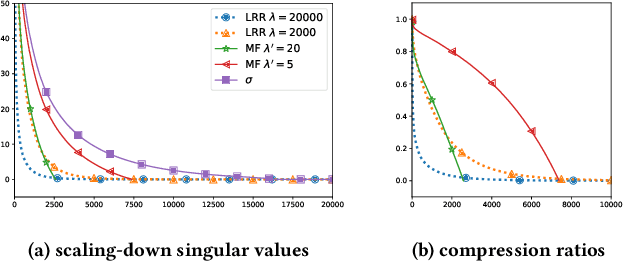
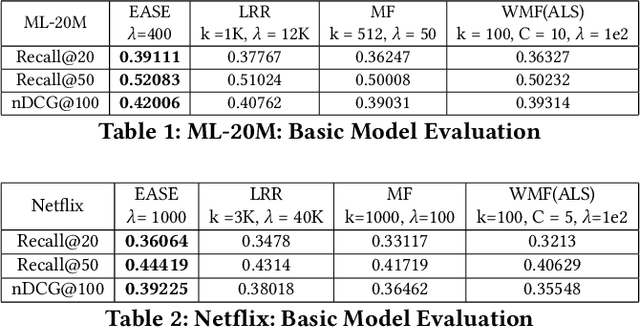
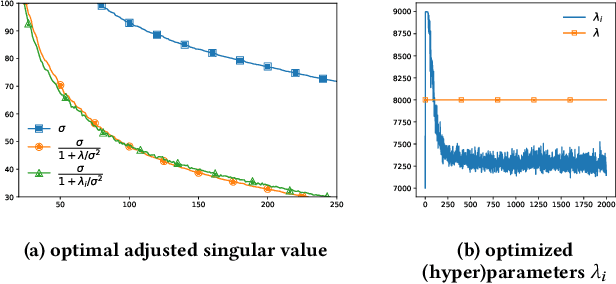
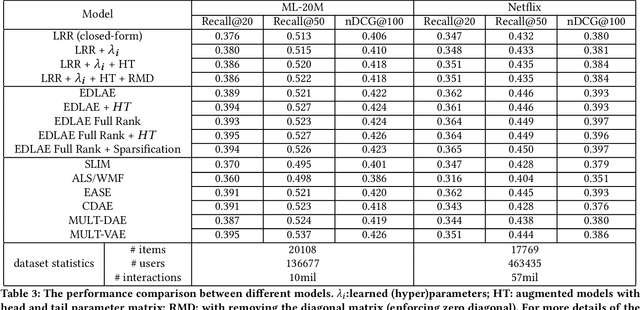
Recently, linear regression models, such as EASE and SLIM, have shown to often produce rather competitive results against more sophisticated deep learning models. On the other side, the (weighted) matrix factorization approaches have been popular choices for recommendation in the past and widely adopted in the industry. In this work, we aim to theoretically understand the relationship between these two approaches, which are the cornerstones of model-based recommendations. Through the derivation and analysis of the closed-form solutions for two basic regression and matrix factorization approaches, we found these two approaches are indeed inherently related but also diverge in how they "scale-down" the singular values of the original user-item interaction matrix. This analysis also helps resolve the questions related to the regularization parameter range and model complexities. We further introduce a new learning algorithm in searching (hyper)parameters for the closed-form solution and utilize it to discover the nearby models of the existing solutions. The experimental results demonstrate that the basic models and their closed-form solutions are indeed quite competitive against the state-of-the-art models, thus, confirming the validity of studying the basic models. The effectiveness of exploring the nearby models are also experimentally validated.
Towards Self-Supervision for Video Identification of Individual Holstein-Friesian Cattle: The Cows2021 Dataset
May 05, 2021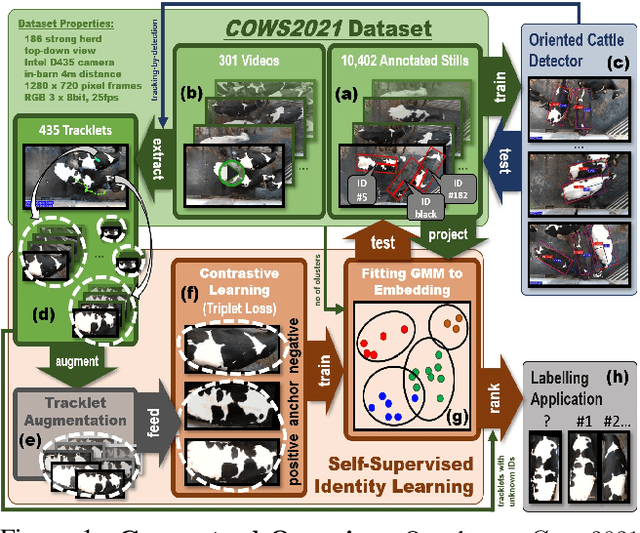


In this paper we publish the largest identity-annotated Holstein-Friesian cattle dataset Cows2021 and a first self-supervision framework for video identification of individual animals. The dataset contains 10,402 RGB images with labels for localisation and identity as well as 301 videos from the same herd. The data shows top-down in-barn imagery, which captures the breed's individually distinctive black and white coat pattern. Motivated by the labelling burden involved in constructing visual cattle identification systems, we propose exploiting the temporal coat pattern appearance across videos as a self-supervision signal for animal identity learning. Using an individual-agnostic cattle detector that yields oriented bounding-boxes, rotation-normalised tracklets of individuals are formed via tracking-by-detection and enriched via augmentations. This produces a `positive' sample set per tracklet, which is paired against a `negative' set sampled from random cattle of other videos. Frame-triplet contrastive learning is then employed to construct a metric latent space. The fitting of a Gaussian Mixture Model to this space yields a cattle identity classifier. Results show an accuracy of Top-1 57.0% and Top-4: 76.9% and an Adjusted Rand Index: 0.53 compared to the ground truth. Whilst supervised training surpasses this benchmark by a large margin, we conclude that self-supervision can nevertheless play a highly effective role in speeding up labelling efforts when initially constructing supervision information. We provide all data and full source code alongside an analysis and evaluation of the system.
Fairness-aware Outlier Ensemble
Mar 17, 2021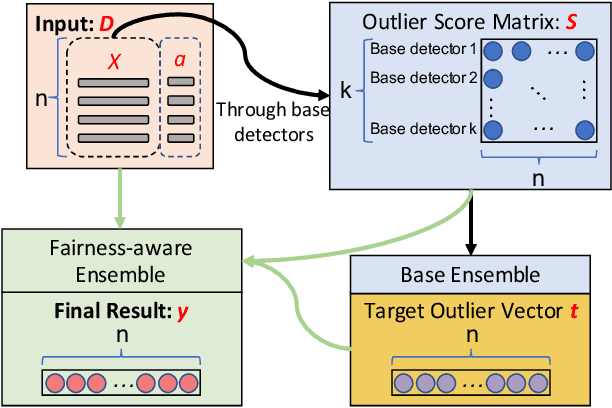

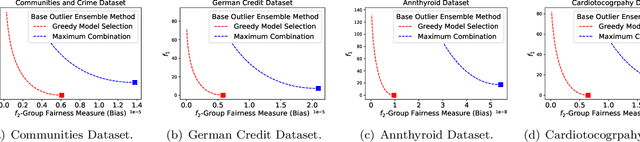
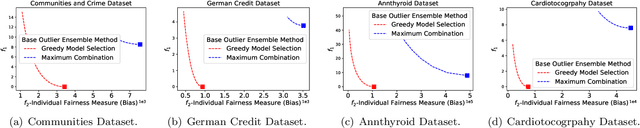
Outlier ensemble methods have shown outstanding performance on the discovery of instances that are significantly different from the majority of the data. However, without the awareness of fairness, their applicability in the ethical scenarios, such as fraud detection and judiciary judgement system, could be degraded. In this paper, we propose to reduce the bias of the outlier ensemble results through a fairness-aware ensemble framework. Due to the lack of ground truth in the outlier detection task, the key challenge is how to mitigate the degradation in the detection performance with the improvement of fairness. To address this challenge, we define a distance measure based on the output of conventional outlier ensemble techniques to estimate the possible cost associated with detection performance degradation. Meanwhile, we propose a post-processing framework to tune the original ensemble results through a stacking process so that we can achieve a trade off between fairness and detection performance. Detection performance is measured by the area under ROC curve (AUC) while fairness is measured at both group and individual level. Experiments on eight public datasets are conducted. Results demonstrate the effectiveness of the proposed framework in improving fairness of outlier ensemble results. We also analyze the trade-off between AUC and fairness.
On Estimating Recommendation Evaluation Metrics under Sampling
Mar 03, 2021
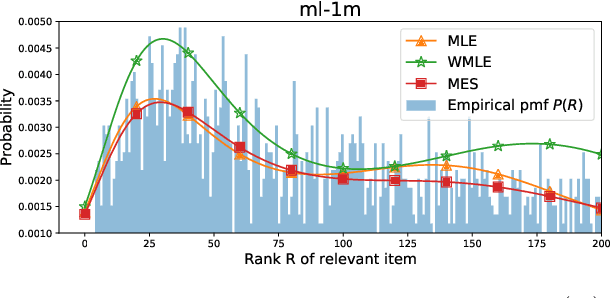
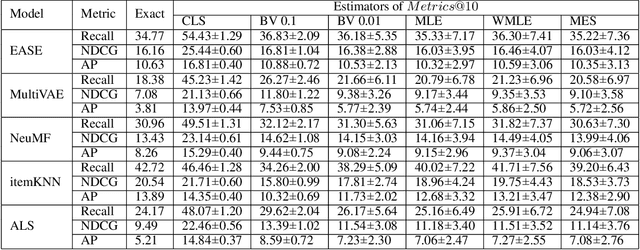
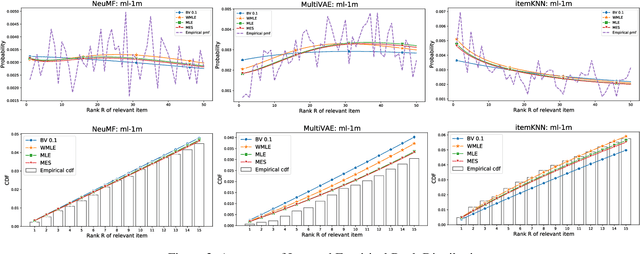
Since the recent study (Krichene and Rendle 2020) done by Krichene and Rendle on the sampling-based top-k evaluation metric for recommendation, there has been a lot of debates on the validity of using sampling to evaluate recommendation algorithms. Though their work and the recent work (Li et al.2020) have proposed some basic approaches for mapping the sampling-based metrics to their global counterparts which rank the entire set of items, there is still a lack of understanding and consensus on how sampling should be used for recommendation evaluation. The proposed approaches either are rather uninformative (linking sampling to metric evaluation) or can only work on simple metrics, such as Recall/Precision (Krichene and Rendle 2020; Li et al. 2020). In this paper, we introduce a new research problem on learning the empirical rank distribution, and a new approach based on the estimated rank distribution, to estimate the top-k metrics. Since this question is closely related to the underlying mechanism of sampling for recommendation, tackling it can help better understand the power of sampling and can help resolve the questions of if and how should we use sampling for evaluating recommendation. We introduce two approaches based on MLE (MaximalLikelihood Estimation) and its weighted variants, and ME(Maximal Entropy) principals to recover the empirical rank distribution, and then utilize them for metrics estimation. The experimental results show the advantages of using the new approaches for evaluating recommendation algorithms based on top-k metrics.
Adaptive Self-training for Few-shot Neural Sequence Labeling
Oct 07, 2020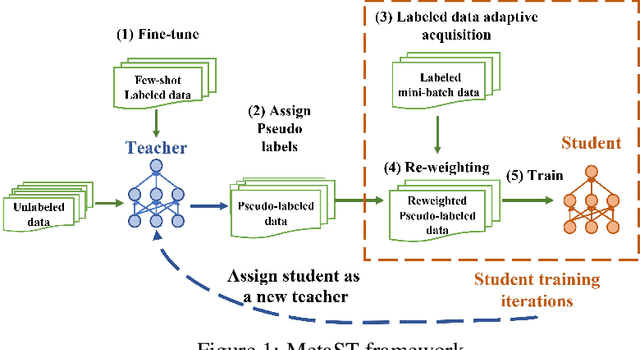
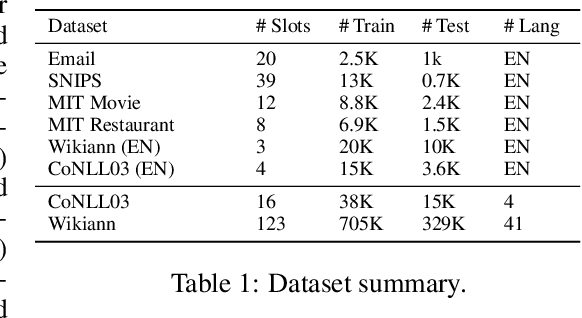
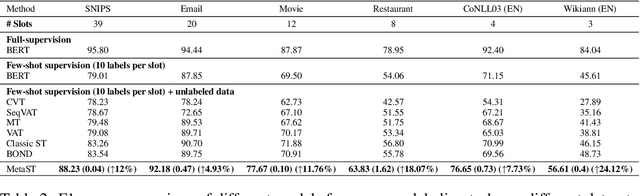
Neural sequence labeling is an important technique employed for many Natural Language Processing (NLP) tasks, such as Named Entity Recognition (NER), slot tagging for dialog systems and semantic parsing. Large-scale pre-trained language models obtain very good performance on these tasks when fine-tuned on large amounts of task-specific labeled data. However, such large-scale labeled datasets are difficult to obtain for several tasks and domains due to the high cost of human annotation as well as privacy and data access constraints for sensitive user applications. This is exacerbated for sequence labeling tasks requiring such annotations at token-level. In this work, we develop techniques to address the label scarcity challenge for neural sequence labeling models. Specifically, we develop self-training and meta-learning techniques for few-shot training of neural sequence taggers, namely MetaST. While self-training serves as an effective mechanism to learn from large amounts of unlabeled data -- meta-learning helps in adaptive sample re-weighting to mitigate error propagation from noisy pseudo-labels. Extensive experiments on six benchmark datasets including two massive multilingual NER datasets and four slot tagging datasets for task-oriented dialog systems demonstrate the effectiveness of our method with around 10% improvement over state-of-the-art systems for the 10-shot setting.