 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSoK: Dataset Copyright Auditing in Machine Learning Systems
Oct 22, 2024



As the implementation of machine learning (ML) systems becomes more widespread, especially with the introduction of larger ML models, we perceive a spring demand for massive data. However, it inevitably causes infringement and misuse problems with the data, such as using unauthorized online artworks or face images to train ML models. To address this problem, many efforts have been made to audit the copyright of the model training dataset. However, existing solutions vary in auditing assumptions and capabilities, making it difficult to compare their strengths and weaknesses. In addition, robustness evaluations usually consider only part of the ML pipeline and hardly reflect the performance of algorithms in real-world ML applications. Thus, it is essential to take a practical deployment perspective on the current dataset copyright auditing tools, examining their effectiveness and limitations. Concretely, we categorize dataset copyright auditing research into two prominent strands: intrusive methods and non-intrusive methods, depending on whether they require modifications to the original dataset. Then, we break down the intrusive methods into different watermark injection options and examine the non-intrusive methods using various fingerprints. To summarize our results, we offer detailed reference tables, highlight key points, and pinpoint unresolved issues in the current literature. By combining the pipeline in ML systems and analyzing previous studies, we highlight several future directions to make auditing tools more suitable for real-world copyright protection requirements.
A Consistency-Aware Spot-Guided Transformer for Versatile and Hierarchical Point Cloud Registration
Oct 14, 2024



Deep learning-based feature matching has shown great superiority for point cloud registration in the absence of pose priors. Although coarse-to-fine matching approaches are prevalent, the coarse matching of existing methods is typically sparse and loose without consideration of geometric consistency, which makes the subsequent fine matching rely on ineffective optimal transport and hypothesis-and-selection methods for consistency. Therefore, these methods are neither efficient nor scalable for real-time applications such as odometry in robotics. To address these issues, we design a consistency-aware spot-guided Transformer (CAST), which incorporates a spot-guided cross-attention module to avoid interfering with irrelevant areas, and a consistency-aware self-attention module to enhance matching capabilities with geometrically consistent correspondences. Furthermore, a lightweight fine matching module for both sparse keypoints and dense features can estimate the transformation accurately. Extensive experiments on both outdoor LiDAR point cloud datasets and indoor RGBD point cloud datasets demonstrate that our method achieves state-of-the-art accuracy, efficiency, and robustness.
Dashing for the Golden Snitch: Multi-Drone Time-Optimal Motion Planning with Multi-Agent Reinforcement Learning
Sep 25, 2024



Recent innovations in autonomous drones have facilitated time-optimal flight in single-drone configurations and enhanced maneuverability in multi-drone systems through the application of optimal control and learning-based methods. However, few studies have achieved time-optimal motion planning for multi-drone systems, particularly during highly agile maneuvers or in dynamic scenarios. This paper presents a decentralized policy network for time-optimal multi-drone flight using multi-agent reinforcement learning. To strike a balance between flight efficiency and collision avoidance, we introduce a soft collision penalty inspired by optimization-based methods. By customizing PPO in a centralized training, decentralized execution (CTDE) fashion, we unlock higher efficiency and stability in training, while ensuring lightweight implementation. Extensive simulations show that, despite slight performance trade-offs compared to single-drone systems, our multi-drone approach maintains near-time-optimal performance with low collision rates. Real-world experiments validate our method, with two quadrotors using the same network as simulation achieving a maximum speed of 13.65 m/s and a maximum body rate of 13.4 rad/s in a 5.5 m * 5.5 m * 2.0 m space across various tracks, relying entirely on onboard computation.
FAST: Boosting Uncertainty-based Test Prioritization Methods for Neural Networks via Feature Selection
Sep 13, 2024



Due to the vast testing space, the increasing demand for effective and efficient testing of deep neural networks (DNNs) has led to the development of various DNN test case prioritization techniques. However, the fact that DNNs can deliver high-confidence predictions for incorrectly predicted examples, known as the over-confidence problem, causes these methods to fail to reveal high-confidence errors. To address this limitation, in this work, we propose FAST, a method that boosts existing prioritization methods through guided FeAture SelecTion. FAST is based on the insight that certain features may introduce noise that affects the model's output confidence, thereby contributing to high-confidence errors. It quantifies the importance of each feature for the model's correct predictions, and then dynamically prunes the information from the noisy features during inference to derive a new probability vector for the uncertainty estimation. With the help of FAST, the high-confidence errors and correctly classified examples become more distinguishable, resulting in higher APFD (Average Percentage of Fault Detection) values for test prioritization, and higher generalization ability for model enhancement. We conduct extensive experiments to evaluate FAST across a diverse set of model structures on multiple benchmark datasets to validate the effectiveness, efficiency, and scalability of FAST compared to the state-of-the-art prioritization techniques.
AdaptiveFusion: Adaptive Multi-Modal Multi-View Fusion for 3D Human Body Reconstruction
Sep 07, 2024



Recent advancements in sensor technology and deep learning have led to significant progress in 3D human body reconstruction. However, most existing approaches rely on data from a specific sensor, which can be unreliable due to the inherent limitations of individual sensing modalities. On the other hand, existing multi-modal fusion methods generally require customized designs based on the specific sensor combinations or setups, which limits the flexibility and generality of these methods. Furthermore, conventional point-image projection-based and Transformer-based fusion networks are susceptible to the influence of noisy modalities and sensor poses. To address these limitations and achieve robust 3D human body reconstruction in various conditions, we propose AdaptiveFusion, a generic adaptive multi-modal multi-view fusion framework that can effectively incorporate arbitrary combinations of uncalibrated sensor inputs. By treating different modalities from various viewpoints as equal tokens, and our handcrafted modality sampling module by leveraging the inherent flexibility of Transformer models, AdaptiveFusion is able to cope with arbitrary numbers of inputs and accommodate noisy modalities with only a single training network. Extensive experiments on large-scale human datasets demonstrate the effectiveness of AdaptiveFusion in achieving high-quality 3D human body reconstruction in various environments. In addition, our method achieves superior accuracy compared to state-of-the-art fusion methods.
Optimizing 6G Integrated Sensing and Communications (ISAC) via Expert Networks
Jun 01, 2024



Integrated Sensing and Communications (ISAC) is one of the core technologies of 6G, which combines sensing and communication functions into a single system. However, limited computing and storage resources make it impractical to combine multiple sensing models into a single device, constraining the system's function and performance. Therefore, this article proposes enhancing ISAC with the mixture of experts (MoE) architecture. Rigorously, we first investigate ISAC and MoE, including their concepts, advantages, and applications. Then, we explore how MoE can enhance ISAC from the perspectives of signal processing and network optimization. Building on this, we propose an MoE based ISAC framework, which uses a gating network to selectively activate multiple experts in handling sensing tasks under given communication conditions, thereby improving the overall performance. The case study demonstrates that the proposed framework can effectively increase the accuracy and robustness in detecting targets by using wireless communication signal, providing strong support for the practical deployment and applications of the ISAC system.
Frequency-Domain Refinement with Multiscale Diffusion for Super Resolution
May 16, 2024



The performance of single image super-resolution depends heavily on how to generate and complement high-frequency details to low-resolution images. Recently, diffusion-based models exhibit great potential in generating high-quality images for super-resolution tasks. However, existing models encounter difficulties in directly predicting high-frequency information of wide bandwidth by solely utilizing the high-resolution ground truth as the target for all sampling timesteps. To tackle this problem and achieve higher-quality super-resolution, we propose a novel Frequency Domain-guided multiscale Diffusion model (FDDiff), which decomposes the high-frequency information complementing process into finer-grained steps. In particular, a wavelet packet-based frequency complement chain is developed to provide multiscale intermediate targets with increasing bandwidth for reverse diffusion process. Then FDDiff guides reverse diffusion process to progressively complement the missing high-frequency details over timesteps. Moreover, we design a multiscale frequency refinement network to predict the required high-frequency components at multiple scales within one unified network. Comprehensive evaluations on popular benchmarks are conducted, and demonstrate that FDDiff outperforms prior generative methods with higher-fidelity super-resolution results.
CT-NeRF: Incremental Optimizing Neural Radiance Field and Poses with Complex Trajectory
Apr 23, 2024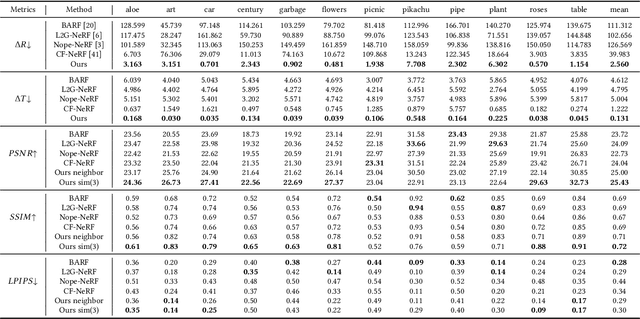
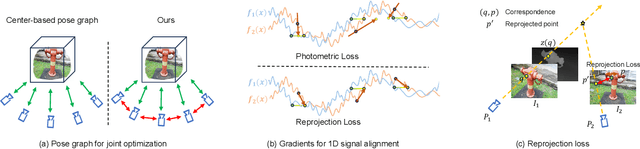
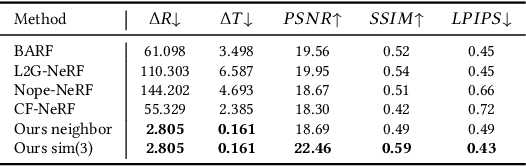
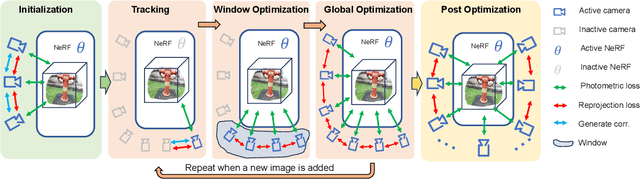
Neural radiance field (NeRF) has achieved impressive results in high-quality 3D scene reconstruction. However, NeRF heavily relies on precise camera poses. While recent works like BARF have introduced camera pose optimization within NeRF, their applicability is limited to simple trajectory scenes. Existing methods struggle while tackling complex trajectories involving large rotations. To address this limitation, we propose CT-NeRF, an incremental reconstruction optimization pipeline using only RGB images without pose and depth input. In this pipeline, we first propose a local-global bundle adjustment under a pose graph connecting neighboring frames to enforce the consistency between poses to escape the local minima caused by only pose consistency with the scene structure. Further, we instantiate the consistency between poses as a reprojected geometric image distance constraint resulting from pixel-level correspondences between input image pairs. Through the incremental reconstruction, CT-NeRF enables the recovery of both camera poses and scene structure and is capable of handling scenes with complex trajectories. We evaluate the performance of CT-NeRF on two real-world datasets, NeRFBuster and Free-Dataset, which feature complex trajectories. Results show CT-NeRF outperforms existing methods in novel view synthesis and pose estimation accuracy.
MAexp: A Generic Platform for RL-based Multi-Agent Exploration
Apr 19, 2024



The sim-to-real gap poses a significant challenge in RL-based multi-agent exploration due to scene quantization and action discretization. Existing platforms suffer from the inefficiency in sampling and the lack of diversity in Multi-Agent Reinforcement Learning (MARL) algorithms across different scenarios, restraining their widespread applications. To fill these gaps, we propose MAexp, a generic platform for multi-agent exploration that integrates a broad range of state-of-the-art MARL algorithms and representative scenarios. Moreover, we employ point clouds to represent our exploration scenarios, leading to high-fidelity environment mapping and a sampling speed approximately 40 times faster than existing platforms. Furthermore, equipped with an attention-based Multi-Agent Target Generator and a Single-Agent Motion Planner, MAexp can work with arbitrary numbers of agents and accommodate various types of robots. Extensive experiments are conducted to establish the first benchmark featuring several high-performance MARL algorithms across typical scenarios for robots with continuous actions, which highlights the distinct strengths of each algorithm in different scenarios.
Autonomous Implicit Indoor Scene Reconstruction with Frontier Exploration
Apr 16, 2024



Implicit neural representations have demonstrated significant promise for 3D scene reconstruction. Recent works have extended their applications to autonomous implicit reconstruction through the Next Best View (NBV) based method. However, the NBV method cannot guarantee complete scene coverage and often necessitates extensive viewpoint sampling, particularly in complex scenes. In the paper, we propose to 1) incorporate frontier-based exploration tasks for global coverage with implicit surface uncertainty-based reconstruction tasks to achieve high-quality reconstruction. and 2) introduce a method to achieve implicit surface uncertainty using color uncertainty, which reduces the time needed for view selection. Further with these two tasks, we propose an adaptive strategy for switching modes in view path planning, to reduce time and maintain superior reconstruction quality. Our method exhibits the highest reconstruction quality among all planning methods and superior planning efficiency in methods involving reconstruction tasks. We deploy our method on a UAV and the results show that our method can plan multi-task views and reconstruct a scene with high quality.
* 7 pages