 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSafeHarbor: Hierarchical Memory-Augmented Guardrail for LLM Agent Safety
May 07, 2026With the rapid evolution of foundation models, Large Language Model (LLM) agents have demonstrated increasingly powerful tool-use capabilities. However, this proficiency introduces significant security risks, as malicious actors can manipulate agents into executing tools to generate harmful content. While existing defensive mechanisms are effective, they frequently suffer from the over-refusal problem, where increased safety strictness compromises the agent's utility on benign tasks. To mitigate this trade-off, we propose \textsc{SafeHarbor}, a novel framework designed to establish precise decision boundaries for LLM agents. Unlike static guidelines, \textsc{SafeHarbor} extracts context-aware defense rules through enhanced adversarial generation. We design a local hierarchical memory system for dynamic rule injection, offering a training-free, efficient, and plug-and-play solution. Furthermore, we introduce an information entropy-based self-evolution mechanism that continuously optimizes the memory structure through dynamic node splitting and merging. Extensive experiments demonstrate that \textsc{SafeHarbor} achieves state-of-the-art performance on both ambiguous benign tasks and explicit malicious attacks, notably attaining a peak benign utility of 63.6\% on GPT-4o while maintaining a robust refusal rate exceeding 93\% against harmful requests. The source code is publicly available at https://github.com/ljj-cyber/SafeHarbor.
DIVER: Dynamic Iterative Visual Evidence Reasoning for Multimodal Fake News Detection
Jan 12, 2026Multimodal fake news detection is crucial for mitigating adversarial misinformation. Existing methods, relying on static fusion or LLMs, face computational redundancy and hallucination risks due to weak visual foundations. To address this, we propose DIVER (Dynamic Iterative Visual Evidence Reasoning), a framework grounded in a progressive, evidence-driven reasoning paradigm. DIVER first establishes a strong text-based baseline through language analysis, leveraging intra-modal consistency to filter unreliable or hallucinated claims. Only when textual evidence is insufficient does the framework introduce visual information, where inter-modal alignment verification adaptively determines whether deeper visual inspection is necessary. For samples exhibiting significant cross-modal semantic discrepancies, DIVER selectively invokes fine-grained visual tools (e.g., OCR and dense captioning) to extract task-relevant evidence, which is iteratively aggregated via uncertainty-aware fusion to refine multimodal reasoning. Experiments on Weibo, Weibo21, and GossipCop demonstrate that DIVER outperforms state-of-the-art baselines by an average of 2.72\%, while optimizing inference efficiency with a reduced latency of 4.12 s.
Disentangling Fact from Sentiment: A Dynamic Conflict-Consensus Framework for Multimodal Fake News Detection
Dec 19, 2025



Prevalent multimodal fake news detection relies on consistency-based fusion, yet this paradigm fundamentally misinterprets critical cross-modal discrepancies as noise, leading to over-smoothing, which dilutes critical evidence of fabrication. Mainstream consistency-based fusion inherently minimizes feature discrepancies to align modalities, yet this approach fundamentally fails because it inadvertently smoothes out the subtle cross-modal contradictions that serve as the primary evidence of fabrication. To address this, we propose the Dynamic Conflict-Consensus Framework (DCCF), an inconsistency-seeking paradigm designed to amplify rather than suppress contradictions. First, DCCF decouples inputs into independent Fact and Sentiment spaces to distinguish objective mismatches from emotional dissonance. Second, we employ physics-inspired feature dynamics to iteratively polarize these representations, actively extracting maximally informative conflicts. Finally, a conflict-consensus mechanism standardizes these local discrepancies against the global context for robust deliberative judgment.Extensive experiments conducted on three real world datasets demonstrate that DCCF consistently outperforms state-of-the-art baselines, achieving an average accuracy improvement of 3.52\%.
Performance Comparison of Aerial RIS and STAR-RIS in 3D Wireless Environments
Dec 09, 2025Reconfigurable intelligent surface (RIS) and simultaneously transmitting and reflecting RIS (STAR-RIS) have emerged as key enablers for enhancing wireless coverage and capacity in next-generation networks. When mounted on unmanned aerial vehicles (UAVs), they benefit from flexible deployment and improved line-of-sight conditions. Despite their promising potential, a comprehensive performance comparison between aerial RIS and STAR-RIS architectures has not been thoroughly investigated. This letter presents a detailed performance comparison between aerial RIS and STAR-RIS in three-dimensional wireless environments. Accurate channel models incorporating directional radiation patterns are established, and the influence of deployment altitude and orientation is thoroughly examined. To optimize the system sum-rate, we formulate joint optimization problems for both architectures and propose an efficient solution based on the weighted minimum mean square error and block coordinate descent algorithms. Simulation results reveal that STAR-RIS outperforms RIS in low-altitude scenarios due to its full-space coverage capability, whereas RIS delivers better performance near the base station at higher altitudes. The findings provide practical insights for the deployment of aerial intelligent surfaces in future 6G communication systems.
Efficient Beamforming Optimization for STAR-RIS-Assisted Communications: A Gradient-Based Meta Learning Approach
Dec 09, 2025Simultaneously transmitting and reflecting reconfigurable intelligent surface (STAR-RIS) has emerged as a promising technology to realize full-space coverage and boost spectral efficiency in next-generation wireless networks. Yet, the joint design of the base station precoding matrix as well as the STAR-RIS transmission and reflection coefficient matrices leads to a high-dimensional, strongly nonconvex, and NP-hard optimization problem. Conventional alternating optimization (AO) schemes typically involve repeated large-scale matrix inversion operations, resulting in high computational complexity and poor scalability, while existing deep learning approaches often rely on expensive pre-training and large network models. In this paper, we develop a gradient-based meta learning (GML) framework that directly feeds optimization gradients into lightweight neural networks, thereby removing the need for pre-training and enabling fast adaptation. Specifically, we design dedicated GML-based schemes for both independent-phase and coupled-phase STAR-RIS models, effectively handling their respective amplitude and phase constraints while achieving weighted sum-rate performance very close to that of AO-based benchmarks. Extensive simulations demonstrate that, for both phase models, the proposed methods substantially reduce computational overhead, with complexity growing nearly linearly when the number of BS antennas and STAR-RIS elements grows, and yielding up to 10 times runtime speedup over AO, which confirms the scalability and practicality of the proposed GML method for large-scale STAR-RIS-assisted communications.
Utilizing Jailbreak Probability to Attack and Safeguard Multimodal LLMs
Mar 10, 2025Recently, Multimodal Large Language Models (MLLMs) have demonstrated their superior ability in understanding multimodal contents. However, they remain vulnerable to jailbreak attacks, which exploit weaknesses in their safety alignment to generate harmful responses. Previous studies categorize jailbreaks as successful or failed based on whether responses contain malicious content. However, given the stochastic nature of MLLM responses, this binary classification of an input's ability to jailbreak MLLMs is inappropriate. Derived from this viewpoint, we introduce jailbreak probability to quantify the jailbreak potential of an input, which represents the likelihood that MLLMs generated a malicious response when prompted with this input. We approximate this probability through multiple queries to MLLMs. After modeling the relationship between input hidden states and their corresponding jailbreak probability using Jailbreak Probability Prediction Network (JPPN), we use continuous jailbreak probability for optimization. Specifically, we propose Jailbreak-Probability-based Attack (JPA) that optimizes adversarial perturbations on inputs to maximize jailbreak probability. To counteract attacks, we also propose two defensive methods: Jailbreak-Probability-based Finetuning (JPF) and Jailbreak-Probability-based Defensive Noise (JPDN), which minimizes jailbreak probability in the MLLM parameters and input space, respectively. Extensive experiments show that (1) JPA yields improvements (up to 28.38\%) under both white and black box settings compared to previous methods with small perturbation bounds and few iterations. (2) JPF and JPDN significantly reduce jailbreaks by at most over 60\%. Both of the above results demonstrate the significance of introducing jailbreak probability to make nuanced distinctions among input jailbreak abilities.
Multi-Turn Context Jailbreak Attack on Large Language Models From First Principles
Aug 08, 2024Large language models (LLMs) have significantly enhanced the performance of numerous applications, from intelligent conversations to text generation. However, their inherent security vulnerabilities have become an increasingly significant challenge, especially with respect to jailbreak attacks. Attackers can circumvent the security mechanisms of these LLMs, breaching security constraints and causing harmful outputs. Focusing on multi-turn semantic jailbreak attacks, we observe that existing methods lack specific considerations for the role of multiturn dialogues in attack strategies, leading to semantic deviations during continuous interactions. Therefore, in this paper, we establish a theoretical foundation for multi-turn attacks by considering their support in jailbreak attacks, and based on this, propose a context-based contextual fusion black-box jailbreak attack method, named Context Fusion Attack (CFA). This method approach involves filtering and extracting key terms from the target, constructing contextual scenarios around these terms, dynamically integrating the target into the scenarios, replacing malicious key terms within the target, and thereby concealing the direct malicious intent. Through comparisons on various mainstream LLMs and red team datasets, we have demonstrated CFA's superior success rate, divergence, and harmfulness compared to other multi-turn attack strategies, particularly showcasing significant advantages on Llama3 and GPT-4.
A clean-label graph backdoor attack method in node classification task
Dec 30, 2023Backdoor attacks in the traditional graph neural networks (GNNs) field are easily detectable due to the dilemma of confusing labels. To explore the backdoor vulnerability of GNNs and create a more stealthy backdoor attack method, a clean-label graph backdoor attack method(CGBA) in the node classification task is proposed in this paper. Differently from existing backdoor attack methods, CGBA requires neither modification of node labels nor graph structure. Specifically, to solve the problem of inconsistency between the contents and labels of the samples, CGBA selects poisoning samples in a specific target class and uses the label of sample as the target label (i.e., clean-label) after injecting triggers into the target samples. To guarantee the similarity of neighboring nodes, the raw features of the nodes are elaborately picked as triggers to further improve the concealment of the triggers. Extensive experiments results show the effectiveness of our method. When the poisoning rate is 0.04, CGBA can achieve an average attack success rate of 87.8%, 98.9%, 89.1%, and 98.5%, respectively.
Interpretable Deep Learning Model for Online Multi-touch Attribution
Mar 26, 2020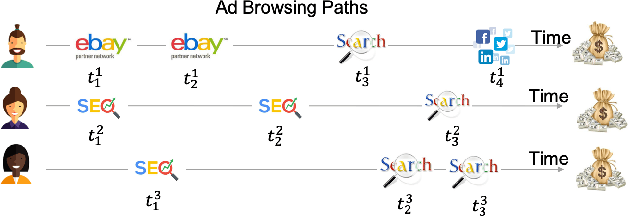
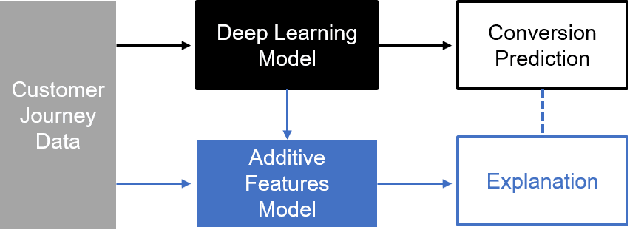
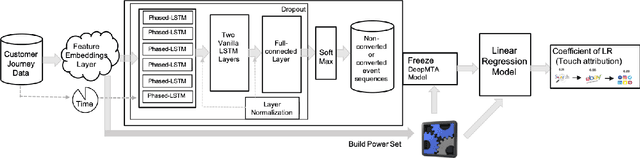
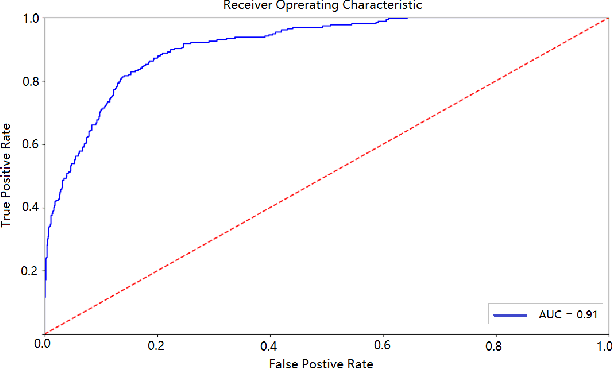
In online advertising, users may be exposed to a range of different advertising campaigns, such as natural search or referral or organic search, before leading to a final transaction. Estimating the contribution of advertising campaigns on the user's journey is very meaningful and crucial. A marketer could observe each customer's interaction with different marketing channels and modify their investment strategies accordingly. Existing methods including both traditional last-clicking methods and recent data-driven approaches for the multi-touch attribution (MTA) problem lack enough interpretation on why the methods work. In this paper, we propose a novel model called DeepMTA, which combines deep learning model and additive feature explanation model for interpretable online multi-touch attribution. DeepMTA mainly contains two parts, the phased-LSTMs based conversion prediction model to catch different time intervals, and the additive feature attribution model combined with shaley values. Additive feature attribution is explanatory that contains a linear function of binary variables. As the first interpretable deep learning model for MTA, DeepMTA considers three important features in the customer journey: event sequence order, event frequency and time-decay effect of the event. Evaluation on a real dataset shows the proposed conversion prediction model achieves 91\% accuracy.