 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLook-Ahead Selective Plasticity for Continual Learning of Visual Tasks
Nov 02, 2023Contrastive representation learning has emerged as a promising technique for continual learning as it can learn representations that are robust to catastrophic forgetting and generalize well to unseen future tasks. Previous work in continual learning has addressed forgetting by using previous task data and trained models. Inspired by event models created and updated in the brain, we propose a new mechanism that takes place during task boundaries, i.e., when one task finishes and another starts. By observing the redundancy-inducing ability of contrastive loss on the output of a neural network, our method leverages the first few samples of the new task to identify and retain parameters contributing most to the transfer ability of the neural network, freeing up the remaining parts of the network to learn new features. We evaluate the proposed methods on benchmark computer vision datasets including CIFAR10 and TinyImagenet and demonstrate state-of-the-art performance in the task-incremental, class-incremental, and domain-incremental continual learning scenarios.
Z-Code++: A Pre-trained Language Model Optimized for Abstractive Summarization
Aug 21, 2022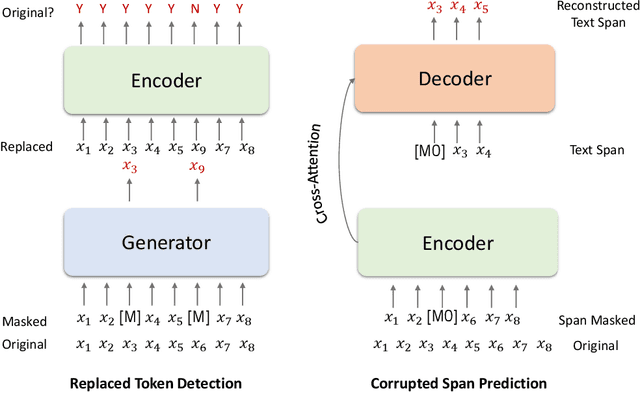

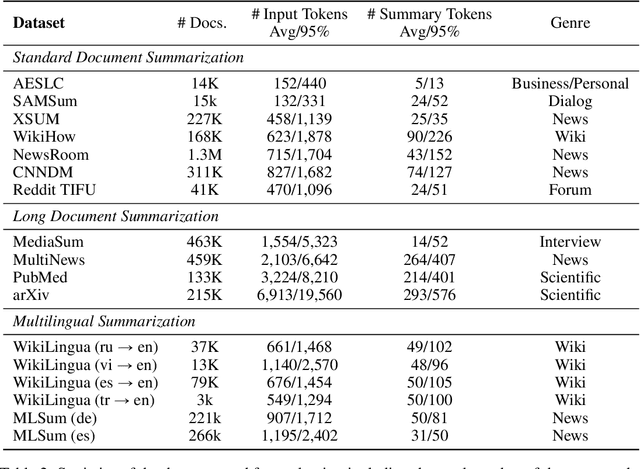
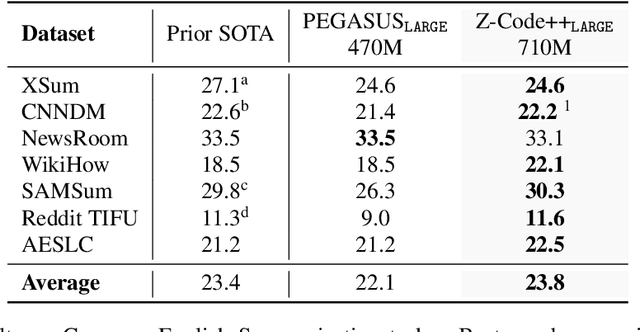
This paper presents Z-Code++, a new pre-trained language model optimized for abstractive text summarization. The model extends the state of the art encoder-decoder model using three techniques. First, we use a two-phase pre-training process to improve model's performance on low-resource summarization tasks. The model is first pre-trained using text corpora for language understanding, and then is continually pre-trained on summarization corpora for grounded text generation. Second, we replace self-attention layers in the encoder with disentangled attention layers, where each word is represented using two vectors that encode its content and position, respectively. Third, we use fusion-in-encoder, a simple yet effective method of encoding long sequences in a hierarchical manner. Z-Code++ creates new state of the art on 9 out of 13 text summarization tasks across 5 languages. Our model is parameter-efficient in that it outperforms the 600x larger PaLM-540B on XSum, and the finetuned 200x larger GPT3-175B on SAMSum. In zero-shot and few-shot settings, our model substantially outperforms the competing models.
HCIL: Hierarchical Class Incremental Learning for Longline Fishing Visual Monitoring
Feb 25, 2022
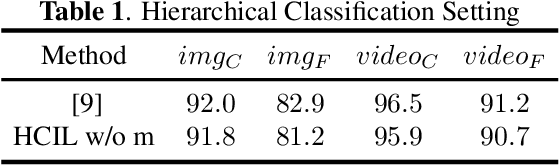
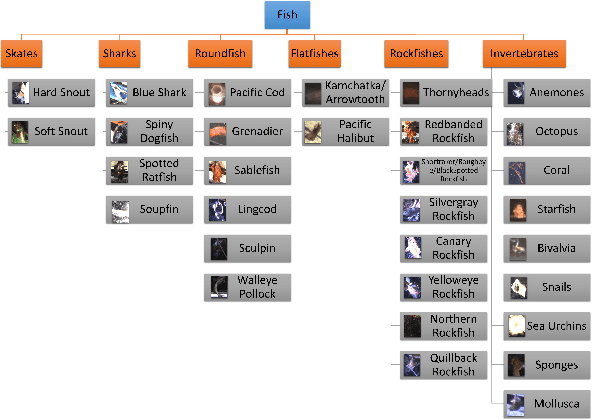
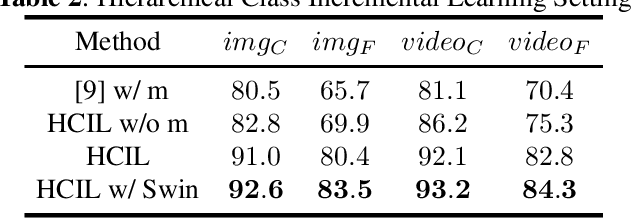
The goal of electronic monitoring of longline fishing is to visually monitor the fish catching activities on fishing vessels based on cameras, either for regulatory compliance or catch counting. The previous hierarchical classification method demonstrates efficient fish species identification of catches from longline fishing, where fishes are under severe deformation and self-occlusion during the catching process. Although the hierarchical classification mitigates the laborious efforts of human reviews by providing confidence scores in different hierarchical levels, its performance drops dramatically under the class incremental learning (CIL) scenario. A CIL system should be able to learn about more and more classes over time from a stream of data, i.e., only the training data for a small number of classes have to be present at the beginning and new classes can be added progressively. In this work, we introduce a Hierarchical Class Incremental Learning (HCIL) model, which significantly improves the state-of-the-art hierarchical classification methods under the CIL scenario.
Unsupervised Severely Deformed Mesh Reconstruction (DMR) from a Single-View Image
Jan 23, 2022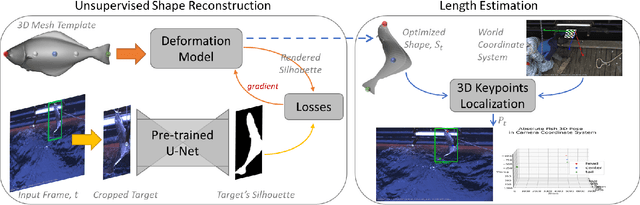
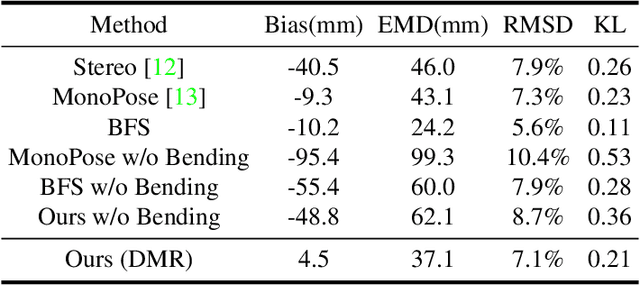

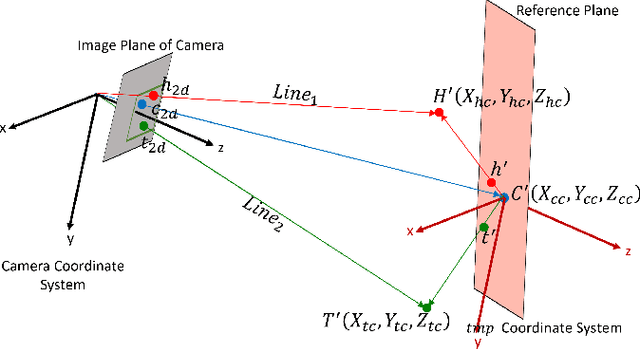
Much progress has been made in the supervised learning of 3D reconstruction of rigid objects from multi-view images or a video. However, it is more challenging to reconstruct severely deformed objects from a single-view RGB image in an unsupervised manner. Although training-based methods, such as specific category-level training, have been shown to successfully reconstruct rigid objects and slightly deformed objects like birds from a single-view image, they cannot effectively handle severely deformed objects and neither can be applied to some downstream tasks in the real world due to the inconsistent semantic meaning of vertices, which are crucial in defining the adopted 3D templates of objects to be reconstructed. In this work, we introduce a template-based method to infer 3D shapes from a single-view image and apply the reconstructed mesh to a downstream task, i.e., absolute length measurement. Without using 3D ground truth, our method faithfully reconstructs 3D meshes and achieves state-of-the-art accuracy in a length measurement task on a severely deformed fish dataset.
NTIRE 2021 Multi-modal Aerial View Object Classification Challenge
Jul 02, 2021
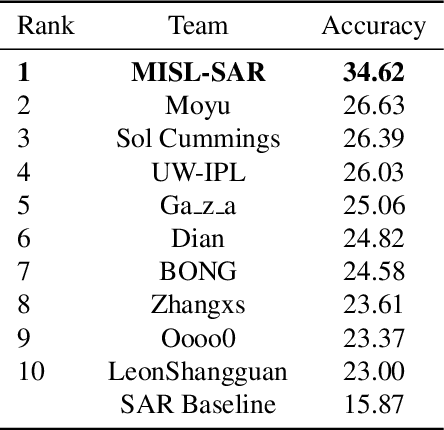
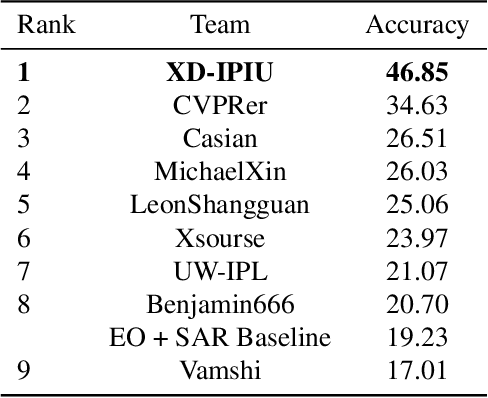
In this paper, we introduce the first Challenge on Multi-modal Aerial View Object Classification (MAVOC) in conjunction with the NTIRE 2021 workshop at CVPR. This challenge is composed of two different tracks using EO andSAR imagery. Both EO and SAR sensors possess different advantages and drawbacks. The purpose of this competition is to analyze how to use both sets of sensory information in complementary ways. We discuss the top methods submitted for this competition and evaluate their results on our blind test set. Our challenge results show significant improvement of more than 15% accuracy from our current baselines for each track of the competition
* 10 pages, 1 figure. Conference on Computer Vision and Pattern Recognition
MediaSum: A Large-scale Media Interview Dataset for Dialogue Summarization
Mar 12, 2021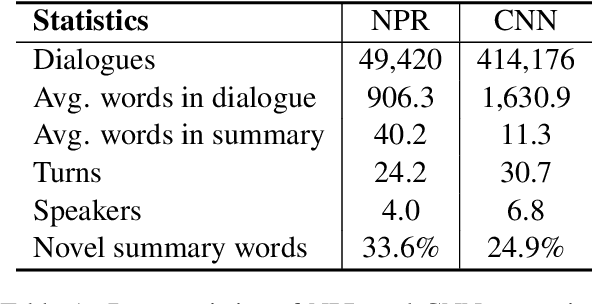
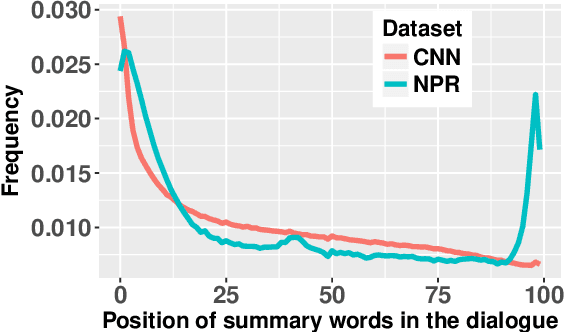
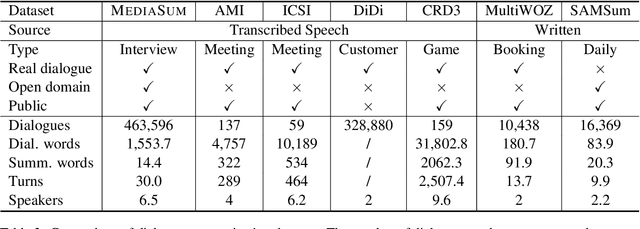
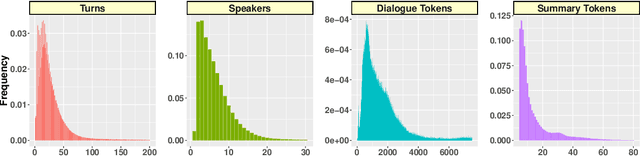
MediaSum, a large-scale media interview dataset consisting of 463.6K transcripts with abstractive summaries. To create this dataset, we collect interview transcripts from NPR and CNN and employ the overview and topic descriptions as summaries. Compared with existing public corpora for dialogue summarization, our dataset is an order of magnitude larger and contains complex multi-party conversations from multiple domains. We conduct statistical analysis to demonstrate the unique positional bias exhibited in the transcripts of televised and radioed interviews. We also show that MediaSum can be used in transfer learning to improve a model's performance on other dialogue summarization tasks.
* Dataset: https://github.com/zcgzcgzcg1/MediaSum/
Absolute 3D Pose Estimation and Length Measurement of Severely Deformed Fish from Monocular Videos in Longline Fishing
Feb 09, 2021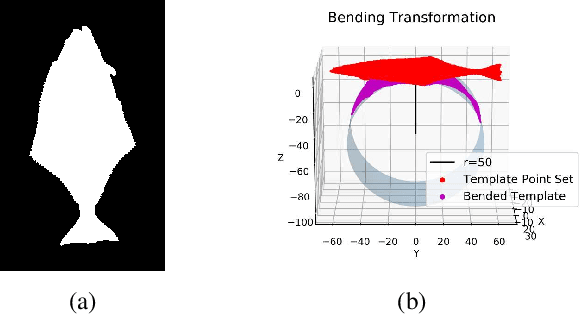
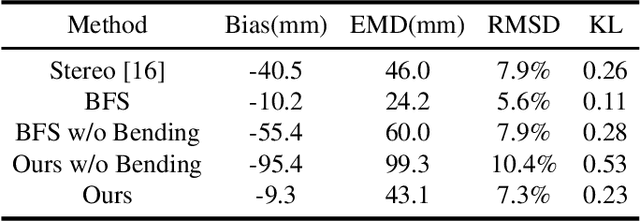
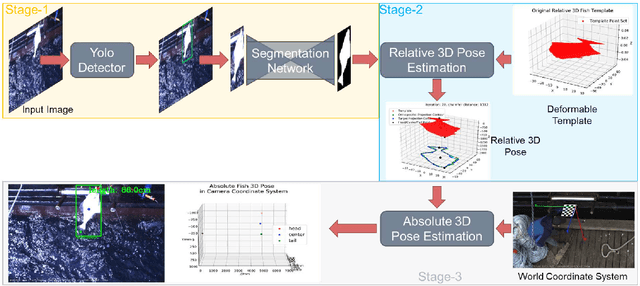
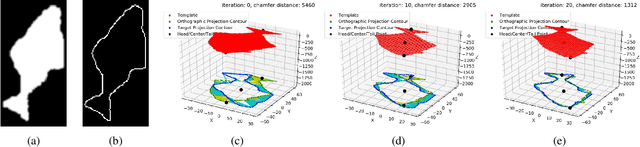
Monocular absolute 3D fish pose estimation allows for efficient fish length measurement in the longline fisheries, where fishes are under severe deformation during the catching process. This task is challenging since it requires locating absolute 3D fish keypoints based on a short monocular video clip. Unlike related works, which either require expensive 3D ground-truth data and/or multiple-view images to provide depth information, or are limited to rigid objects, we propose a novel frame-based method to estimate the absolute 3D fish pose and fish length from a single-view 2D segmentation mask. We first introduce a relative 3D fish template. By minimizing an objective function, our method systematically estimates the relative 3D pose of the target fish and fish 2D keypoints in the image. Finally, with a closed-form solution, the relative 3D fish pose can help locate absolute 3D keypoints, resulting in the frame-based absolute fish length measurement, which is further refined based on the statistical temporal inference for the optimal fish length measurement from the video clip. Our experiments show that this method can accurately estimate the absolute 3D fish pose and further measure the absolute length, even outperforming the state-of-the-art multi-view method.
Video-based Hierarchical Species Classification for Longline Fishing Monitoring
Feb 06, 2021
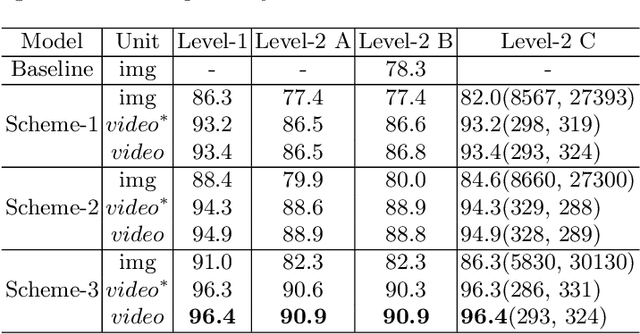
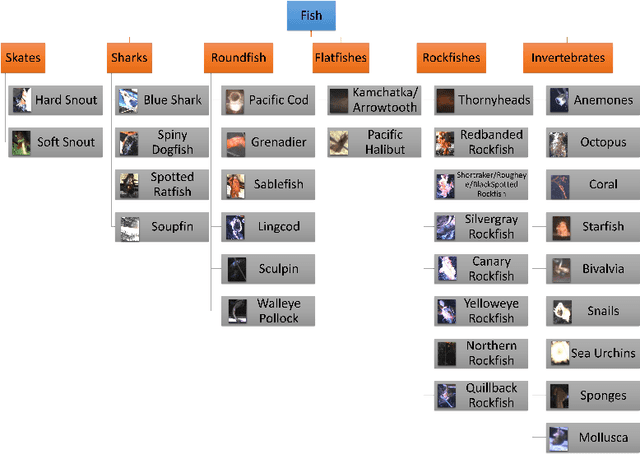
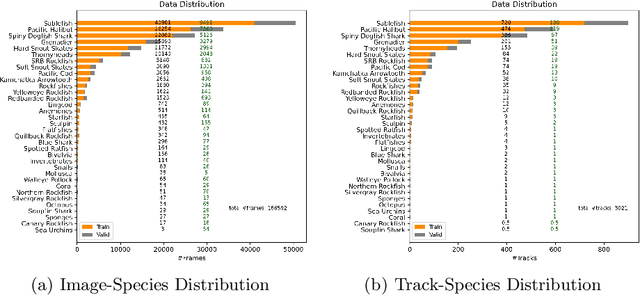
The goal of electronic monitoring (EM) of longline fishing is to monitor the fish catching activities on fishing vessels, either for the regulatory compliance or catch counting. Hierarchical classification based on videos allows for inexpensive and efficient fish species identification of catches from longline fishing, where fishes are under severe deformation and self-occlusion during the catching process. More importantly, the flexibility of hierarchical classification mitigates the laborious efforts of human reviews by providing confidence scores in different hierarchical levels. Some related works either use cascaded models for hierarchical classification or make predictions per image or predict one overlapping hierarchical data structure of the dataset in advance. However, with a known non-overlapping hierarchical data structure provided by fisheries scientists, our method enforces the hierarchical data structure and introduces an efficient training and inference strategy for video-based fisheries data. Our experiments show that the proposed method outperforms the classic flat classification system significantly and our ablation study justifies our contributions in CNN model design, training strategy, and the video-based inference schemes for the hierarchical fish species classification task.
Seismic Facies Analysis: A Deep Domain Adaptation Approach
Nov 20, 2020

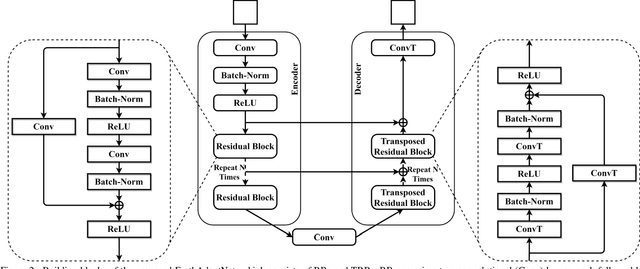

Deep neural networks (DNNs) can learn accurately from large quantities of labeled input data, but DNNs sometimes fail to generalize to test data sampled from different input distributions. Unsupervised Deep Domain Adaptation (DDA) proves useful when no input labels are available, and distribution shifts are observed in the target domain (TD). Experiments are performed on seismic images of the F3 block 3D dataset from offshore Netherlands (source domain; SD) and Penobscot 3D survey data from Canada (target domain; TD). Three geological classes from SD and TD that have similar reflection patterns are considered. In the present study, an improved deep neural network architecture named EarthAdaptNet (EAN) is proposed to semantically segment the seismic images. We specifically use a transposed residual unit to replace the traditional dilated convolution in the decoder block. The EAN achieved a pixel-level accuracy >84% and an accuracy of ~70% for the minority classes, showing improved performance compared to existing architectures. In addition, we introduced the CORAL (Correlation Alignment) method to the EAN to create an unsupervised deep domain adaptation network (EAN-DDA) for the classification of seismic reflections fromF3 and Penobscot. Maximum class accuracy achieved was ~99% for class 2 of Penobscot with >50% overall accuracy. Taken together, EAN-DDA has the potential to classify target domain seismic facies classes with high accuracy.
Machine learning for the diagnosis of Parkinson's disease: A systematic review
Oct 13, 2020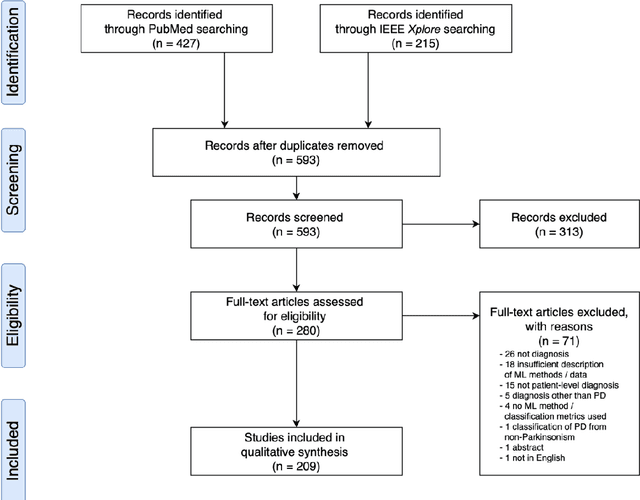
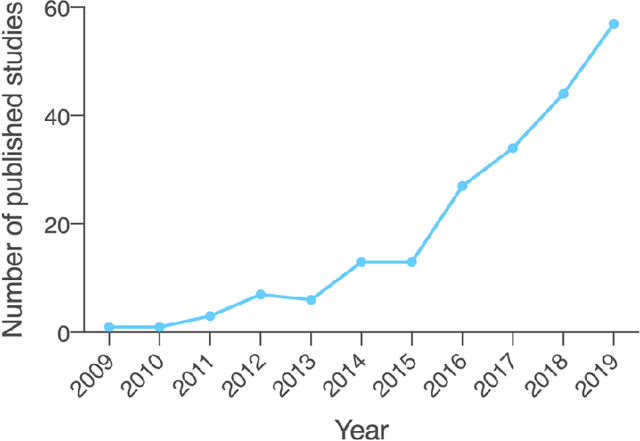
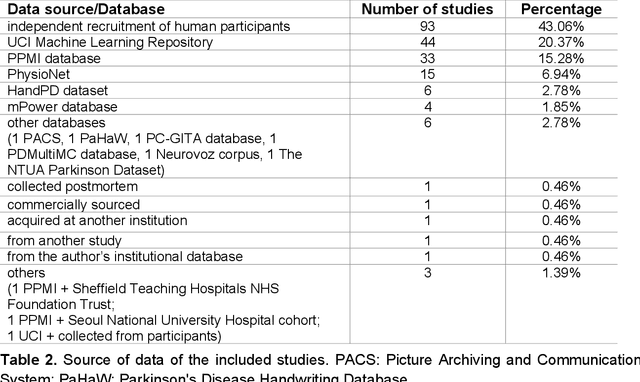
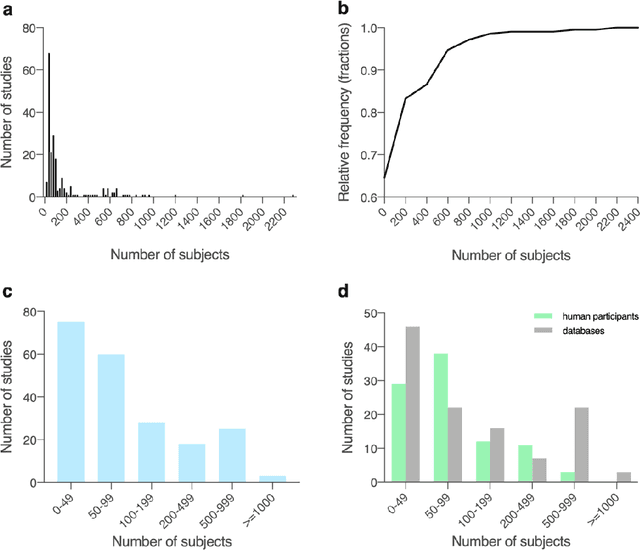
Diagnosis of Parkinson's disease (PD) is commonly based on medical observations and assessment of clinical signs, including the characterization of a variety of motor symptoms. However, traditional diagnostic approaches may suffer from subjectivity as they rely on the evaluation of movements that are sometimes subtle to human eyes and therefore difficult to classify, leading to possible misclassification. In the meantime, early non-motor symptoms of PD may be mild and can be caused by many other conditions. Therefore, these symptoms are often overlooked, making diagnosis of PD at an early stage challenging. To address these difficulties and to refine the diagnosis and assessment procedures of PD, machine learning methods have been implemented for the classification of PD and healthy controls or patients with similar clinical presentations (e.g., movement disorders or other Parkinsonian syndromes). To provide a comprehensive overview of data modalities and machine learning methods that have been used in the diagnosis and differential diagnosis of PD, in this study, we conducted a systematic literature review of studies published until February 14, 2020, using the PubMed and IEEE Xplore databases. A total of 209 studies were included, extracted for relevant information and presented in this systematic review, with an investigation of their aims, sources of data, types of data, machine learning methods and associated outcomes. These studies demonstrate a high potential for adaptation of machine learning methods and novel biomarkers in clinical decision making, leading to increasingly systematic, informed diagnosis of PD.