 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Semi-supervised Nighttime Dehazing Baseline with Spatial-Frequency Aware and Realistic Brightness Constraint
Mar 27, 2024



Existing research based on deep learning has extensively explored the problem of daytime image dehazing. However, few studies have considered the characteristics of nighttime hazy scenes. There are two distinctions between nighttime and daytime haze. First, there may be multiple active colored light sources with lower illumination intensity in nighttime scenes, which may cause haze, glow and noise with localized, coupled and frequency inconsistent characteristics. Second, due to the domain discrepancy between simulated and real-world data, unrealistic brightness may occur when applying a dehazing model trained on simulated data to real-world data. To address the above two issues, we propose a semi-supervised model for real-world nighttime dehazing. First, the spatial attention and frequency spectrum filtering are implemented as a spatial-frequency domain information interaction module to handle the first issue. Second, a pseudo-label-based retraining strategy and a local window-based brightness loss for semi-supervised training process is designed to suppress haze and glow while achieving realistic brightness. Experiments on public benchmarks validate the effectiveness of the proposed method and its superiority over state-of-the-art methods. The source code and Supplementary Materials are placed in the https://github.com/Xiaofeng-life/SFSNiD.
Illumination Controllable Dehazing Network based on Unsupervised Retinex Embedding
Jun 09, 2023



On the one hand, the dehazing task is an illposedness problem, which means that no unique solution exists. On the other hand, the dehazing task should take into account the subjective factor, which is to give the user selectable dehazed images rather than a single result. Therefore, this paper proposes a multi-output dehazing network by introducing illumination controllable ability, called IC-Dehazing. The proposed IC-Dehazing can change the illumination intensity by adjusting the factor of the illumination controllable module, which is realized based on the interpretable Retinex theory. Moreover, the backbone dehazing network of IC-Dehazing consists of a Transformer with double decoders for high-quality image restoration. Further, the prior-based loss function and unsupervised training strategy enable IC-Dehazing to complete the parameter learning process without the need for paired data. To demonstrate the effectiveness of the proposed IC-Dehazing, quantitative and qualitative experiments are conducted on image dehazing, semantic segmentation, and object detection tasks. Code is available at https://github.com/Xiaofeng-life/ICDehazing.
No Place to Hide: Dual Deep Interaction Channel Network for Fake News Detection based on Data Augmentation
Mar 31, 2023



Online Social Network (OSN) has become a hotbed of fake news due to the low cost of information dissemination. Although the existing methods have made many attempts in news content and propagation structure, the detection of fake news is still facing two challenges: one is how to mine the unique key features and evolution patterns, and the other is how to tackle the problem of small samples to build the high-performance model. Different from popular methods which take full advantage of the propagation topology structure, in this paper, we propose a novel framework for fake news detection from perspectives of semantic, emotion and data enhancement, which excavates the emotional evolution patterns of news participants during the propagation process, and a dual deep interaction channel network of semantic and emotion is designed to obtain a more comprehensive and fine-grained news representation with the consideration of comments. Meanwhile, the framework introduces a data enhancement module to obtain more labeled data with high quality based on confidence which further improves the performance of the classification model. Experiments show that the proposed approach outperforms the state-of-the-art methods.
Adversarial Attack and Defense for Dehazing Networks
Mar 30, 2023



The research on single image dehazing task has been widely explored. However, as far as we know, no comprehensive study has been conducted on the robustness of the well-trained dehazing models. Therefore, there is no evidence that the dehazing networks can resist malicious attacks. In this paper, we focus on designing a group of attack methods based on first order gradient to verify the robustness of the existing dehazing algorithms. By analyzing the general goal of image dehazing task, five attack methods are proposed, which are prediction, noise, mask, ground-truth and input attack. The corresponding experiments are conducted on six datasets with different scales. Further, the defense strategy based on adversarial training is adopted for reducing the negative effects caused by malicious attacks. In summary, this paper defines a new challenging problem for image dehazing area, which can be called as adversarial attack on dehazing networks (AADN). Code is available at https://github.com/guijiejie/AADN.
A Survey of Self-Supervised Learning from Multiple Perspectives: Algorithms, Theory, Applications and Future Trends
Jan 13, 2023



Deep supervised learning algorithms generally require large numbers of labeled examples to attain satisfactory performance. To avoid the expensive cost incurred by collecting and labeling too many examples, as a subset of unsupervised learning, self-supervised learning (SSL) was proposed to learn good features from many unlabeled examples without any human-annotated labels. SSL has recently become a hot research topic, and many related algorithms have been proposed. However, few comprehensive studies have explained the connections among different SSL variants and how they have evolved. In this paper, we attempt to provide a review of the various SSL methods from the perspectives of algorithms, theory, applications, three main trends, and open questions. First, the motivations of most SSL algorithms are introduced in detail, and their commonalities and differences are compared. Second, the theoretical issues associated with SSL are investigated. Third, typical applications of SSL in areas such as image processing and computer vision (CV), as well as natural language processing (NLP), are discussed. Finally, the three main trends of SSL and the open research questions are discussed. A collection of useful materials is available at https://github.com/guijiejie/SSL.
Learning the Relation between Similarity Loss and Clustering Loss in Self-Supervised Learning
Jan 08, 2023



Self-supervised learning enables networks to learn discriminative features from massive data itself. Most state-of-the-art methods maximize the similarity between two augmentations of one image based on contrastive learning. By utilizing the consistency of two augmentations, the burden of manual annotations can be freed. Contrastive learning exploits instance-level information to learn robust features. However, the learned information is probably confined to different views of the same instance. In this paper, we attempt to leverage the similarity between two distinct images to boost representation in self-supervised learning. In contrast to instance-level information, the similarity between two distinct images may provide more useful information. Besides, we analyze the relation between similarity loss and feature-level cross-entropy loss. These two losses are essential for most deep learning methods. However, the relation between these two losses is not clear. Similarity loss helps obtain instance-level representation, while feature-level cross-entropy loss helps mine the similarity between two distinct images. We provide theoretical analyses and experiments to show that a suitable combination of these two losses can get state-of-the-art results.
Fast Online Hashing with Multi-Label Projection
Dec 03, 2022



Hashing has been widely researched to solve the large-scale approximate nearest neighbor search problem owing to its time and storage superiority. In recent years, a number of online hashing methods have emerged, which can update the hash functions to adapt to the new stream data and realize dynamic retrieval. However, existing online hashing methods are required to update the whole database with the latest hash functions when a query arrives, which leads to low retrieval efficiency with the continuous increase of the stream data. On the other hand, these methods ignore the supervision relationship among the examples, especially in the multi-label case. In this paper, we propose a novel Fast Online Hashing (FOH) method which only updates the binary codes of a small part of the database. To be specific, we first build a query pool in which the nearest neighbors of each central point are recorded. When a new query arrives, only the binary codes of the corresponding potential neighbors are updated. In addition, we create a similarity matrix which takes the multi-label supervision information into account and bring in the multi-label projection loss to further preserve the similarity among the multi-label data. The experimental results on two common benchmarks show that the proposed FOH can achieve dramatic superiority on query time up to 6.28 seconds less than state-of-the-art baselines with competitive retrieval accuracy.
Good helper is around you: Attention-driven Masked Image Modeling
Dec 01, 2022It has been witnessed that masked image modeling (MIM) has shown a huge potential in self-supervised learning in the past year. Benefiting from the universal backbone vision transformer, MIM learns self-supervised visual representations through masking a part of patches of the image while attempting to recover the missing pixels. Most previous works mask patches of the image randomly, which underutilizes the semantic information that is beneficial to visual representation learning. On the other hand, due to the large size of the backbone, most previous works have to spend much time on pre-training. In this paper, we propose \textbf{Attention-driven Masking and Throwing Strategy} (AMT), which could solve both problems above. We first leverage the self-attention mechanism to obtain the semantic information of the image during the training process automatically without using any supervised methods. Masking strategy can be guided by that information to mask areas selectively, which is helpful for representation learning. Moreover, a redundant patch throwing strategy is proposed, which makes learning more efficient. As a plug-and-play module for masked image modeling, AMT improves the linear probing accuracy of MAE by $2.9\% \sim 5.9\%$ on CIFAR-10/100, STL-10, Tiny ImageNet, and ImageNet-1K, and obtains an improved performance with respect to fine-tuning accuracy of MAE and SimMIM. Moreover, this design also achieves superior performance on downstream detection and segmentation tasks. Code is available at https://github.com/guijiejie/AMT.
AlignVE: Visual Entailment Recognition Based on Alignment Relations
Nov 16, 2022



Visual entailment (VE) is to recognize whether the semantics of a hypothesis text can be inferred from the given premise image, which is one special task among recent emerged vision and language understanding tasks. Currently, most of the existing VE approaches are derived from the methods of visual question answering. They recognize visual entailment by quantifying the similarity between the hypothesis and premise in the content semantic features from multi modalities. Such approaches, however, ignore the VE's unique nature of relation inference between the premise and hypothesis. Therefore, in this paper, a new architecture called AlignVE is proposed to solve the visual entailment problem with a relation interaction method. It models the relation between the premise and hypothesis as an alignment matrix. Then it introduces a pooling operation to get feature vectors with a fixed size. Finally, it goes through the fully-connected layer and normalization layer to complete the classification. Experiments show that our alignment-based architecture reaches 72.45\% accuracy on SNLI-VE dataset, outperforming previous content-based models under the same settings.
Predicting Tau Accumulation in Cerebral Cortex with Multivariate MRI Morphometry Measurements, Sparse Coding, and Correntropy
Oct 20, 2021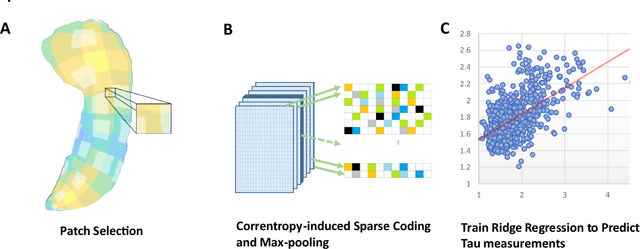
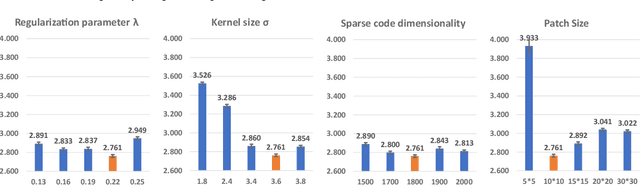
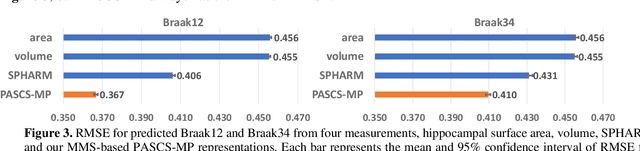
Biomarker-assisted diagnosis and intervention in Alzheimer's disease (AD) may be the key to prevention breakthroughs. One of the hallmarks of AD is the accumulation of tau plaques in the human brain. However, current methods to detect tau pathology are either invasive (lumbar puncture) or quite costly and not widely available (Tau PET). In our previous work, structural MRI-based hippocampal multivariate morphometry statistics (MMS) showed superior performance as an effective neurodegenerative biomarker for preclinical AD and Patch Analysis-based Surface Correntropy-induced Sparse coding and max-pooling (PASCS-MP) has excellent ability to generate low-dimensional representations with strong statistical power for brain amyloid prediction. In this work, we apply this framework together with ridge regression models to predict Tau deposition in Braak12 and Braak34 brain regions separately. We evaluate our framework on 925 subjects from the Alzheimer's Disease Neuroimaging Initiative (ADNI). Each subject has one pair consisting of a PET image and MRI scan which were collected at about the same times. Experimental results suggest that the representations from our MMS and PASCS-MP have stronger predictive power and their predicted Braak12 and Braak34 are closer to the real values compared to the measures derived from other approaches such as hippocampal surface area and volume, and shape morphometry features based on spherical harmonics (SPHARM).