 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStructural Dilemmas and Developmental Pathways of Legal Argument Mining in the Era of Artificial Intelligence
May 04, 2026Against the backdrop of rapid advances in artificial intelligence, legal argument mining has emerged as an important research area linking legal texts with intelligent analysis, carrying significant theoretical and practical implications. Existing studies have primarily developed along three dimensions: data, technology, and theory. At the data level, raw legal texts and annotated corpora constitute the foundational resources. At the technological level, research paradigms have evolved from rule-based systems and traditional machine learning to large language models (LLMs). At the theoretical level, argumentation theory and legal dogmatics provide important references for modeling argumentation structures. However, despite ongoing progress, the overall development of legal argument mining remains relatively slow. Building on a systematic review of existing research, this study conducts an in-depth analysis and finds that this is due not only to data scarcity or technical limitations, but more fundamentally to the lack of a structured representational approach that reconciles theoretical expressiveness with computational feasibility. Specifically, this challenge manifests in dilemmas in data standardization, obstacles to effective modeling, and limitations in domain adaptation. In response, the study proposes several key directions for future research. It aims to provide a reframing of key problems and a pathway for future development in legal argument mining, while leaving specific models and implementation schemes for further investigation.
FailureMem: A Failure-Aware Multimodal Framework for Autonomous Software Repair
Mar 18, 2026Multimodal Automated Program Repair (MAPR) extends traditional program repair by requiring models to jointly reason over source code, textual issue descriptions, and visual artifacts such as GUI screenshots. While recent LLM-based repair systems have shown promising results, existing approaches face several limitations: rigid workflow pipelines restrict exploration during debugging, visual reasoning is often performed over full-page screenshots without localized grounding, and failed repair attempts are rarely transformed into reusable knowledge. To address these challenges, we propose FailureMem, a multimodal repair framework that integrates three key mechanisms: a hybrid workflow-agent architecture that balances structured localization with flexible reasoning, active perception tools that enable region-level visual grounding, and a Failure Memory Bank that converts past repair attempts into reusable guidance. Experiments on SWE-bench Multimodal demonstrate FailureMem improves the resolved rate over GUIRepair by 3.7%.
RepoRepair: Leveraging Code Documentation for Repository-Level Automated Program Repair
Mar 01, 2026Automated program repair (APR) struggles to scale from isolated functions to full repositories, as it demands a global, task-aware understanding to locate necessary changes. Current methods, limited by context and reliant on shallow retrieval or costly agent iterations, falter on complex cross-file issues. To this end, we propose RepoRepair, a novel documentation-enhanced approach for repository-level fault localization and program repair. Our core insight is to leverage LLMs to generate hierarchical code documentation (from functions to files) for code repositories, creating structured semantic abstractions that enable LLMs to comprehend repository-level context and dependencies. Specifically, RepoRepair first employs a text-based LLM (e.g., DeepSeek-V3) to generate file/function-level code documentation for repositories, which serves as auxiliary knowledge to guide fault localization. Subsequently, based on the fault localization results and the issue description, a powerful LLM (e.g., Claude-4) attempts to repair the identified suspicious code snippets. Evaluated on SWE-bench Lite, RepoRepair achieves a 45.7% repair rate at a low cost of $0.44 per fix. On SWE-bench Multimodal, it delivers state-of-the-art performance with a 37.1% repair rate despite a higher cost of $0.56 per fix, demonstrating robust and cost-effective performance across diverse problem domains.
A Comprehensive Evaluation of Parameter-Efficient Fine-Tuning on Software Engineering Tasks
Dec 25, 2023Pre-trained models (PTMs) have achieved great success in various Software Engineering (SE) downstream tasks following the ``pre-train then fine-tune'' paradigm. As fully fine-tuning all parameters of PTMs can be computationally expensive, a widely used solution is parameter-efficient fine-tuning (PEFT), which freezes PTMs while introducing extra parameters. Though work has been done to test PEFT methods in the SE field, a comprehensive evaluation is still lacking. This paper aims to fill in this gap by evaluating the effectiveness of five PEFT methods on eight PTMs and four SE downstream tasks. For different tasks and PEFT methods, we seek answers to the following research questions: 1) Is it more effective to use PTMs trained specifically on source code, or is it sufficient to use PTMs trained on natural language text? 2) What is the impact of varying model sizes? 3) How does the model architecture affect the performance? Besides effectiveness, we also discuss the efficiency of PEFT methods, concerning the costs of required training time and GPU resource consumption. We hope that our findings can provide a deeper understanding of PEFT methods on various PTMs and SE downstream tasks. All the codes and data are available at \url{https://github.com/zwtnju/PEFT.git}.
Judicial Intelligent Assistant System: Extracting Events from Divorce Cases to Detect Disputes for the Judge
Mar 23, 2023In formal procedure of civil cases, the textual materials provided by different parties describe the development process of the cases. It is a difficult but necessary task to extract the key information for the cases from these textual materials and to clarify the dispute focus of related parties. Currently, officers read the materials manually and use methods, such as keyword searching and regular matching, to get the target information. These approaches are time-consuming and heavily depending on prior knowledge and carefulness of the officers. To assist the officers to enhance working efficiency and accuracy, we propose an approach to detect disputes from divorce cases based on a two-round-labeling event extracting technique in this paper. We implement the Judicial Intelligent Assistant (JIA) system according to the proposed approach to 1) automatically extract focus events from divorce case materials, 2) align events by identifying co-reference among them, and 3) detect conflicts among events brought by the plaintiff and the defendant. With the JIA system, it is convenient for judges to determine the disputed issues. Experimental results demonstrate that the proposed approach and system can obtain the focus of cases and detect conflicts more effectively and efficiently comparing with existing method.
CrossCodeBench: Benchmarking Cross-Task Generalization of Source Code Models
Feb 10, 2023



Despite the recent advances showing that a model pre-trained on large-scale source code data is able to gain appreciable generalization capability, it still requires a sizeable amount of data on the target task for fine-tuning. And the effectiveness of the model generalization is largely affected by the size and quality of the fine-tuning data, which is detrimental for target tasks with limited or unavailable resources. Therefore, cross-task generalization, with the goal of improving the generalization of the model to unseen tasks that have not been seen before, is of strong research and application value. In this paper, we propose a large-scale benchmark that includes 216 existing code-related tasks. Then, we annotate each task with the corresponding meta information such as task description and instruction, which contains detailed information about the task and a solution guide. This also helps us to easily create a wide variety of ``training/evaluation'' task splits to evaluate the various cross-task generalization capabilities of the model. Then we perform some preliminary experiments to demonstrate that the cross-task generalization of models can be largely improved by in-context learning methods such as few-shot learning and learning from task instructions, which shows the promising prospects of conducting cross-task learning research on our benchmark. We hope that the collection of the datasets and our benchmark will facilitate future work that is not limited to cross-task generalization.
Deep Learning Meets Software Engineering: A Survey on Pre-Trained Models of Source Code
May 24, 2022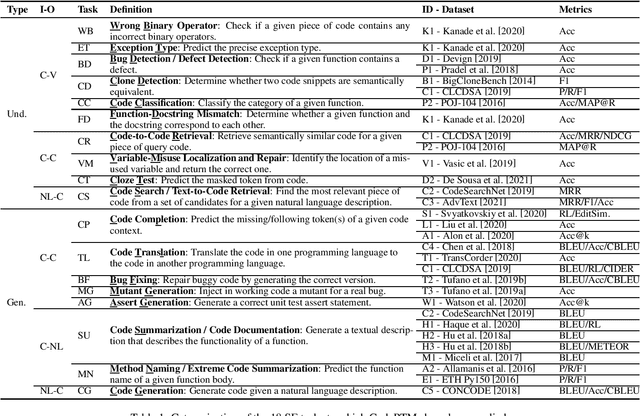

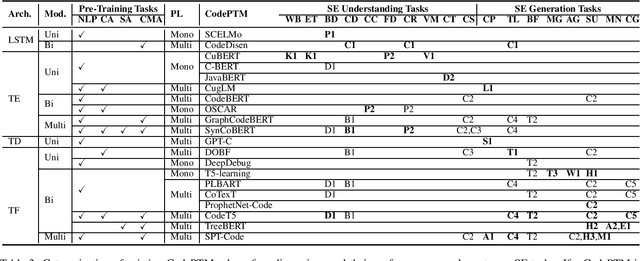
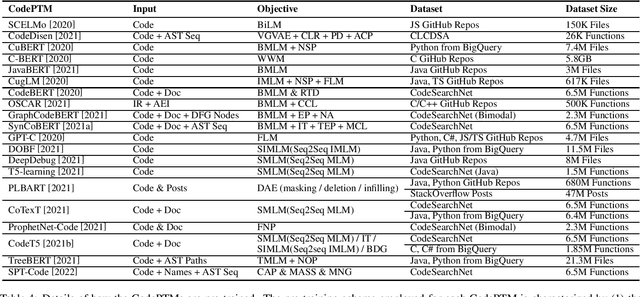
Recent years have seen the successful application of deep learning to software engineering (SE). In particular, the development and use of pre-trained models of source code has enabled state-of-the-art results to be achieved on a wide variety of SE tasks. This paper provides an overview of this rapidly advancing field of research and reflects on future research directions.
Neural Program Repair: Systems, Challenges and Solutions
Feb 22, 2022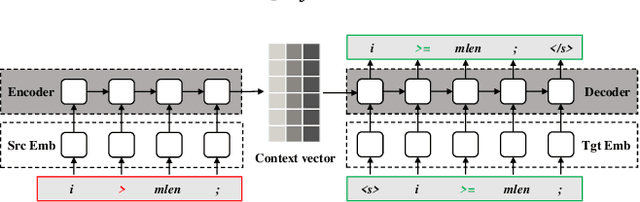
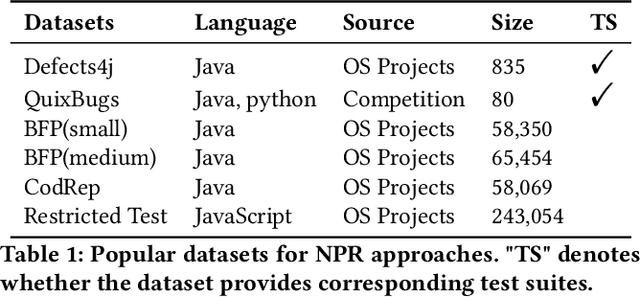
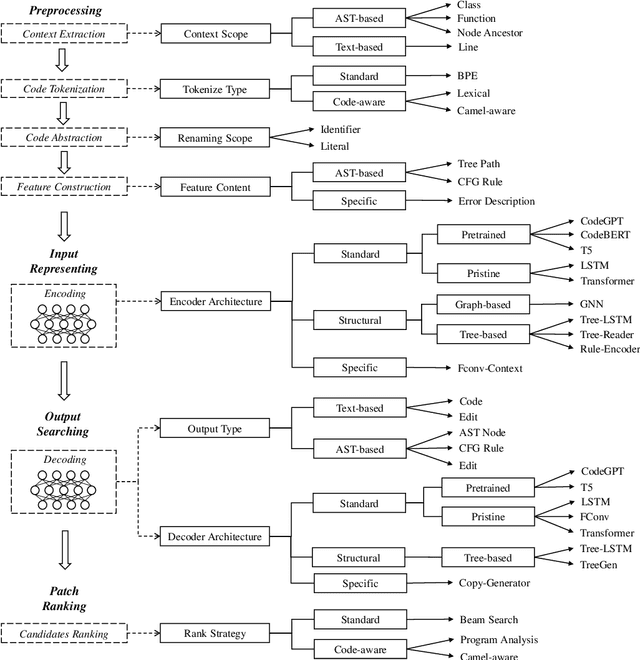
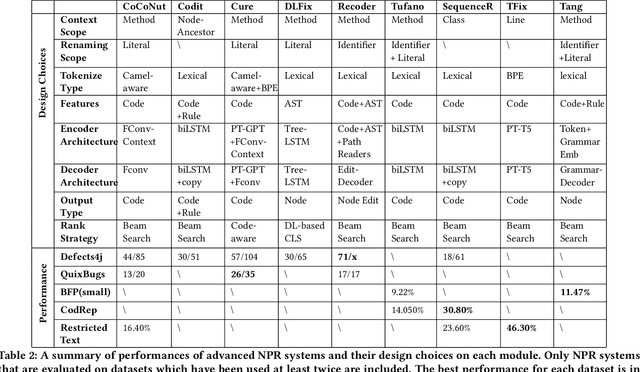
Automated Program Repair (APR) aims to automatically fix bugs in the source code. Recently, as advances in Deep Learning (DL) field, there is a rise of Neural Program Repair (NPR) studies, which formulate APR as a translation task from buggy code to correct code and adopt neural networks based on encoder-decoder architecture. Compared with other APR techniques, NPR approaches have a great advantage in applicability because they do not need any specification (i.e., a test suite). Although NPR has been a hot research direction, there isn't any overview on this field yet. In order to help interested readers understand architectures, challenges and corresponding solutions of existing NPR systems, we conduct a literature review on latest studies in this paper. We begin with introducing the background knowledge on this field. Next, to be understandable, we decompose the NPR procedure into a series of modules and explicate various design choices on each module. Furthermore, we identify several challenges and discuss the effect of existing solutions. Finally, we conclude and provide some promising directions for future research.
Dependency Learning for Legal Judgment Prediction with a Unified Text-to-Text Transformer
Dec 13, 2021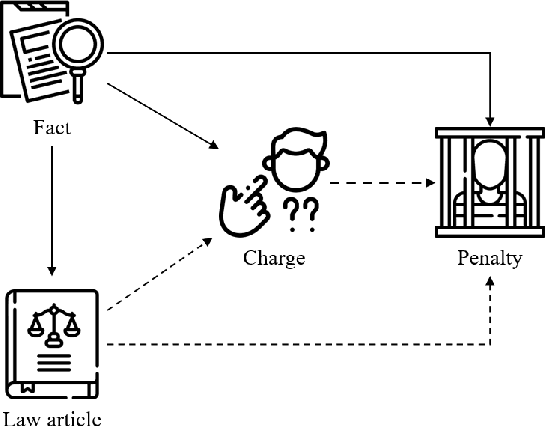


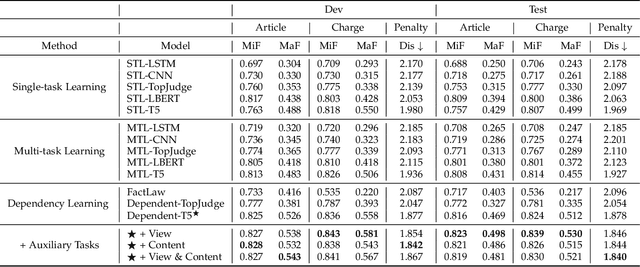
Given the fact of a case, Legal Judgment Prediction (LJP) involves a series of sub-tasks such as predicting violated law articles, charges and term of penalty. We propose leveraging a unified text-to-text Transformer for LJP, where the dependencies among sub-tasks can be naturally established within the auto-regressive decoder. Compared with previous works, it has three advantages: (1) it fits in the pretraining pattern of masked language models, and thereby can benefit from the semantic prompts of each sub-task rather than treating them as atomic labels, (2) it utilizes a single unified architecture, enabling full parameter sharing across all sub-tasks, and (3) it can incorporate both classification and generative sub-tasks. We show that this unified transformer, albeit pretrained on general-domain text, outperforms pretrained models tailored specifically for the legal domain. Through an extensive set of experiments, we find that the best order to capture dependencies is different from human intuitions, and the most reasonable logical order for humans can be sub-optimal for the model. We further include two more auxiliary tasks: court view generation and article content prediction, showing they can not only improve the prediction accuracy, but also provide interpretable explanations for model outputs even when an error is made. With the best configuration, our model outperforms both previous SOTA and a single-tasked version of the unified transformer by a large margin.
AST-Transformer: Encoding Abstract Syntax Trees Efficiently for Code Summarization
Dec 02, 2021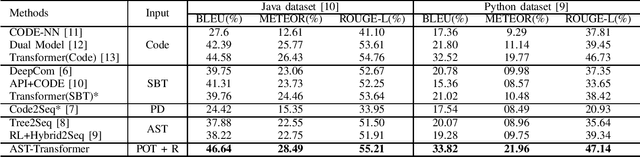
Code summarization aims to generate brief natural language descriptions for source code. As source code is highly structured and follows strict programming language grammars, its Abstract Syntax Tree (AST) is often leveraged to inform the encoder about the structural information. However, ASTs are usually much longer than the source code. Current approaches ignore the size limit and simply feed the whole linearized AST into the encoder. To address this problem, we propose AST-Transformer to efficiently encode tree-structured ASTs. Experiments show that AST-Transformer outperforms the state-of-arts by a substantial margin while being able to reduce $90\sim95\%$ of the computational complexity in the encoding process.