 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEmerson-Lei and Manna-Pnueli Games for LTLf+ and PPLTL+ Synthesis
Aug 20, 2025Recently, the Manna-Pnueli Hierarchy has been used to define the temporal logics LTLfp and PPLTLp, which allow to use finite-trace LTLf/PPLTL techniques in infinite-trace settings while achieving the expressiveness of full LTL. In this paper, we present the first actual solvers for reactive synthesis in these logics. These are based on games on graphs that leverage DFA-based techniques from LTLf/PPLTL to construct the game arena. We start with a symbolic solver based on Emerson-Lei games, which reduces lower-class properties (guarantee, safety) to higher ones (recurrence, persistence) before solving the game. We then introduce Manna-Pnueli games, which natively embed Manna-Pnueli objectives into the arena. These games are solved by composing solutions to a DAG of simpler Emerson-Lei games, resulting in a provably more efficient approach. We implemented the solvers and practically evaluated their performance on a range of representative formulas. The results show that Manna-Pnueli games often offer significant advantages, though not universally, indicating that combining both approaches could further enhance practical performance.
A Compositional Framework for On-the-Fly LTLf Synthesis
Aug 06, 2025Reactive synthesis from Linear Temporal Logic over finite traces (LTLf) can be reduced to a two-player game over a Deterministic Finite Automaton (DFA) of the LTLf specification. The primary challenge here is DFA construction, which is 2EXPTIME-complete in the worst case. Existing techniques either construct the DFA compositionally before solving the game, leveraging automata minimization to mitigate state-space explosion, or build the DFA incrementally during game solving to avoid full DFA construction. However, neither is dominant. In this paper, we introduce a compositional on-the-fly synthesis framework that integrates the strengths of both approaches, focusing on large conjunctions of smaller LTLf formulas common in practice. This framework applies composition during game solving instead of automata (game arena) construction. While composing all intermediate results may be necessary in the worst case, pruning these results simplifies subsequent compositions and enables early detection of unrealizability. Specifically, the framework allows two composition variants: pruning before composition to take full advantage of minimization or pruning during composition to guide on-the-fly synthesis. Compared to state-of-the-art synthesis solvers, our framework is able to solve a notable number of instances that other solvers cannot handle. A detailed analysis shows that both composition variants have unique merits.
LTLf Adaptive Synthesis for Multi-Tier Goals in Nondeterministic Domains
Apr 29, 2025

We study a variant of LTLf synthesis that synthesizes adaptive strategies for achieving a multi-tier goal, consisting of multiple increasingly challenging LTLf objectives in nondeterministic planning domains. Adaptive strategies are strategies that at any point of their execution (i) enforce the satisfaction of as many objectives as possible in the multi-tier goal, and (ii) exploit possible cooperation from the environment to satisfy as many as possible of the remaining ones. This happens dynamically: if the environment cooperates (ii) and an objective becomes enforceable (i), then our strategies will enforce it. We provide a game-theoretic technique to compute adaptive strategies that is sound and complete. Notably, our technique is polynomial, in fact quadratic, in the number of objectives. In other words, it handles multi-tier goals with only a minor overhead compared to standard LTLf synthesis.
On-the-fly Synthesis for LTL over Finite Traces: An Efficient Approach that Counts
Aug 14, 2024



We present an on-the-fly synthesis framework for Linear Temporal Logic over finite traces (LTLf) based on top-down deterministic automata construction. Existing approaches rely on constructing a complete Deterministic Finite Automaton (DFA) corresponding to the LTLf specification, a process with doubly exponential complexity relative to the formula size in the worst case. In this case, the synthesis procedure cannot be conducted until the entire DFA is constructed. This inefficiency is the main bottleneck of existing approaches. To address this challenge, we first present a method for converting LTLf into Transition-based DFA (TDFA) by directly leveraging LTLf semantics, incorporating intermediate results as direct components of the final automaton to enable parallelized synthesis and automata construction. We then explore the relationship between LTLf synthesis and TDFA games and subsequently develop an algorithm for performing LTLf synthesis using on-the-fly TDFA game solving. This algorithm traverses the state space in a global forward manner combined with a local backward method, along with the detection of strongly connected components. Moreover, we introduce two optimization techniques -- model-guided synthesis and state entailment -- to enhance the practical efficiency of our approach. Experimental results demonstrate that our on-the-fly approach achieves the best performance on the tested benchmarks and effectively complements existing tools and approaches.
The Trembling-Hand Problem for LTLf Planning
Apr 24, 2024



Consider an agent acting to achieve its temporal goal, but with a "trembling hand". In this case, the agent may mistakenly instruct, with a certain (typically small) probability, actions that are not intended due to faults or imprecision in its action selection mechanism, thereby leading to possible goal failure. We study the trembling-hand problem in the context of reasoning about actions and planning for temporally extended goals expressed in Linear Temporal Logic on finite traces (LTLf), where we want to synthesize a strategy (aka plan) that maximizes the probability of satisfying the LTLf goal in spite of the trembling hand. We consider both deterministic and nondeterministic (adversarial) domains. We propose solution techniques for both cases by relying respectively on Markov Decision Processes and on Markov Decision Processes with Set-valued Transitions with LTLf objectives, where the set-valued probabilistic transitions capture both the nondeterminism from the environment and the possible action instruction errors from the agent. We formally show the correctness of our solution techniques and demonstrate their effectiveness experimentally through a proof-of-concept implementation.
LTLf Best-Effort Synthesis in Nondeterministic Planning Domains
Aug 29, 2023



We study best-effort strategies (aka plans) in fully observable nondeterministic domains (FOND) for goals expressed in Linear Temporal Logic on Finite Traces (LTLf). The notion of best-effort strategy has been introduced to also deal with the scenario when no agent strategy exists that fulfills the goal against every possible nondeterministic environment reaction. Such strategies fulfill the goal if possible, and do their best to do so otherwise. We present a game-theoretic technique for synthesizing best-effort strategies that exploit the specificity of nondeterministic planning domains. We formally show its correctness and demonstrate its effectiveness experimentally, exhibiting a much greater scalability with respect to a direct best-effort synthesis approach based on re-expressing the planning domain as generic environment specifications.
Symbolic LTLf Best-Effort Synthesis
Aug 29, 2023



We consider an agent acting to fulfil tasks in a nondeterministic environment. When a strategy that fulfills the task regardless of how the environment acts does not exist, the agent should at least avoid adopting strategies that prevent from fulfilling its task. Best-effort synthesis captures this intuition. In this paper, we devise and compare various symbolic approaches for best-effort synthesis in Linear Temporal Logic on finite traces (LTLf). These approaches are based on the same basic components, however they change in how these components are combined, and this has a significant impact on the performance of the approaches as confirmed by our empirical evaluations.
LTLf Synthesis Under Environment Specifications for Reachability and Safety Properties
Aug 29, 2023In this paper, we study LTLf synthesis under environment specifications for arbitrary reachability and safety properties. We consider both kinds of properties for both agent tasks and environment specifications, providing a complete landscape of synthesis algorithms. For each case, we devise a specific algorithm (optimal wrt complexity of the problem) and prove its correctness. The algorithms combine common building blocks in different ways. While some cases are already studied in literature others are studied here for the first time.
Act for Your Duties but Maintain Your Rights
Feb 07, 2023Most of the synthesis literature has focused on studying how to synthesize a strategy to fulfill a task. This task is a duty for the agent. In this paper, we argue that intelligent agents should also be equipped with rights, that is, tasks that the agent itself can choose to fulfill (e.g., the right of recharging the battery). The agent should be able to maintain these rights while acting for its duties. We study this issue in the context of LTLf synthesis: we give duties and rights in terms of LTLf specifications, and synthesize a suitable strategy to achieve the duties that can be modified on-the-fly to achieve also the rights, if the agent chooses to do so. We show that handling rights does not make synthesis substantially more difficult, although it requires a more sophisticated solution concept than standard LTLf synthesis. We also extend our results to the case in which further duties and rights are given to the agent while already executing.
Mimicking Behaviors in Separated Domains
May 18, 2022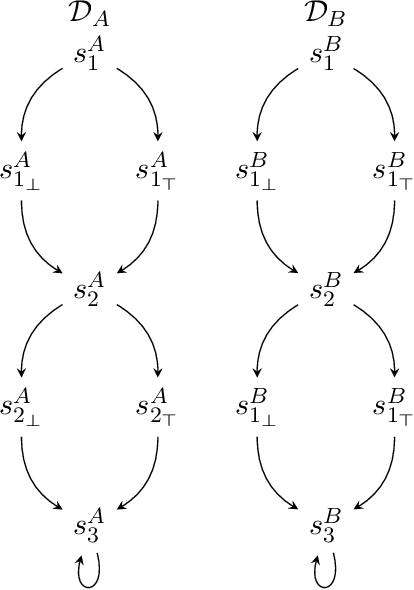
Devising a strategy to make a system mimicking behaviors from another system is a problem that naturally arises in many areas of Computer Science. In this work, we interpret this problem in the context of intelligent agents, from the perspective of LTLf, a formalism commonly used in AI for expressing finite-trace properties. Our model consists of two separated dynamic domains, D_A and D_B, and an LTLf specification that formalizes the notion of mimicking by mapping properties on behaviors (traces) of D_A into properties on behaviors of D_B. The goal is to synthesize a strategy that step-by-step maps every behavior of D_A into a behavior of D_B so that the specification is met. We consider several forms of mapping specifications, ranging from simple ones to full LTLf, and for each we study synthesis algorithms and computational properties.