 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProbing Inter-modality: Visual Parsing with Self-Attention for Vision-Language Pre-training
Jun 28, 2021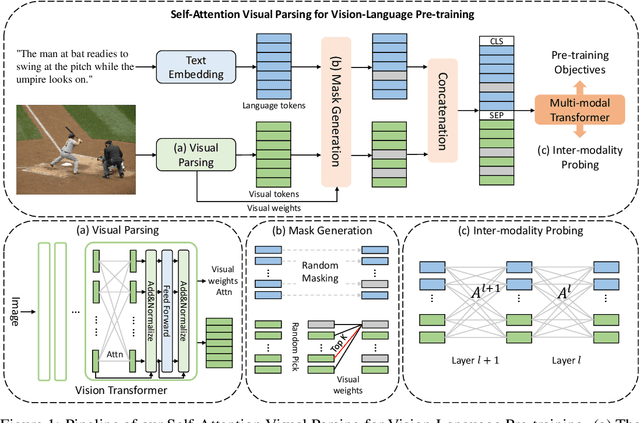

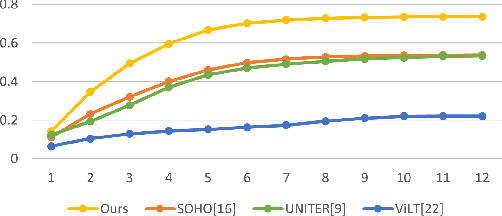
Vision-Language Pre-training (VLP) aims to learn multi-modal representations from image-text pairs and serves for downstream vision-language tasks in a fine-tuning fashion. The dominant VLP models adopt a CNN-Transformer architecture, which embeds images with a CNN, and then aligns images and text with a Transformer. Visual relationship between visual contents plays an important role in image understanding and is the basic for inter-modal alignment learning. However, CNNs have limitations in visual relation learning due to local receptive field's weakness in modeling long-range dependencies. Thus the two objectives of learning visual relation and inter-modal alignment are encapsulated in the same Transformer network. Such design might restrict the inter-modal alignment learning in the Transformer by ignoring the specialized characteristic of each objective. To tackle this, we propose a fully Transformer visual embedding for VLP to better learn visual relation and further promote inter-modal alignment. Specifically, we propose a metric named Inter-Modality Flow (IMF) to measure the interaction between vision and language modalities (i.e., inter-modality). We also design a novel masking optimization mechanism named Masked Feature Regression (MFR) in Transformer to further promote the inter-modality learning. To the best of our knowledge, this is the first study to explore the benefit of Transformer for visual feature learning in VLP. We verify our method on a wide range of vision-language tasks, including Image-Text Retrieval, Visual Question Answering (VQA), Visual Entailment and Visual Reasoning. Our approach not only outperforms the state-of-the-art VLP performance, but also shows benefits on the IMF metric.
LightTrack: Finding Lightweight Neural Networks for Object Tracking via One-Shot Architecture Search
Apr 29, 2021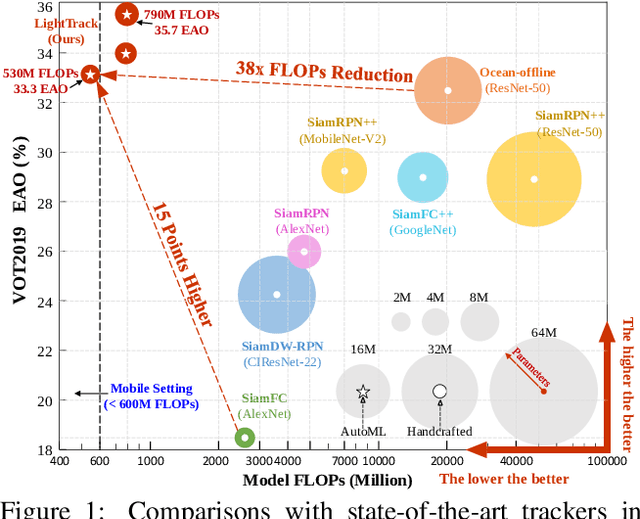
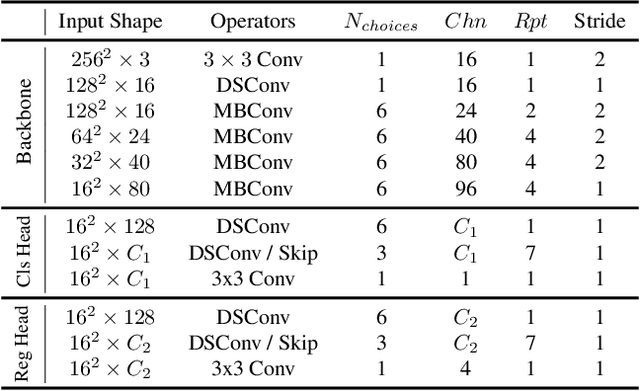
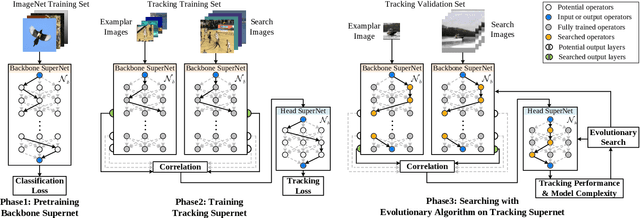

Object tracking has achieved significant progress over the past few years. However, state-of-the-art trackers become increasingly heavy and expensive, which limits their deployments in resource-constrained applications. In this work, we present LightTrack, which uses neural architecture search (NAS) to design more lightweight and efficient object trackers. Comprehensive experiments show that our LightTrack is effective. It can find trackers that achieve superior performance compared to handcrafted SOTA trackers, such as SiamRPN++ and Ocean, while using much fewer model Flops and parameters. Moreover, when deployed on resource-constrained mobile chipsets, the discovered trackers run much faster. For example, on Snapdragon 845 Adreno GPU, LightTrack runs $12\times$ faster than Ocean, while using $13\times$ fewer parameters and $38\times$ fewer Flops. Such improvements might narrow the gap between academic models and industrial deployments in object tracking task. LightTrack is released at https://github.com/researchmm/LightTrack.
Seeing Out of tHe bOx: End-to-End Pre-training for Vision-Language Representation Learning
Apr 08, 2021
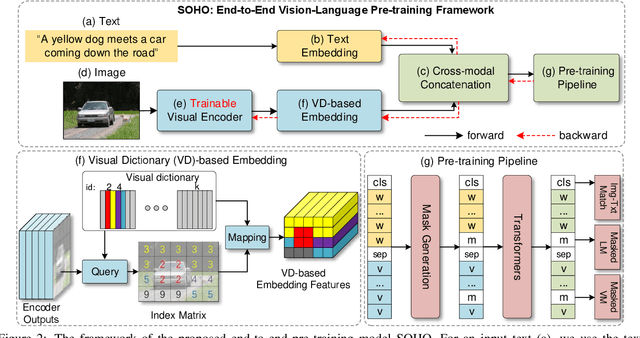
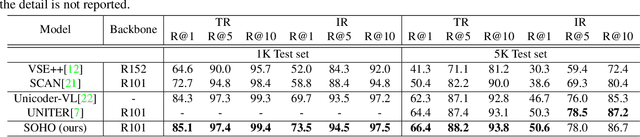
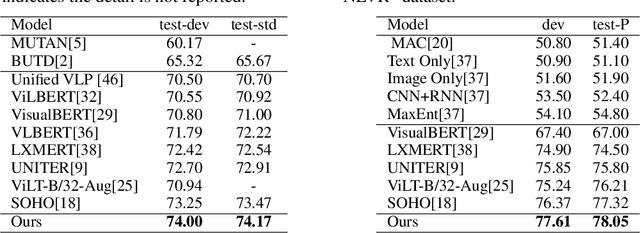
We study joint learning of Convolutional Neural Network (CNN) and Transformer for vision-language pre-training (VLPT) which aims to learn cross-modal alignments from millions of image-text pairs. State-of-the-art approaches extract salient image regions and align regions with words step-by-step. As region-based visual features usually represent parts of an image, it is challenging for existing vision-language models to fully understand the semantics from paired natural languages. In this paper, we propose SOHO to "See Out of tHe bOx" that takes a whole image as input, and learns vision-language representation in an end-to-end manner. SOHO does not require bounding box annotations which enables inference 10 times faster than region-based approaches. In particular, SOHO learns to extract comprehensive yet compact image features through a visual dictionary (VD) that facilitates cross-modal understanding. VD is designed to represent consistent visual abstractions of similar semantics. It is updated on-the-fly and utilized in our proposed pre-training task Masked Visual Modeling (MVM). We conduct experiments on four well-established vision-language tasks by following standard VLPT settings. In particular, SOHO achieves absolute gains of 2.0% R@1 score on MSCOCO text retrieval 5k test split, 1.5% accuracy on NLVR$^2$ test-P split, 6.7% accuracy on SNLI-VE test split, respectively.
3D Human Body Reshaping with Anthropometric Modeling
Apr 05, 2021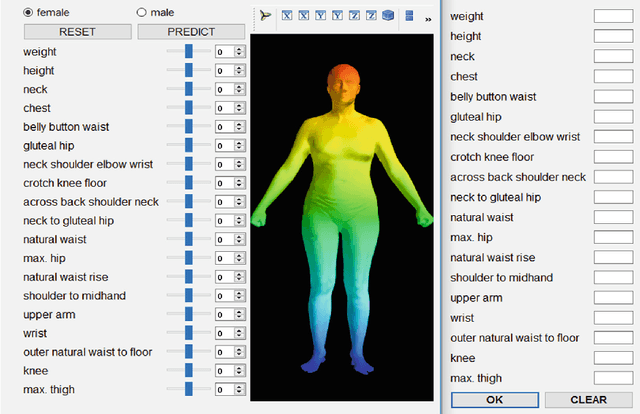
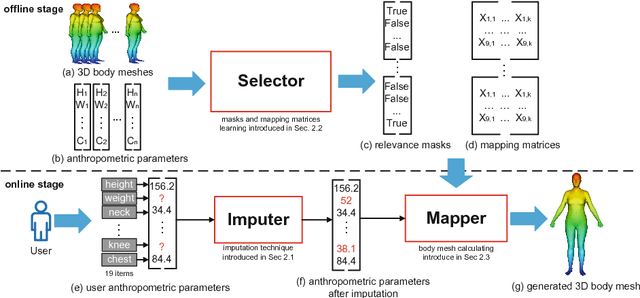
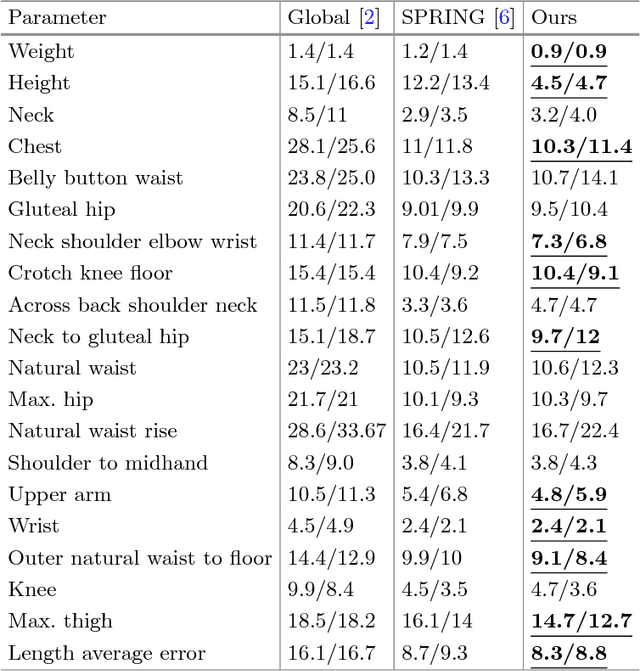
Reshaping accurate and realistic 3D human bodies from anthropometric parameters (e.g., height, chest size, etc.) poses a fundamental challenge for person identification, online shopping and virtual reality. Existing approaches for creating such 3D shapes often suffer from complex measurement by range cameras or high-end scanners, which either involve heavy expense cost or result in low quality. However, these high-quality equipments limit existing approaches in real applications, because the equipments are not easily accessible for common users. In this paper, we have designed a 3D human body reshaping system by proposing a novel feature-selection-based local mapping technique, which enables automatic anthropometric parameter modeling for each body facet. Note that the proposed approach can leverage limited anthropometric parameters (i.e., 3-5 measurements) as input, which avoids complex measurement, and thus better user-friendly experience can be achieved in real scenarios. Specifically, the proposed reshaping model consists of three steps. First, we calculate full-body anthropometric parameters from limited user inputs by imputation technique, and thus essential anthropometric parameters for 3D body reshaping can be obtained. Second, we select the most relevant anthropometric parameters for each facet by adopting relevance masks, which are learned offline by the proposed local mapping technique. Third, we generate the 3D body meshes by mapping matrices, which are learned by linear regression from the selected parameters to mesh-based body representation. We conduct experiments by anthropomorphic evaluation and a user study from 68 volunteers. Experiments show the superior results of the proposed system in terms of mean reconstruction error against the state-of-the-art approaches.
* ICIMCS 2017(oral). The final publication is available at Springer via https://doi.org/10.1007/978-981-10-8530-7_10
Aggregated Contextual Transformations for High-Resolution Image Inpainting
Apr 03, 2021
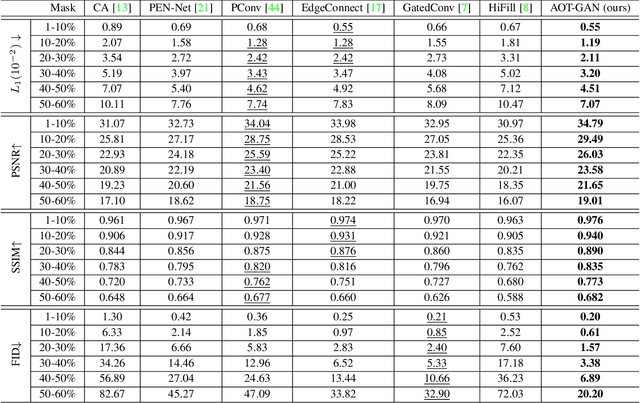
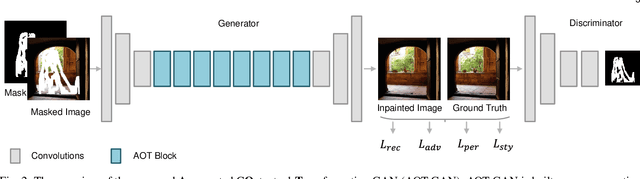

State-of-the-art image inpainting approaches can suffer from generating distorted structures and blurry textures in high-resolution images (e.g., 512x512). The challenges mainly drive from (1) image content reasoning from distant contexts, and (2) fine-grained texture synthesis for a large missing region. To overcome these two challenges, we propose an enhanced GAN-based model, named Aggregated COntextual-Transformation GAN (AOT-GAN), for high-resolution image inpainting. Specifically, to enhance context reasoning, we construct the generator of AOT-GAN by stacking multiple layers of a proposed AOT block. The AOT blocks aggregate contextual transformations from various receptive fields, allowing to capture both informative distant image contexts and rich patterns of interest for context reasoning. For improving texture synthesis, we enhance the discriminator of AOT-GAN by training it with a tailored mask-prediction task. Such a training objective forces the discriminator to distinguish the detailed appearances of real and synthesized patches, and in turn, facilitates the generator to synthesize clear textures. Extensive comparisons on Places2, the most challenging benchmark with 1.8 million high-resolution images of 365 complex scenes, show that our model outperforms the state-of-the-art by a significant margin in terms of FID with 38.60% relative improvement. A user study including more than 30 subjects further validates the superiority of AOT-GAN. We further evaluate the proposed AOT-GAN in practical applications, e.g., logo removal, face editing, and object removal. Results show that our model achieves promising completions in the real world. We release code and models in https://github.com/researchmm/AOT-GAN-for-Inpainting.
One-Shot Neural Ensemble Architecture Search by Diversity-Guided Search Space Shrinking
Apr 01, 2021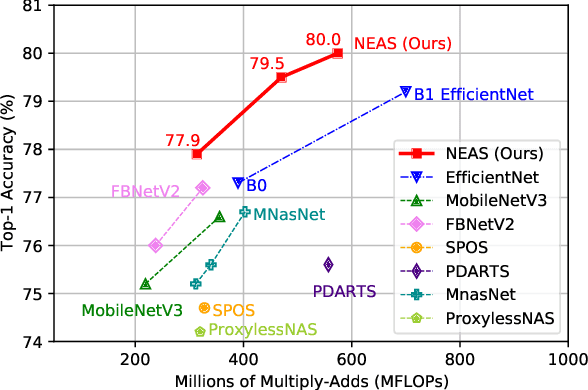
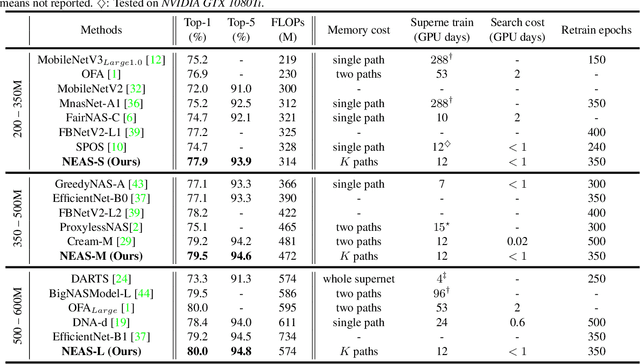
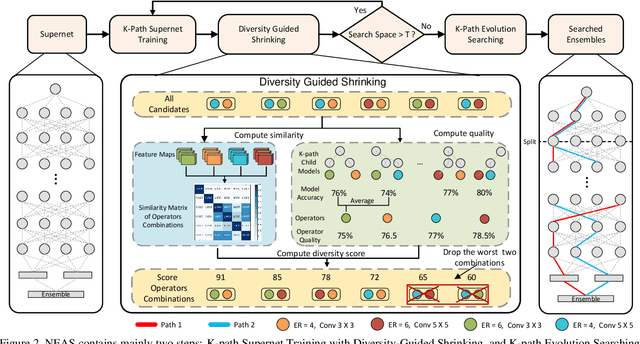
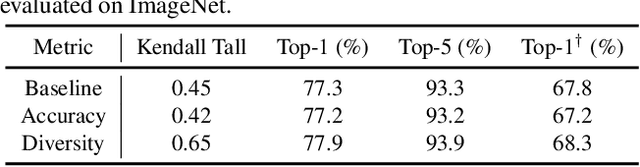
Despite remarkable progress achieved, most neural architecture search (NAS) methods focus on searching for one single accurate and robust architecture. To further build models with better generalization capability and performance, model ensemble is usually adopted and performs better than stand-alone models. Inspired by the merits of model ensemble, we propose to search for multiple diverse models simultaneously as an alternative way to find powerful models. Searching for ensembles is non-trivial and has two key challenges: enlarged search space and potentially more complexity for the searched model. In this paper, we propose a one-shot neural ensemble architecture search (NEAS) solution that addresses the two challenges. For the first challenge, we introduce a novel diversity-based metric to guide search space shrinking, considering both the potentiality and diversity of candidate operators. For the second challenge, we enable a new search dimension to learn layer sharing among different models for efficiency purposes. The experiments on ImageNet clearly demonstrate that our solution can improve the supernet's capacity of ranking ensemble architectures, and further lead to better search results. The discovered architectures achieve superior performance compared with state-of-the-arts such as MobileNetV3 and EfficientNet families under aligned settings. Moreover, we evaluate the generalization ability and robustness of our searched architecture on the COCO detection benchmark and achieve a 3.1% improvement on AP compared with MobileNetV3. Codes and models are available at https://github.com/researchmm/NEAS.
Learning Spatio-Temporal Transformer for Visual Tracking
Mar 31, 2021In this paper, we present a new tracking architecture with an encoder-decoder transformer as the key component. The encoder models the global spatio-temporal feature dependencies between target objects and search regions, while the decoder learns a query embedding to predict the spatial positions of the target objects. Our method casts object tracking as a direct bounding box prediction problem, without using any proposals or predefined anchors. With the encoder-decoder transformer, the prediction of objects just uses a simple fully-convolutional network, which estimates the corners of objects directly. The whole method is end-to-end, does not need any postprocessing steps such as cosine window and bounding box smoothing, thus largely simplifying existing tracking pipelines. The proposed tracker achieves state-of-the-art performance on five challenging short-term and long-term benchmarks, while running at real-time speed, being 6x faster than Siam R-CNN. Code and models are open-sourced at https://github.com/researchmm/Stark.
Multi-Scale 2D Temporal Adjacent Networks for Moment Localization with Natural Language
Dec 04, 2020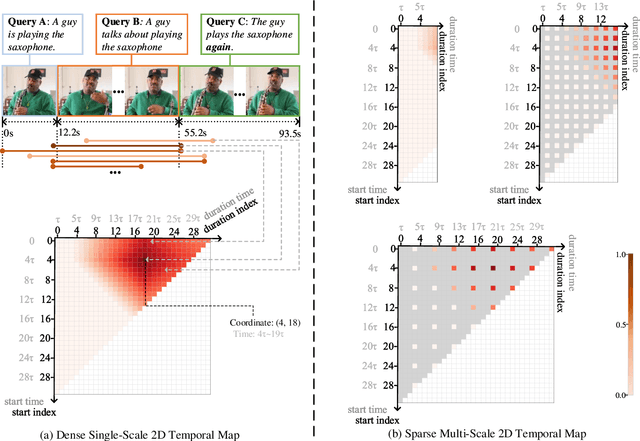
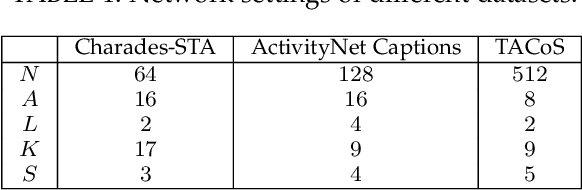
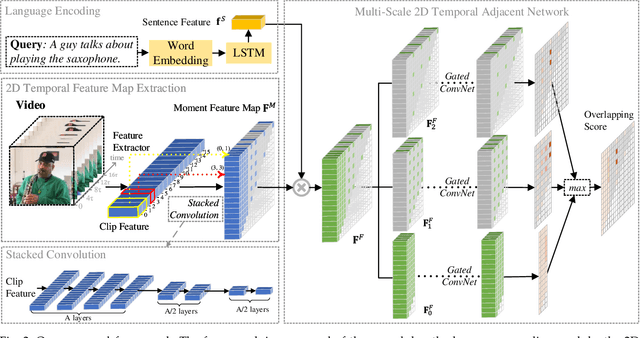
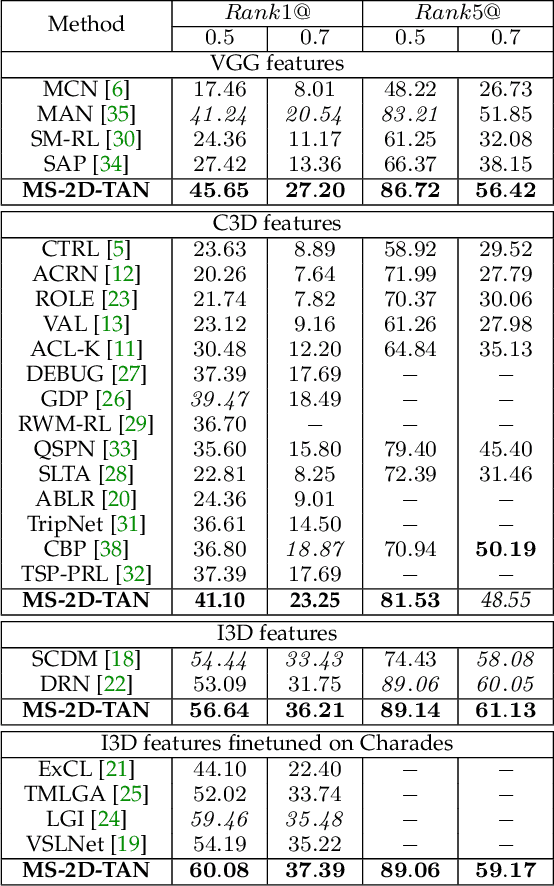
We address the problem of retrieving a specific moment from an untrimmed video by natural language. It is a challenging problem because a target moment may take place in the context of other temporal moments in the untrimmed video. Existing methods cannot tackle this challenge well since they do not fully consider the temporal contexts between temporal moments. In this paper, we model the temporal context between video moments by a set of predefined two-dimensional maps under different temporal scales. For each map, one dimension indicates the starting time of a moment and the other indicates the duration. These 2D temporal maps can cover diverse video moments with different lengths, while representing their adjacent contexts at different temporal scales. Based on the 2D temporal maps, we propose a Multi-Scale Temporal Adjacent Network (MS-2D-TAN), a single-shot framework for moment localization. It is capable of encoding the adjacent temporal contexts at each scale, while learning discriminative features for matching video moments with referring expressions. We evaluate the proposed MS-2D-TAN on three challenging benchmarks, i.e., Charades-STA, ActivityNet Captions, and TACoS, where our MS-2D-TAN outperforms the state of the art.
Cream of the Crop: Distilling Prioritized Paths For One-Shot Neural Architecture Search
Oct 29, 2020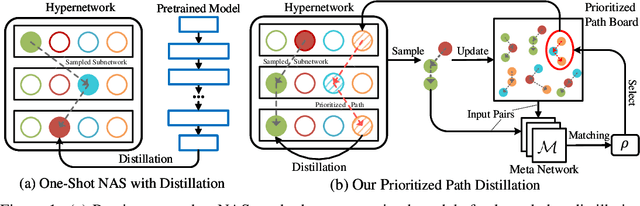

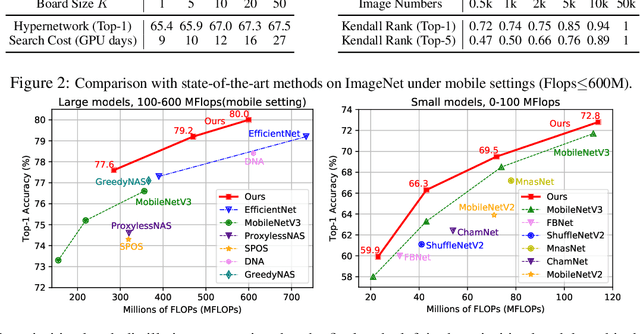
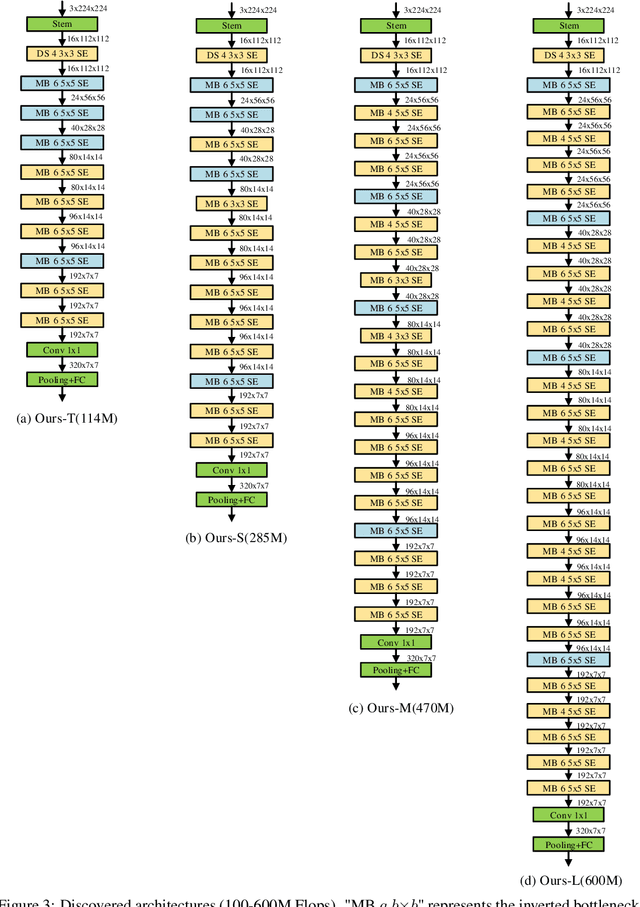
One-shot weight sharing methods have recently drawn great attention in neural architecture search due to high efficiency and competitive performance. However, weight sharing across models has an inherent deficiency, i.e., insufficient training of subnetworks in the hypernetwork. To alleviate this problem, we present a simple yet effective architecture distillation method. The central idea is that subnetworks can learn collaboratively and teach each other throughout the training process, aiming to boost the convergence of individual models. We introduce the concept of prioritized path, which refers to the architecture candidates exhibiting superior performance during training. Distilling knowledge from the prioritized paths is able to boost the training of subnetworks. Since the prioritized paths are changed on the fly depending on their performance and complexity, the final obtained paths are the cream of the crop. We directly select the most promising one from the prioritized paths as the final architecture, without using other complex search methods, such as reinforcement learning or evolution algorithms. The experiments on ImageNet verify such path distillation method can improve the convergence ratio and performance of the hypernetwork, as well as boosting the training of subnetworks. The discovered architectures achieve superior performance compared to the recent MobileNetV3 and EfficientNet families under aligned settings. Moreover, the experiments on object detection and more challenging search space show the generality and robustness of the proposed method. Code and models are available at https://github.com/microsoft/cream.git.
Revisiting Anchor Mechanisms for Temporal Action Localization
Aug 22, 2020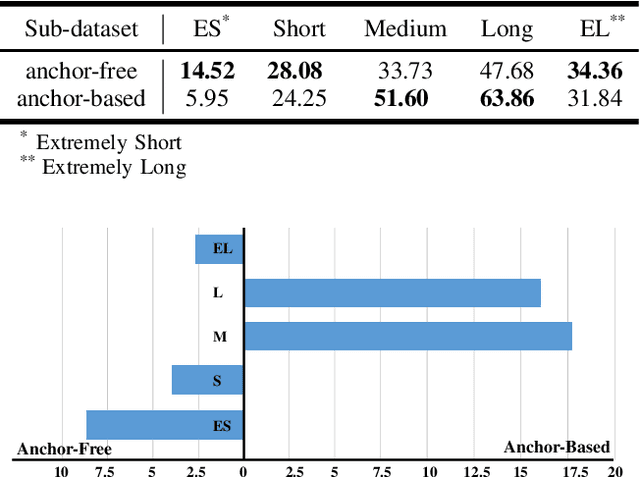
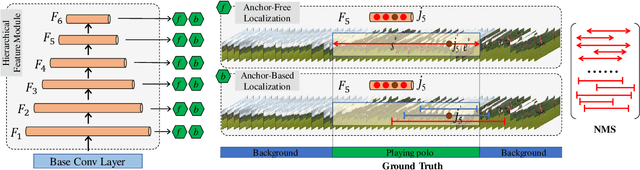
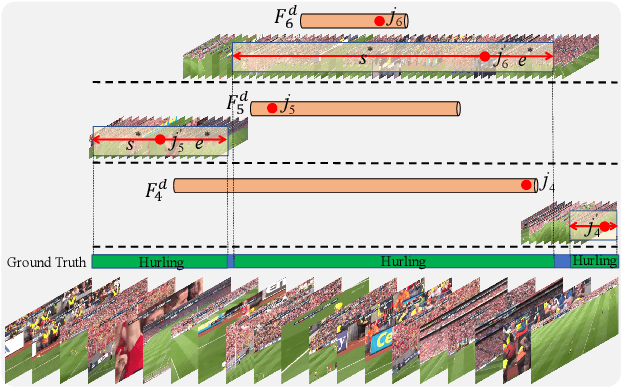
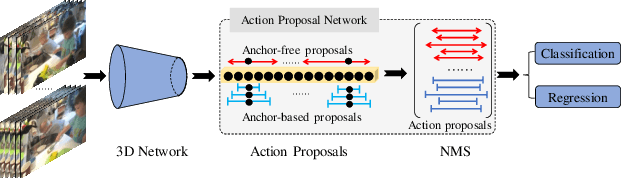
Most of the current action localization methods follow an anchor-based pipeline: depicting action instances by pre-defined anchors, learning to select the anchors closest to the ground truth, and predicting the confidence of anchors with refinements. Pre-defined anchors set prior about the location and duration for action instances, which facilitates the localization for common action instances but limits the flexibility for tackling action instances with drastic varieties, especially for extremely short or extremely long ones. To address this problem, this paper proposes a novel anchor-free action localization module that assists action localization by temporal points. Specifically, this module represents an action instance as a point with its distances to the starting boundary and ending boundary, alleviating the pre-defined anchor restrictions in terms of action localization and duration. The proposed anchor-free module is capable of predicting the action instances whose duration is either extremely short or extremely long. By combining the proposed anchor-free module with a conventional anchor-based module, we propose a novel action localization framework, called A2Net. The cooperation between anchor-free and anchor-based modules achieves superior performance to the state-of-the-art on THUMOS14 (45.5% vs. 42.8%). Furthermore, comprehensive experiments demonstrate the complementarity between the anchor-free and the anchor-based module, making A2Net simple but effective.