 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeElucidating the Exposure Bias in Diffusion Models
Sep 12, 2023Diffusion models have demonstrated impressive generative capabilities, but their 'exposure bias' problem, described as the input mismatch between training and sampling, lacks in-depth exploration. In this paper, we systematically investigate the exposure bias problem in diffusion models by first analytically modelling the sampling distribution, based on which we then attribute the prediction error at each sampling step as the root cause of the exposure bias issue. Furthermore, we discuss potential solutions to this issue and propose an intuitive metric for it. Along with the elucidation of exposure bias, we propose a simple, yet effective, training-free method called Epsilon Scaling to alleviate the exposure bias. We show that Epsilon Scaling explicitly moves the sampling trajectory closer to the vector field learned in the training phase by scaling down the network output (Epsilon), mitigating the input mismatch between training and sampling. Experiments on various diffusion frameworks (ADM, DDPM/DDIM, EDM, LDM), unconditional and conditional settings, and deterministic vs. stochastic sampling verify the effectiveness of our method. The code is available at https://github.com/forever208/ADM-ES; https://github.com/forever208/EDM-ES
Rank-Aware Negative Training for Semi-Supervised Text Classification
Jun 13, 2023Semi-supervised text classification-based paradigms (SSTC) typically employ the spirit of self-training. The key idea is to train a deep classifier on limited labeled texts and then iteratively predict the unlabeled texts as their pseudo-labels for further training. However, the performance is largely affected by the accuracy of pseudo-labels, which may not be significant in real-world scenarios. This paper presents a Rank-aware Negative Training (RNT) framework to address SSTC in learning with noisy label manner. To alleviate the noisy information, we adapt a reasoning with uncertainty-based approach to rank the unlabeled texts based on the evidential support received from the labeled texts. Moreover, we propose the use of negative training to train RNT based on the concept that ``the input instance does not belong to the complementary label''. A complementary label is randomly selected from all labels except the label on-target. Intuitively, the probability of a true label serving as a complementary label is low and thus provides less noisy information during the training, resulting in better performance on the test data. Finally, we evaluate the proposed solution on various text classification benchmark datasets. Our extensive experiments show that it consistently overcomes the state-of-the-art alternatives in most scenarios and achieves competitive performance in the others. The code of RNT is publicly available at:https://github.com/amurtadha/RNT.
Global Pointer: Novel Efficient Span-based Approach for Named Entity Recognition
Aug 05, 2022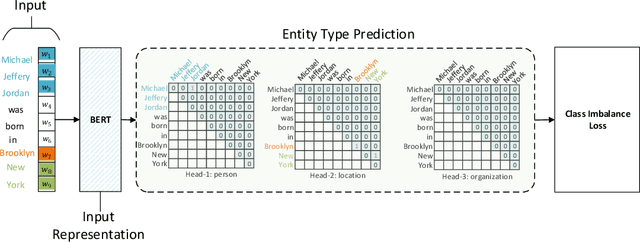
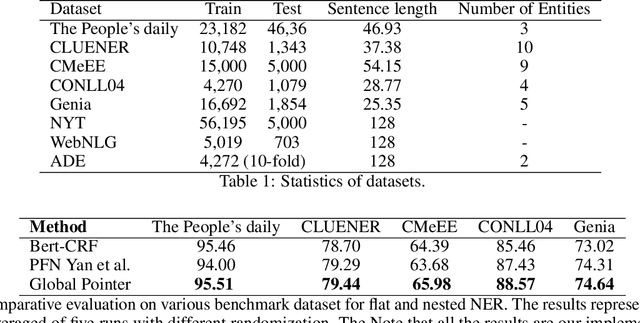
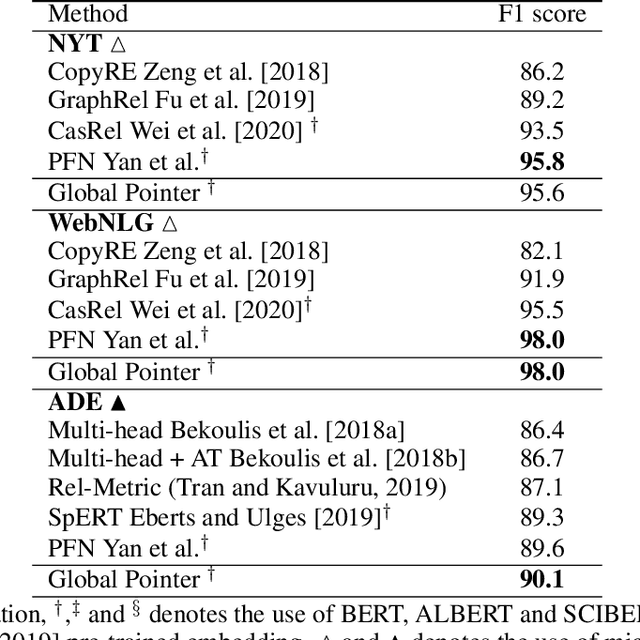

Named entity recognition (NER) task aims at identifying entities from a piece of text that belong to predefined semantic types such as person, location, organization, etc. The state-of-the-art solutions for flat entities NER commonly suffer from capturing the fine-grained semantic information in underlying texts. The existing span-based approaches overcome this limitation, but the computation time is still a concern. In this work, we propose a novel span-based NER framework, namely Global Pointer (GP), that leverages the relative positions through a multiplicative attention mechanism. The ultimate goal is to enable a global view that considers the beginning and the end positions to predict the entity. To this end, we design two modules to identify the head and the tail of a given entity to enable the inconsistency between the training and inference processes. Moreover, we introduce a novel classification loss function to address the imbalance label problem. In terms of parameters, we introduce a simple but effective approximate method to reduce the training parameters. We extensively evaluate GP on various benchmark datasets. Our extensive experiments demonstrate that GP can outperform the existing solution. Moreover, the experimental results show the efficacy of the introduced loss function compared to softmax and entropy alternatives.
ZLPR: A Novel Loss for Multi-label Classification
Aug 05, 2022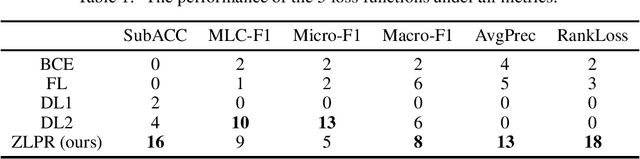
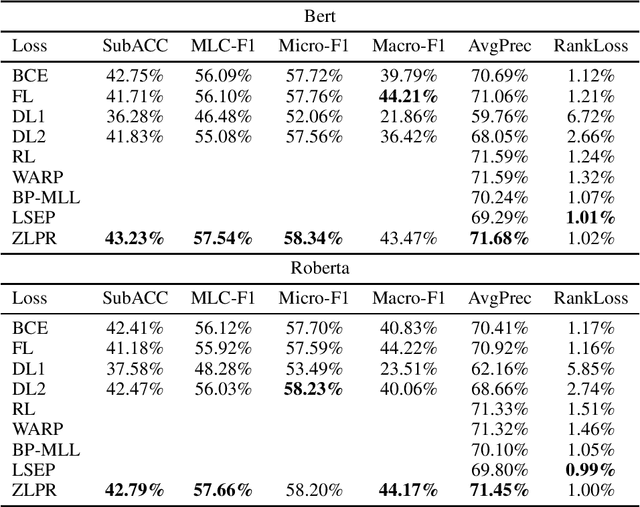
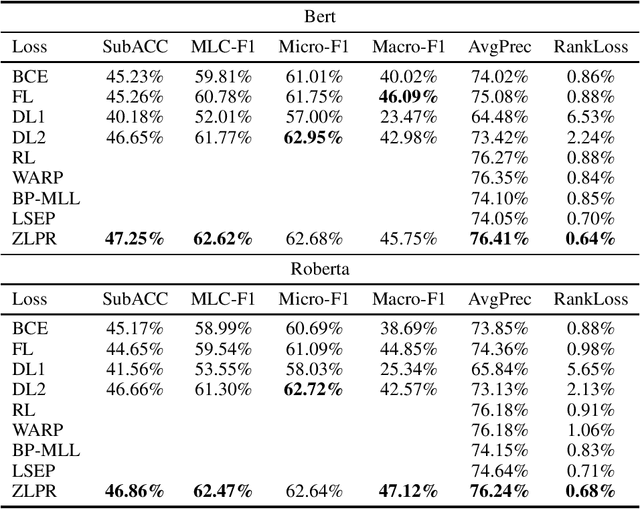
In the era of deep learning, loss functions determine the range of tasks available to models and algorithms. To support the application of deep learning in multi-label classification (MLC) tasks, we propose the ZLPR (zero-bounded log-sum-exp \& pairwise rank-based) loss in this paper. Compared to other rank-based losses for MLC, ZLPR can handel problems that the number of target labels is uncertain, which, in this point of view, makes it equally capable with the other two strategies often used in MLC, namely the binary relevance (BR) and the label powerset (LP). Additionally, ZLPR takes the corelation between labels into consideration, which makes it more comprehensive than the BR methods. In terms of computational complexity, ZLPR can compete with the BR methods because its prediction is also label-independent, which makes it take less time and memory than the LP methods. Our experiments demonstrate the effectiveness of ZLPR on multiple benchmark datasets and multiple evaluation metrics. Moreover, we propose the soft version and the corresponding KL-divergency calculation method of ZLPR, which makes it possible to apply some regularization tricks such as label smoothing to enhance the generalization of models.
BERT-ASC: Auxiliary-Sentence Construction for Implicit Aspect Learning in Sentiment Analysis
Mar 22, 2022
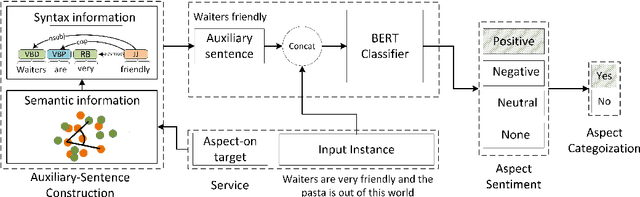
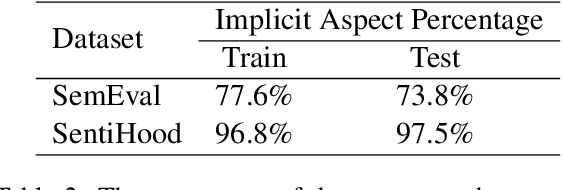

Aspect-based sentiment analysis (ABSA) task aims to associate a piece of text with a set of aspects and meanwhile infer their respective sentimental polarities. Up to now, the state-of-the-art approaches are built upon fine-tuning of various pre-trained language models. They commonly aim to learn the aspect-specific representation in the corpus. Unfortunately, the aspect is often expressed implicitly through a set of representatives and thus renders implicit mapping process unattainable unless sufficient labeled examples. In this paper, we propose to jointly address aspect categorization and aspect-based sentiment subtasks in a unified framework. Specifically, we first introduce a simple but effective mechanism that collaborates the semantic and syntactic information to construct auxiliary-sentences for the implicit aspect. Then, we encourage BERT to learn the aspect-specific representation in response to the automatically constructed auxiliary-sentence instead of the aspect itself. Finally, we empirically evaluate the performance of the proposed solution by a comparative study on real benchmark datasets for both ABSA and Targeted-ABSA tasks. Our extensive experiments show that it consistently achieves state-of-the-art performance in terms of aspect categorization and aspect-based sentiment across all datasets and the improvement margins are considerable.
Sparse-softmax: A Simpler and Faster Alternative Softmax Transformation
Dec 23, 2021
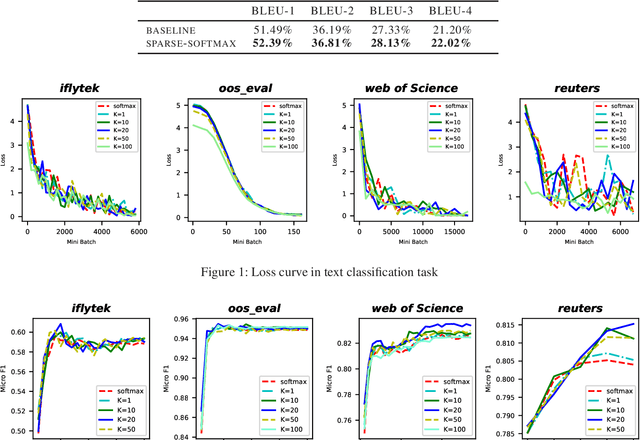
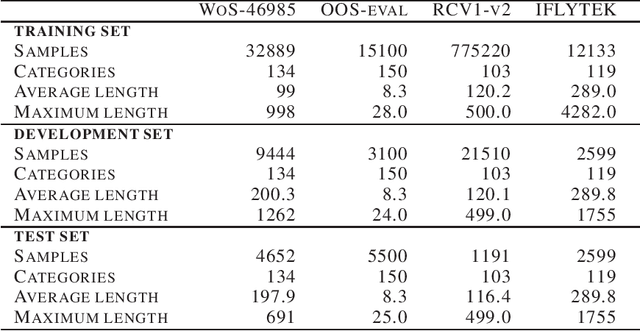
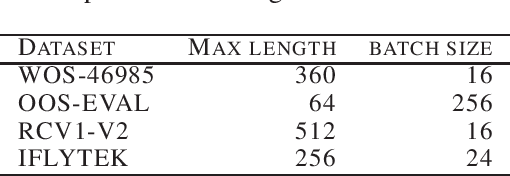
The softmax function is widely used in artificial neural networks for the multiclass classification problems, where the softmax transformation enforces the output to be positive and sum to one, and the corresponding loss function allows to use maximum likelihood principle to optimize the model. However, softmax leaves a large margin for loss function to conduct optimizing operation when it comes to high-dimensional classification, which results in low-performance to some extent. In this paper, we provide an empirical study on a simple and concise softmax variant, namely sparse-softmax, to alleviate the problem that occurred in traditional softmax in terms of high-dimensional classification problems. We evaluate our approach in several interdisciplinary tasks, the experimental results show that sparse-softmax is simpler, faster, and produces better results than the baseline models.
ZARTS: On Zero-order Optimization for Neural Architecture Search
Oct 10, 2021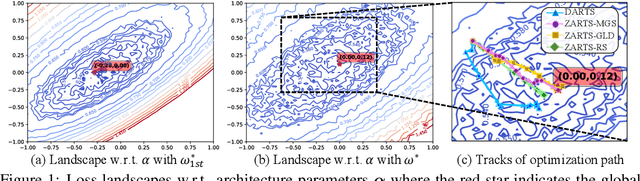

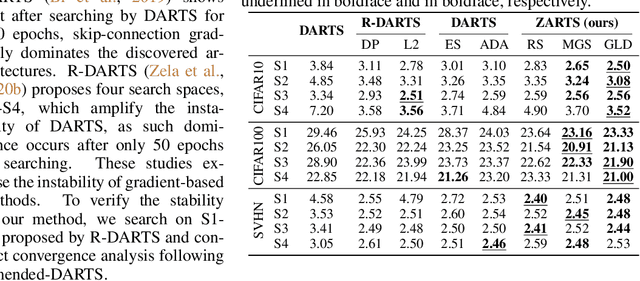
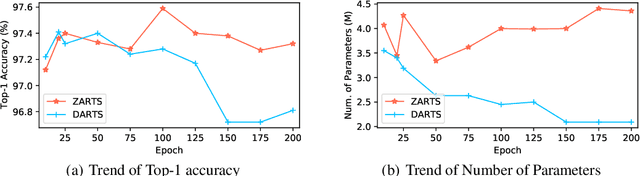
Differentiable architecture search (DARTS) has been a popular one-shot paradigm for NAS due to its high efficiency. It introduces trainable architecture parameters to represent the importance of candidate operations and proposes first/second-order approximation to estimate their gradients, making it possible to solve NAS by gradient descent algorithm. However, our in-depth empirical results show that the approximation will often distort the loss landscape, leading to the biased objective to optimize and in turn inaccurate gradient estimation for architecture parameters. This work turns to zero-order optimization and proposes a novel NAS scheme, called ZARTS, to search without enforcing the above approximation. Specifically, three representative zero-order optimization methods are introduced: RS, MGS, and GLD, among which MGS performs best by balancing the accuracy and speed. Moreover, we explore the connections between RS/MGS and gradient descent algorithm and show that our ZARTS can be seen as a robust gradient-free counterpart to DARTS. Extensive experiments on multiple datasets and search spaces show the remarkable performance of our method. In particular, results on 12 benchmarks verify the outstanding robustness of ZARTS, where the performance of DARTS collapses due to its known instability issue. Also, we search on the search space of DARTS to compare with peer methods, and our discovered architecture achieves 97.54% accuracy on CIFAR-10 and 75.7% top-1 accuracy on ImageNet, which are state-of-the-art performance.
BioCopy: A Plug-And-Play Span Copy Mechanism in Seq2Seq Models
Sep 26, 2021
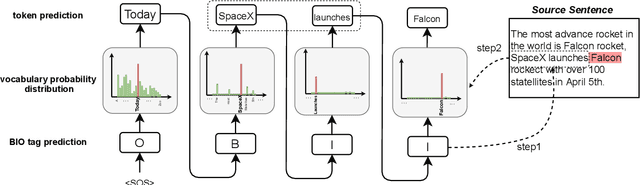
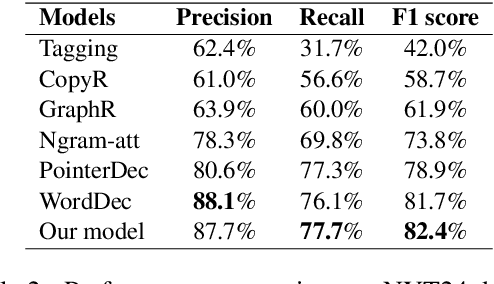
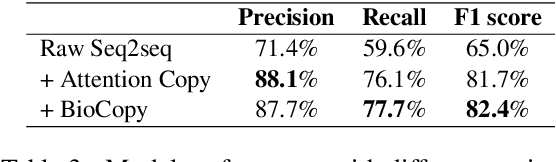
Copy mechanisms explicitly obtain unchanged tokens from the source (input) sequence to generate the target (output) sequence under the neural seq2seq framework. However, most of the existing copy mechanisms only consider single word copying from the source sentences, which results in losing essential tokens while copying long spans. In this work, we propose a plug-and-play architecture, namely BioCopy, to alleviate the problem aforementioned. Specifically, in the training stage, we construct a BIO tag for each token and train the original model with BIO tags jointly. In the inference stage, the model will firstly predict the BIO tag at each time step, then conduct different mask strategies based on the predicted BIO label to diminish the scope of the probability distributions over the vocabulary list. Experimental results on two separate generative tasks show that they all outperform the baseline models by adding our BioCopy to the original model structure.
RoFormer: Enhanced Transformer with Rotary Position Embedding
Apr 20, 2021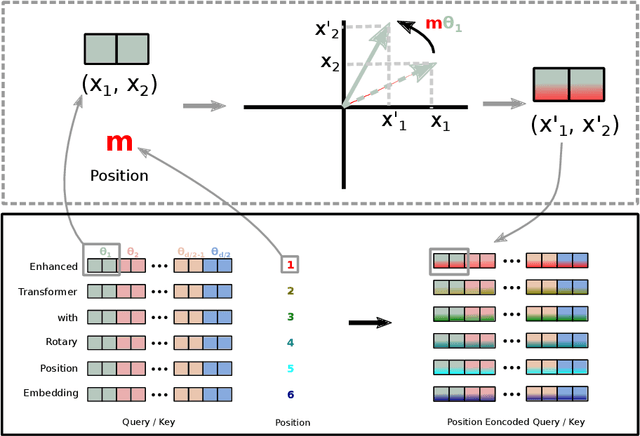
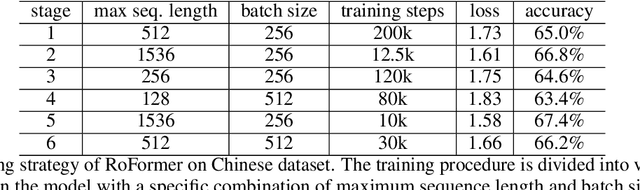
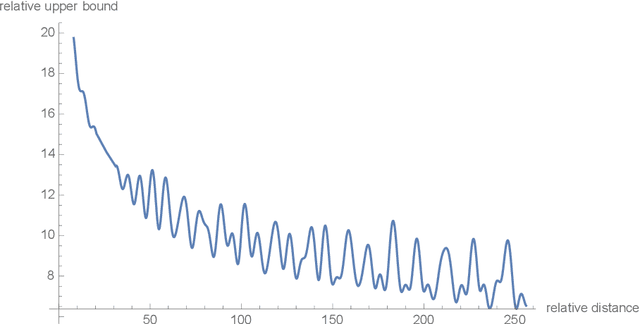
Position encoding in transformer architecture provides supervision for dependency modeling between elements at different positions in the sequence. We investigate various methods to encode positional information in transformer-based language models and propose a novel implementation named Rotary Position Embedding(RoPE). The proposed RoPE encodes absolute positional information with rotation matrix and naturally incorporates explicit relative position dependency in self-attention formulation. Notably, RoPE comes with valuable properties such as flexibility of being expand to any sequence lengths, decaying inter-token dependency with increasing relative distances, and capability of equipping the linear self-attention with relative position encoding. As a result, the enhanced transformer with rotary position embedding, or RoFormer, achieves superior performance in tasks with long texts. We release the theoretical analysis along with some preliminary experiment results on Chinese data. The undergoing experiment for English benchmark will soon be updated.
Whitening Sentence Representations for Better Semantics and Faster Retrieval
Mar 29, 2021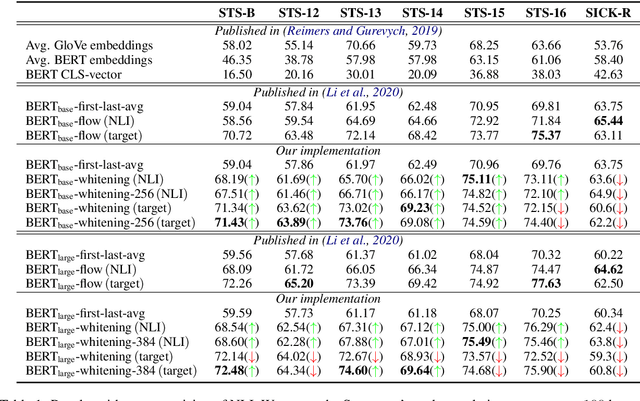
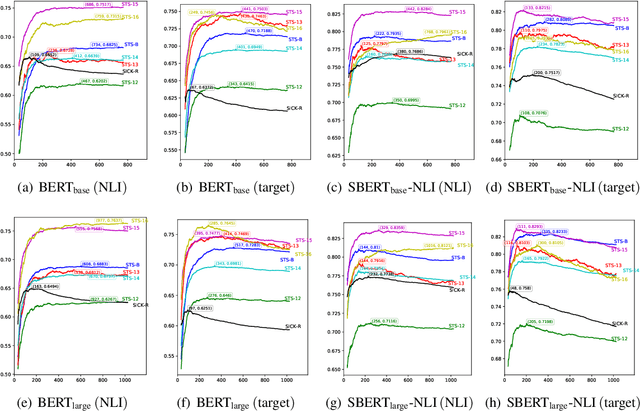
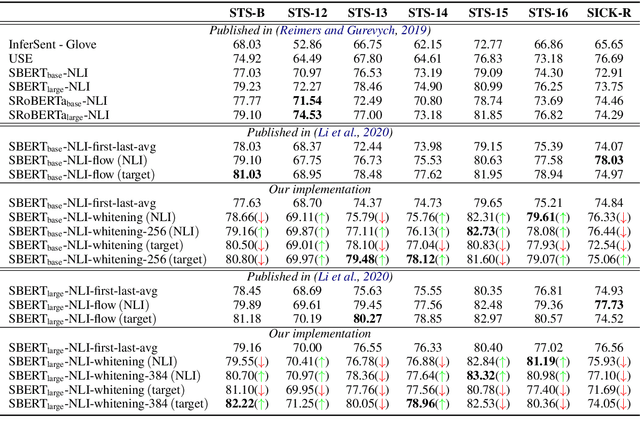
Pre-training models such as BERT have achieved great success in many natural language processing tasks. However, how to obtain better sentence representation through these pre-training models is still worthy to exploit. Previous work has shown that the anisotropy problem is an critical bottleneck for BERT-based sentence representation which hinders the model to fully utilize the underlying semantic features. Therefore, some attempts of boosting the isotropy of sentence distribution, such as flow-based model, have been applied to sentence representations and achieved some improvement. In this paper, we find that the whitening operation in traditional machine learning can similarly enhance the isotropy of sentence representations and achieve competitive results. Furthermore, the whitening technique is also capable of reducing the dimensionality of the sentence representation. Our experimental results show that it can not only achieve promising performance but also significantly reduce the storage cost and accelerate the model retrieval speed.