 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJiangmeng Li
Introducing Expertise Logic into Graph Representation Learning from A Causal Perspective
Jan 20, 2023
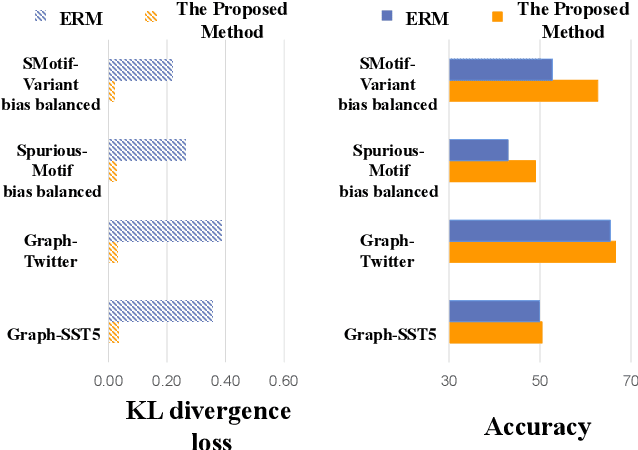
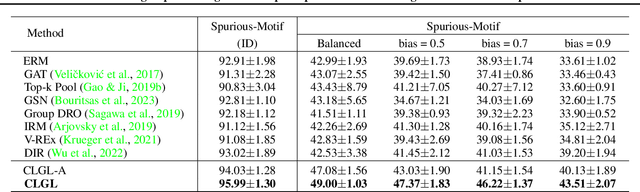
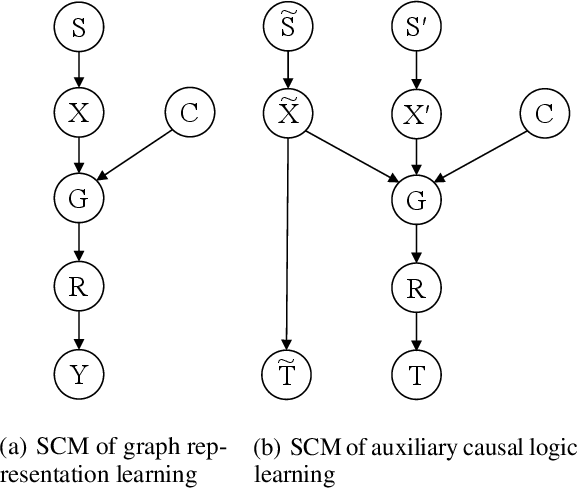
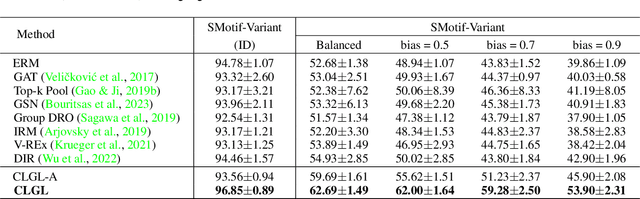
Benefiting from the injection of human prior knowledge, graphs, as derived discrete data, are semantically dense so that models can efficiently learn the semantic information from such data. Accordingly, graph neural networks (GNNs) indeed achieve impressive success in various fields. Revisiting the GNN learning paradigms, we discover that the relationship between human expertise and the knowledge modeled by GNNs still confuses researchers. To this end, we introduce motivating experiments and derive an empirical observation that the human expertise is gradually learned by the GNNs in general domains. By further observing the ramifications of introducing expertise logic into graph representation learning, we conclude that leading the GNNs to learn human expertise can improve the model performance. By exploring the intrinsic mechanism behind such observations, we elaborate the Structural Causal Model for the graph representation learning paradigm. Following the theoretical guidance, we innovatively introduce the auxiliary causal logic learning paradigm to improve the model to learn the expertise logic causally related to the graph representation learning task. In practice, the counterfactual technique is further performed to tackle the insufficient training issue during optimization. Plentiful experiments on the crafted and real-world domains support the consistent effectiveness of the proposed method.
MetaMask: Revisiting Dimensional Confounder for Self-Supervised Learning
Sep 16, 2022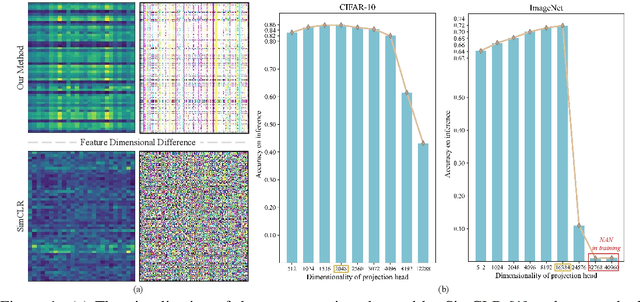
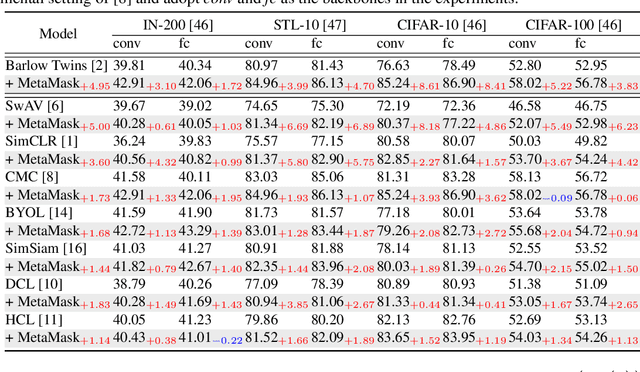
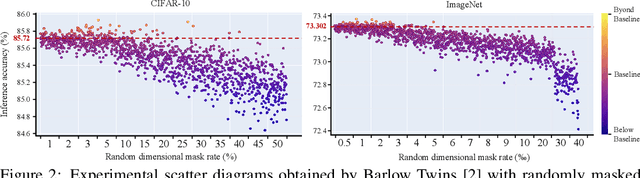
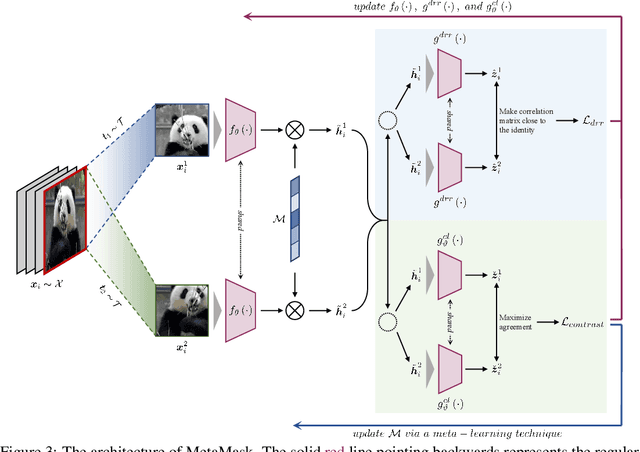
As a successful approach to self-supervised learning, contrastive learning aims to learn invariant information shared among distortions of the input sample. While contrastive learning has yielded continuous advancements in sampling strategy and architecture design, it still remains two persistent defects: the interference of task-irrelevant information and sample inefficiency, which are related to the recurring existence of trivial constant solutions. From the perspective of dimensional analysis, we find out that the dimensional redundancy and dimensional confounder are the intrinsic issues behind the phenomena, and provide experimental evidence to support our viewpoint. We further propose a simple yet effective approach MetaMask, short for the dimensional Mask learned by Meta-learning, to learn representations against dimensional redundancy and confounder. MetaMask adopts the redundancy-reduction technique to tackle the dimensional redundancy issue and innovatively introduces a dimensional mask to reduce the gradient effects of specific dimensions containing the confounder, which is trained by employing a meta-learning paradigm with the objective of improving the performance of masked representations on a typical self-supervised task. We provide solid theoretical analyses to prove MetaMask can obtain tighter risk bounds for downstream classification compared to typical contrastive methods. Empirically, our method achieves state-of-the-art performance on various benchmarks.
Modeling Multiple Views via Implicitly Preserving Global Consistency and Local Complementarity
Sep 16, 2022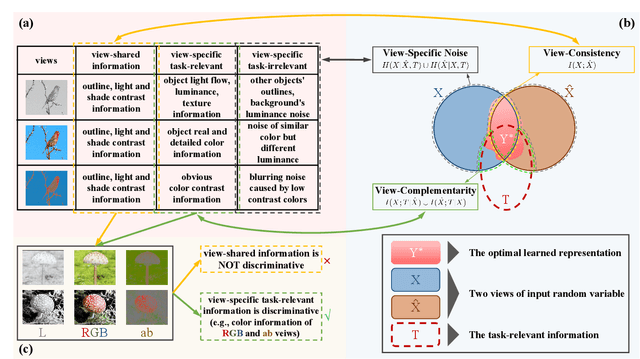
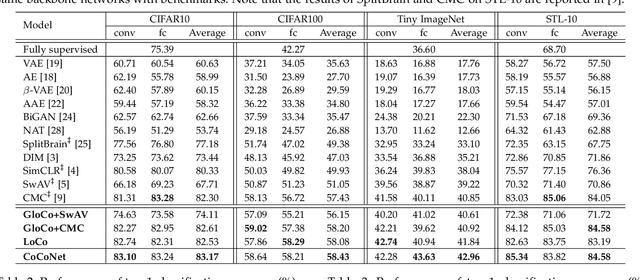
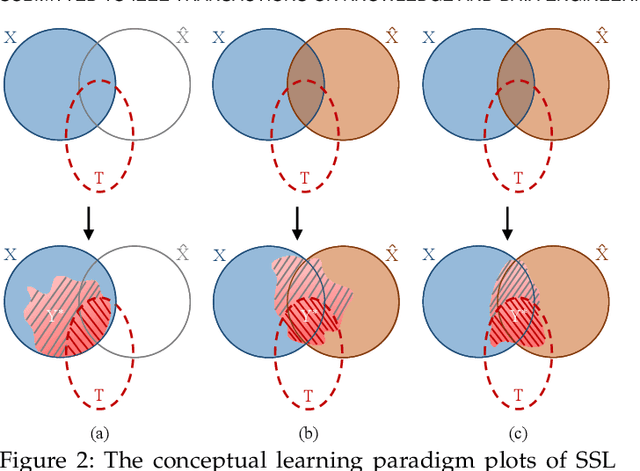
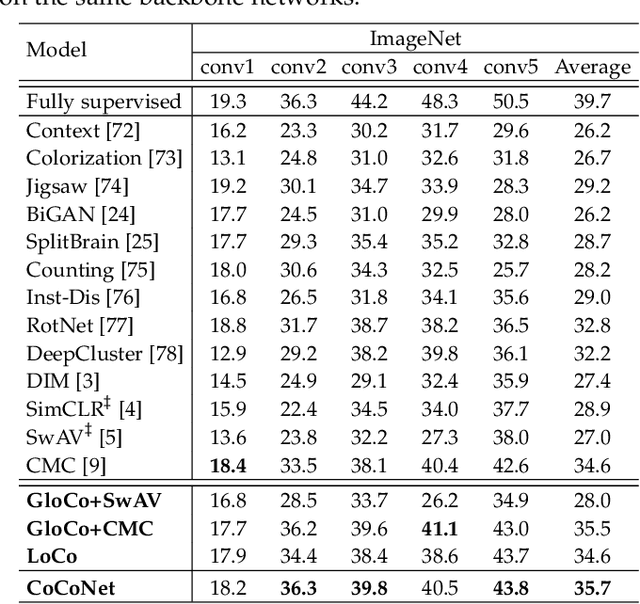
While self-supervised learning techniques are often used to mining implicit knowledge from unlabeled data via modeling multiple views, it is unclear how to perform effective representation learning in a complex and inconsistent context. To this end, we propose a methodology, specifically consistency and complementarity network (CoCoNet), which avails of strict global inter-view consistency and local cross-view complementarity preserving regularization to comprehensively learn representations from multiple views. On the global stage, we reckon that the crucial knowledge is implicitly shared among views, and enhancing the encoder to capture such knowledge from data can improve the discriminability of the learned representations. Hence, preserving the global consistency of multiple views ensures the acquisition of common knowledge. CoCoNet aligns the probabilistic distribution of views by utilizing an efficient discrepancy metric measurement based on the generalized sliced Wasserstein distance. Lastly on the local stage, we propose a heuristic complementarity-factor, which joints cross-view discriminative knowledge, and it guides the encoders to learn not only view-wise discriminability but also cross-view complementary information. Theoretically, we provide the information-theoretical-based analyses of our proposed CoCoNet. Empirically, to investigate the improvement gains of our approach, we conduct adequate experimental validations, which demonstrate that CoCoNet outperforms the state-of-the-art self-supervised methods by a significant margin proves that such implicit consistency and complementarity preserving regularization can enhance the discriminability of latent representations.
A Molecular Multimodal Foundation Model Associating Molecule Graphs with Natural Language
Sep 12, 2022
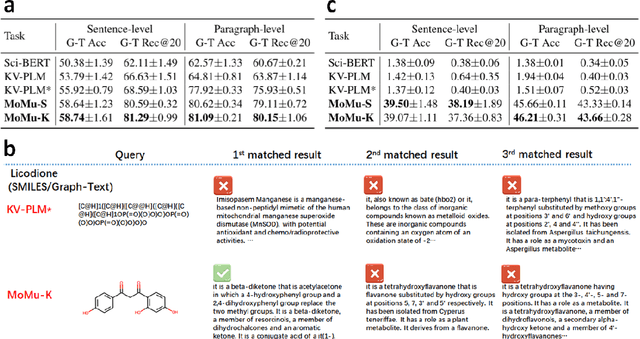
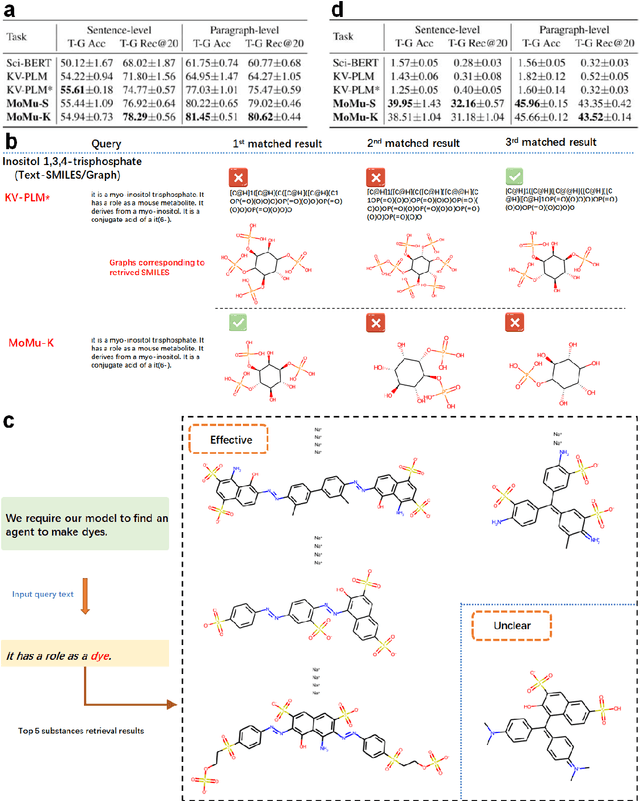
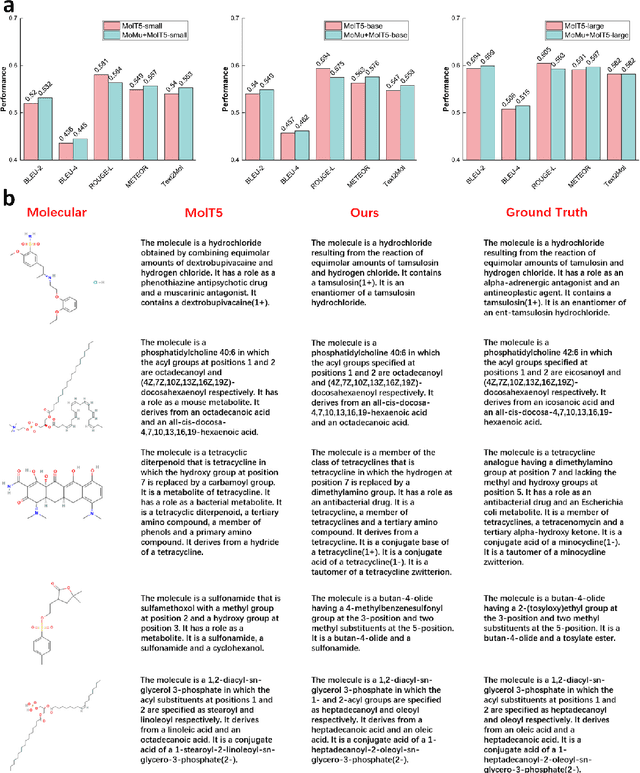
Although artificial intelligence (AI) has made significant progress in understanding molecules in a wide range of fields, existing models generally acquire the single cognitive ability from the single molecular modality. Since the hierarchy of molecular knowledge is profound, even humans learn from different modalities including both intuitive diagrams and professional texts to assist their understanding. Inspired by this, we propose a molecular multimodal foundation model which is pretrained from molecular graphs and their semantically related textual data (crawled from published Scientific Citation Index papers) via contrastive learning. This AI model represents a critical attempt that directly bridges molecular graphs and natural language. Importantly, through capturing the specific and complementary information of the two modalities, our proposed model can better grasp molecular expertise. Experimental results show that our model not only exhibits promising performance in cross-modal tasks such as cross-modal retrieval and molecule caption, but also enhances molecular property prediction and possesses capability to generate meaningful molecular graphs from natural language descriptions. We believe that our model would have a broad impact on AI-empowered fields across disciplines such as biology, chemistry, materials, environment, and medicine, among others.
Supporting Medical Relation Extraction via Causality-Pruned Semantic Dependency Forest
Aug 29, 2022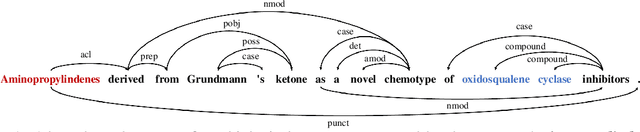

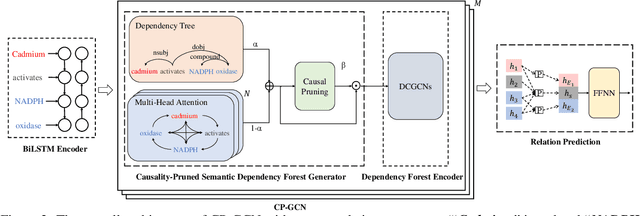
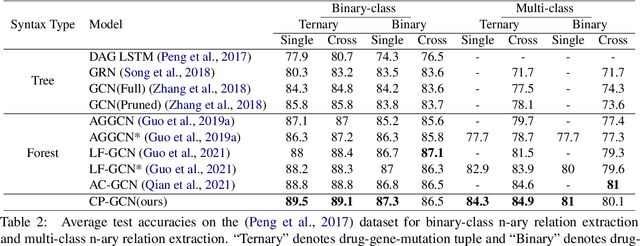
Medical Relation Extraction (MRE) task aims to extract relations between entities in medical texts. Traditional relation extraction methods achieve impressive success by exploring the syntactic information, e.g., dependency tree. However, the quality of the 1-best dependency tree for medical texts produced by an out-of-domain parser is relatively limited so that the performance of medical relation extraction method may degenerate. To this end, we propose a method to jointly model semantic and syntactic information from medical texts based on causal explanation theory. We generate dependency forests consisting of the semantic-embedded 1-best dependency tree. Then, a task-specific causal explainer is adopted to prune the dependency forests, which are further fed into a designed graph convolutional network to learn the corresponding representation for downstream task. Empirically, the various comparisons on benchmark medical datasets demonstrate the effectiveness of our model.
Disentangle and Remerge: Interventional Knowledge Distillation for Few-Shot Object Detection from A Conditional Causal Perspective
Aug 26, 2022
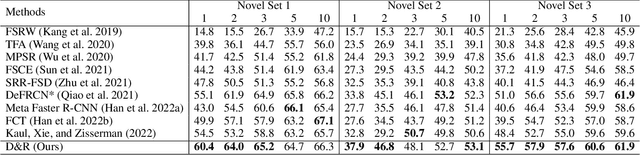
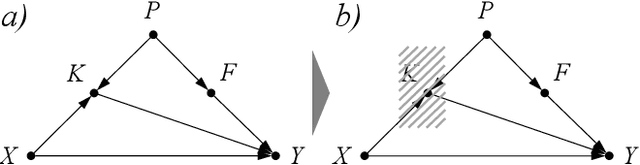
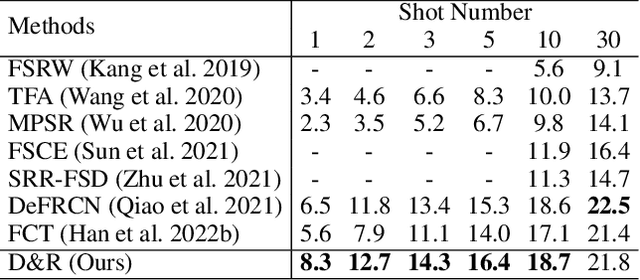
Few-shot learning models learn representations with limited human annotations, and such a learning paradigm demonstrates practicability in various tasks, e.g., image classification, object detection, etc. However, few-shot object detection methods suffer from an intrinsic defect that the limited training data makes the model cannot sufficiently explore semantic information. To tackle this, we introduce knowledge distillation to the few-shot object detection learning paradigm. We further run a motivating experiment, which demonstrates that in the process of knowledge distillation the empirical error of the teacher model degenerates the prediction performance of the few-shot object detection model, as the student. To understand the reasons behind this phenomenon, we revisit the learning paradigm of knowledge distillation on the few-shot object detection task from the causal theoretic standpoint, and accordingly, develop a Structural Causal Model. Following the theoretical guidance, we propose a backdoor adjustment-based knowledge distillation method for the few-shot object detection task, namely Disentangle and Remerge (D&R), to perform conditional causal intervention toward the corresponding Structural Causal Model. Theoretically, we provide an extended definition, i.e., general backdoor path, for the backdoor criterion, which can expand the theoretical application boundary of the backdoor criterion in specific cases. Empirically, the experiments on multiple benchmark datasets demonstrate that D&R can yield significant performance boosts in few-shot object detection.
Robust Causal Graph Representation Learning against Confounding Effects
Aug 18, 2022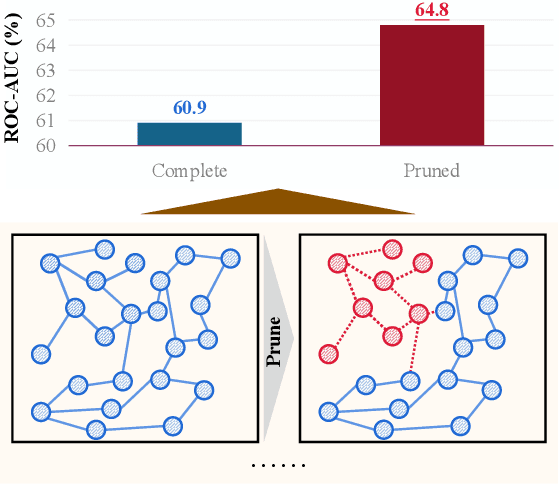
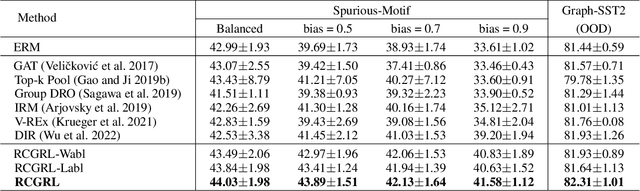
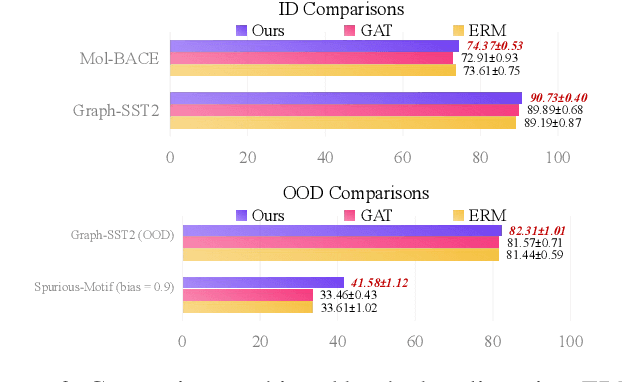
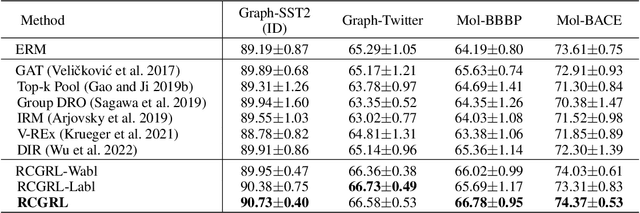
The prevailing graph neural network models have achieved significant progress in graph representation learning. However, in this paper, we uncover an ever-overlooked phenomenon: the pre-trained graph representation learning model tested with full graphs underperforms the model tested with well-pruned graphs. This observation reveals that there exist confounders in graphs, which may interfere with the model learning semantic information, and current graph representation learning methods have not eliminated their influence. To tackle this issue, we propose Robust Causal Graph Representation Learning (RCGRL) to learn robust graph representations against confounding effects. RCGRL introduces an active approach to generate instrumental variables under unconditional moment restrictions, which empowers the graph representation learning model to eliminate confounders, thereby capturing discriminative information that is causally related to downstream predictions. We offer theorems and proofs to guarantee the theoretical effectiveness of the proposed approach. Empirically, we conduct extensive experiments on a synthetic dataset and multiple benchmark datasets. The results demonstrate that compared with state-of-the-art methods, RCGRL achieves better prediction performance and generalization ability.
Interventional Contrastive Learning with Meta Semantic Regularizer
Jun 29, 2022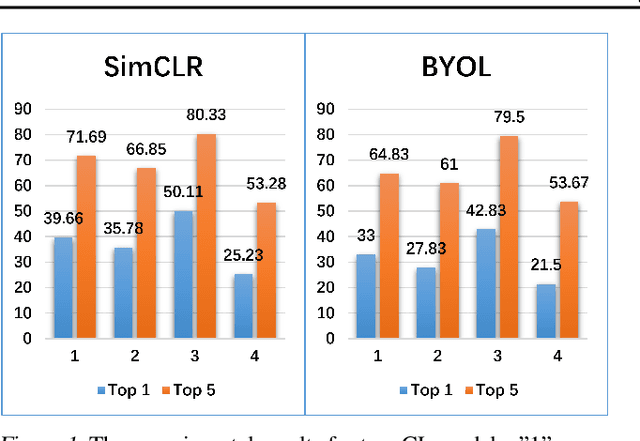
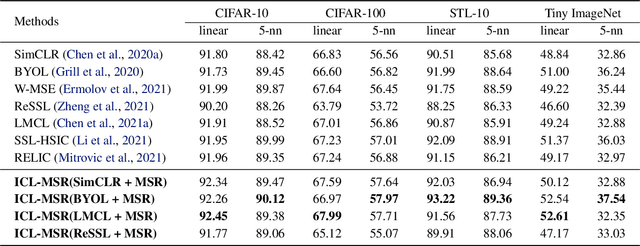
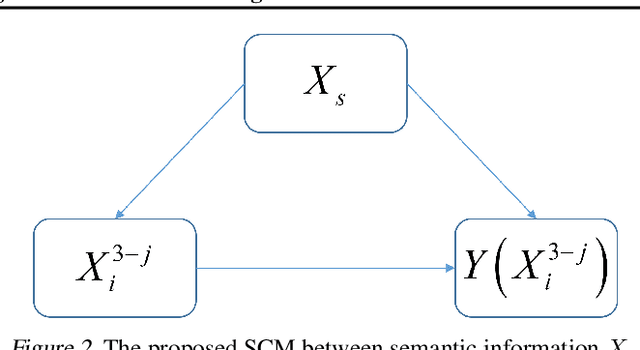
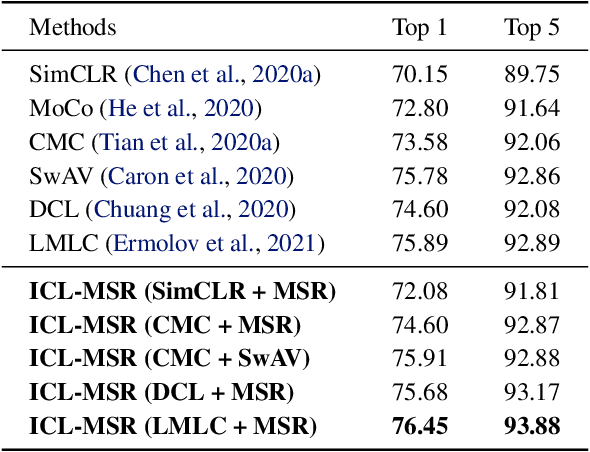
Contrastive learning (CL)-based self-supervised learning models learn visual representations in a pairwise manner. Although the prevailing CL model has achieved great progress, in this paper, we uncover an ever-overlooked phenomenon: When the CL model is trained with full images, the performance tested in full images is better than that in foreground areas; when the CL model is trained with foreground areas, the performance tested in full images is worse than that in foreground areas. This observation reveals that backgrounds in images may interfere with the model learning semantic information and their influence has not been fully eliminated. To tackle this issue, we build a Structural Causal Model (SCM) to model the background as a confounder. We propose a backdoor adjustment-based regularization method, namely Interventional Contrastive Learning with Meta Semantic Regularizer (ICL-MSR), to perform causal intervention towards the proposed SCM. ICL-MSR can be incorporated into any existing CL methods to alleviate background distractions from representation learning. Theoretically, we prove that ICL-MSR achieves a tighter error bound. Empirically, our experiments on multiple benchmark datasets demonstrate that ICL-MSR is able to improve the performances of different state-of-the-art CL methods.
Supporting Vision-Language Model Inference with Causality-pruning Knowledge Prompt
May 23, 2022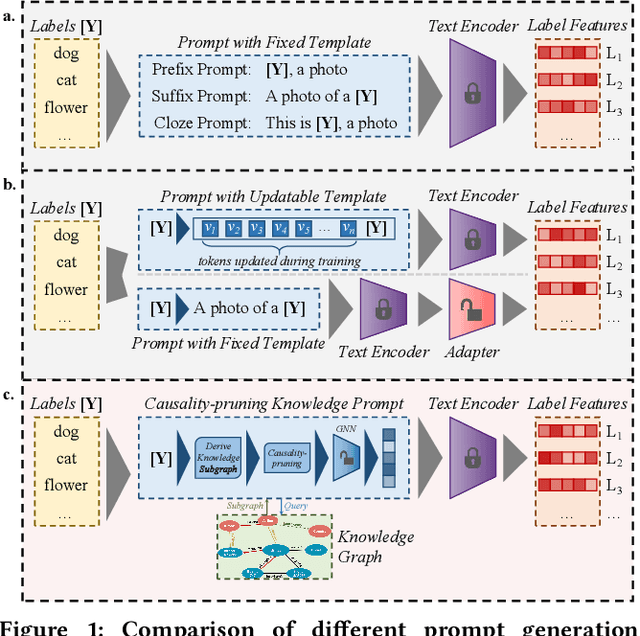
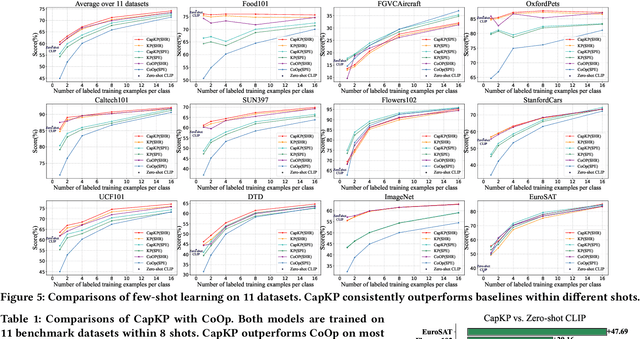
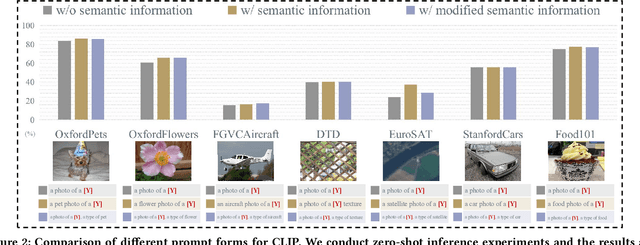
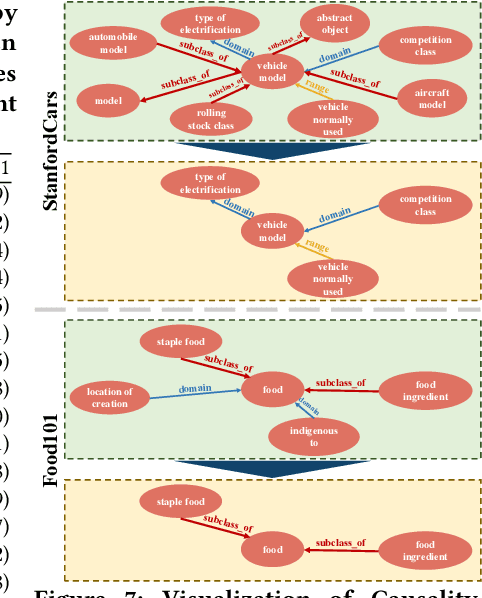
Vision-language models are pre-trained by aligning image-text pairs in a common space so that the models can deal with open-set visual concepts by learning semantic information from textual labels. To boost the transferability of these models on downstream tasks in a zero-shot manner, recent works explore generating fixed or learnable prompts, i.e., classification weights are synthesized from natural language describing task-relevant categories, to reduce the gap between tasks in the training and test phases. However, how and what prompts can improve inference performance remains unclear. In this paper, we explicitly provide exploration and clarify the importance of including semantic information in prompts, while existing prompt methods generate prompts without exploring the semantic information of textual labels. A challenging issue is that manually constructing prompts, with rich semantic information, requires domain expertise and is extremely time-consuming. To this end, we propose Causality-pruning Knowledge Prompt (CapKP) for adapting pre-trained vision-language models to downstream image recognition. CapKP retrieves an ontological knowledge graph by treating the textual label as a query to explore task-relevant semantic information. To further refine the derived semantic information, CapKP introduces causality-pruning by following the first principle of Granger causality. Empirically, we conduct extensive evaluations to demonstrate the effectiveness of CapKP, e.g., with 8 shots, CapKP outperforms the manual-prompt method by 12.51% and the learnable-prompt method by 1.39% on average, respectively. Experimental analyses prove the superiority of CapKP in domain generalization compared to benchmark approaches.
MetAug: Contrastive Learning via Meta Feature Augmentation
Mar 10, 2022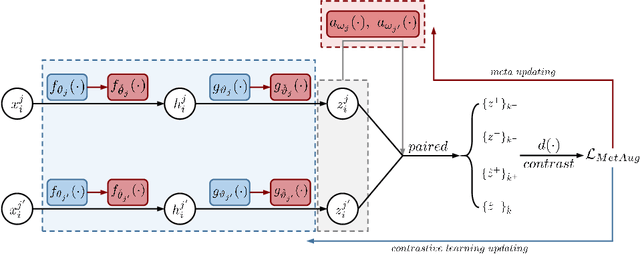
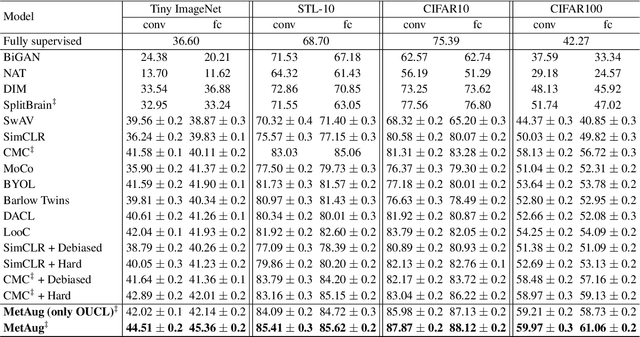
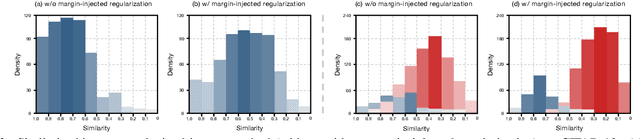
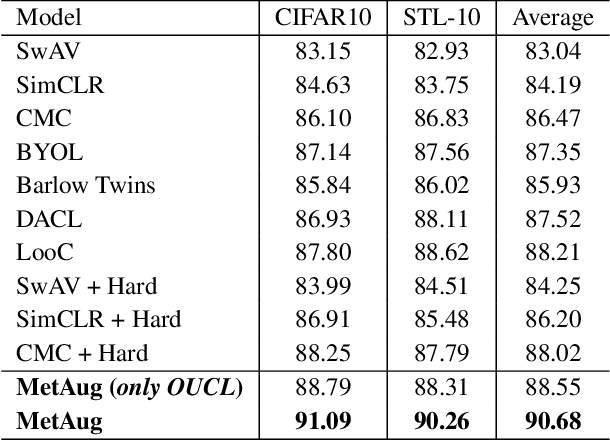
What matters for contrastive learning? We argue that contrastive learning heavily relies on informative features, or "hard" (positive or negative) features. Early works include more informative features by applying complex data augmentations and large batch size or memory bank, and recent works design elaborate sampling approaches to explore informative features. The key challenge toward exploring such features is that the source multi-view data is generated by applying random data augmentations, making it infeasible to always add useful information in the augmented data. Consequently, the informativeness of features learned from such augmented data is limited. In response, we propose to directly augment the features in latent space, thereby learning discriminative representations without a large amount of input data. We perform a meta learning technique to build the augmentation generator that updates its network parameters by considering the performance of the encoder. However, insufficient input data may lead the encoder to learn collapsed features and therefore malfunction the augmentation generator. A new margin-injected regularization is further added in the objective function to avoid the encoder learning a degenerate mapping. To contrast all features in one gradient back-propagation step, we adopt the proposed optimization-driven unified contrastive loss instead of the conventional contrastive loss. Empirically, our method achieves state-of-the-art results on several benchmark datasets.