 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModeling Multiple Views via Implicitly Preserving Global Consistency and Local Complementarity
Sep 16, 2022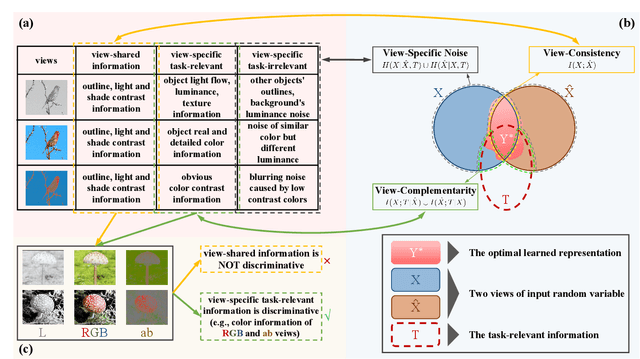
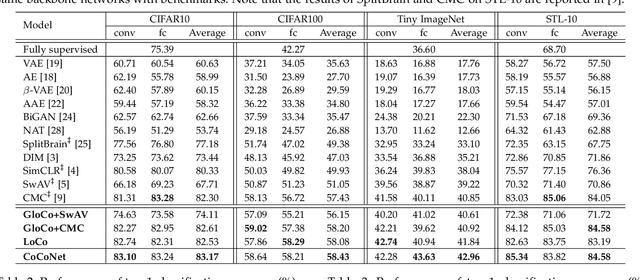
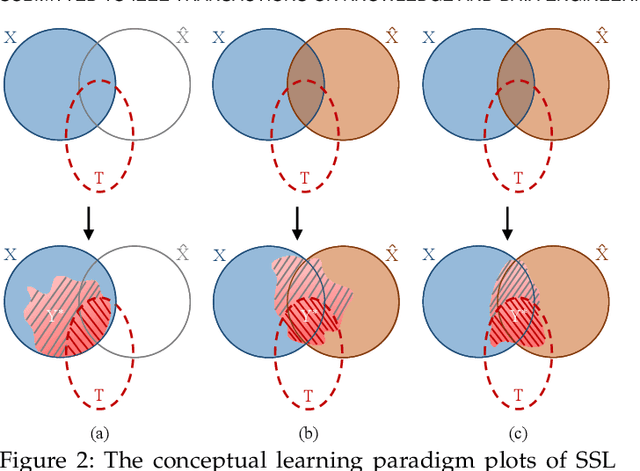
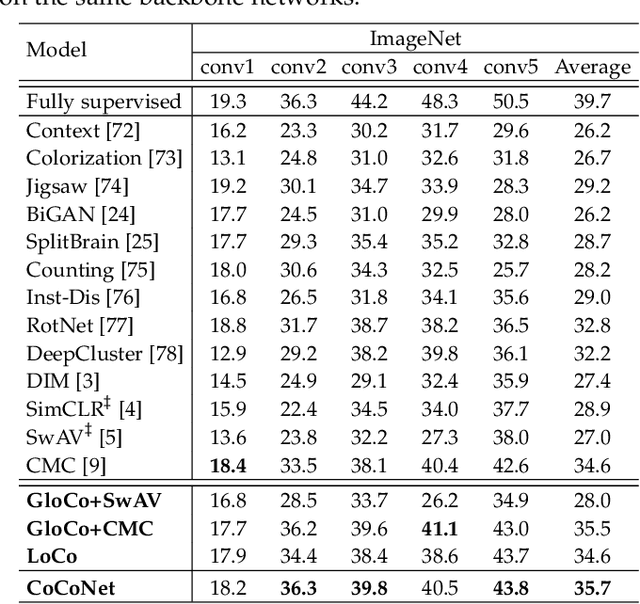
While self-supervised learning techniques are often used to mining implicit knowledge from unlabeled data via modeling multiple views, it is unclear how to perform effective representation learning in a complex and inconsistent context. To this end, we propose a methodology, specifically consistency and complementarity network (CoCoNet), which avails of strict global inter-view consistency and local cross-view complementarity preserving regularization to comprehensively learn representations from multiple views. On the global stage, we reckon that the crucial knowledge is implicitly shared among views, and enhancing the encoder to capture such knowledge from data can improve the discriminability of the learned representations. Hence, preserving the global consistency of multiple views ensures the acquisition of common knowledge. CoCoNet aligns the probabilistic distribution of views by utilizing an efficient discrepancy metric measurement based on the generalized sliced Wasserstein distance. Lastly on the local stage, we propose a heuristic complementarity-factor, which joints cross-view discriminative knowledge, and it guides the encoders to learn not only view-wise discriminability but also cross-view complementary information. Theoretically, we provide the information-theoretical-based analyses of our proposed CoCoNet. Empirically, to investigate the improvement gains of our approach, we conduct adequate experimental validations, which demonstrate that CoCoNet outperforms the state-of-the-art self-supervised methods by a significant margin proves that such implicit consistency and complementarity preserving regularization can enhance the discriminability of latent representations.
Information Theory-Guided Heuristic Progressive Multi-View Coding
Sep 06, 2021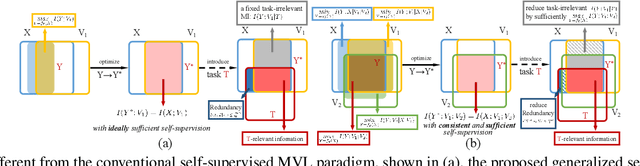
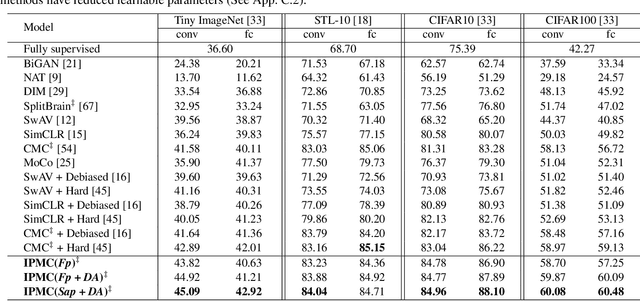
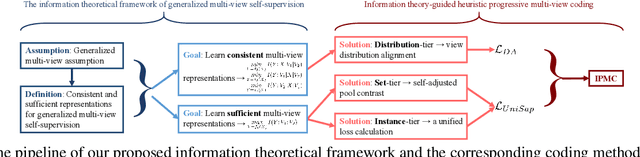
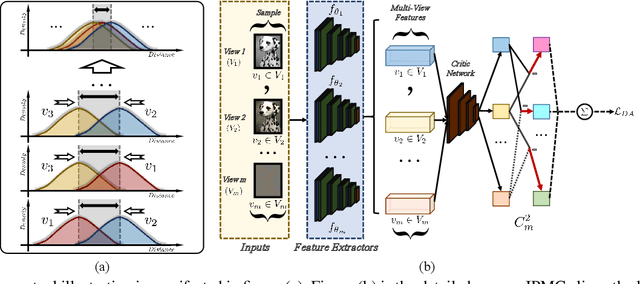
Multi-view representation learning captures comprehensive information from multiple views of a shared context. Recent works intuitively apply contrastive learning (CL) to learn representations, regarded as a pairwise manner, which is still scalable: view-specific noise is not filtered in learning view-shared representations; the fake negative pairs, where the negative terms are actually within the same class as the positive, and the real negative pairs are coequally treated; and evenly measuring the similarities between terms might interfere with optimization. Importantly, few works research the theoretical framework of generalized self-supervised multi-view learning, especially for more than two views. To this end, we rethink the existing multi-view learning paradigm from the information theoretical perspective and then propose a novel information theoretical framework for generalized multi-view learning. Guided by it, we build a multi-view coding method with a three-tier progressive architecture, namely Information theory-guided heuristic Progressive Multi-view Coding (IPMC). In the distribution-tier, IPMC aligns the distribution between views to reduce view-specific noise. In the set-tier, IPMC builds self-adjusted pools for contrasting, which utilizes a view filter to adaptively modify the pools. Lastly, in the instance-tier, we adopt a designed unified loss to learn discriminative representations and reduce the gradient interference. Theoretically and empirically, we demonstrate the superiority of IPMC over state-of-the-art methods.