 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeG10: Enabling An Efficient Unified GPU Memory and Storage Architecture with Smart Tensor Migrations
Oct 13, 2023To break the GPU memory wall for scaling deep learning workloads, a variety of architecture and system techniques have been proposed recently. Their typical approaches include memory extension with flash memory and direct storage access. However, these techniques still suffer from suboptimal performance and introduce complexity to the GPU memory management, making them hard to meet the scalability requirement of deep learning workloads today. In this paper, we present a unified GPU memory and storage architecture named G10 driven by the fact that the tensor behaviors of deep learning workloads are highly predictable. G10 integrates the host memory, GPU memory, and flash memory into a unified memory space, to scale the GPU memory capacity while enabling transparent data migrations. Based on this unified GPU memory and storage architecture, G10 utilizes compiler techniques to characterize the tensor behaviors in deep learning workloads. Therefore, it can schedule data migrations in advance by considering the available bandwidth of flash memory and host memory. The cooperative mechanism between deep learning compilers and the unified memory architecture enables G10 to hide data transfer overheads in a transparent manner. We implement G10 based on an open-source GPU simulator. Our experiments demonstrate that G10 outperforms state-of-the-art GPU memory solutions by up to 1.75$\times$, without code modifications to deep learning workloads. With the smart data migration mechanism, G10 can reach 90.3\% of the performance of the ideal case assuming unlimited GPU memory.
Non-Asymptotic Bounds for Adversarial Excess Risk under Misspecified Models
Sep 02, 2023We propose a general approach to evaluating the performance of robust estimators based on adversarial losses under misspecified models. We first show that adversarial risk is equivalent to the risk induced by a distributional adversarial attack under certain smoothness conditions. This ensures that the adversarial training procedure is well-defined. To evaluate the generalization performance of the adversarial estimator, we study the adversarial excess risk. Our proposed analysis method includes investigations on both generalization error and approximation error. We then establish non-asymptotic upper bounds for the adversarial excess risk associated with Lipschitz loss functions. In addition, we apply our general results to adversarial training for classification and regression problems. For the quadratic loss in nonparametric regression, we show that the adversarial excess risk bound can be improved over those for a general loss.
Wasserstein Generative Regression
Jun 27, 2023In this paper, we propose a new and unified approach for nonparametric regression and conditional distribution learning. Our approach simultaneously estimates a regression function and a conditional generator using a generative learning framework, where a conditional generator is a function that can generate samples from a conditional distribution. The main idea is to estimate a conditional generator that satisfies the constraint that it produces a good regression function estimator. We use deep neural networks to model the conditional generator. Our approach can handle problems with multivariate outcomes and covariates, and can be used to construct prediction intervals. We provide theoretical guarantees by deriving non-asymptotic error bounds and the distributional consistency of our approach under suitable assumptions. We also perform numerical experiments with simulated and real data to demonstrate the effectiveness and superiority of our approach over some existing approaches in various scenarios.
Differentiable Neural Networks with RePU Activation: with Applications to Score Estimation and Isotonic Regression
May 14, 2023


We study the properties of differentiable neural networks activated by rectified power unit (RePU) functions. We show that the partial derivatives of RePU neural networks can be represented by RePUs mixed-activated networks and derive upper bounds for the complexity of the function class of derivatives of RePUs networks. We establish error bounds for simultaneously approximating $C^s$ smooth functions and their derivatives using RePU-activated deep neural networks. Furthermore, we derive improved approximation error bounds when data has an approximate low-dimensional support, demonstrating the ability of RePU networks to mitigate the curse of dimensionality. To illustrate the usefulness of our results, we consider a deep score matching estimator (DSME) and propose a penalized deep isotonic regression (PDIR) using RePU networks. We establish non-asymptotic excess risk bounds for DSME and PDIR under the assumption that the target functions belong to a class of $C^s$ smooth functions. We also show that PDIR has a robustness property in the sense it is consistent with vanishing penalty parameters even when the monotonicity assumption is not satisfied. Furthermore, if the data distribution is supported on an approximate low-dimensional manifold, we show that DSME and PDIR can mitigate the curse of dimensionality.
CREPES: Cooperative RElative Pose EStimation towards Real-World Multi-Robot Systems
Feb 02, 2023



Mutual localization plays a crucial role in multi-robot systems. In this work, we propose a novel system to estimate the 3D relative pose targeting real-world applications. We design and implement a compact hardware module using active infrared (IR) LEDs, an IR fish-eye camera, an ultra-wideband (UWB) module and an inertial measurement unit (IMU). By leveraging IR light communication, the system solves data association between visual detection and UWB ranging. Ranging measurements from the UWB and directional information from the camera offer relative 3D position estimation. Combining the mutual relative position with neighbors and the gravity constraints provided by IMUs, we can estimate the 3D relative pose from every single frame of sensor fusion. In addition, we design an estimator based on the error-state Kalman filter (ESKF) to enhance system accuracy and robustness. When multiple neighbors are available, a Pose Graph Optimization (PGO) algorithm is applied to further improve system accuracy. We conduct experiments in various environments, and the results show that our system outperforms state-of-the-art accuracy and robustness, especially in challenging environments.
Nonparametric Quantile Regression: Non-Crossing Constraints and Conformal Prediction
Oct 18, 2022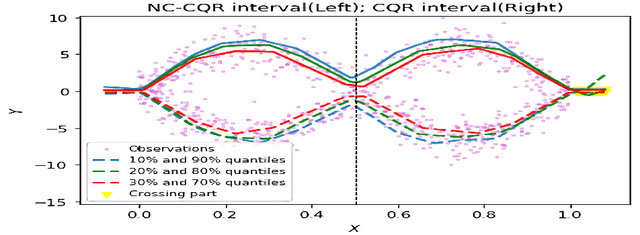
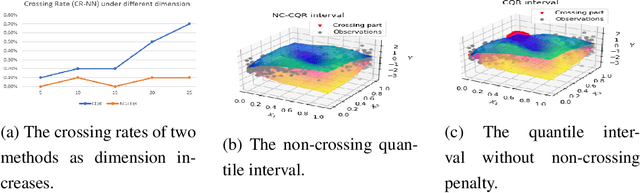

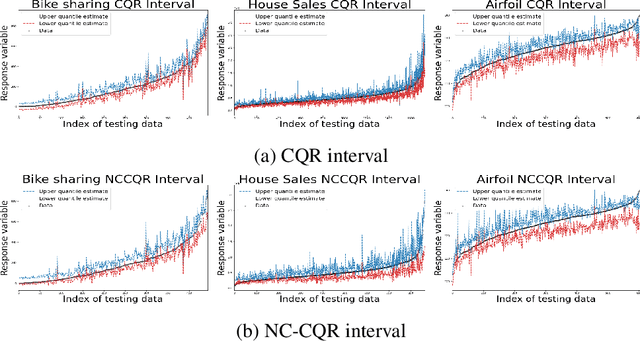
We propose a nonparametric quantile regression method using deep neural networks with a rectified linear unit penalty function to avoid quantile crossing. This penalty function is computationally feasible for enforcing non-crossing constraints in multi-dimensional nonparametric quantile regression. We establish non-asymptotic upper bounds for the excess risk of the proposed nonparametric quantile regression function estimators. Our error bounds achieve optimal minimax rate of convergence for the Holder class, and the prefactors of the error bounds depend polynomially on the dimension of the predictor, instead of exponentially. Based on the proposed non-crossing penalized deep quantile regression, we construct conformal prediction intervals that are fully adaptive to heterogeneity. The proposed prediction interval is shown to have good properties in terms of validity and accuracy under reasonable conditions. We also derive non-asymptotic upper bounds for the difference of the lengths between the proposed non-crossing conformal prediction interval and the theoretically oracle prediction interval. Numerical experiments including simulation studies and a real data example are conducted to demonstrate the effectiveness of the proposed method.
Fast localization and single-pixel imaging of the moving object using time-division multiplexing
Aug 15, 2022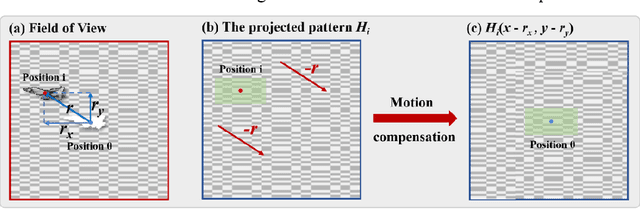
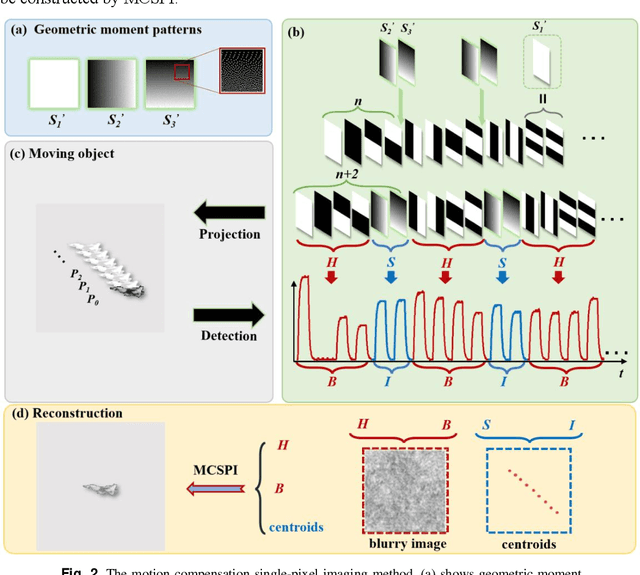
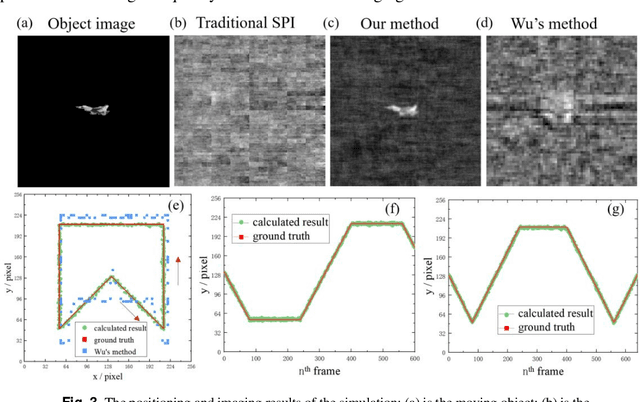
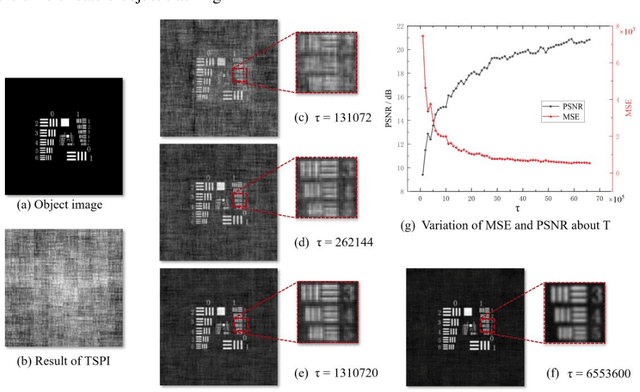
When imaging moving objects, single-pixel imaging produces motion blur. This paper proposes a new single-pixel imaging method, which can achieve anti-motion blur imaging of a fast-moving object. The geometric moment patterns and Hadamard patterns are used to alternately encode the position information and the image information of the object with time-division multiplexing. In the reconstruction process, the object position information is extracted independently and combining motion-compensation reconstruction algorithm to decouple the object motion from image information. As a result, the anti-motion blur image and the high frame rate object positions are obtained. Experimental results show that for a moving object with an angular velocity of up to 0.5rad/s relative to the imaging system, the proposed method achieves a localization frequency of 5.55kHz, and gradually reconstructs a clear image of the fast-moving object with a pseudo resolution of 512x512. The method has application prospects in single-pixel imaging of the fast-moving object.
Deep Sufficient Representation Learning via Mutual Information
Jul 21, 2022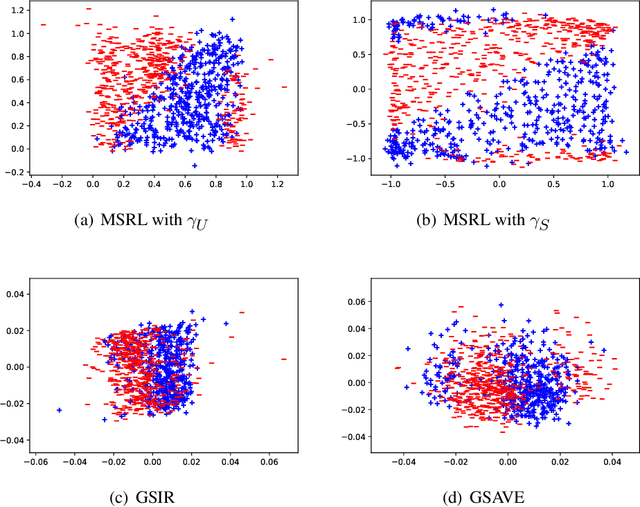
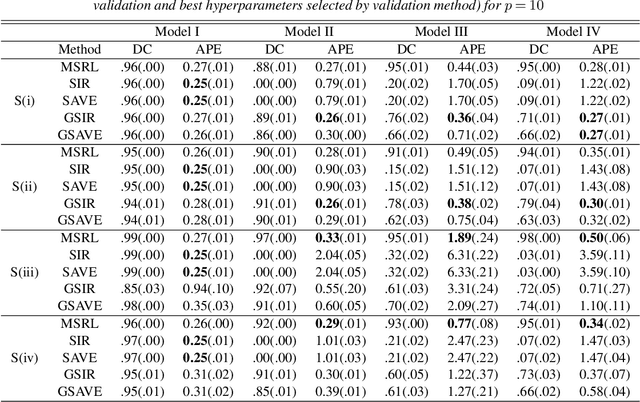
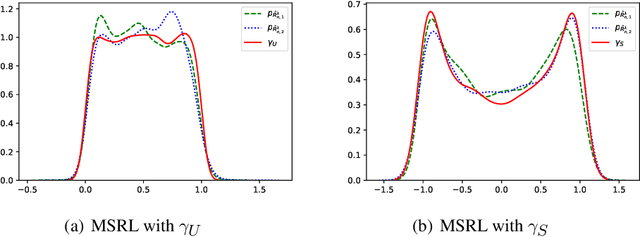
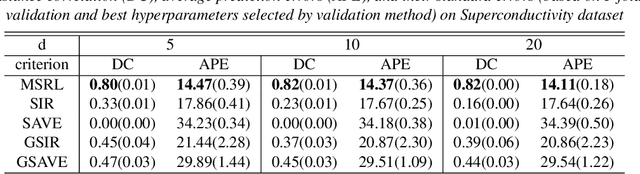
We propose a mutual information-based sufficient representation learning (MSRL) approach, which uses the variational formulation of the mutual information and leverages the approximation power of deep neural networks. MSRL learns a sufficient representation with the maximum mutual information with the response and a user-selected distribution. It can easily handle multi-dimensional continuous or categorical response variables. MSRL is shown to be consistent in the sense that the conditional probability density function of the response variable given the learned representation converges to the conditional probability density function of the response variable given the predictor. Non-asymptotic error bounds for MSRL are also established under suitable conditions. To establish the error bounds, we derive a generalized Dudley's inequality for an order-two U-process indexed by deep neural networks, which may be of independent interest. We discuss how to determine the intrinsic dimension of the underlying data distribution. Moreover, we evaluate the performance of MSRL via extensive numerical experiments and real data analysis and demonstrate that MSRL outperforms some existing nonlinear sufficient dimension reduction methods.
Estimation of Non-Crossing Quantile Regression Process with Deep ReQU Neural Networks
Jul 21, 2022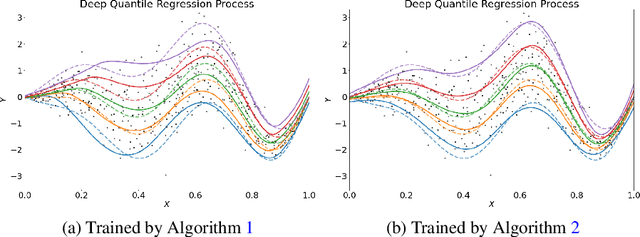
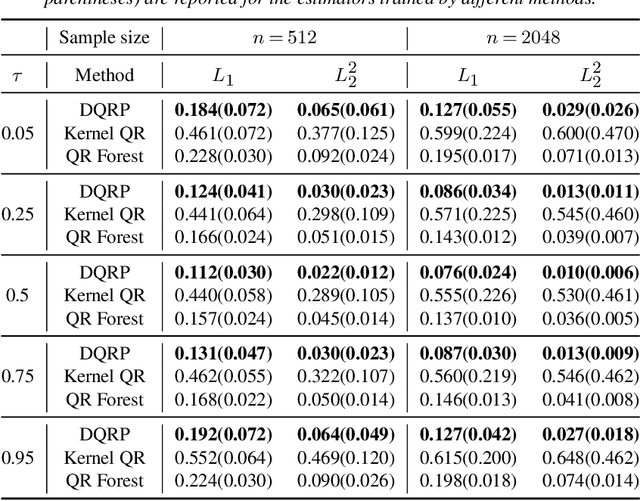
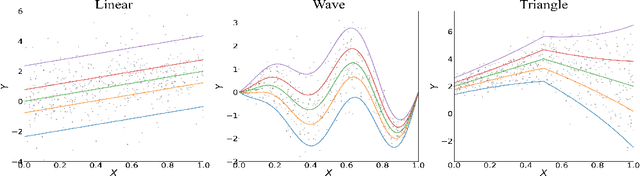
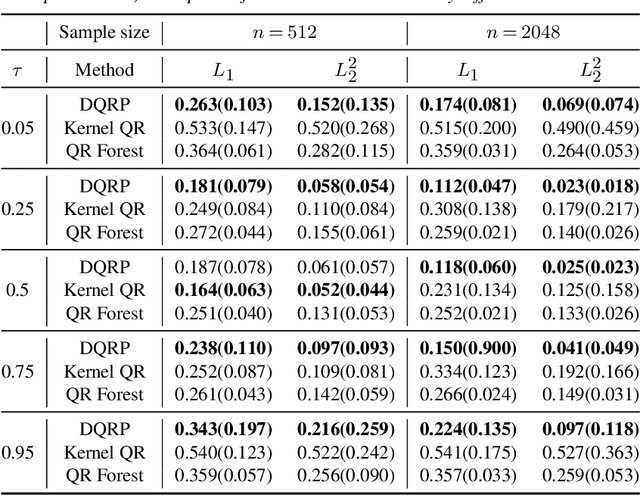
We propose a penalized nonparametric approach to estimating the quantile regression process (QRP) in a nonseparable model using rectifier quadratic unit (ReQU) activated deep neural networks and introduce a novel penalty function to enforce non-crossing of quantile regression curves. We establish the non-asymptotic excess risk bounds for the estimated QRP and derive the mean integrated squared error for the estimated QRP under mild smoothness and regularity conditions. To establish these non-asymptotic risk and estimation error bounds, we also develop a new error bound for approximating $C^s$ smooth functions with $s >0$ and their derivatives using ReQU activated neural networks. This is a new approximation result for ReQU networks and is of independent interest and may be useful in other problems. Our numerical experiments demonstrate that the proposed method is competitive with or outperforms two existing methods, including methods using reproducing kernels and random forests, for nonparametric quantile regression.
Wasserstein Generative Learning of Conditional Distribution
Dec 19, 2021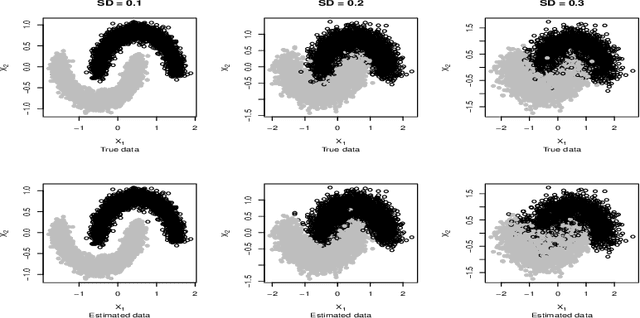
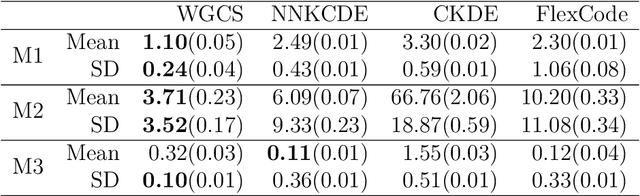
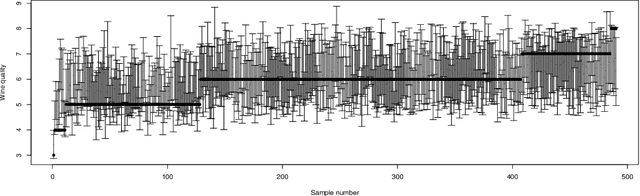
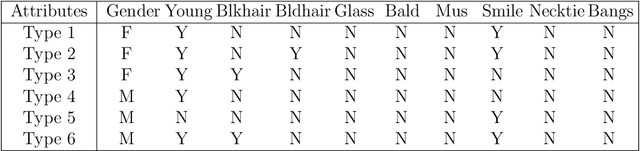
Conditional distribution is a fundamental quantity for describing the relationship between a response and a predictor. We propose a Wasserstein generative approach to learning a conditional distribution. The proposed approach uses a conditional generator to transform a known distribution to the target conditional distribution. The conditional generator is estimated by matching a joint distribution involving the conditional generator and the target joint distribution, using the Wasserstein distance as the discrepancy measure for these joint distributions. We establish non-asymptotic error bound of the conditional sampling distribution generated by the proposed method and show that it is able to mitigate the curse of dimensionality, assuming that the data distribution is supported on a lower-dimensional set. We conduct numerical experiments to validate proposed method and illustrate its applications to conditional sample generation, nonparametric conditional density estimation, prediction uncertainty quantification, bivariate response data, image reconstruction and image generation.