 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWasserstein Generative Learning of Conditional Distribution
Dec 19, 2021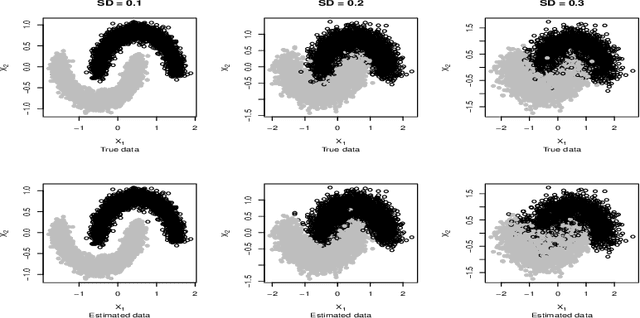
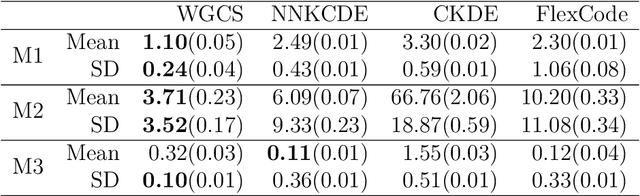
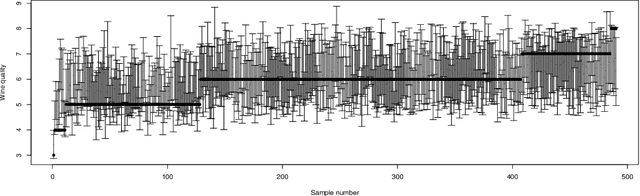
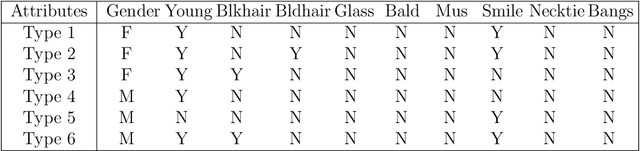
Conditional distribution is a fundamental quantity for describing the relationship between a response and a predictor. We propose a Wasserstein generative approach to learning a conditional distribution. The proposed approach uses a conditional generator to transform a known distribution to the target conditional distribution. The conditional generator is estimated by matching a joint distribution involving the conditional generator and the target joint distribution, using the Wasserstein distance as the discrepancy measure for these joint distributions. We establish non-asymptotic error bound of the conditional sampling distribution generated by the proposed method and show that it is able to mitigate the curse of dimensionality, assuming that the data distribution is supported on a lower-dimensional set. We conduct numerical experiments to validate proposed method and illustrate its applications to conditional sample generation, nonparametric conditional density estimation, prediction uncertainty quantification, bivariate response data, image reconstruction and image generation.
Non-Asymptotic Error Bounds for Bidirectional GANs
Oct 24, 2021We derive nearly sharp bounds for the bidirectional GAN (BiGAN) estimation error under the Dudley distance between the latent joint distribution and the data joint distribution with appropriately specified architecture of the neural networks used in the model. To the best of our knowledge, this is the first theoretical guarantee for the bidirectional GAN learning approach. An appealing feature of our results is that they do not assume the reference and the data distributions to have the same dimensions or these distributions to have bounded support. These assumptions are commonly assumed in the existing convergence analysis of the unidirectional GANs but may not be satisfied in practice. Our results are also applicable to the Wasserstein bidirectional GAN if the target distribution is assumed to have a bounded support. To prove these results, we construct neural network functions that push forward an empirical distribution to another arbitrary empirical distribution on a possibly different-dimensional space. We also develop a novel decomposition of the integral probability metric for the error analysis of bidirectional GANs. These basic theoretical results are of independent interest and can be applied to other related learning problems.
An error analysis of generative adversarial networks for learning distributions
Jun 12, 2021This paper studies how well generative adversarial networks (GANs) learn probability distributions from finite samples. Our main results establish the convergence rates of GANs under a collection of integral probability metrics defined through H\"older classes, including the Wasserstein distance as a special case. We also show that GANs are able to adaptively learn data distributions with low-dimensional structures or have H\"older densities, when the network architectures are chosen properly. In particular, for distributions concentrated around a low-dimensional set, we show that the learning rates of GANs do not depend on the high ambient dimension, but on the lower intrinsic dimension. Our analysis is based on a new oracle inequality decomposing the estimation error into the generator and discriminator approximation error and the statistical error, which may be of independent interest.