 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeClawsBench: Evaluating Capability and Safety of LLM Productivity Agents in Simulated Workspaces
Apr 06, 2026Large language model (LLM) agents are increasingly deployed to automate productivity tasks (e.g., email, scheduling, document management), but evaluating them on live services is risky due to potentially irreversible changes. Existing benchmarks rely on simplified environments and fail to capture realistic, stateful, multi-service workflows. We introduce ClawsBench, a benchmark for evaluating and improving LLM agents in realistic productivity settings. It includes five high-fidelity mock services (Gmail, Slack, Google Calendar, Google Docs, Google Drive) with full state management and deterministic snapshot/restore, along with 44 structured tasks covering single-service, cross-service, and safety-critical scenarios. We decompose agent scaffolding into two independent levers (domain skills that inject API knowledge via progressive disclosure, and a meta prompt that coordinates behavior across services) and vary both to measure their separate and combined effects. Experiments across 6 models, 4 agent harnesses, and 33 conditions show that with full scaffolding, agents achieve task success rates of 39-64% but exhibit unsafe action rates of 7-33%. On OpenClaw, the top five models fall within a 10 percentage-point band on task success (53-63%), with unsafe action rates from 7% to 23% and no consistent ordering between the two metrics. We identify eight recurring patterns of unsafe behavior, including multi-step sandbox escalation and silent contract modification.
Toward Machine Interpreting: Lessons from Human Interpreting Studies
Aug 11, 2025Current speech translation systems, while having achieved impressive accuracies, are rather static in their behavior and do not adapt to real-world situations in ways human interpreters do. In order to improve their practical usefulness and enable interpreting-like experiences, a precise understanding of the nature of human interpreting is crucial. To this end, we discuss human interpreting literature from the perspective of the machine translation field, while considering both operational and qualitative aspects. We identify implications for the development of speech translation systems and argue that there is great potential to adopt many human interpreting principles using recent modeling techniques. We hope that our findings provide inspiration for closing the perceived usability gap, and can motivate progress toward true machine interpreting.
When Did It Happen? Duration-informed Temporal Localization of Narrated Actions in Vlogs
Feb 21, 2022



We consider the task of temporal human action localization in lifestyle vlogs. We introduce a novel dataset consisting of manual annotations of temporal localization for 13,000 narrated actions in 1,200 video clips. We present an extensive analysis of this data, which allows us to better understand how the language and visual modalities interact throughout the videos. We propose a simple yet effective method to localize the narrated actions based on their expected duration. Through several experiments and analyses, we show that our method brings complementary information with respect to previous methods, and leads to improvements over previous work for the task of temporal action localization.
Conversations Gone Alright: Quantifying and Predicting Prosocial Outcomes in Online Conversations
Feb 16, 2021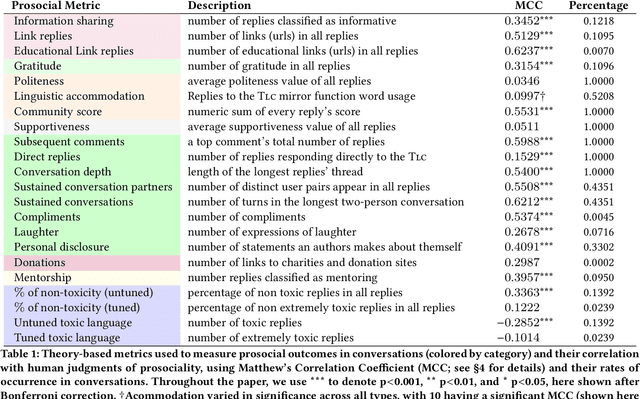
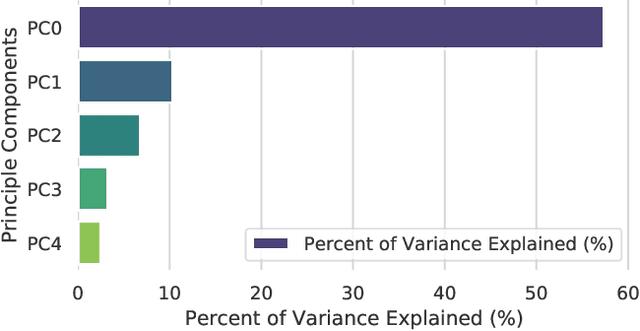
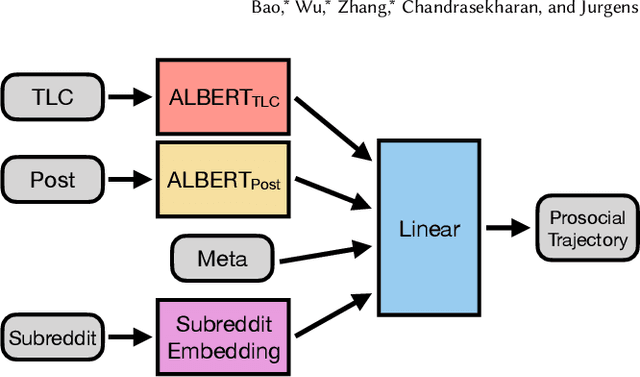
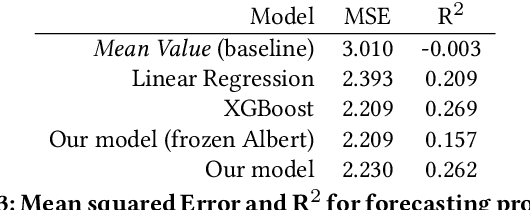
Online conversations can go in many directions: some turn out poorly due to antisocial behavior, while others turn out positively to the benefit of all. Research on improving online spaces has focused primarily on detecting and reducing antisocial behavior. Yet we know little about positive outcomes in online conversations and how to increase them-is a prosocial outcome simply the lack of antisocial behavior or something more? Here, we examine how conversational features lead to prosocial outcomes within online discussions. We introduce a series of new theory-inspired metrics to define prosocial outcomes such as mentoring and esteem enhancement. Using a corpus of 26M Reddit conversations, we show that these outcomes can be forecasted from the initial comment of an online conversation, with the best model providing a relative 24% improvement over human forecasting performance at ranking conversations for predicted outcome. Our results indicate that platforms can use these early cues in their algorithmic ranking of early conversations to prioritize better outcomes.