 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKnowCoder-V2: Deep Knowledge Analysis
Jun 07, 2025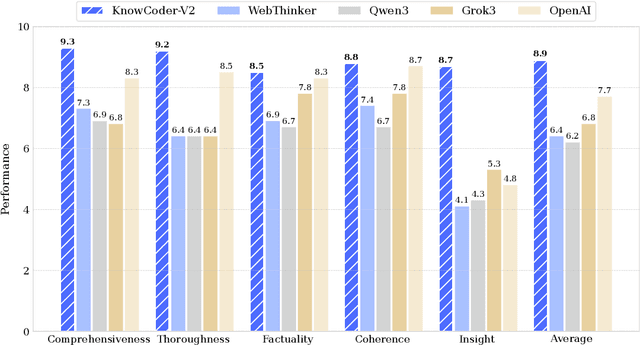
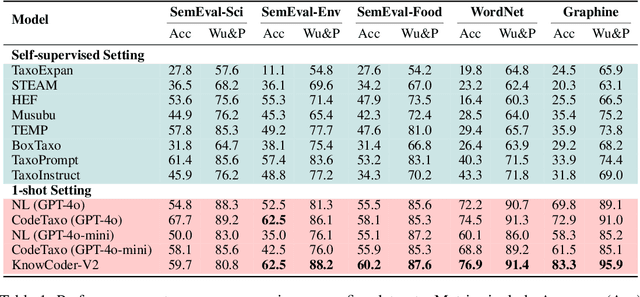
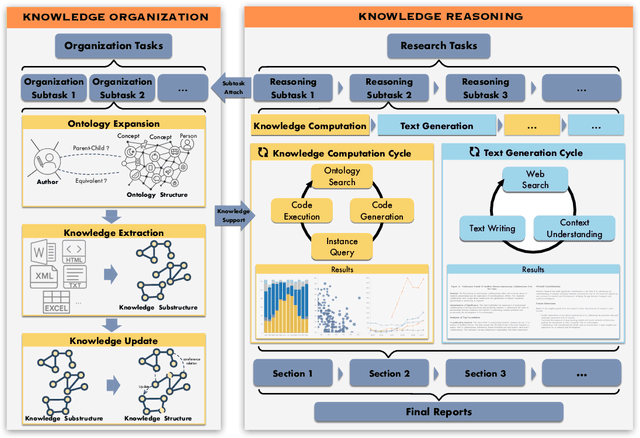
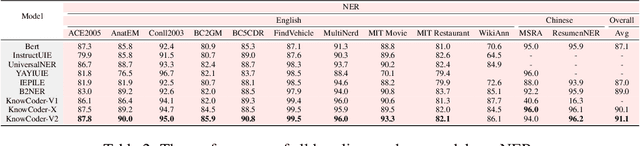
Deep knowledge analysis tasks always involve the systematic extraction and association of knowledge from large volumes of data, followed by logical reasoning to discover insights. However, to solve such complex tasks, existing deep research frameworks face three major challenges: 1) They lack systematic organization and management of knowledge; 2) They operate purely online, making it inefficient for tasks that rely on shared and large-scale knowledge; 3) They cannot perform complex knowledge computation, limiting their abilities to produce insightful analytical results. Motivated by these, in this paper, we propose a \textbf{K}nowledgeable \textbf{D}eep \textbf{R}esearch (\textbf{KDR}) framework that empowers deep research with deep knowledge analysis capability. Specifically, it introduces an independent knowledge organization phase to preprocess large-scale, domain-relevant data into systematic knowledge offline. Based on this knowledge, it extends deep research with an additional kind of reasoning steps that perform complex knowledge computation in an online manner. To enhance the abilities of LLMs to solve knowledge analysis tasks in the above framework, we further introduce \textbf{\KCII}, an LLM that bridges knowledge organization and reasoning via unified code generation. For knowledge organization, it generates instantiation code for predefined classes, transforming data into knowledge objects. For knowledge computation, it generates analysis code and executes on the above knowledge objects to obtain deep analysis results. Experimental results on more than thirty datasets across six knowledge analysis tasks demonstrate the effectiveness of \KCII. Moreover, when integrated into the KDR framework, \KCII can generate high-quality reports with insightful analytical results compared to the mainstream deep research framework.
On the Scaling of Robustness and Effectiveness in Dense Retrieval
May 30, 2025Robustness and Effectiveness are critical aspects of developing dense retrieval models for real-world applications. It is known that there is a trade-off between the two. Recent work has addressed scaling laws of effectiveness in dense retrieval, revealing a power-law relationship between effectiveness and the size of models and data. Does robustness follow scaling laws too? If so, can scaling improve both robustness and effectiveness together, or do they remain locked in a trade-off? To answer these questions, we conduct a comprehensive experimental study. We find that:(i) Robustness, including out-of-distribution and adversarial robustness, also follows a scaling law.(ii) Robustness and effectiveness exhibit different scaling patterns, leading to significant resource costs when jointly improving both. Given these findings, we shift to the third factor that affects model performance, namely the optimization strategy, beyond the model size and data size. We find that: (i) By fitting different optimization strategies, the joint performance of robustness and effectiveness traces out a Pareto frontier. (ii) When the optimization strategy strays from Pareto efficiency, the joint performance scales in a sub-optimal direction. (iii) By adjusting the optimization weights to fit the Pareto efficiency, we can achieve Pareto training, where the scaling of joint performance becomes most efficient. Even without requiring additional resources, Pareto training is comparable to the performance of scaling resources several times under optimization strategies that overly prioritize either robustness or effectiveness. Finally, we demonstrate that our findings can help deploy dense retrieval models in real-world applications that scale efficiently and are balanced for robustness and effectiveness.
The Silent Saboteur: Imperceptible Adversarial Attacks against Black-Box Retrieval-Augmented Generation Systems
May 24, 2025



We explore adversarial attacks against retrieval-augmented generation (RAG) systems to identify their vulnerabilities. We focus on generating human-imperceptible adversarial examples and introduce a novel imperceptible retrieve-to-generate attack against RAG. This task aims to find imperceptible perturbations that retrieve a target document, originally excluded from the initial top-$k$ candidate set, in order to influence the final answer generation. To address this task, we propose ReGENT, a reinforcement learning-based framework that tracks interactions between the attacker and the target RAG and continuously refines attack strategies based on relevance-generation-naturalness rewards. Experiments on newly constructed factual and non-factual question-answering benchmarks demonstrate that ReGENT significantly outperforms existing attack methods in misleading RAG systems with small imperceptible text perturbations.
How Knowledge Popularity Influences and Enhances LLM Knowledge Boundary Perception
May 23, 2025Large language models (LLMs) often fail to recognize their knowledge boundaries, producing confident yet incorrect answers. In this paper, we investigate how knowledge popularity affects LLMs' ability to perceive their knowledge boundaries. Focusing on entity-centric factual question answering (QA), we quantify knowledge popularity from three perspectives: the popularity of entities in the question, the popularity of entities in the answer, and relation popularity, defined as their co-occurrence frequency. Experiments on three representative datasets containing knowledge with varying popularity show that LLMs exhibit better QA performance, higher confidence, and more accurate perception on more popular knowledge, with relation popularity having the strongest correlation. Cause knowledge popularity shows strong correlation with LLMs' QA performance, we propose to leverage these signals for confidence calibration. This improves the accuracy of answer correctness prediction by an average of 5.24% across all models and datasets. Furthermore, we explore prompting LLMs to estimate popularity without external corpora, which yields a viable alternative.
Chain-of-Thought Poisoning Attacks against R1-based Retrieval-Augmented Generation Systems
May 22, 2025


Retrieval-augmented generation (RAG) systems can effectively mitigate the hallucination problem of large language models (LLMs),but they also possess inherent vulnerabilities. Identifying these weaknesses before the large-scale real-world deployment of RAG systems is of great importance, as it lays the foundation for building more secure and robust RAG systems in the future. Existing adversarial attack methods typically exploit knowledge base poisoning to probe the vulnerabilities of RAG systems, which can effectively deceive standard RAG models. However, with the rapid advancement of deep reasoning capabilities in modern LLMs, previous approaches that merely inject incorrect knowledge are inadequate when attacking RAG systems equipped with deep reasoning abilities. Inspired by the deep thinking capabilities of LLMs, this paper extracts reasoning process templates from R1-based RAG systems, uses these templates to wrap erroneous knowledge into adversarial documents, and injects them into the knowledge base to attack RAG systems. The key idea of our approach is that adversarial documents, by simulating the chain-of-thought patterns aligned with the model's training signals, may be misinterpreted by the model as authentic historical reasoning processes, thus increasing their likelihood of being referenced. Experiments conducted on the MS MARCO passage ranking dataset demonstrate the effectiveness of our proposed method.
Mixture Policy based Multi-Hop Reasoning over N-tuple Temporal Knowledge Graphs
May 19, 2025Temporal Knowledge Graphs (TKGs), which utilize quadruples in the form of (subject, predicate, object, timestamp) to describe temporal facts, have attracted extensive attention. N-tuple TKGs (N-TKGs) further extend traditional TKGs by utilizing n-tuples to incorporate auxiliary elements alongside core elements (i.e., subject, predicate, and object) of facts, so as to represent them in a more fine-grained manner. Reasoning over N-TKGs aims to predict potential future facts based on historical ones. However, existing N-TKG reasoning methods often lack explainability due to their black-box nature. Therefore, we introduce a new Reinforcement Learning-based method, named MT-Path, which leverages the temporal information to traverse historical n-tuples and construct a temporal reasoning path. Specifically, in order to integrate the information encapsulated within n-tuples, i.e., the entity-irrelevant information within the predicate, the information about core elements, and the complete information about the entire n-tuples, MT-Path utilizes a mixture policy-driven action selector, which bases on three low-level policies, namely, the predicate-focused policy, the core-element-focused policy and the whole-fact-focused policy. Further, MT-Path utilizes an auxiliary element-aware GCN to capture the rich semantic dependencies among facts, thereby enabling the agent to gain a deep understanding of each n-tuple. Experimental results demonstrate the effectiveness and the explainability of MT-Path.
An Empirical Study of Evaluating Long-form Question Answering
Apr 25, 2025\Ac{LFQA} aims to generate lengthy answers to complex questions. This scenario presents great flexibility as well as significant challenges for evaluation. Most evaluations rely on deterministic metrics that depend on string or n-gram matching, while the reliability of large language model-based evaluations for long-form answers remains relatively unexplored. We address this gap by conducting an in-depth study of long-form answer evaluation with the following research questions: (i) To what extent do existing automatic evaluation metrics serve as a substitute for human evaluations? (ii) What are the limitations of existing evaluation metrics compared to human evaluations? (iii) How can the effectiveness and robustness of existing evaluation methods be improved? We collect 5,236 factoid and non-factoid long-form answers generated by different large language models and conduct a human evaluation on 2,079 of them, focusing on correctness and informativeness. Subsequently, we investigated the performance of automatic evaluation metrics by evaluating these answers, analyzing the consistency between these metrics and human evaluations. We find that the style, length of the answers, and the category of questions can bias the automatic evaluation metrics. However, fine-grained evaluation helps mitigate this issue on some metrics. Our findings have important implications for the use of large language models for evaluating long-form question answering. All code and datasets are available at https://github.com/bugtig6351/lfqa_evaluation.
Bridging Queries and Tables through Entities in Table Retrieval
Apr 09, 2025Table retrieval is essential for accessing information stored in structured tabular formats; however, it remains less explored than text retrieval. The content of the table primarily consists of phrases and words, which include a large number of entities, such as time, locations, persons, and organizations. Entities are well-studied in the context of text retrieval, but there is a noticeable lack of research on their applications in table retrieval. In this work, we explore how to leverage entities in tables to improve retrieval performance. First, we investigate the important role of entities in table retrieval from a statistical perspective and propose an entity-enhanced training framework. Subsequently, we use the type of entities to highlight entities instead of introducing an external knowledge base. Moreover, we design an interaction paradigm based on entity representations. Our proposed framework is plug-and-play and flexible, making it easy to integrate into existing table retriever training processes. Empirical results on two table retrieval benchmarks, NQ-TABLES and OTT-QA, show that our proposed framework is both simple and effective in enhancing existing retrievers. We also conduct extensive analyses to confirm the efficacy of different components. Overall, our work provides a promising direction for elevating table retrieval, enlightening future research in this area.
Leveraging LLMs for Utility-Focused Annotation: Reducing Manual Effort for Retrieval and RAG
Apr 08, 2025Retrieval models typically rely on costly human-labeled query-document relevance annotations for training and evaluation. To reduce this cost and leverage the potential of Large Language Models (LLMs) in relevance judgments, we aim to explore whether LLM-generated annotations can effectively replace human annotations in training retrieval models. Retrieval usually emphasizes relevance, which indicates "topic-relatedness" of a document to a query, while in RAG, the value of a document (or utility) depends on how it contributes to answer generation. Recognizing this mismatch, some researchers use LLM performance on downstream tasks with documents as labels, but this approach requires manual answers for specific tasks, leading to high costs and limited generalization. In another line of work, prompting LLMs to select useful documents as RAG references eliminates the need for human annotation and is not task-specific. If we leverage LLMs' utility judgments to annotate retrieval data, we may retain cross-task generalization without human annotation in large-scale corpora. Therefore, we investigate utility-focused annotation via LLMs for large-scale retriever training data across both in-domain and out-of-domain settings on the retrieval and RAG tasks. To reduce the impact of low-quality positives labeled by LLMs, we design a novel loss function, i.e., Disj-InfoNCE. Our experiments reveal that: (1) Retrievers trained on utility-focused annotations significantly outperform those trained on human annotations in the out-of-domain setting on both tasks, demonstrating superior generalization capabilities. (2) LLM annotation does not replace human annotation in the in-domain setting. However, incorporating just 20% human-annotated data enables retrievers trained with utility-focused annotations to match the performance of models trained entirely with human annotations.
Unleashing the Power of LLMs in Dense Retrieval with Query Likelihood Modeling
Apr 07, 2025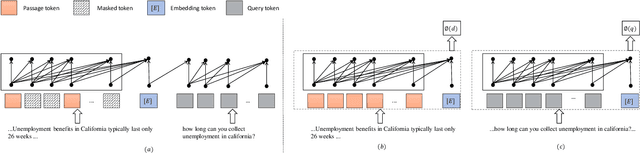
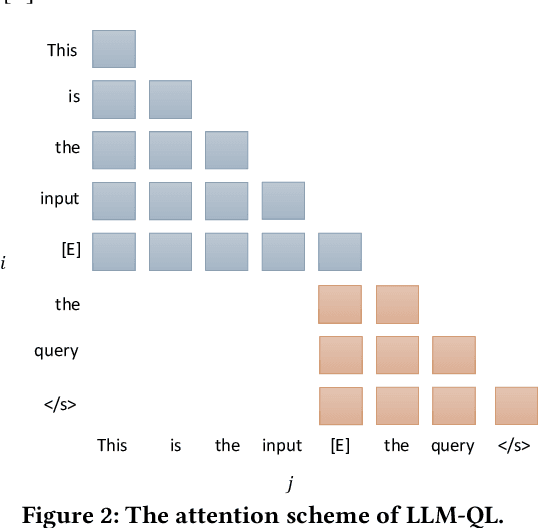
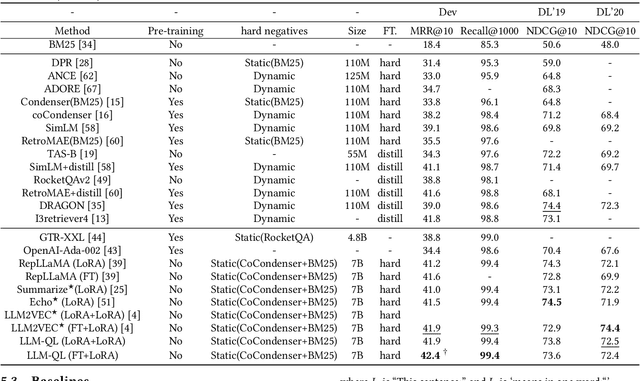
Dense retrieval is a crucial task in Information Retrieval (IR) and is the foundation for downstream tasks such as re-ranking. Recently, large language models (LLMs) have shown compelling semantic understanding capabilities and are appealing to researchers studying dense retrieval. LLMs, as decoder-style generative models, are competent at language generation while falling short on modeling global information due to the lack of attention to tokens afterward. Inspired by the classical word-based language modeling approach for IR, i.e., the query likelihood (QL) model, we seek to sufficiently utilize LLMs' generative ability by QL maximization. However, instead of ranking documents with QL estimation, we introduce an auxiliary task of QL maximization to yield a better backbone for contrastively learning a discriminative retriever. We name our model as LLM-QL. To condense global document semantics to a single vector during QL modeling, LLM-QL has two major components, Attention Stop (AS) and Input Corruption (IC). AS stops the attention of predictive tokens to previous tokens until the ending token of the document. IC masks a portion of tokens in the input documents during prediction. Experiments on MSMARCO show that LLM-QL can achieve significantly better performance than other LLM-based retrievers and using QL estimated by LLM-QL for ranking outperforms word-based QL by a large margin.