 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpenAI GPT-5 System Card
Dec 19, 2025This is the system card published alongside the OpenAI GPT-5 launch, August 2025. GPT-5 is a unified system with a smart and fast model that answers most questions, a deeper reasoning model for harder problems, and a real-time router that quickly decides which model to use based on conversation type, complexity, tool needs, and explicit intent (for example, if you say 'think hard about this' in the prompt). The router is continuously trained on real signals, including when users switch models, preference rates for responses, and measured correctness, improving over time. Once usage limits are reached, a mini version of each model handles remaining queries. This system card focuses primarily on gpt-5-thinking and gpt-5-main, while evaluations for other models are available in the appendix. The GPT-5 system not only outperforms previous models on benchmarks and answers questions more quickly, but -- more importantly -- is more useful for real-world queries. We've made significant advances in reducing hallucinations, improving instruction following, and minimizing sycophancy, and have leveled up GPT-5's performance in three of ChatGPT's most common uses: writing, coding, and health. All of the GPT-5 models additionally feature safe-completions, our latest approach to safety training to prevent disallowed content. Similarly to ChatGPT agent, we have decided to treat gpt-5-thinking as High capability in the Biological and Chemical domain under our Preparedness Framework, activating the associated safeguards. While we do not have definitive evidence that this model could meaningfully help a novice to create severe biological harm -- our defined threshold for High capability -- we have chosen to take a precautionary approach.
GPT-4o System Card
Oct 25, 2024GPT-4o is an autoregressive omni model that accepts as input any combination of text, audio, image, and video, and generates any combination of text, audio, and image outputs. It's trained end-to-end across text, vision, and audio, meaning all inputs and outputs are processed by the same neural network. GPT-4o can respond to audio inputs in as little as 232 milliseconds, with an average of 320 milliseconds, which is similar to human response time in conversation. It matches GPT-4 Turbo performance on text in English and code, with significant improvement on text in non-English languages, while also being much faster and 50\% cheaper in the API. GPT-4o is especially better at vision and audio understanding compared to existing models. In line with our commitment to building AI safely and consistent with our voluntary commitments to the White House, we are sharing the GPT-4o System Card, which includes our Preparedness Framework evaluations. In this System Card, we provide a detailed look at GPT-4o's capabilities, limitations, and safety evaluations across multiple categories, focusing on speech-to-speech while also evaluating text and image capabilities, and measures we've implemented to ensure the model is safe and aligned. We also include third-party assessments on dangerous capabilities, as well as discussion of potential societal impacts of GPT-4o's text and vision capabilities.
Tiny Machine Learning: Progress and Futures
Mar 29, 2024



Tiny Machine Learning (TinyML) is a new frontier of machine learning. By squeezing deep learning models into billions of IoT devices and microcontrollers (MCUs), we expand the scope of AI applications and enable ubiquitous intelligence. However, TinyML is challenging due to hardware constraints: the tiny memory resource makes it difficult to hold deep learning models designed for cloud and mobile platforms. There is also limited compiler and inference engine support for bare-metal devices. Therefore, we need to co-design the algorithm and system stack to enable TinyML. In this review, we will first discuss the definition, challenges, and applications of TinyML. We then survey the recent progress in TinyML and deep learning on MCUs. Next, we will introduce MCUNet, showing how we can achieve ImageNet-scale AI applications on IoT devices with system-algorithm co-design. We will further extend the solution from inference to training and introduce tiny on-device training techniques. Finally, we present future directions in this area. Today's large model might be tomorrow's tiny model. The scope of TinyML should evolve and adapt over time.
* arXiv admin note: text overlap with arXiv:2206.15472
VILA: On Pre-training for Visual Language Models
Dec 14, 2023



Visual language models (VLMs) rapidly progressed with the recent success of large language models. There have been growing efforts on visual instruction tuning to extend the LLM with visual inputs, but lacks an in-depth study of the visual language pre-training process, where the model learns to perform joint modeling on both modalities. In this work, we examine the design options for VLM pre-training by augmenting LLM towards VLM through step-by-step controllable comparisons. We introduce three main findings: (1) freezing LLMs during pre-training can achieve decent zero-shot performance, but lack in-context learning capability, which requires unfreezing the LLM; (2) interleaved pre-training data is beneficial whereas image-text pairs alone are not optimal; (3) re-blending text-only instruction data to image-text data during instruction fine-tuning not only remedies the degradation of text-only tasks, but also boosts VLM task accuracy. With an enhanced pre-training recipe we build VILA, a Visual Language model family that consistently outperforms the state-of-the-art models, e.g., LLaVA-1.5, across main benchmarks without bells and whistles. Multi-modal pre-training also helps unveil appealing properties of VILA, including multi-image reasoning, enhanced in-context learning, and better world knowledge.
PockEngine: Sparse and Efficient Fine-tuning in a Pocket
Oct 26, 2023



On-device learning and efficient fine-tuning enable continuous and privacy-preserving customization (e.g., locally fine-tuning large language models on personalized data). However, existing training frameworks are designed for cloud servers with powerful accelerators (e.g., GPUs, TPUs) and lack the optimizations for learning on the edge, which faces challenges of resource limitations and edge hardware diversity. We introduce PockEngine: a tiny, sparse and efficient engine to enable fine-tuning on various edge devices. PockEngine supports sparse backpropagation: it prunes the backward graph and sparsely updates the model with measured memory saving and latency reduction while maintaining the model quality. Secondly, PockEngine is compilation first: the entire training graph (including forward, backward and optimization steps) is derived at compile-time, which reduces the runtime overhead and brings opportunities for graph transformations. PockEngine also integrates a rich set of training graph optimizations, thus can further accelerate the training cost, including operator reordering and backend switching. PockEngine supports diverse applications, frontends and hardware backends: it flexibly compiles and tunes models defined in PyTorch/TensorFlow/Jax and deploys binaries to mobile CPU/GPU/DSPs. We evaluated PockEngine on both vision models and large language models. PockEngine achieves up to 15 $\times$ speedup over off-the-shelf TensorFlow (Raspberry Pi), 5.6 $\times$ memory saving back-propagation (Jetson AGX Orin). Remarkably, PockEngine enables fine-tuning LLaMav2-7B on NVIDIA Jetson AGX Orin at 550 tokens/s, 7.9$\times$ faster than the PyTorch.
AWQ: Activation-aware Weight Quantization for LLM Compression and Acceleration
Jun 01, 2023



Large language models (LLMs) have shown excellent performance on various tasks, but the astronomical model size raises the hardware barrier for serving (memory size) and slows down token generation (memory bandwidth). In this paper, we propose Activation-aware Weight Quantization (AWQ), a hardware-friendly approach for LLM low-bit weight-only quantization. Our method is based on the observation that weights are not equally important: protecting only 1% of salient weights can greatly reduce quantization error. We then propose to search for the optimal per-channel scaling that protects the salient weights by observing the activation, not weights. AWQ does not rely on any backpropagation or reconstruction, so it can well preserve LLMs' generalization ability on different domains and modalities, without overfitting to the calibration set; it also does not rely on any data layout reordering, maintaining the hardware efficiency. AWQ outperforms existing work on various language modeling, common sense QA, and domain-specific benchmarks. Thanks to better generalization, it achieves excellent quantization performance for instruction-tuned LMs and, for the first time, multi-modal LMs. We also implement efficient tensor core kernels with reorder-free online dequantization to accelerate AWQ, achieving a 1.45x speedup over GPTQ and is 1.85x faster than the cuBLAS FP16 implementation. Our method provides a turn-key solution to compress LLMs to 3/4 bits for efficient deployment.
Offsite-Tuning: Transfer Learning without Full Model
Feb 09, 2023



Transfer learning is important for foundation models to adapt to downstream tasks. However, many foundation models are proprietary, so users must share their data with model owners to fine-tune the models, which is costly and raise privacy concerns. Moreover, fine-tuning large foundation models is computation-intensive and impractical for most downstream users. In this paper, we propose Offsite-Tuning, a privacy-preserving and efficient transfer learning framework that can adapt billion-parameter foundation models to downstream data without access to the full model. In offsite-tuning, the model owner sends a light-weight adapter and a lossy compressed emulator to the data owner, who then fine-tunes the adapter on the downstream data with the emulator's assistance. The fine-tuned adapter is then returned to the model owner, who plugs it into the full model to create an adapted foundation model. Offsite-tuning preserves both parties' privacy and is computationally more efficient than the existing fine-tuning methods that require access to the full model weights. We demonstrate the effectiveness of offsite-tuning on various large language and vision foundation models. Offsite-tuning can achieve comparable accuracy as full model fine-tuning while being privacy-preserving and efficient, achieving 6.5x speedup and 5.6x memory reduction. Code is available at https://github.com/mit-han-lab/offsite-tuning.
SmoothQuant: Accurate and Efficient Post-Training Quantization for Large Language Models
Nov 28, 2022Large language models (LLMs) show excellent performance but are compute- and memory-intensive. Quantization can reduce memory and accelerate inference. However, for LLMs beyond 100 billion parameters, existing methods cannot maintain accuracy or do not run efficiently on hardware. We propose SmoothQuant, a training-free, accuracy-preserving, and general-purpose post-training quantization (PTQ) solution to enable 8-bit weight, 8-bit activation (W8A8) quantization for LLMs that can be implemented efficiently. We observe that systematic outliers appear at fixed activation channels. Based on the fact that weights are easy to quantize while activations are not, SmoothQuant smooths the activation outliers by offline migrating the quantization difficulty from activations to weights with a mathematically equivalent transformation. SmoothQuant enables an INT8 quantization of both weights and activations for all the GEMMs in LLMs, including OPT-175B, BLOOM-176B, and GLM-130B. SmoothQuant has better hardware efficiency than existing techniques using mixed-precision activation quantization or weight-only quantization. We demonstrate up to 1.56x speedup and 2x memory reduction for LLMs with negligible loss in accuracy. Thanks to the hardware-friendly design, we integrate SmoothQuant into FasterTransformer, a state-of-the-art LLM serving framework, and achieve faster inference speed with half the number of GPUs compared to FP16. Our work offers a turn-key solution that reduces hardware costs and democratizes LLMs. Code is available at: https://github.com/mit-han-lab/smoothquant.
Efficient Spatially Sparse Inference for Conditional GANs and Diffusion Models
Nov 15, 2022



During image editing, existing deep generative models tend to re-synthesize the entire output from scratch, including the unedited regions. This leads to a significant waste of computation, especially for minor editing operations. In this work, we present Spatially Sparse Inference (SSI), a general-purpose technique that selectively performs computation for edited regions and accelerates various generative models, including both conditional GANs and diffusion models. Our key observation is that users tend to make gradual changes to the input image. This motivates us to cache and reuse the feature maps of the original image. Given an edited image, we sparsely apply the convolutional filters to the edited regions while reusing the cached features for the unedited regions. Based on our algorithm, we further propose Sparse Incremental Generative Engine (SIGE) to convert the computation reduction to latency reduction on off-the-shelf hardware. With 1.2%-area edited regions, our method reduces the computation of DDIM by 7.5$\times$ and GauGAN by 18$\times$ while preserving the visual fidelity. With SIGE, we accelerate the speed of DDIM by 3.0x on RTX 3090 and 6.6$\times$ on Apple M1 Pro CPU, and GauGAN by 4.2$\times$ on RTX 3090 and 14$\times$ on Apple M1 Pro CPU.
On-Device Training Under 256KB Memory
Jul 14, 2022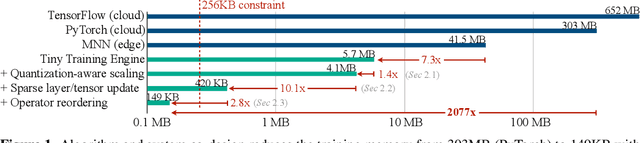
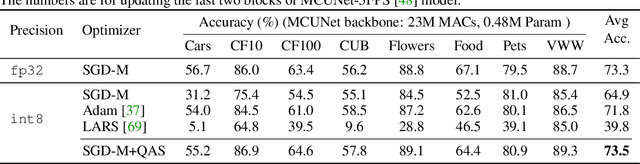
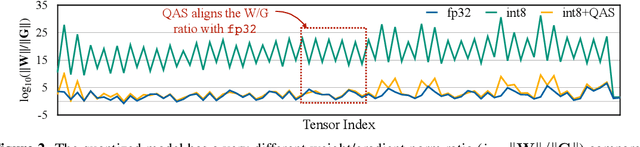
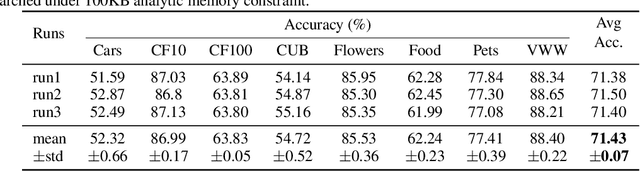
On-device training enables the model to adapt to new data collected from the sensors by fine-tuning a pre-trained model. However, the training memory consumption is prohibitive for IoT devices that have tiny memory resources. We propose an algorithm-system co-design framework to make on-device training possible with only 256KB of memory. On-device training faces two unique challenges: (1) the quantized graphs of neural networks are hard to optimize due to mixed bit-precision and the lack of normalization; (2) the limited hardware resource (memory and computation) does not allow full backward computation. To cope with the optimization difficulty, we propose Quantization-Aware Scaling to calibrate the gradient scales and stabilize quantized training. To reduce the memory footprint, we propose Sparse Update to skip the gradient computation of less important layers and sub-tensors. The algorithm innovation is implemented by a lightweight training system, Tiny Training Engine, which prunes the backward computation graph to support sparse updates and offloads the runtime auto-differentiation to compile time. Our framework is the first practical solution for on-device transfer learning of visual recognition on tiny IoT devices (e.g., a microcontroller with only 256KB SRAM), using less than 1/100 of the memory of existing frameworks while matching the accuracy of cloud training+edge deployment for the tinyML application VWW. Our study enables IoT devices to not only perform inference but also continuously adapt to new data for on-device lifelong learning.