 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStructured Semidefinite Programming for Recovering Structured Preconditioners
Oct 27, 2023We develop a general framework for finding approximately-optimal preconditioners for solving linear systems. Leveraging this framework we obtain improved runtimes for fundamental preconditioning and linear system solving problems including the following. We give an algorithm which, given positive definite $\mathbf{K} \in \mathbb{R}^{d \times d}$ with $\mathrm{nnz}(\mathbf{K})$ nonzero entries, computes an $\epsilon$-optimal diagonal preconditioner in time $\widetilde{O}(\mathrm{nnz}(\mathbf{K}) \cdot \mathrm{poly}(\kappa^\star,\epsilon^{-1}))$, where $\kappa^\star$ is the optimal condition number of the rescaled matrix. We give an algorithm which, given $\mathbf{M} \in \mathbb{R}^{d \times d}$ that is either the pseudoinverse of a graph Laplacian matrix or a constant spectral approximation of one, solves linear systems in $\mathbf{M}$ in $\widetilde{O}(d^2)$ time. Our diagonal preconditioning results improve state-of-the-art runtimes of $\Omega(d^{3.5})$ attained by general-purpose semidefinite programming, and our solvers improve state-of-the-art runtimes of $\Omega(d^{\omega})$ where $\omega > 2.3$ is the current matrix multiplication constant. We attain our results via new algorithms for a class of semidefinite programs (SDPs) we call matrix-dictionary approximation SDPs, which we leverage to solve an associated problem we call matrix-dictionary recovery.
KITAB: Evaluating LLMs on Constraint Satisfaction for Information Retrieval
Oct 24, 2023We study the ability of state-of-the art models to answer constraint satisfaction queries for information retrieval (e.g., 'a list of ice cream shops in San Diego'). In the past, such queries were considered to be tasks that could only be solved via web-search or knowledge bases. More recently, large language models (LLMs) have demonstrated initial emergent abilities in this task. However, many current retrieval benchmarks are either saturated or do not measure constraint satisfaction. Motivated by rising concerns around factual incorrectness and hallucinations of LLMs, we present KITAB, a new dataset for measuring constraint satisfaction abilities of language models. KITAB consists of book-related data across more than 600 authors and 13,000 queries, and also offers an associated dynamic data collection and constraint verification approach for acquiring similar test data for other authors. Our extended experiments on GPT4 and GPT3.5 characterize and decouple common failure modes across dimensions such as information popularity, constraint types, and context availability. Results show that in the absence of context, models exhibit severe limitations as measured by irrelevant information, factual errors, and incompleteness, many of which exacerbate as information popularity decreases. While context availability mitigates irrelevant information, it is not helpful for satisfying constraints, identifying fundamental barriers to constraint satisfaction. We open source our contributions to foster further research on improving constraint satisfaction abilities of future models.
Matrix Completion in Almost-Verification Time
Aug 07, 2023
We give a new framework for solving the fundamental problem of low-rank matrix completion, i.e., approximating a rank-$r$ matrix $\mathbf{M} \in \mathbb{R}^{m \times n}$ (where $m \ge n$) from random observations. First, we provide an algorithm which completes $\mathbf{M}$ on $99\%$ of rows and columns under no further assumptions on $\mathbf{M}$ from $\approx mr$ samples and using $\approx mr^2$ time. Then, assuming the row and column spans of $\mathbf{M}$ satisfy additional regularity properties, we show how to boost this partial completion guarantee to a full matrix completion algorithm by aggregating solutions to regression problems involving the observations. In the well-studied setting where $\mathbf{M}$ has incoherent row and column spans, our algorithms complete $\mathbf{M}$ to high precision from $mr^{2+o(1)}$ observations in $mr^{3 + o(1)}$ time (omitting logarithmic factors in problem parameters), improving upon the prior state-of-the-art [JN15] which used $\approx mr^5$ samples and $\approx mr^7$ time. Under an assumption on the row and column spans of $\mathbf{M}$ we introduce (which is satisfied by random subspaces with high probability), our sample complexity improves to an almost information-theoretically optimal $mr^{1 + o(1)}$, and our runtime improves to $mr^{2 + o(1)}$. Our runtimes have the appealing property of matching the best known runtime to verify that a rank-$r$ decomposition $\mathbf{U}\mathbf{V}^\top$ agrees with the sampled observations. We also provide robust variants of our algorithms that, given random observations from $\mathbf{M} + \mathbf{N}$ with $\|\mathbf{N}\|_{F} \le \Delta$, complete $\mathbf{M}$ to Frobenius norm distance $\approx r^{1.5}\Delta$ in the same runtimes as the noiseless setting. Prior noisy matrix completion algorithms [CP10] only guaranteed a distance of $\approx \sqrt{n}\Delta$.
Automatic Prompt Optimization with "Gradient Descent" and Beam Search
May 04, 2023Large Language Models (LLMs) have shown impressive performance as general purpose agents, but their abilities remain highly dependent on prompts which are hand written with onerous trial-and-error effort. We propose a simple and nonparametric solution to this problem, Automatic Prompt Optimization (APO), which is inspired by numerical gradient descent to automatically improve prompts, assuming access to training data and an LLM API. The algorithm uses minibatches of data to form natural language ``gradients'' that criticize the current prompt. The gradients are then ``propagated'' into the prompt by editing the prompt in the opposite semantic direction of the gradient. These gradient descent steps are guided by a beam search and bandit selection procedure which significantly improves algorithmic efficiency. Preliminary results across three benchmark NLP tasks and the novel problem of LLM jailbreak detection suggest that Automatic Prompt Optimization can outperform prior prompt editing techniques and improve an initial prompt's performance by up to 31\%, by using data to rewrite vague task descriptions into more precise annotation instructions.
Query lower bounds for log-concave sampling
Apr 05, 2023Log-concave sampling has witnessed remarkable algorithmic advances in recent years, but the corresponding problem of proving lower bounds for this task has remained elusive, with lower bounds previously known only in dimension one. In this work, we establish the following query lower bounds: (1) sampling from strongly log-concave and log-smooth distributions in dimension $d\ge 2$ requires $\Omega(\log \kappa)$ queries, which is sharp in any constant dimension, and (2) sampling from Gaussians in dimension $d$ (hence also from general log-concave and log-smooth distributions in dimension $d$) requires $\widetilde \Omega(\min(\sqrt\kappa \log d, d))$ queries, which is nearly sharp for the class of Gaussians. Here $\kappa$ denotes the condition number of the target distribution. Our proofs rely upon (1) a multiscale construction inspired by work on the Kakeya conjecture in harmonic analysis, and (2) a novel reduction that demonstrates that block Krylov algorithms are optimal for this problem, as well as connections to lower bound techniques based on Wishart matrices developed in the matrix-vector query literature.
REAP: A Large-Scale Realistic Adversarial Patch Benchmark
Dec 12, 2022Machine learning models are known to be susceptible to adversarial perturbation. One famous attack is the adversarial patch, a sticker with a particularly crafted pattern that makes the model incorrectly predict the object it is placed on. This attack presents a critical threat to cyber-physical systems that rely on cameras such as autonomous cars. Despite the significance of the problem, conducting research in this setting has been difficult; evaluating attacks and defenses in the real world is exceptionally costly while synthetic data are unrealistic. In this work, we propose the REAP (REalistic Adversarial Patch) benchmark, a digital benchmark that allows the user to evaluate patch attacks on real images, and under real-world conditions. Built on top of the Mapillary Vistas dataset, our benchmark contains over 14,000 traffic signs. Each sign is augmented with a pair of geometric and lighting transformations, which can be used to apply a digitally generated patch realistically onto the sign. Using our benchmark, we perform the first large-scale assessments of adversarial patch attacks under realistic conditions. Our experiments suggest that adversarial patch attacks may present a smaller threat than previously believed and that the success rate of an attack on simpler digital simulations is not predictive of its actual effectiveness in practice. We release our benchmark publicly at https://github.com/wagner-group/reap-benchmark.
Controlling Commercial Cooling Systems Using Reinforcement Learning
Nov 11, 2022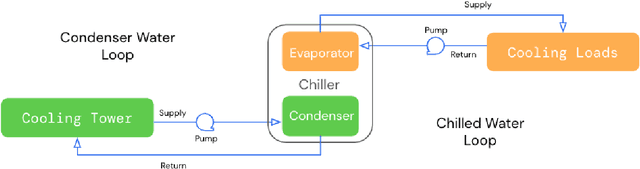
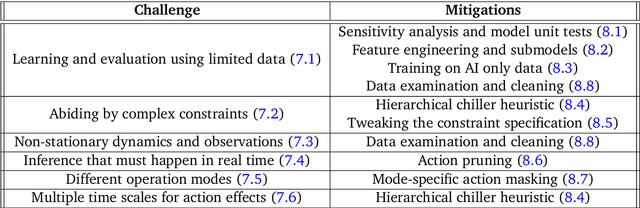

This paper is a technical overview of DeepMind and Google's recent work on reinforcement learning for controlling commercial cooling systems. Building on expertise that began with cooling Google's data centers more efficiently, we recently conducted live experiments on two real-world facilities in partnership with Trane Technologies, a building management system provider. These live experiments had a variety of challenges in areas such as evaluation, learning from offline data, and constraint satisfaction. Our paper describes these challenges in the hope that awareness of them will benefit future applied RL work. We also describe the way we adapted our RL system to deal with these challenges, resulting in energy savings of approximately 9% and 13% respectively at the two live experiment sites.
The Complexity of NISQ
Oct 13, 2022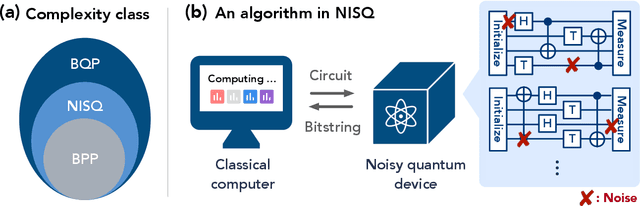
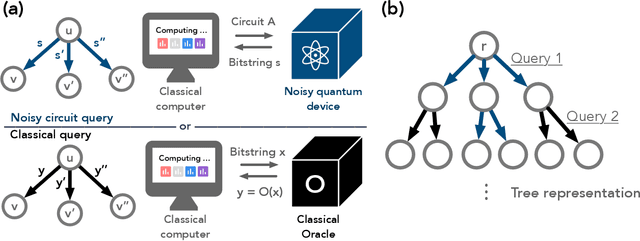
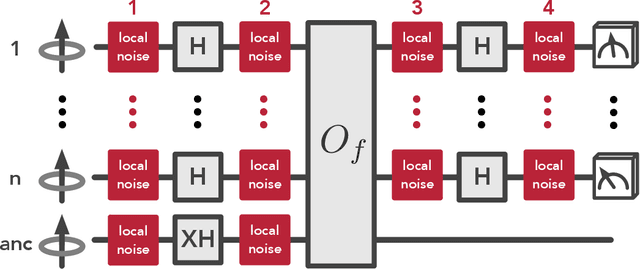
The recent proliferation of NISQ devices has made it imperative to understand their computational power. In this work, we define and study the complexity class $\textsf{NISQ} $, which is intended to encapsulate problems that can be efficiently solved by a classical computer with access to a NISQ device. To model existing devices, we assume the device can (1) noisily initialize all qubits, (2) apply many noisy quantum gates, and (3) perform a noisy measurement on all qubits. We first give evidence that $\textsf{BPP}\subsetneq \textsf{NISQ}\subsetneq \textsf{BQP}$, by demonstrating super-polynomial oracle separations among the three classes, based on modifications of Simon's problem. We then consider the power of $\textsf{NISQ}$ for three well-studied problems. For unstructured search, we prove that $\textsf{NISQ}$ cannot achieve a Grover-like quadratic speedup over $\textsf{BPP}$. For the Bernstein-Vazirani problem, we show that $\textsf{NISQ}$ only needs a number of queries logarithmic in what is required for $\textsf{BPP}$. Finally, for a quantum state learning problem, we prove that $\textsf{NISQ}$ is exponentially weaker than classical computation with access to noiseless constant-depth quantum circuits.
Sampling is as easy as learning the score: theory for diffusion models with minimal data assumptions
Oct 04, 2022We provide theoretical convergence guarantees for score-based generative models (SGMs) such as denoising diffusion probabilistic models (DDPMs), which constitute the backbone of large-scale real-world generative models such as DALL$\cdot$E 2. Our main result is that, assuming accurate score estimates, such SGMs can efficiently sample from essentially any realistic data distribution. In contrast to prior works, our results (1) hold for an $L^2$-accurate score estimate (rather than $L^\infty$-accurate); (2) do not require restrictive functional inequality conditions that preclude substantial non-log-concavity; (3) scale polynomially in all relevant problem parameters; and (4) match state-of-the-art complexity guarantees for discretization of the Langevin diffusion, provided that the score error is sufficiently small. We view this as strong theoretical justification for the empirical success of SGMs. We also examine SGMs based on the critically damped Langevin diffusion (CLD). Contrary to conventional wisdom, we provide evidence that the use of the CLD does not reduce the complexity of SGMs.
Tight Bounds for State Tomography with Incoherent Measurements
Jun 10, 2022We consider the classic question of state tomography: given copies of an unknown quantum state $\rho\in\mathbb{C}^{d\times d}$, output $\widehat{\rho}$ for which $\|\rho - \widehat{\rho}\|_{\mathsf{tr}} \le \varepsilon$. When one is allowed to make coherent measurements entangled across all copies, $\Theta(d^2/\varepsilon^2)$ copies are necessary and sufficient [Haah et al. '17, O'Donnell-Wright '16]. Unfortunately, the protocols achieving this rate incur large quantum memory overheads that preclude implementation on current or near-term devices. On the other hand, the best known protocol using incoherent (single-copy) measurements uses $O(d^3/\varepsilon^2)$ copies [Kueng-Rauhut-Terstiege '17], and multiple papers have posed it as an open question to understand whether or not this rate is tight. In this work, we fully resolve this question, by showing that any protocol using incoherent measurements, even if they are chosen adaptively, requires $\Omega(d^3/\varepsilon^2)$ copies, matching the upper bound of [Kueng-Rauhut-Terstiege '17]. We do so by a new proof technique which directly bounds the "tilt" of the posterior distribution after measurements, which yields a surprisingly short proof of our lower bound, and which we believe may be of independent interest.