 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMatrix Completion in Almost-Verification Time
Aug 07, 2023
We give a new framework for solving the fundamental problem of low-rank matrix completion, i.e., approximating a rank-$r$ matrix $\mathbf{M} \in \mathbb{R}^{m \times n}$ (where $m \ge n$) from random observations. First, we provide an algorithm which completes $\mathbf{M}$ on $99\%$ of rows and columns under no further assumptions on $\mathbf{M}$ from $\approx mr$ samples and using $\approx mr^2$ time. Then, assuming the row and column spans of $\mathbf{M}$ satisfy additional regularity properties, we show how to boost this partial completion guarantee to a full matrix completion algorithm by aggregating solutions to regression problems involving the observations. In the well-studied setting where $\mathbf{M}$ has incoherent row and column spans, our algorithms complete $\mathbf{M}$ to high precision from $mr^{2+o(1)}$ observations in $mr^{3 + o(1)}$ time (omitting logarithmic factors in problem parameters), improving upon the prior state-of-the-art [JN15] which used $\approx mr^5$ samples and $\approx mr^7$ time. Under an assumption on the row and column spans of $\mathbf{M}$ we introduce (which is satisfied by random subspaces with high probability), our sample complexity improves to an almost information-theoretically optimal $mr^{1 + o(1)}$, and our runtime improves to $mr^{2 + o(1)}$. Our runtimes have the appealing property of matching the best known runtime to verify that a rank-$r$ decomposition $\mathbf{U}\mathbf{V}^\top$ agrees with the sampled observations. We also provide robust variants of our algorithms that, given random observations from $\mathbf{M} + \mathbf{N}$ with $\|\mathbf{N}\|_{F} \le \Delta$, complete $\mathbf{M}$ to Frobenius norm distance $\approx r^{1.5}\Delta$ in the same runtimes as the noiseless setting. Prior noisy matrix completion algorithms [CP10] only guaranteed a distance of $\approx \sqrt{n}\Delta$.
Semi-Random Sparse Recovery in Nearly-Linear Time
Mar 08, 2022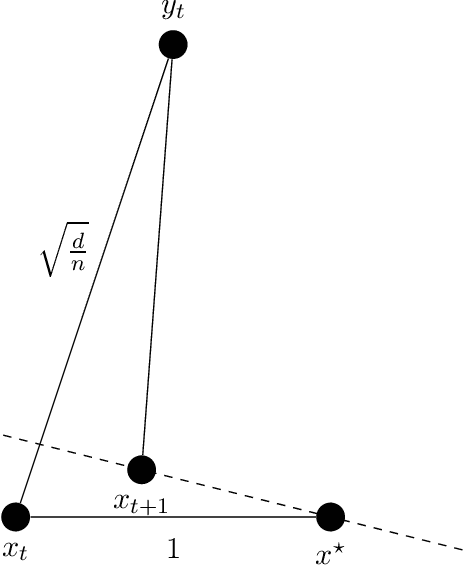
Sparse recovery is one of the most fundamental and well-studied inverse problems. Standard statistical formulations of the problem are provably solved by general convex programming techniques and more practical, fast (nearly-linear time) iterative methods. However, these latter "fast algorithms" have previously been observed to be brittle in various real-world settings. We investigate the brittleness of fast sparse recovery algorithms to generative model changes through the lens of studying their robustness to a "helpful" semi-random adversary, a framework which tests whether an algorithm overfits to input assumptions. We consider the following basic model: let $\mathbf{A} \in \mathbb{R}^{n \times d}$ be a measurement matrix which contains an unknown subset of rows $\mathbf{G} \in \mathbb{R}^{m \times d}$ which are bounded and satisfy the restricted isometry property (RIP), but is otherwise arbitrary. Letting $x^\star \in \mathbb{R}^d$ be $s$-sparse, and given either exact measurements $b = \mathbf{A} x^\star$ or noisy measurements $b = \mathbf{A} x^\star + \xi$, we design algorithms recovering $x^\star$ information-theoretically optimally in nearly-linear time. We extend our algorithm to hold for weaker generative models relaxing our planted RIP assumption to a natural weighted variant, and show that our method's guarantees naturally interpolate the quality of the measurement matrix to, in some parameter regimes, run in sublinear time. Our approach differs from prior fast iterative methods with provable guarantees under semi-random generative models: natural conditions on a submatrix which make sparse recovery tractable are NP-hard to verify. We design a new iterative method tailored to the geometry of sparse recovery which is provably robust to our semi-random model. We hope our approach opens the door to new robust, efficient algorithms for natural statistical inverse problems.
Distributional Hardness Against Preconditioned Lasso via Erasure-Robust Designs
Mar 05, 2022Sparse linear regression with ill-conditioned Gaussian random designs is widely believed to exhibit a statistical/computational gap, but there is surprisingly little formal evidence for this belief, even in the form of examples that are hard for restricted classes of algorithms. Recent work has shown that, for certain covariance matrices, the broad class of Preconditioned Lasso programs provably cannot succeed on polylogarithmically sparse signals with a sublinear number of samples. However, this lower bound only shows that for every preconditioner, there exists at least one signal that it fails to recover successfully. This leaves open the possibility that, for example, trying multiple different preconditioners solves every sparse linear regression problem. In this work, we prove a stronger lower bound that overcomes this issue. For an appropriate covariance matrix, we construct a single signal distribution on which any invertibly-preconditioned Lasso program fails with high probability, unless it receives a linear number of samples. Surprisingly, at the heart of our lower bound is a new positive result in compressed sensing. We show that standard sparse random designs are with high probability robust to adversarial measurement erasures, in the sense that if $b$ measurements are erased, then all but $O(b)$ of the coordinates of the signal are still information-theoretically identifiable. To our knowledge, this is the first time that partial recoverability of arbitrary sparse signals under erasures has been studied in compressed sensing.
Dictionary Learning and Tensor Decomposition via the Sum-of-Squares Method
Nov 07, 2014
We give a new approach to the dictionary learning (also known as "sparse coding") problem of recovering an unknown $n\times m$ matrix $A$ (for $m \geq n$) from examples of the form \[ y = Ax + e, \] where $x$ is a random vector in $\mathbb R^m$ with at most $\tau m$ nonzero coordinates, and $e$ is a random noise vector in $\mathbb R^n$ with bounded magnitude. For the case $m=O(n)$, our algorithm recovers every column of $A$ within arbitrarily good constant accuracy in time $m^{O(\log m/\log(\tau^{-1}))}$, in particular achieving polynomial time if $\tau = m^{-\delta}$ for any $\delta>0$, and time $m^{O(\log m)}$ if $\tau$ is (a sufficiently small) constant. Prior algorithms with comparable assumptions on the distribution required the vector $x$ to be much sparser---at most $\sqrt{n}$ nonzero coordinates---and there were intrinsic barriers preventing these algorithms from applying for denser $x$. We achieve this by designing an algorithm for noisy tensor decomposition that can recover, under quite general conditions, an approximate rank-one decomposition of a tensor $T$, given access to a tensor $T'$ that is $\tau$-close to $T$ in the spectral norm (when considered as a matrix). To our knowledge, this is the first algorithm for tensor decomposition that works in the constant spectral-norm noise regime, where there is no guarantee that the local optima of $T$ and $T'$ have similar structures. Our algorithm is based on a novel approach to using and analyzing the Sum of Squares semidefinite programming hierarchy (Parrilo 2000, Lasserre 2001), and it can be viewed as an indication of the utility of this very general and powerful tool for unsupervised learning problems.