 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProBO: a Framework for Using Probabilistic Programming in Bayesian Optimization
Jan 31, 2019
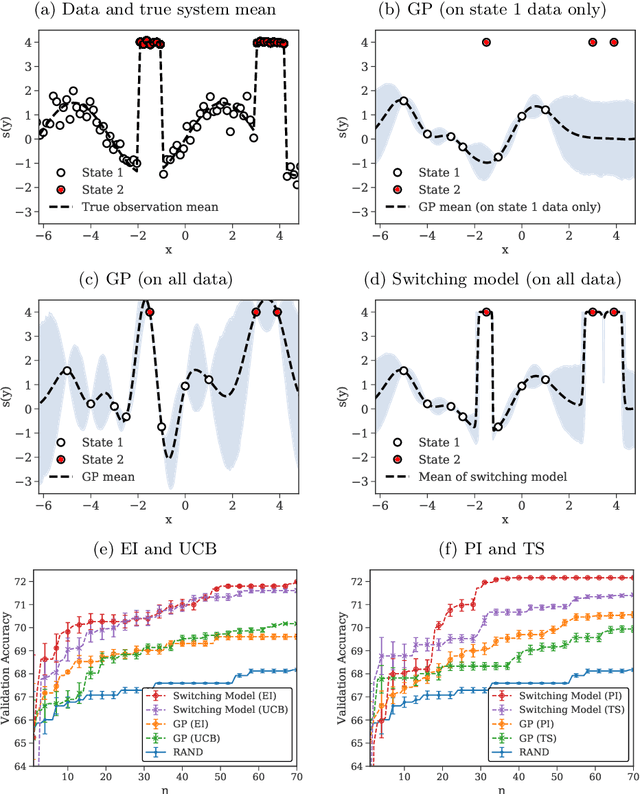
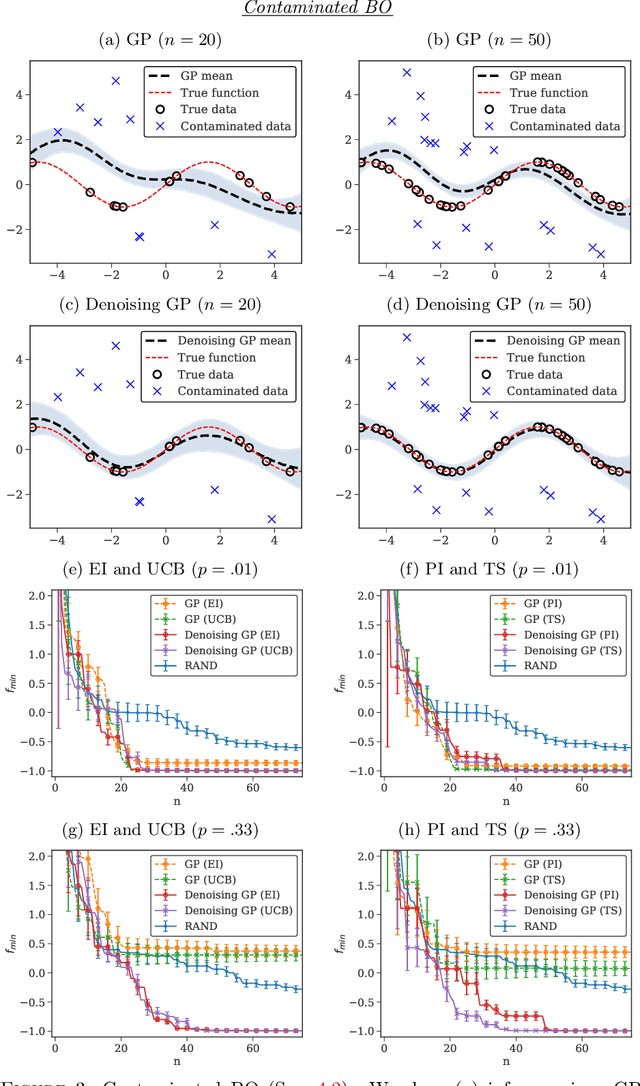
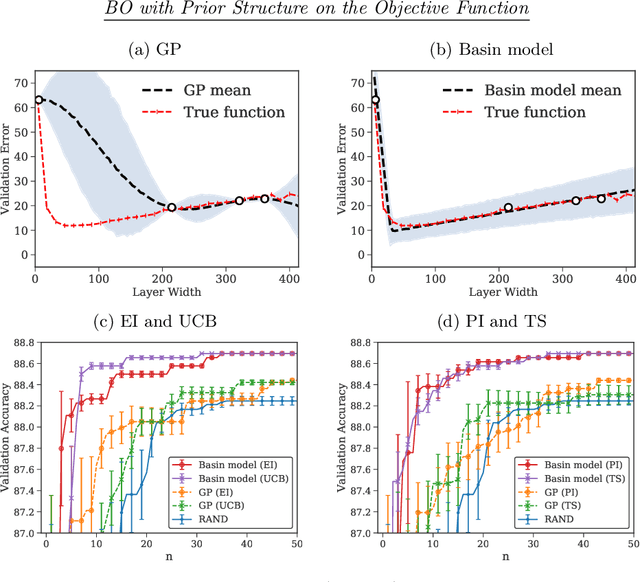
Optimizing an expensive-to-query function is a common task in science and engineering, where it is beneficial to keep the number of queries to a minimum. A popular strategy is Bayesian optimization (BO), which leverages probabilistic models for this task. Most BO today uses Gaussian processes (GPs), or a few other surrogate models. However, there is a broad set of Bayesian modeling techniques that we may want to use to capture complex systems and reduce the number of queries. Probabilistic programs (PPs) are modern tools that allow for flexible model composition, incorporation of prior information, and automatic inference. In this paper, we develop ProBO, a framework for BO using only standard operations common to most PPs. This allows a user to drop in an arbitrary PP implementation and use it directly in BO. To do this, we describe black box versions of popular acquisition functions that can be used in our framework automatically, without model-specific derivation, and show how to optimize these functions. We also introduce a model, which we term the Bayesian Product of Experts, that integrates into ProBO and can be used to combine information from multiple models implemented with different PPs. We show empirical results using multiple PP implementations, and compare against standard BO methods.
Transformation Autoregressive Networks
Oct 23, 2018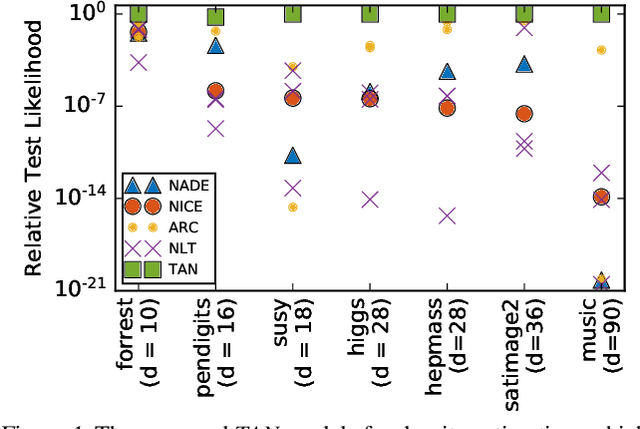
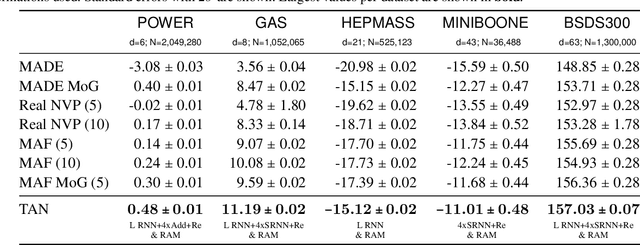
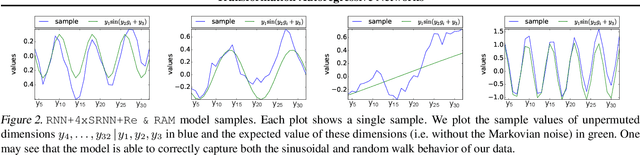
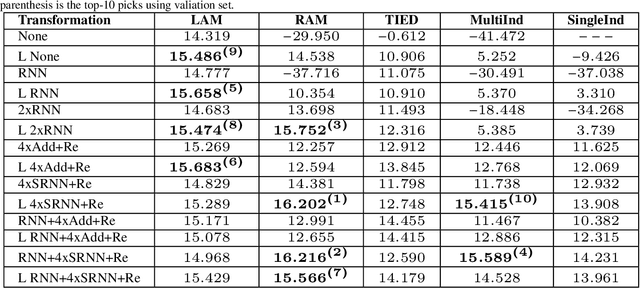
The fundamental task of general density estimation $p(x)$ has been of keen interest to machine learning. In this work, we attempt to systematically characterize methods for density estimation. Broadly speaking, most of the existing methods can be categorized into either using: \textit{a}) autoregressive models to estimate the conditional factors of the chain rule, $p(x_{i}\, |\, x_{i-1}, \ldots)$; or \textit{b}) non-linear transformations of variables of a simple base distribution. Based on the study of the characteristics of these categories, we propose multiple novel methods for each category. For example we proposed RNN based transformations to model non-Markovian dependencies. Further, through a comprehensive study over both real world and synthetic data, we show for that jointly leveraging transformations of variables and autoregressive conditional models, results in a considerable improvement in performance. We illustrate the use of our models in outlier detection and image modeling. Finally we introduce a novel data driven framework for learning a family of distributions.
Short-term Motion Prediction of Traffic Actors for Autonomous Driving using Deep Convolutional Networks
Sep 16, 2018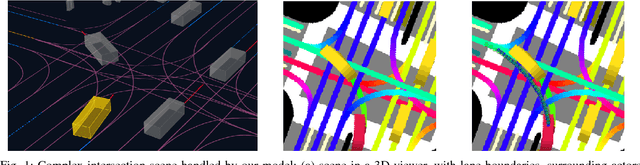


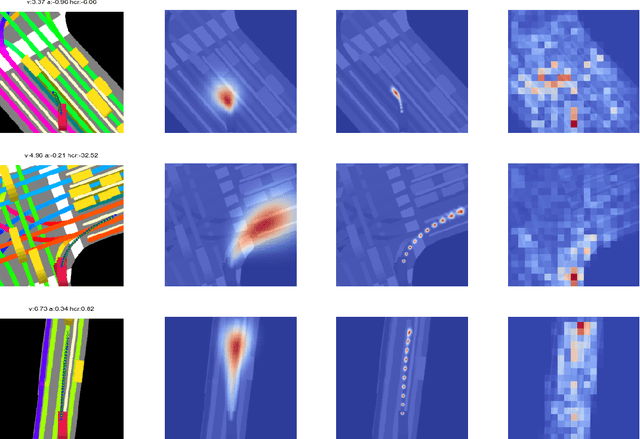
Despite its ubiquity in our daily lives, AI is only just starting to make advances in what may arguably have the largest societal impact thus far, the nascent field of autonomous driving. In this work we discuss this important topic and address one of crucial aspects of the emerging area, the problem of predicting future state of autonomous vehicle's surrounding necessary for safe and efficient operations. We introduce a deep learning-based approach that takes into account current world state and produces rasterized representations of each actor's vicinity. The raster images are then used by deep convolutional models to infer future movement of actors while accounting for inherent uncertainty of the prediction task. Extensive experiments on real-world data strongly suggest benefits of the proposed approach. Moreover, following successful tests the system was deployed to a fleet of autonomous vehicles.
Multi-fidelity Gaussian Process Bandit Optimisation
Aug 04, 2018
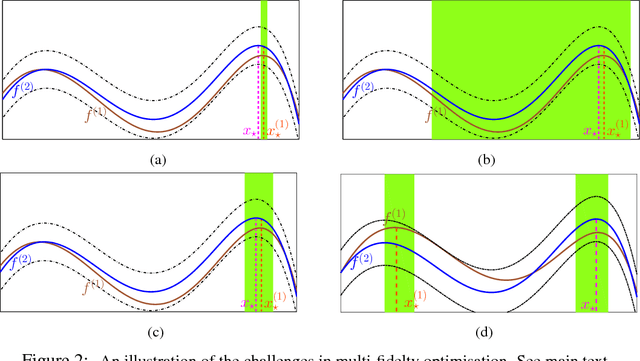
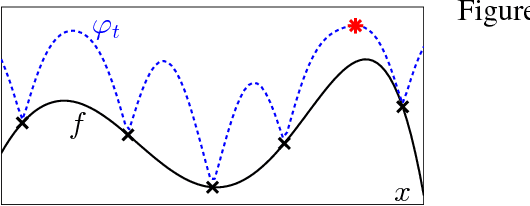
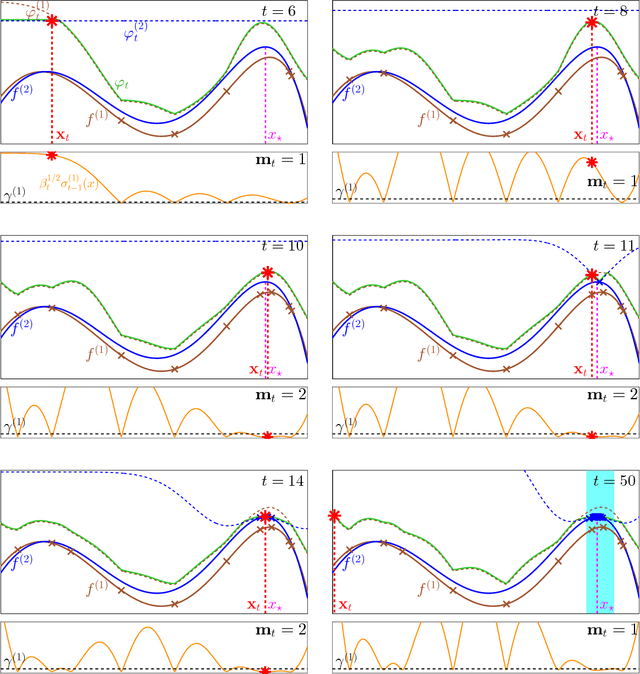
In many scientific and engineering applications, we are tasked with the maximisation of an expensive to evaluate black box function $f$. Traditional settings for this problem assume just the availability of this single function. However, in many cases, cheap approximations to $f$ may be obtainable. For example, the expensive real world behaviour of a robot can be approximated by a cheap computer simulation. We can use these approximations to eliminate low function value regions cheaply and use the expensive evaluations of $f$ in a small but promising region and speedily identify the optimum. We formalise this task as a \emph{multi-fidelity} bandit problem where the target function and its approximations are sampled from a Gaussian process. We develop MF-GP-UCB, a novel method based on upper confidence bound techniques. In our theoretical analysis we demonstrate that it exhibits precisely the above behaviour, and achieves better regret than strategies which ignore multi-fidelity information. Empirically, MF-GP-UCB outperforms such naive strategies and other multi-fidelity methods on several synthetic and real experiments.
Neural Architecture Search with Bayesian Optimisation and Optimal Transport
Jun 10, 2018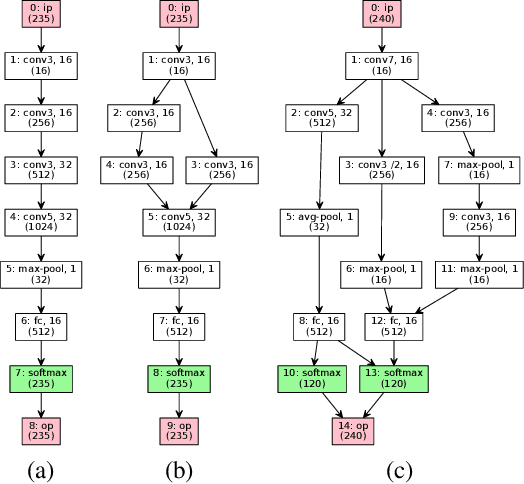


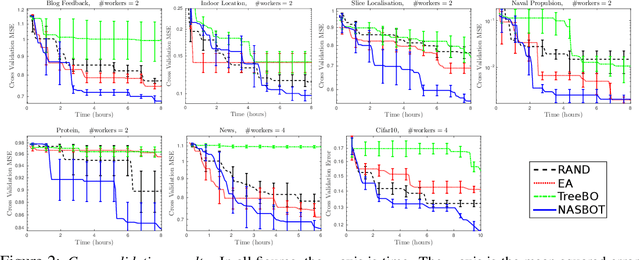
Bayesian Optimisation (BO) refers to a class of methods for global optimisation of a function $f$ which is only accessible via point evaluations. It is typically used in settings where $f$ is expensive to evaluate. A common use case for BO in machine learning is model selection, where it is not possible to analytically model the generalisation performance of a statistical model, and we resort to noisy and expensive training and validation procedures to choose the best model. Conventional BO methods have focused on Euclidean and categorical domains, which, in the context of model selection, only permits tuning scalar hyper-parameters of machine learning algorithms. However, with the surge of interest in deep learning, there is an increasing demand to tune neural network \emph{architectures}. In this work, we develop NASBOT, a Gaussian process based BO framework for neural architecture search. To accomplish this, we develop a distance metric in the space of neural network architectures which can be computed efficiently via an optimal transport program. This distance might be of independent interest to the deep learning community as it may find applications outside of BO. We demonstrate that NASBOT outperforms other alternatives for architecture search in several cross validation based model selection tasks on multi-layer perceptrons and convolutional neural networks.
Myopic Bayesian Design of Experiments via Posterior Sampling and Probabilistic Programming
May 25, 2018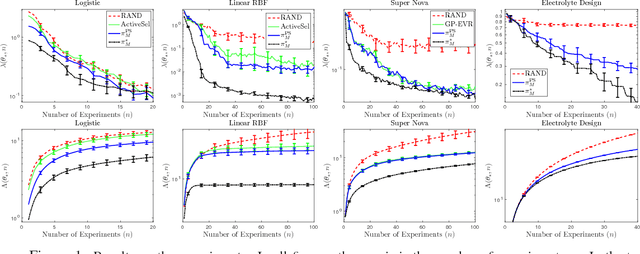
We design a new myopic strategy for a wide class of sequential design of experiment (DOE) problems, where the goal is to collect data in order to to fulfil a certain problem specific goal. Our approach, Myopic Posterior Sampling (MPS), is inspired by the classical posterior (Thompson) sampling algorithm for multi-armed bandits and leverages the flexibility of probabilistic programming and approximate Bayesian inference to address a broad set of problems. Empirically, this general-purpose strategy is competitive with more specialised methods in a wide array of DOE tasks, and more importantly, enables addressing complex DOE goals where no existing method seems applicable. On the theoretical side, we leverage ideas from adaptive submodularity and reinforcement learning to derive conditions under which MPS achieves sublinear regret against natural benchmark policies.
Bayesian Nonparametric Kernel-Learning
Jan 30, 2018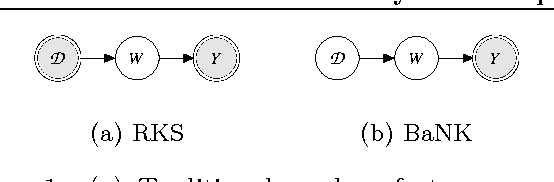

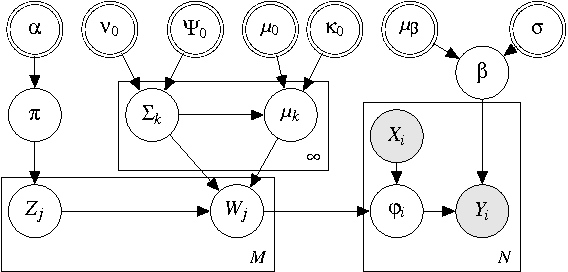

Kernel methods are ubiquitous tools in machine learning. However, there is often little reason for the common practice of selecting a kernel a priori. Even if a universal approximating kernel is selected, the quality of the finite sample estimator may be greatly affected by the choice of kernel. Furthermore, when directly applying kernel methods, one typically needs to compute a $N \times N$ Gram matrix of pairwise kernel evaluations to work with a dataset of $N$ instances. The computation of this Gram matrix precludes the direct application of kernel methods on large datasets, and makes kernel learning especially difficult. In this paper we introduce Bayesian nonparmetric kernel-learning (BaNK), a generic, data-driven framework for scalable learning of kernels. BaNK places a nonparametric prior on the spectral distribution of random frequencies allowing it to both learn kernels and scale to large datasets. We show that this framework can be used for large scale regression and classification tasks. Furthermore, we show that BaNK outperforms several other scalable approaches for kernel learning on a variety of real world datasets.
Estimating Cosmological Parameters from the Dark Matter Distribution
Nov 06, 2017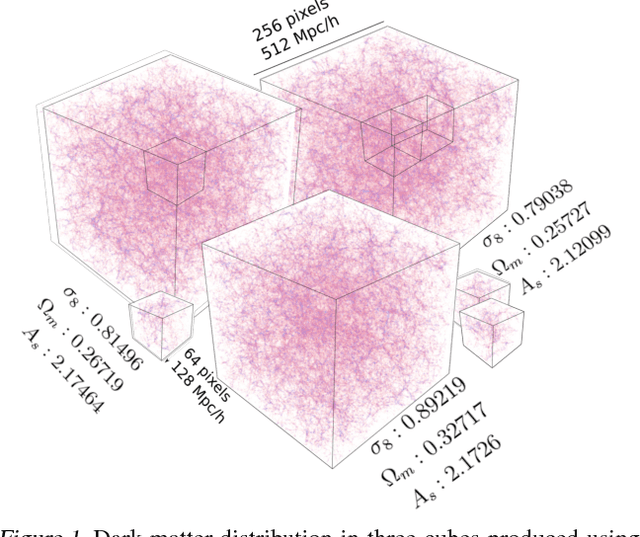
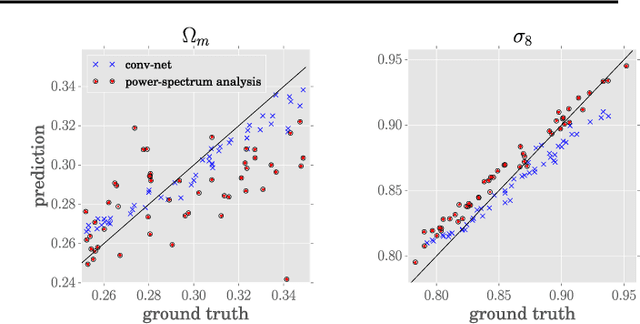

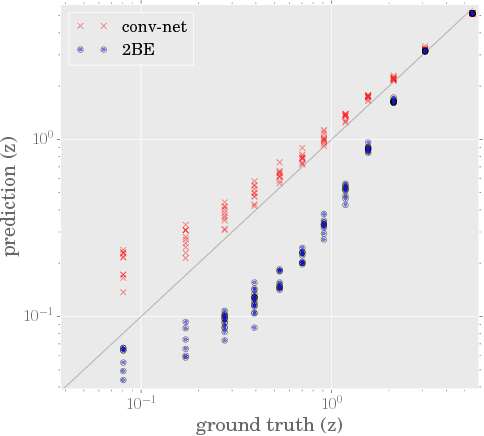
A grand challenge of the 21st century cosmology is to accurately estimate the cosmological parameters of our Universe. A major approach to estimating the cosmological parameters is to use the large-scale matter distribution of the Universe. Galaxy surveys provide the means to map out cosmic large-scale structure in three dimensions. Information about galaxy locations is typically summarized in a "single" function of scale, such as the galaxy correlation function or power-spectrum. We show that it is possible to estimate these cosmological parameters directly from the distribution of matter. This paper presents the application of deep 3D convolutional networks to volumetric representation of dark-matter simulations as well as the results obtained using a recently proposed distribution regression framework, showing that machine learning techniques are comparable to, and can sometimes outperform, maximum-likelihood point estimates using "cosmological models". This opens the way to estimating the parameters of our Universe with higher accuracy.
Scaling Active Search using Linear Similarity Functions
Aug 22, 2017
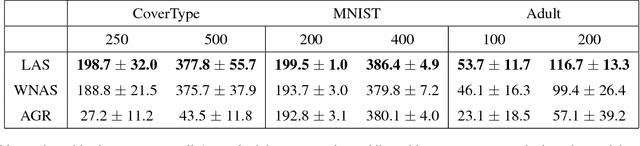
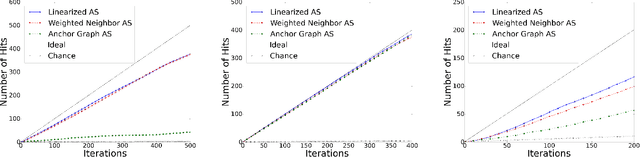
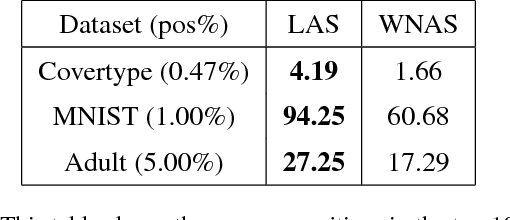
Active Search has become an increasingly useful tool in information retrieval problems where the goal is to discover as many target elements as possible using only limited label queries. With the advent of big data, there is a growing emphasis on the scalability of such techniques to handle very large and very complex datasets. In this paper, we consider the problem of Active Search where we are given a similarity function between data points. We look at an algorithm introduced by Wang et al. [2013] for Active Search over graphs and propose crucial modifications which allow it to scale significantly. Their approach selects points by minimizing an energy function over the graph induced by the similarity function on the data. Our modifications require the similarity function to be a dot-product between feature vectors of data points, equivalent to having a linear kernel for the adjacency matrix. With this, we are able to scale tremendously: for $n$ data points, the original algorithm runs in $O(n^2)$ time per iteration while ours runs in only $O(nr + r^2)$ given $r$-dimensional features. We also describe a simple alternate approach using a weighted-neighbor predictor which also scales well. In our experiments, we show that our method is competitive with existing semi-supervised approaches. We also briefly discuss conditions under which our algorithm performs well.
Equivariance Through Parameter-Sharing
Jun 13, 2017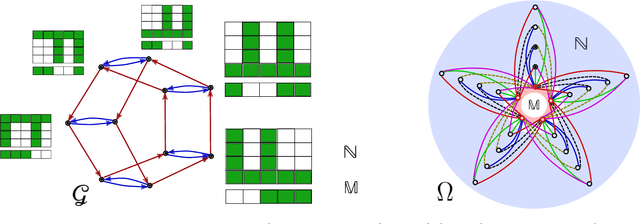
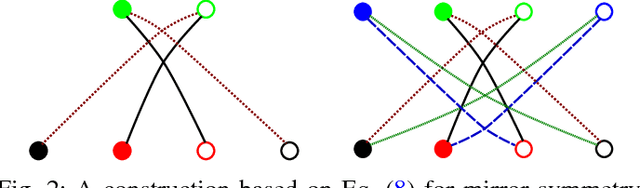
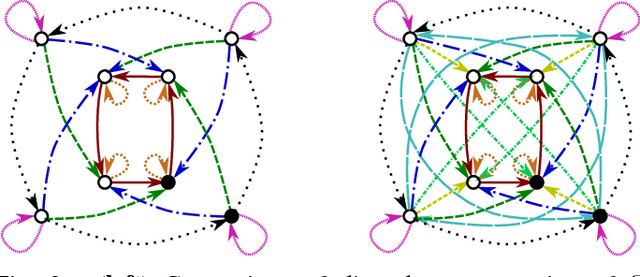
We propose to study equivariance in deep neural networks through parameter symmetries. In particular, given a group $\mathcal{G}$ that acts discretely on the input and output of a standard neural network layer $\phi_{W}: \Re^{M} \to \Re^{N}$, we show that $\phi_{W}$ is equivariant with respect to $\mathcal{G}$-action iff $\mathcal{G}$ explains the symmetries of the network parameters $W$. Inspired by this observation, we then propose two parameter-sharing schemes to induce the desirable symmetry on $W$. Our procedures for tying the parameters achieve $\mathcal{G}$-equivariance and, under some conditions on the action of $\mathcal{G}$, they guarantee sensitivity to all other permutation groups outside $\mathcal{G}$.